solr之搜索引擎
文 / 汝淉
都是个人自己写的,肯定会有一些不当的地方,还希望海涵,当然指出来多交流
如若转载,请说明出处…原创不易…谢谢支持
一:solr的介绍
目前市面上流行的搜素引擎有以Solr 和ElasticSearch领衔的等等好几种…他们的共同点都是能处理千万以及上亿级别的数据搜索和存储…功能很强大,数据量越大,就得采用集群发方式,会让性能得到很大的提升…
说到Solr 和ElasticSearch不得不提Lucene.一个功能强大的检索引擎,Solr 和ElasticSearch都是基于Lucene的…所以就有必要提提Lucene.
Lucene: 全称"全文检索引擎".是一款高性能的、可拓展的信息检索(IR)工具库,
提供了完整的查询引擎和索引引擎…他有以下几种操作类型…
- IndexWriter :负责创建新索引或者打开已有索引,以及向索引中添加、删除或更新被索引文档的信息。
- Directory:描述了Lucene索引的存放位置。它是一个抽象类,它的子类负责具体指定索引的存储路径。
- Analyzar:负责从被索引文本文件中提取词汇单元,并提出剩下的无用信息。分析器的分析对象为文档,该文档包含一些分离的能被索引的域。
- Document:文档对象代表一些域(Field)的集合。Lucene只处理从二进制文档中提取的以Field实例出现的文本
- Field:指包含能被索引的文本内容的类。
- IndexSearcher:用于搜索由IndexWriter类创建的索引。
- Term:搜索功能的基本单元。与Field对象类似,Term对象包含一对字符串元素:域名和单词(或域文本值)。
- Query: 查询类。
- TermQuery:最基本的查询类型,也是简单查询类型之一。用来匹配指定域中包含特定项的文档。
- TopDocs:一个简单的指针容器,指针一般指向前N个排名的搜索结果,搜索结果即匹配查询条件的文档。TopDocs会记录前N个结果中每个结果的int docID(可以用它来恢复文档)和浮点型分数。
其实,Solr与Lucene 并不是竞争对立关系,恰恰相反Solr 依存于Lucene,因为Solr底层的核心技术是使用Lucene 来实现的,Solr和Lucene的本质区别有以下三点:搜索服务器,企业级和管理。Lucene本质上是搜索库,不是独立的应用程序,而Solr是。Lucene专注于搜索底层的建设,而Solr专注于企业应用。Lucene不负责支撑搜索服务所必须的管理,而Solr负责。
一句话概括 Solr: Solr是Lucene面向企业搜索应用的扩展。
这些相关标志在后面的Solr界面会有体现.详细介绍可网上查询.
以Solr为例.Solr基于Lucene,继承了Lucene的强大的检索能力. …下面重点介绍Solr.
Solr:是一个高性能,采用Java5开发,Solr基于Lucene的全文搜索服务器。同时对其进行了扩展,提供了比Lucene更为丰富的查询语言,同时实现了可配置、可扩展并对查询性能进行了优化,并且提供了一个完善的功能管理界面,是一款非常优秀的全文搜索引擎。
个人使用见解: Solr提供了方便的"管理员"操作界面,大大方便了"管理员的操作",使得变的非常灵活 和方便,他有索引创建和索引检索2个强大的功能…
**索引创建:**他有自己提供的NoSql的索引库,可以把数据从数据库增量到索引库中,对每条数据生成索引,进行存储…
**索引检索:**方便查询,所以才会使千万级别的数据查询变的很快…灵活的参数设置和完美的结果展示,使用户体验非常好…,上面这2大功能都能在Solr界面展示出来…以图为例
看的时候, 最左侧都是目录 右侧一大片都是query的操作详情界面
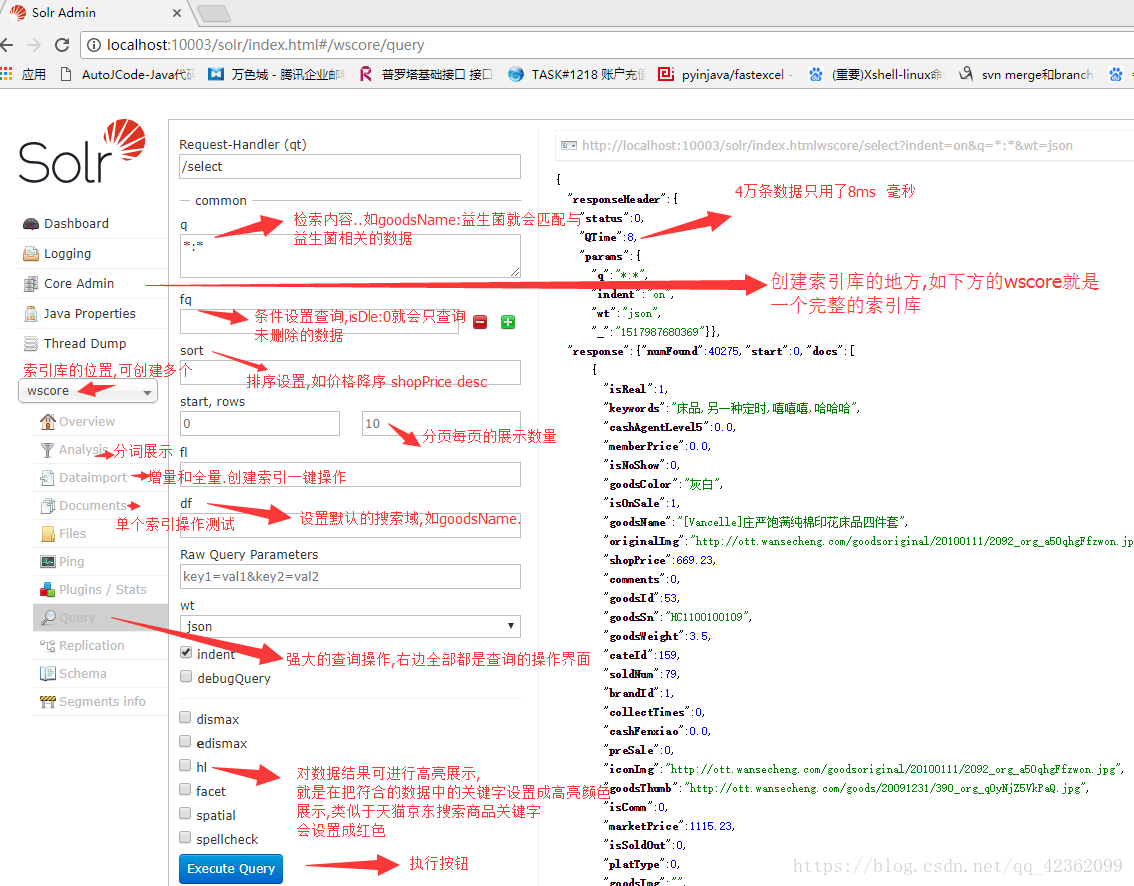
非常方便和灵活的操作界面,后面会逐个详解各个操作位置的详情.
二:solr的安装部署
1. 所需工具solr6.6.2 tomcat8 jdk8 Ik-Analyzer 本地就正常解压就行.放到tomcat容器中部署.(都可去官网下载)…
solr自己找的下载地址: http://mirrors.shuosc.org/apache/lucene/solr/ (可选择自己想要的版本)
2. 在解压后的文件solr-6.6.2中找到solr-6.6.2\server\solr-webapp下的webapp文件夹,然后将其复制到tomcat8\webapps目录下 并起名叫solr
3.把solr-6.6.2\server\lib\ext 下所有的jar包和 solr-6.6.2\dist 下的solr-dataimporthandler-6.4.1.jar、solr-dataimporthandler-extras-6.4.1.jar2个文件复制到Tomcat8\webapps\solr\WEB-INF\lib路径中…
4. 创建solr-home 把solr-6.6.2\server目录下的solr复制到其他目录地方…(我本地的位置是D:/soft/apache-tomcat-8.0.39/solr-home)…并把该solr起名叫solr-home (索引库存放地)这是solr核心文件夹。
5. 到tomcat8\webapps\solr\WEB-INF下的web.xml 在文件中找到如下内容…取消其注释.
<env-entry>
<env-entry-name>solr/home</env-entry-name>
<env-entry-value>D:/solr/apache-tomcat-8.0.39/solr-home</env-entry-value>
<env-entry-type>java.lang.String</env-entry-type>
</env-entry>
这里是配置solr-home的位置.如我的地址是本地的地址D:/solr/apache-tomcat-8.0.39/solr-home
6.将solr-6.6.2\server\lib下的5个metrics开头的jar包复制到Tomcat8\webapps\solr\WEB-INF\lib下.
7. 将solr-6.6.2\server\resources下的log4j.properties 复制到Tomcat8\webapps\solr\WEB-INF下的classes文件夹下,此文件夹手动创建.
8.去掉tomcat的权限…找到Tomcat8\webapps\solr\WEB-INF下的web.xml文件…注释掉下面这段文字
<!--
<security-constraint>
<web-resource-collection>
<web-resource-name>Disable TRACE</web-resource-name>
<url-pattern>/</url-pattern>
<http-method>TRACE</http-method>
</web-resource-collection>
<auth-constraint/>
</security-constraint>
<security-constraint>
<web-resource-collection>
<web-resource-name>Enable everything but TRACE</web-resource-name>
<url-pattern>/</url-pattern>
<http-method-omission>TRACE</http-method-omission>
</web-resource-collection>
</security-constraint>
-->
然后这就是solr部署安装成功. 可以启动客户端尝试访问一下.不做其他修改,就是下面这个地址,就是solr的操作界面, http://localhost:10003/solr/index.html (端口号自己tomcat的端口号我的是10003)
三:创建Solr core 之索引库.(手动操作文件夹,不是在线直接创建)
Solr core是Solr-Home下的索引存储地…可以创建多个,一个core有以下目录

1. 需要创建这个core.找到solr-6.6.2\example\example-DIH\solr 下的db文件夹…将其复制到solr-home中.并起名叫mycore(随便起) 注意mycore/conf中的schema-manaed文件.此文件是配置solr的索引数据. (这个一会会做详细说明)
2.找到mycore/conf中的solrconfig.xml文件…找到此处
<requestHandler name="/dataimport" class="solr.DataImportHandler">
<lst name="defaults">
<str name="config">data-config.xml</str>
</lst>
</requestHandler>
其实只要这里配置的文件名称和mycore/conf中的data-config.xml名字一样就行..
把该文件名称配置到这里即可. .该文件是solr索引库中增量的配置地方---也就是数据库导入索引库需要配置的地方
到此处基本上就core就创建好了.
接下来需要对mycore/conf中的几个文件做详细讲解,包括各自的作用.
图中标记的前2个文件十分重要,下面那个改动一点点, 在Solr5.5版本之前,managed-schema 叫schema.xml…5.5版本之后才改成managed-schema .而网上大部分文档还是5.5以前的,所以会是schema.xml…接下来就解开managed-schema这个文件的神秘面纱.
之前提了这里是索引库中对字段的设置,所以就显得十分重要…他的内部内容很多,但是无需关心那些,只要关注3个标签 .
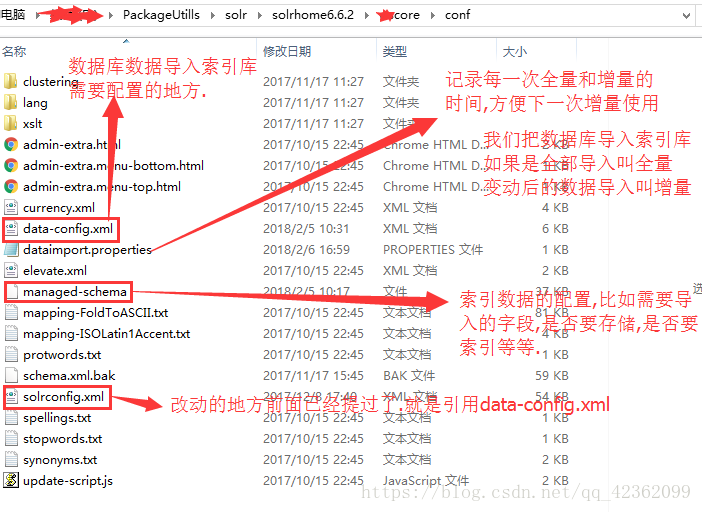
- fieldType(自带的分词类型.有很多分词器,但是没有很好支持中文的分词器.).
- field:这里是配置单个字段的地方,着重配置这里
- copyField:这里是配置字段的域…也很重要.
上截图
这里面有个地方,对于searchkey这个多值域,有了更加灵活的方法,后期直接在solr客户端query中进行查询语句匹配,无需像我这样进行固定式配置,麻烦而且不灵活…讲完这个,后面就讲多值多域匹配…
介绍上面截图中field标签中的属性
| field | 介绍上面截图中field标签中的属性|
| :-------- | -------- --: |
| name | 和数据库中的字段对应起别名,导入进索引库以后对应的字段名就是这里配置的如goods_name 对应这里可以起别名goodsName |
| type | 这里配置字段的类型,要和数据库中的字段类型一致,选取的时候,其实上方配置都有定义类型,要注意和配置的一致,比如string上方定义的时候是小写,我们就别写成大写S了至于text_ik类型,后续会讲解 |
| multiValued | 是否是多值,比如 goodsColor 可以使红,黄,蓝…所以就看需不需要多值存储了.存进索引库都是以逗号分割… |
| indexed | 是否需要索引,只有需要当做域(比如根据goodsName:益生菌)来查询,包括当做where条件来匹配的字段有必要添加索引,其他可以不用建立索引. |
| stored | 是否需要存储到索引库,一般需要返回给用户的都需要被存储, |

| copyField | 介绍上面截图中copyField标签中的属性(可以理解成设置域)|
| :-------- | -------- --: |
| source | 这里就是配置field中name属性的值,如果写的上面field未定义的会报错. |
| dest | 这里是设置域,需要一个多值的字段就行…
多值多域匹配
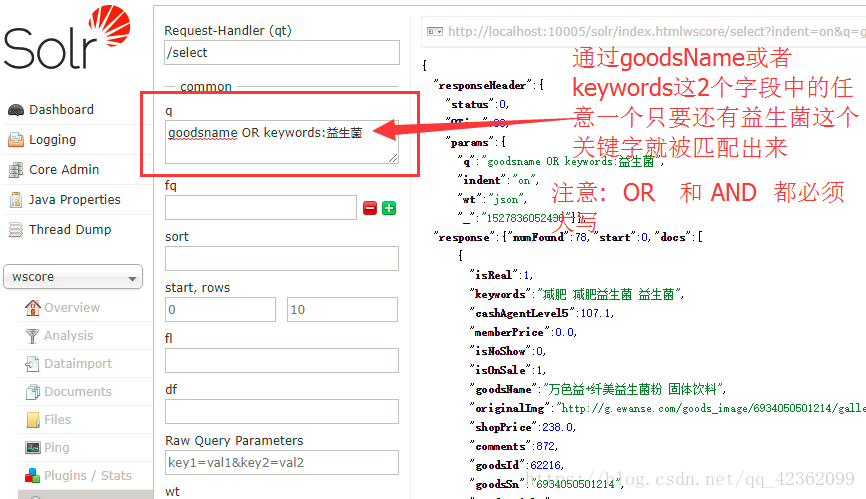
需求:相对多个字段同时进行检索,只要其中一个字段含有该关键字就匹配出记录,这里就有 大写的 OR 来组装查询语句
查询既满足A字段 又满足B字段的记录…则 查询语句为 A AND(一定要大写) B :输入的关键字.
优化上面的多值多域匹配…searchkey,可以无需像我那样设置searchkey来指定goodsName和keywords
我们可以在solr客户端这样用,直接上截图
四: 配置中文分词器 (其实这一步可以放在第二步之前,放到这里也没关系)
由于solr中没有对于中文有很好的智能分词器,所以需要我们手动配置中文分词器,我使用的是ik分词器.
我使用Ik-Analyzer5.5 将解压后的唯一一个jar包复制到solr-home\wscore\lib中.
然后将Ik-Analyzer下的3个文件ext.dic 和stopword.dic还有IKAnalyzer.xml也一起复制到Tomcat8\webapps\solr\WEB-INF\classes目录中
| Ik-Analyzer5.5中的文件 | 各个文件的作用 |
|---|---|
| IKAnalyzer.xml | 这里主要是指定ext.dic和stopword.dic…,只要这3个文件在同一目录下就不用修改这里 |
| ext.dic | 是ik的自定义词库,我们可以把不当做关键字的词,配置在这里变成关键字…如:汝淉本身不是一个关键字,定义在这里就是个关键字了. |
| stopword.dic | 是ik的自定义停词词库,意味着和ext.dic作用是相反的…比如女性是关键字,配到停词库中,分词器就不会把女性当做关键字了 |
其中的ext.dic是ik的自定义词库,用户可以进行自定义配置自己的词库…配置成功以后只要再次启动solr服务就生效了…
还有一步很重要:找到solr-home\core\conf中的managed-schema文件…然后打开此文件.加上这句话
<fieldType name="text_ik" class="solr.TextField">
<analyzer type="index" class="org.wltea.analyzer.lucene.IKAnalyzer"/>
<analyzer type="query" class="org.wltea.analyzer.lucene.IKAnalyzer"/>
</fieldType>
上截图
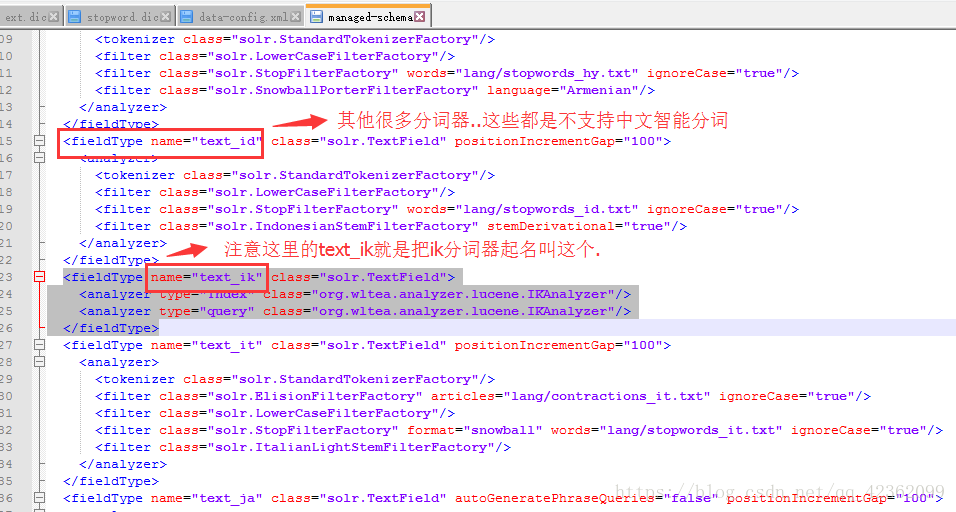
下面是对含有中文的字段配上ik,当然要有分词使用想法的字段,不能凡是中文字段的都配(没这个必要),

到此分词器就配置成功了.我们可以到Solr的操作界面去看看…启动我本地tomcat即可.然后访问http://localhost:10003/solr/index.html进行测试(我的tomcat端口号设置成10003)
在客户端界面,切换到自己的core下面的分词类目中.-----Analysis—界面.就会出现如下界面
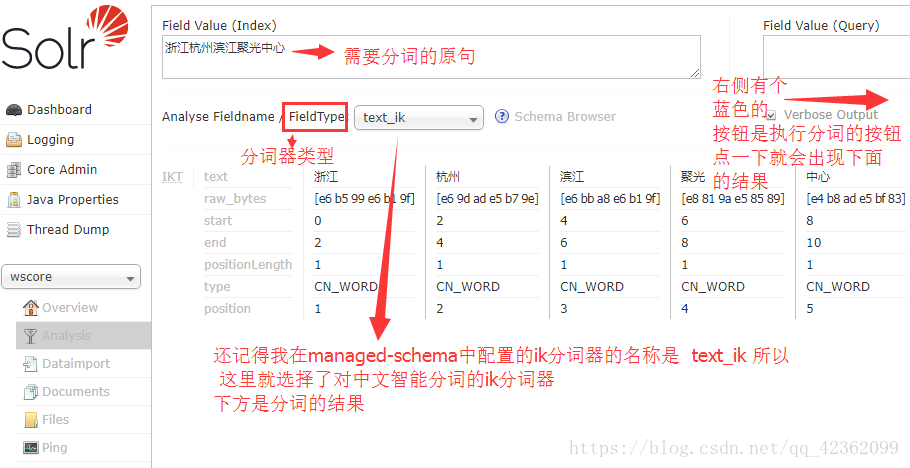
看到这步,就说明分词效果配置成功了…
拓展分词词库–自定义词库
除了solr自身的分词词库以外,有些词ik并不识别,但是我们需要用到,我们需要建立自己需要的新的关键字 比如我输入"裤子男士", ik会分成裤子,男士这2个关键字,除此以外我还想要关键字 "裤子男"这个关键字,这时候就得用到拓展四库之自定义词库.
接下来我们就配置自定义词库…找到Tomcat8\webapps\solr\WEB-INF下的classes这个文件…还记得这个文件是在前几步就创建好了…里面放了ext.dic 和stopword.dic还有IKAnalyzer.xml还有一个日志文件.总共4个文件…之前提过ext.dic就是拓展词库的配置文件…在这个文件中专门存放自定义的关键字-----上截图更直观
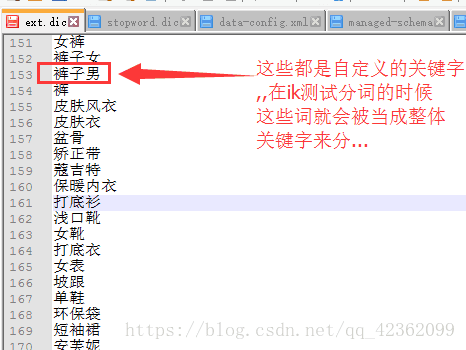
然后重启tomcat就能生效… 同理停词词库也是这样配置的…把ik识别的关键字配到stopword.dic就不会在当成关键字了.
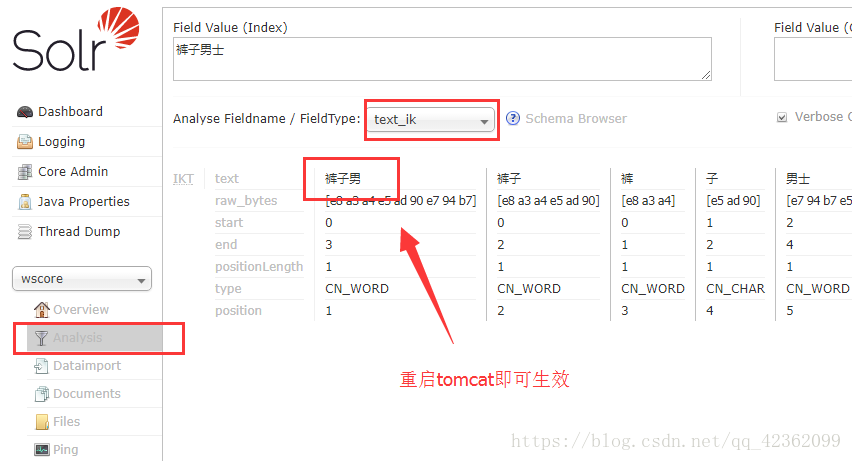
值得注意的是:ext.dic和stopword.dic…这2个文件的编码 必须是utf-8无bom编码格式,否则不生效.
到此支持中文智能分词的分词器就配置成功了.
四:增量和全量数据导入
增量:其实solr就是一个NOSQL,只是里面存储的都是被索引好的数据,查询的时候就查询索引库中的数据就行了,但是问题来了,数据里面的数据更新了,被之前导入到solr中的数据却还是原来的–也就是solr和数据库的数据不同步,基于这个需求,就衍生出了同步被更新的数据到solr中…
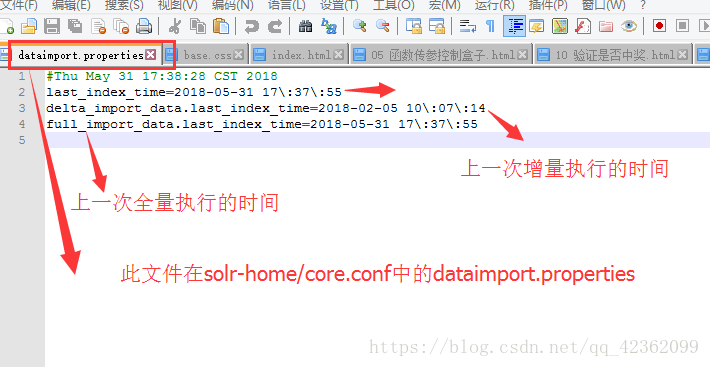
增量原理::需要数据库来一个updateTime字段,凡是数据修改就更新该字段为当前时间…然后用这个字段和上一次增量执行时间作比较…如果updateTime>大于上一次索引更新时间,就说明该数据修改过了,需要重新增量导入…索引更新时间,一会截图给出…
全量:相对于增量全量是把所有需要的数据全部重新导入到solr中
操作如下:
1. 找到solr-home\wscore\conf下的data-config.xml文件…这里就是配置数据库增量的相关配置.
2. 在增量导入数据的时候需要一个jar包…这个jar包是数据库的驱动…将此jar包上传到Tomcat8\webapps\solr\WEB-INF\lib下…启动tomcat就可以了,在solr客户端就能测试了…
直接上传本地处理好的schema-manaed这个文件和data-config.xml文件.
这是schema-manaed中相关字段的配置..
<field name="goodsId" type="long" multiValued="false" indexed="true" stored="true"/>
<field name="goodsName" type="text_ik" multiValued="false" indexed="true" stored="true"/>
<field name="goodsSn" type="text_ik" multiValued="false" indexed="false" stored="true"/>
<field name="keywords" type="text_ik" multiValued="false" indexed="true" stored="true"/>
<field name="isOnSale" type="int" multiValued="false" indexed="true" stored="true"/>
<field name="isDel" type="int" multiValued="false" indexed="true" stored="true"/>
<field name="isNoShow" type="int" multiValued="false" indexed="true" stored="true"/>
<field name="isSoldOut" type="int" multiValued="false" indexed="true" stored="true"/>
<field name="platType" type="int" multiValued="false" indexed="true" stored="true"/>
<field name="shopPrice" type="double" multiValued="false" indexed="true" stored="true"/>
<field name="marketPrice" type="double" multiValued="false" indexed="false" stored="true"/>
<field name="originalImg" type="string" multiValued="false" indexed="false" stored="true"/>
<field name="comments" type="long" multiValued="false" indexed="true" stored="true"/>
<field name="soldNum" type="long" multiValued="false" indexed="true" stored="true"/>
<field name="brandId" type="int" multiValued="false" indexed="false" stored="true"/>
<field name="cateId" type="int" multiValued="false" indexed="false" stored="true"/>
<field name="collectTimes" type="int" multiValued="false" indexed="false" stored="true"/>
<field name="goodsColor" type="string" multiValued="false" indexed="false" stored="true"/>
<field name="goodsWeight" type="double" multiValued="false" indexed="false" stored="true"/>
<field name="iconImg" type="string" multiValued="false" indexed="false" stored="true"/>
<field name="isComm" type="int" multiValued="false" indexed="false" stored="true"/>
<field name="isHot" type="int" multiValued="false" indexed="false" stored="true"/>
<field name="isReal" type="int" multiValued="false" indexed="false" stored="true"/>
<field name="memberPrice" type="double" multiValued="false" indexed="false" stored="true"/>
<field name="cashFenxiao" type="float" multiValued="false" indexed="false" stored="true"/>
<field name="cashAgentLevel5" type="float" multiValued="false" indexed="false" stored="true"/>
<field name="goodsThumb" type="string" multiValued="false" indexed="false" stored="true"/>
<field name="goodsImg" type="string" multiValued="false" indexed="false" stored="true"/>
<field name="preSale" type="int" multiValued="false" indexed="false" stored="true"/>
<field name="platCode" type="string" multiValued="false" indexed="true" stored="true"/>
<field name="searchkey" type="text_ik" multiValued="true" indexed="true" stored="false"/>
<field name="text" type="text_ik" multiValued="true" indexed="true" stored="false"/>
<copyField source="goodsId" dest="text"/>
<copyField source="goodsName" dest="searchkey"/>
<copyField source="goodsSn" dest="text"/>
<copyField source="keywords" dest="searchkey"/>
<copyField source="isOnSale" dest="text"/>
<copyField source="isSoldOut" dest="text"/>
<copyField source="isDel" dest="text"/>
<copyField source="isNoShow" dest="text"/>
<copyField source="platType" dest="text"/>
<copyField source="shopPrice" dest="text"/>
<copyField source="marketPrice" dest="text"/>
<copyField source="originalImg" dest="text"/>
<copyField source="comments" dest="text"/>
<copyField source="soldNum" dest="text"/>
<copyField source="brandId" dest="text"/>
<copyField source="cateId" dest="text"/>
<copyField source="collectTimes" dest="text"/>
<copyField source="goodsColor" dest="text"/>
<copyField source="goodsWeight" dest="text"/>
<copyField source="iconImg" dest="text"/>
<copyField source="isComm" dest="text"/>
<copyField source="isHot" dest="text"/>
<copyField source="isReal" dest="text"/>
<copyField source="memberPrice" dest="text"/>
<copyField source="cashFenxiao" dest="text"/>
<copyField source="cashAgentLevel5" dest="text"/>
<copyField source="goodsThumb" dest="text"/>
<copyField source="goodsImg" dest="text"/>
<copyField source="preSale" dest="text"/>
<copyField source="platCode" dest="text"/>
data-config.xml 索引导入文件
data-config.xml文件..索引导入文件....
<dataConfig>
<dataSource
name="source"
type="JdbcDataSource"
driver="com.mysql.jdbc.Driver"
url="jdbc:mysql://*********/?zeroDateTimeBehavior=convertToNull"
user="root"
password="*************"/>
<document>
这里是全量的entity,name是这个entity的名字可以自定义.pk就是主键,具体看这个模板就能理解.
query是数据库的sql,凡是被查出来的数据就会被导入进去..
<entity name="full_import_data" dataSource="source" pk="goods_id" query="select goods_id ,
goods_name,goods_sn ,keywords,convert(is_on_sale,UNSIGNED) as isOnSale,convert(is_delete,UNSIGNED)as isDel,
convert(is_no_show,UNSIGNED)as isNoShow,is_sold_out ,convert(plat_type,UNSIGNED) as platType,shop_price, market_price,
original_img ,comments,sold_num ,brand_id,cate_id,collect_times,goods_color,weight,icon_img,member_price,cash_fenxiao,
cash_agent_level5,goods_thumb,square_img,CONVERT (pre_sale, UNSIGNED) AS preSale,CONVERT (is_real, UNSIGNED) AS isReal,
CONVERT (is_hot, UNSIGNED) AS isHot,CONVERT (is_comm, UNSIGNED) AS isComm,plat_code
from wsmall_goods.gss_goods where is_delete=0 ">
这里 数据库中字段名字 schema-managed中的字段名
<field column="goods_id" name="goodsId" />
<field column="goods_sn" name="goodsSn" />
<field column="goods_name" name="goodsName" />
<field column="keywords" name="keywords" />
<field column="is_on_sale" name="isOnSale" />
<field column="is_delete" name="isDel" />
<field column="is_no_show" name="isNoShow" />
<field column="is_sold_out" name="isSoldOut" />
<field column="plat_type" name="platType" />
<field column="shop_price" name="shopPrice" />
<field column="market_price" name="marketPrice" />
<field column="original_img" name="originalImg" />
<field column="comments" name="comments" />
<field column="sold_num" name="soldNum" />
<field column="brand_id" name="brandId" />
<field column="cate_id" name="cateId" />
<field column="collect_times" name="collectTimes" />
<field column="goods_color" name="goodsColor" />
<field column="weight" name="goodsWeight" />
<field column="icon_img" name="iconImg" />
<field column="is_comm" name="isComm" />
<field column="is_hot" name="isHot" />
<field column="is_real" name="isReal" />
<field column="member_price" name="memberPrice" />
<field column="cash_fenxiao" name="cashFenxiao" />
<field column="cash_agent_level5" name="cashAgentLevel5" />
<field column="goods_thumb" name="goodsThumb" />
<field column="square_img" name="goodsImg" />
<field column="pre_sale" name="preSale" />
<field column="plat_code" name="platCode" />
</entity>
这里是增量的entity...
deletedPkQuery:这里是指标记那些被删除的记录的主键id,因为这些记录不需要导入到索引库中..
deltaImportQuery:这个就是导入那些被修改未删除的记录,,,未修改的数据不做操作,,还在索引库中..
deltaQuery:这一步很重要:这里是查询出那些修改的数据,原理:需要数据库来一个updateTime字段,
凡是数据修改就更新该字段为当前时间..然后用这个字段和上一次增量执行时间作比较..如果updateTime>大于
上一次索引更新时间,,就说明该数据修改过了,,需要重新增量导入...索引更新时间,一会截图给出..
<entity name="delta_import_data" dataSource="source" pk="goods_id"
deletedPkQuery="select goods_id FROM wsmall_goods.gss_goods where is_delete=1"
deltaImportQuery="select goods_id ,
goods_name,goods_sn ,keywords,convert(is_on_sale,UNSIGNED) as isOnSale,convert(is_delete,UNSIGNED)as isDel,
convert(is_no_show,UNSIGNED)as isNoShow,is_sold_out ,convert(plat_type,UNSIGNED) as platType,shop_price, market_price,
original_img ,comments,sold_num ,brand_id,cate_id,collect_times,goods_color,weight,icon_img,member_price,cash_fenxiao,
cash_agent_level5,goods_thumb,square_img,CONVERT (pre_sale, UNSIGNED) AS preSale,CONVERT (is_real, UNSIGNED) AS isReal,
CONVERT (is_hot, UNSIGNED) AS isHot,CONVERT (is_comm, UNSIGNED) AS isComm,plat_code
from wsmall_goods.gss_goods where is_delete=0 and goods_id='${dataimporter.delta.goods_id}'"
deltaQuery="select goods_id FROM wsmall_goods.gss_goods where from_unixtime(update_time,'%Y-%m-%d %H:%i:%m') > '${dataimporter.last_index_time}'">
<field column="goods_id" name="goodsId" />
<field column="goods_sn" name="goodsSn" />
<field column="goods_name" name="goodsName" />
<field column="keywords" name="keywords" />
<field column="is_on_sale" name="isOnSale" />
<field column="is_delete" name="isDel" />
<field column="is_no_show" name="isNoShow" />
<field column="is_sold_out" name="isSoldOut" />
<field column="plat_type" name="platType" />
<field column="shop_price" name="shopPrice" />
<field column="market_price" name="marketPrice" />
<field column="original_img" name="originalImg" />
<field column="comments" name="comments" />
<field column="sold_num" name="soldNum" />
<field column="brand_id" name="brandId" />
<field column="cate_id" name="cateId" />
<field column="collect_times" name="collectTimes" />
<field column="goods_color" name="goodsColor" />
<field column="weight" name="goodsWeight" />
<field column="icon_img" name="iconImg" />
<field column="is_comm" name="isComm" />
<field column="is_hot" name="isHot" />
<field column="is_real" name="isReal" />
<field column="member_price" name="memberPrice" />
<field column="cash_fenxiao" name="cashFenxiao" />
<field column="cash_agent_level5" name="cashAgentLevel5" />
<field column="goods_thumb" name="goodsThumb" />
<field column="square_img" name="goodsImg" />
<field column="pre_sale" name="preSale" />
<field column="plat_code" name="platCode" />
</entity>
</document>
</dataConfig>
上一次索引时间记录的文件在solr-home/core/conf中的 dataimport.properties文件…打开此文件
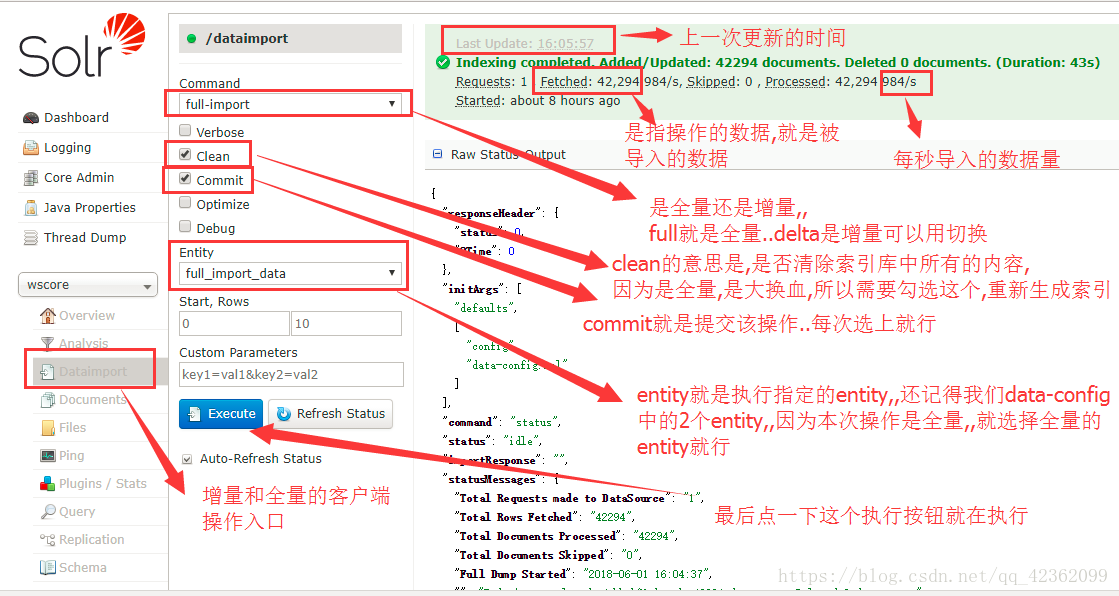
配置好了,就需要我们执行了…看页面截图
全量导入客户端操作
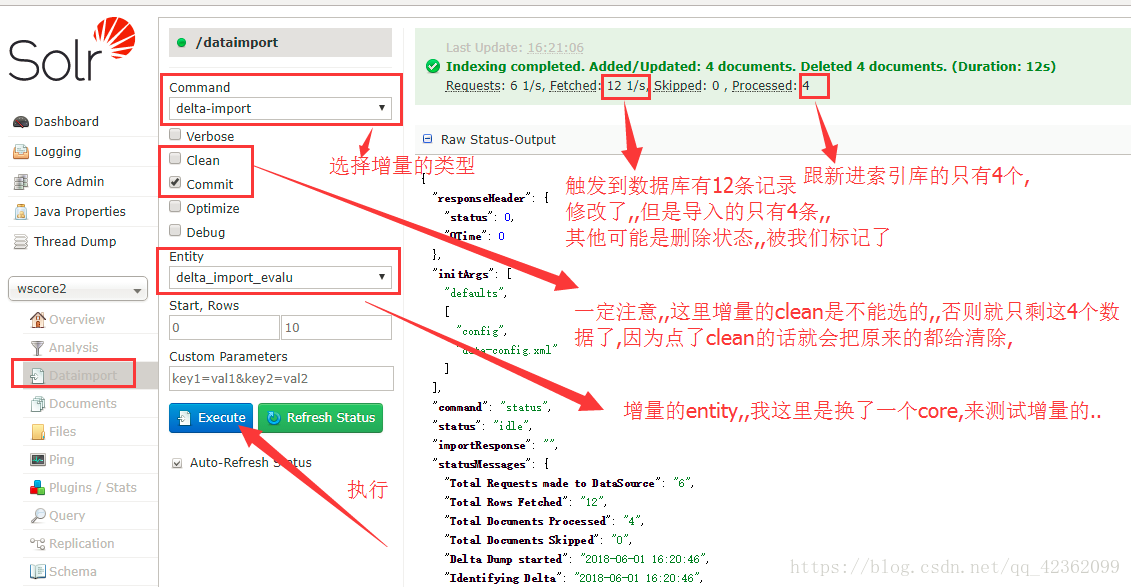
增量的导入操作,如图
我增量和全量中遇到的大BUG
BUG1.solr对于数据库类型为tinyint类型的字段,导入进索引库中会变成Boolean类型的数据…这样导致数据失去原有数值表达的含义,建立的solr索引的也没法使用…如何规避
解决方案
1.更改数据表,将tinyint类型转化为int类型。(不推荐)
2.在DIH获取MySQL数据集通过sql查询时进行类型转换,将查询结果中tinyint类型转换为int类型
MySQL中使用CONVERT(表达式,类型)函数进行类型转换
select convert(is_on_sale,UNSIGNED) as isOnSale,convert(is_delete,UNSIGNED)as isDel,
convert(is_no_show,UNSIGNED)as isNoShow
from .....
BUG2.如果把增量和全量放在一个entity中,全量能执行,增量执行不了,sql其他都是正确的…
解决方案:把分成2个entity,增量一个 全量一个,执行的时候选择指定的…
就像我上面传的data-config.xml中的2个entity一样,就可以执行了,只要从一个entity分离出来就行了…具体原因不详…
五:定时增量,定时全量
很多人希望定时增量,具体有2中方式…
第一种:solr自带的,定时器,需要配置就行…因为我这个操作过,但都没有成功,所以没法贴出来…(不推荐),不推荐的原因不是自己没有折腾出来,而是会增加solr的性能,一般用的多的人都会选择代码中的定时器来完成这个…
第二种:代码中的定时器来完成…推荐…我写了2中定时器…选择自己合适的就行…
pom.xml中需要的依赖;
<!-- solr -->
<dependency>
<groupId>org.apache.solr</groupId>
<artifactId>solr-solrj</artifactId>
<version>6.6.2</version>
</dependency>
<!-- quartz 定时器-->
<dependency>
<groupId>org.quartz-scheduler</groupId>
<artifactId>quartz</artifactId>
<version>${quartz.version}</version>
</dependency>
<dependency>
<groupId>org.quartz-scheduler</groupId>
<artifactId>quartz-jobs</artifactId>
<version>${quartz.version}</version>
</dependency>
上增量定时器代码: 这个使用的是Spring的定时器
http://localhost:10005/solr/wscore2/dataimport?command=delta-import&entity=delta_import_evalu&clean=false&commit=true 这个地址就是增量的地址,只要访问这个地址就能执行增量操作…所以定时器的任务就是去访问这个地址就行…
首先在web.xml中加上这句话…来监听这个类…所以本应该那个地址(就是增量访问地址)配在配置文件中的,但是,web.xml会首先加载,再去加载配置文件,…所以就只能放在这个被监听的类中了…
<listener>
<listener-class>com.wsmall.solr.quartz.StartupListener4analysisReport</listener-class>
</listener>
上代码:
package com.wsmall.solr.quartz;
import com.wsmall.solr.common.util.HttpClientUtil;
import org.slf4j.LoggerFactory;
import javax.servlet.ServletContextEvent;
import javax.servlet.ServletContextListener;
import java.text.SimpleDateFormat;
import java.util.Date;
import java.util.concurrent.ScheduledThreadPoolExecutor;
import java.util.concurrent.TimeUnit;
/**
* Created by RuGuo on 2018/1/31.
*/
public class StartupListener4analysisReport implements ServletContextListener{
private static final org.slf4j.Logger logger = LoggerFactory.getLogger(StartupListener4analysisReport.class);
//@Value("${solr.data.url}")
private static final String solrDataUrl = "http://localhost:10005/solr/wscore/dataimport";
//@Value("${solr.delta.param.url}")
private static final String solrDeltaUrl ="command=full-import&entity=full_import_data&clean=true&commit=true" ;
//evalu & media "http://localhost:10005/solr/wscore2/dataimport"
private static final String solrEvaluMediaDataUrl = "http://localhost:10005/solr/wscore2/dataimport";
private static final String solrDeltaEvaluUrl = "command=delta-import&entity=delta_import_evalu&clean=false&commit=true";
@Override
public void contextInitialized(ServletContextEvent servletContextEvent) {
servletContextEvent.getServletContext().log("启动线程池");
servletContextEvent.getServletContext().log("启动定时器");
//执行goods增量导入
Runnable runnableDelta = new Runnable() {
public void run() {
// task to run goes here
SimpleDateFormat simpleDateFormat = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
String time=simpleDateFormat.format(new Date());
logger.warn("solr定时增量执行循环**delta**"+ time + "**delta**");
String responseJson = HttpClientUtil.get(solrDataUrl,solrDeltaUrl);
}
};
ScheduledThreadPoolExecutor service = new ScheduledThreadPoolExecutor(5);
//ScheduledExecutorService service = Executors
//.newSingleThreadScheduledExecutor();
//5分钟执行一次增量
service.scheduleAtFixedRate(runnableDelta, 0, 5, TimeUnit.MINUTES);
//service.scheduleAtFixedRate(runnableFull, 0, 7, TimeUnit.MINUTES);
//执行evalu增量导入////////////////////////////////////////////////////////////////////
Runnable runnableDeltaEvalu = new Runnable() {
public void run() {
// task to run goes here
logger.warn("solr定时Evalu增量执行循环**Evalu**"+"**delta**");
String responseJson = HttpClientUtil.get(solrEvaluMediaDataUrl,solrDeltaEvaluUrl);
}
};
ScheduledThreadPoolExecutor serviceEvalu = new ScheduledThreadPoolExecutor(5);
serviceEvalu.scheduleAtFixedRate(runnableDeltaEvalu, 0, 7, TimeUnit.MINUTES);
}
@Override
public void contextDestroyed(ServletContextEvent servletContextEvent) {
servletContextEvent.getServletContext().log("定时器销毁");
}
}
全量导入代码…全量采用的是quartz定时器 上代码
package com.wsmall.solr.quartz;
import com.wsmall.solr.common.util.HttpClientUtil;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Value;
import java.text.SimpleDateFormat;
import java.util.Date;
/**
* Created by RuGuo on 2018/1/25.
*/
public class QuartzFullImport {
private static final org.slf4j.Logger logger = LoggerFactory.getLogger(QuartzFullImport.class);
@Value("${solr.data.url}")
private String solrDataUrl;//同样都是访问地址,,,这个配在配置文件中,,方便管理
@Value("${solr.full.param.url}")
private String solrFullUrl;
配置文件中的:
solr.data.url=http://localhost:10005/solr/wscore/dataimport
solr.full.param.url=command=full-import&entity=full_import_data&clean=true&commit=true
/**
* 定时全量导入
*/
public void work()
{
SimpleDateFormat simpleDateFormat = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
String time =simpleDateFormat.format(new Date());
logger.warn("solr定时全量执行循环//////////////"+ time+"/////////////////");
String responseJson = HttpClientUtil.get(solrDataUrl,solrFullUrl);
}
}
quartz的配置文件
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xmlns:task="http://www.springframework.org/schema/task"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans-3.0.xsd
http://www.springframework.org/schema/context
http://www.springframework.org/schema/context/spring-context-3.0.xsd
http://www.springframework.org/schema/task
http://www.springframework.org/schema/task/spring-task-3.0.xsd">
<!-- 线程执行器配置,用于任务注册 -->
<bean id="executor" class="org.springframework.scheduling.concurrent.ThreadPoolTaskExecutor">
<property name="corePoolSize" value="10" />
<property name="maxPoolSize" value="100" />
<property name="queueCapacity" value="500" />
</bean>
<!-- 任务对象 -->
<bean name="quartzFullImport" class="com.wsmall.solr.quartz.QuartzFullImport" />
<bean name="quartzFullEvaluImport" class="com.wsmall.solr.quartz.QuartzFullEvaluImport" />
<!-- 定时任务 -->
<!-- ============= 调度业务============= -->
<bean id="quartzFullImportTask" class="org.springframework.scheduling.quartz.MethodInvokingJobDetailFactoryBean">
<property name="targetObject" ref="quartzFullImport"></property>
<!-- 调度的方法名 -->
<property name="targetMethod" value="work"></property>
<!-- 如果前一个任务还没有结束第二个任务不会启动 false -->
<property name="concurrent" value="true"></property>
</bean>
<!-- ============= 调度业务============= -->
<bean id="quartzFullEvaluImportTask" class="org.springframework.scheduling.quartz.MethodInvokingJobDetailFactoryBean">
<property name="targetObject" ref="quartzFullEvaluImport"></property>
<!-- 调度的方法名 -->
<property name="targetMethod" value="importFullEvalu"></property>
<!-- 如果前一个任务还没有结束第二个任务不会启动 false -->
<property name="concurrent" value="true"></property>
</bean>
<!--//////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////-->
<!-- 定时任务触发器 -->
<bean id="quartzFullImportTrigger" class="org.springframework.scheduling.quartz.CronTriggerFactoryBean">
<property name="jobDetail" ref="quartzFullImportTask"/>
<!-- 0 30 14 ? * TUE表示每个星期一凌晨3点 MON,TUE,WED,THU,FRI,SAT,SUN-->
<property name="cronExpression" value="0 1 2 ? * *"></property>
</bean>
<bean id="quartzFullEvaluImportTrigger" class="org.springframework.scheduling.quartz.CronTriggerFactoryBean">
<property name="jobDetail" ref="quartzFullEvaluImportTask"/>
<!-- 0 30 10 ? * * 每天早上10点30分触发-->
<property name="cronExpression" value="0 30 10 ? * *"></property>
</bean>
<!-- ============= 调度工厂 ============= -->
<bean name="quartzScheduler" class="org.springframework.scheduling.quartz.SchedulerFactoryBean">
<property name="triggers">
<list>
<ref local="quartzFullImportTrigger" />
<ref local="quartzFullEvaluImportTrigger" />
</list>
</property>
</bean>
</beans>
HttpClientUtil 工具类
package com.wsmall.solr.common.util;
import org.apache.commons.lang3.StringUtils;
import org.apache.http.HttpResponse;
import org.apache.http.HttpStatus;
import org.apache.http.client.HttpClient;
import org.apache.http.client.methods.HttpPost;
import org.apache.http.entity.StringEntity;
import org.apache.http.impl.client.HttpClientBuilder;
import org.apache.http.util.EntityUtils;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.io.BufferedReader;
import java.io.Closeable;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.URL;
import java.net.URLConnection;
/**
* Created by pan on 12/01/2017.
*/
public class HttpClientUtil {
private static final Logger logger = LoggerFactory.getLogger(HttpClientUtil.class);
public static String postWithJson(String url, String jsonValues) {
HttpClient httpClient = HttpClientBuilder.create().build();
try {
HttpPost request = new HttpPost(url);
StringEntity params = new StringEntity(jsonValues);
request.addHeader("content-type", "application/json");
request.setEntity(params);
HttpResponse response = httpClient.execute(request);
return parseResponse(response);
} catch (Exception ex) {
ex.printStackTrace();
return null;
}
}
/**
* // * 向指定url发送get方法的请求 // * // * @param url 发送请求的url // * @param param 请求参数,请求参数应该是 name1=value1&name2=value2 的形式。
* // * @return result 所代表远程资源的响应结果 //
*/
public static String get(String url, String param) {
// 返回结果
String result = "";
BufferedReader in;
in = null;
try {
// url
String urlNameString = url + "?" + param;
URL realUrl = new URL(urlNameString);
// 打开和URL之间的连接
URLConnection connection = realUrl.openConnection();
// 设置通用的请求属性
connection.setRequestProperty("accept", "*/*");
connection.setRequestProperty("connection", "Keep-Alive");
connection.setRequestProperty("user-agent", "Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1;SV1)");
// 建立实际的连接
connection.connect();
// 获取所有响应头字段
// Map<String, List<String>> map = connection.getHeaderFields();
// 遍历所有的响应头字段
/*
* for (String key : map.keySet()) { System.out.println(key + "--->" + map.get(key)); }
*/
// 定义 BufferedReader输入流来读取URL的响应
in = new BufferedReader(new InputStreamReader(connection.getInputStream(), "utf-8"));
String line;
while ((line = in.readLine()) != null) {
result += line;
}
} catch (Exception e) {
logger.error(e.getMessage(), e);
}
// 使用finally块来关闭输入流
finally {
close(in);
}
// 如果外部接口返回为空,返回其他错误原因
if (StringUtils.isBlank(result)) {
result = "{\"result\":\"other error\"}";
}
return result;
}
/**
* 将服务器返回的数据包装成为String
*
* @param response
* @return
* @throws IOException
*/
private static String parseResponse(HttpResponse response) throws IOException {
int statusCode = response.getStatusLine().getStatusCode();
if (statusCode != HttpStatus.SC_OK) {
logger.error("Method failed:" + response.getStatusLine());
}
// Read the response body
return EntityUtils.toString(response.getEntity());
}
/**
* @param closeable
*/
private static void close(Closeable... closeable) {
for (Closeable c : closeable) {
try {
if (c != null) {
c.close();
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
}
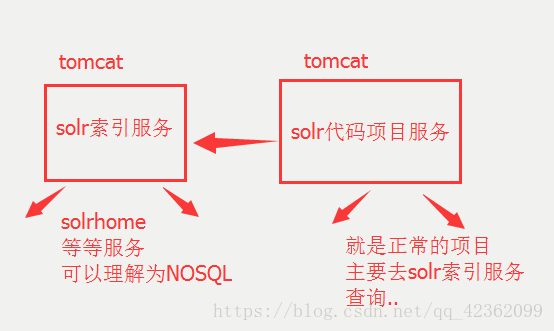
solr查询接口…上代码:
model ------------GoodsVO.java 只截取一部分,有点长…注意value,一会提他的作用
package com.wsmall.solr.pojo.goods.vo;
import org.apache.solr.client.solrj.beans.Field;
import java.io.Serializable;
import java.util.Date;
/**
* Created by RuGuo on 2017/12/7.
*/
public class GoodsVo implements Serializable{
//@Field("id")
//private String id; //索引主键
@Field("goodsId")
private Long goodsId; //商品主键
@Field("goodsSn")
public Long getGoodsId() {
return goodsId;
}
public void setGoodsId(Long goodsId) {
this.goodsId = goodsId;
}
public String getGoodsSn() {
return goodsSn;
}
public void setGoodsSn(String goodsSn) {
this.goodsSn = goodsSn;
}
}
query的代码
solr.url=http://localhost:10005/solr/wscore
@Override
public PageRecords<List<GoodsVo>> query(GoodsQueryParam goodsParam) {
PageRecords<List<GoodsVo>> pageRecords = PageRecords.newByExisted(goodsParam);
try {
SolrClient solr = new HttpSolrClient.Builder(solrUrl).build();
//HttpSolrClient httpSolrClient = SolrUtils.connect();
SolrQuery query = new SolrQuery();
//查询条件
if (StringUtils.isBlank(goodsParam.getSearchkey())) {
query.setQuery("*:*");
} else {
query.setQuery(goodsParam.getSearchkey());
}
//设置默认搜索域
//query.set("df", "keyWords");
if (null != goodsParam.getIsOnSale()){
query.addFilterQuery("isOnSale:"+goodsParam.getIsOnSale());
}
if(null != goodsParam.getIsNoShow()){
query.addFilterQuery("isNoShow:"+goodsParam.getIsNoShow());
}
if(null != goodsParam.getPlatType()){
query.addFilterQuery("platType:"+goodsParam.getPlatType());
}
if(null != goodsParam.getIsSoldOut()){
query.addFilterQuery("isSoldOut:"+goodsParam.getIsSoldOut());
}
if(null != goodsParam.getIsDel()){
query.addFilterQuery("isDel:"+goodsParam.getIsDel());
}else{
query.addFilterQuery("isDel:0");
}
//排序
if(null != goodsParam.getOrderBy()){
if("shopPrice".equals(goodsParam.getOrderBy())){
query.set("sort", "shopPrice "+goodsParam.getSortCat());
}
if("soldNum".equals(goodsParam.getOrderBy())){
query.set("sort", "soldNum "+goodsParam.getSortCat());
}
if("comments".equals(goodsParam.getOrderBy())){
query.set("sort", "comments "+goodsParam.getSortCat());
}
}
//分页开始页数
query.setStart(goodsParam.getBegin());
//设定返回记录数,默认为10条
query.setRows(goodsParam.getRows());
QueryResponse response = solr.query(query);
SolrDocumentList list = response.getResults();
Long recordCount = list.getNumFound();
//Long recordSlipt = 0L;
List<GoodsVo> goodsVoList = null;
if(recordCount!=0){
//还记得model中的字段是为什么有value注解吗?
//作用就体现在这里了,,转换需要到这个注解,,
goodsVoList = response.getBeans(GoodsVo.class);
pageRecords.setRecords(goodsVoList);
pageRecords.setTotalRows(Integer.parseInt(recordCount.toString()));
return pageRecords;
}
} catch (SolrServerException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
return null;
}
分页工具
package com.wsmall.solr.common.db;
import com.wsmall.solr.common.Page;
/**
* Created by pan on 15/11/2016.
*/
public class PageRecords<T> extends Page {
private T records; // 结果集
public PageRecords() {
}
// public PageRecords(int currentPage, int rows) {
// super(currentPage, rows);
// }
public static <A> PageRecords<A> newByExisted(Page formPage) {
PageRecords<A> page = new PageRecords();
page.setCurrentPage(formPage.getCurrentPage());
page.setRows(formPage.getRows());
page.setTotalRows(formPage.getTotalRows());
page.setDisabledCountPage(formPage.isDisabledCountPage());
page.setDisabledPage(formPage.isDisabledPage());
return page;
}
public PageRecords(int currentPage, int rows, int totalRows) {
super(currentPage, rows, totalRows);
}
public T getRecords() {
return records;
}
public void setRecords(T records) {
this.records = records;
}
/**
* 获取统计条数,如若没有禁用统计功能
* @param queryable
*/
public void queryByPage(PageQueryable<T> queryable) {
// 若禁用分页,或者分页查询就跳过count方法
if (!isDisabledPage() && !isDisabledCountPage()) {
// 查询并设置分页
this.setTotalRows(queryable.count());
// 无数据就无须继续往下查询query方法
if (this.getRows() < 1) {
return;
}
}
T t = queryable.query();
setRecords(t);
}
}
page类
package com.wsmall.solr.common;
/**
* Created by zgj on 2015-03-03.
*/
public class Page {
/**
* 查询记录从第几条开始
*/
private int begin = 0;
/**
* 当前页码
*/
private int currentPage = 1;
/**
* 每页记录数
*/
private int rows = 10;
/**
* 总页数
*/
private int totalPages = 0;
/**
* 总记录数
*/
private int totalRows = 0;
private boolean disabledCountPage = Boolean.TRUE;
private boolean disabledPage;
public Page() {
}
public Page(int currentPage, int rows) {
this.currentPage = currentPage;
this.rows = rows;
this.begin = (currentPage - 1) * rows;
}
public Page(int currentPage, int rows, int totalRows) {
this(currentPage, rows);
setTotalRows(totalRows);
}
public int getCurrentPage() {
return currentPage;
}
public void setCurrentPage(Integer currentPage) {
if (currentPage != null) {
this.currentPage = Math.max(currentPage, 1);
this.begin = (this.currentPage - 1) * rows;
}
}
public int getRows() {
return rows;
}
public void setRows(Integer rows) {
if (rows != null) {
this.rows = rows;
}
setCurrentPage(this.currentPage);
}
public int getTotalPages() {
return totalPages;
}
public void setTotalPages(Integer totalPages) {
if (totalPages != null) {
this.totalPages = totalPages;
if (rows > 0 && totalPages > 0) {
this.totalRows = rows * totalPages;
}
}
}
public int getTotalRows() {
return totalRows;
}
public void setTotalRows(Integer totalRows) {
if (totalRows != null) {
this.totalRows = totalRows;
if (rows > 0 && totalRows > 0) {
this.totalPages = (int) (Math.ceil((double) totalRows / rows));
}
}
}
public int getBegin() {
return begin;
}
public void setBegin(Integer begin) {
if (begin != null) {
this.begin = begin;
}
}
public boolean isDisabledPage() {
return disabledPage;
}
public void setDisabledPage(boolean disabledPage) {
this.disabledPage = disabledPage;
}
public boolean isDisabledCountPage() {
return disabledCountPage;
}
public void setDisabledCountPage(boolean disabledCountPage) {
this.disabledCountPage = disabledCountPage;
}
}
如果转载,请说明出处.谢谢.
到此,我能接触的业务就结束了…都是个人自己写的,肯定会有一些不当的地方,还希望海涵,当然指出来多交流…