Tensorflow介绍:
TensorFlow是一个采用数据流图(data flow graphs),用于数值计算的开源软件库。节点(Nodes)在图中表示数学操作,图中的线(edges)则表示在节点间相互联系的多维数据数组,即张量(tensor)。它灵活的架构让你可以在多种平台上展开计算,例如台式计算机中的一个或多个CPU(或GPU),服务器,移动设备等等。
TensorFlow最大的用途是被用于图像识别、语音识别等多项机器学习和深度学习领域。
Tensorflow基础知识:
张量(Tensor):
在TensorFlow中,可以将张量理解为数组。如果是0阶张量,那么将代表这个张量是一个标量,也就是一个数字,如果是一阶张量可以理解为向量或者是一维数组,n阶张量可以理解为n维的数组。
如:

要注意的是TensorFlow张量的实现并没有直接采用数组的形式,张量它只是对运算结果的引用,TensorFlow的张量和numpy的数组是不一样的,TensorFlow的计算结果不是一个数组而是一个张量的结构形式,在这个张量中,它包含了三个重要的属性,名字、维度、类型。
如:
import tensorflow as tf
import numpy as np
if __name__ == "__main__":
a = tf.constant([1.0,2.0],name="a")
b = tf.constant([2.0,3.0],name="b")
result = tf.add(a,b,name="add")
# a,b,result是三个张量,其中result是a和b相加而成
print(result)
# 打印结果为Tensor("add:0", shape=(2,), dtype=float32),即张量的三个属性:名字、维度、类型
# “add:0”代表的是计算节点"add"的第一个输出结果(编号都是从0开始)
# shape=(2,)代表张量是一个二维数组
np_a = np.array([1.0,2.0])
np_b = np.array([2.0,3.0])
np_result = np_a + np_b
print(np_result)
# 打印结果为矩阵中对应元素相加的结果运行结果如下:
Tensor("a:0", shape=(2,), dtype=float32)
Tensor("b:0", shape=(2,), dtype=float32)
Tensor("add:0", shape=(2,), dtype=float32)
[3. 5.]当计算图构造完成之后,可以通过张量来获取计算的结果,需要配合使用Session。
Session(会话):
用来执行定义好的运算,而且会话拥有和管理程序运行时的所有资源。当计算完成之后,需要通过关闭会话来帮助系统回收资源,否则可能导致资源泄露的问题。
在TensorFlow中使用会话有两种方式:第一种需要明确调用会话生成函数和关闭会话函数;第二种则由TensorFlow提供通过python的上下文管理器来使用会话。
如:
import tensorflow as tf
matrix1 = tf.constant([[3, 3]])
# 创建一个1行,2列的矩阵
matrix2 = tf.constant([[2], [2]])
# 创建一个2行,1列的矩阵
# 下面我们要做矩阵乘法
product = tf.matmul(matrix1, matrix2)
# 第一种用会话的形式
# sess = tf.Session()
# result = sess.run(product)
# print(result)
# sess.close()
# 第一种方法必须记得要close
# 第二种会话形式
with tf.Session() as sess:
# 打开一个以sess命名的Session
result2 = sess.run(product)
print(result2)
# 运行完with里的语句后自动关闭这个Session运行结果如下:
2018-09-30 20:32:03.984379: I tensorflow/core/platform/cpu_feature_guard.cc:141] Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX AVX2
2018-09-30 20:32:03.986379: I tensorflow/core/common_runtime/process_util.cc:69] Creating new thread pool with default inter op setting: 8. Tune using inter_op_parallelism_threads for best performance.
[[12]]要去除上面两行警告,只需要在程序代码最前面加上两行:
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'TensorFlow还提供了一种ConfigProto函数来配置生成的会话。
如:
config = tf.ConfigProto(allow_soft_placement=True,log_device_placement=True)
sess1 = tf.InteractiveSession(config=config)
sess2 = tf.Session(config=config)通过ConfigProto()函数,可以配置会话并行的线程数、GPU的分配策略、运算超时等参数。最常用的就是上面配置的两个参数。
第一个就是allow_soft_placement,这是一个bool类型的参数,当它设置为True的时候,满足下面的任意一个条件的时候,GPU上的运算可以放到CPU上进行:
1、运算无法在GPU上执行。
2、没有GPU资源(电脑上不存在GPU设备或者,指定程序在第二个GPU上运行,但是机器只有一个GPU)。
3、运算输入包含对CPU计算结果的引用。
allow_soft_placement参数默认设置为False,为了增强代码的可移植性,在有GPU的情况下一般都会将其设置为True。
第二个参数log_device_placement,也是一个bool类型的参数,当它设置为True的时候日志将会记录每个节点被安排了在哪个设备上运行。一般,在生产环境中将这个参数设置为False,以减少日志的输出。
数据流图(Dataflow Graph):
数据流图是由节点(nodes)和线(edges)构成的有向图:
节点(nodes) 表示计算单元,也可以是输入的起点或者输出的终点;
线(edges) 表示节点之间的输入/输出关系。
在 TensorFlow 中,每个节点都是用 tf.Tensor的实例来表示的,即每个节点的输入、输出都是Tensor。
上面介绍的是 TensorFlow 和 Graph 的概念,下面介绍怎么用 Tensor 构建 Graph。
变量(Variable):
在 Tensorflow 中,定义了某字符串是变量,它才是变量,这一点是与 Python 所不同的。
定义语法:
state = tf.Variable()
举一个例子:
import os
import tensorflow as tf
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
# 解决警告:Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX AVX2
state = tf.Variable(0, name='counter')
# 定义变量state
print(state.name)
one = tf.constant(1)
# 定义常量one
new_value = tf.add(state, one)
# 定义加法,注意这里还没有开始计算
update = tf.assign(state, new_value)
# 把state更新成new_value
# 在Tensorflow中设定了变量后一定要初始化
init = tf.global_variables_initializer()
# 初始化后变量还没有被激活,要创建session后才能激活
with tf.Session() as sess:
sess.run(init)
for _ in range(3):
sess.run(update)
print(sess.run(state))运行结果如下:

Placeholder:
如果我们想创建两个Tensor,但这两个Tensor的值需要从外部输入,这时我们可以用tf.placeholder 创建占位 Tensor,占位 Tensor 的值可以在运行的时候输入。
如:
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
# 解决警告:Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX AVX2
import tensorflow as tf
import tensorflow as tf
# 创建两个占位 Tensor 节点
node1 = tf.placeholder(tf.float32)
node2 = tf.placeholder(tf.float32)
# 创建一个 adder 节点,对上面两个节点执行 + 操作
adder = node1 + node2
# 打印三个节点
print(node1)
print(node2)
print(adder)
# 运行一下,后面的 dict 参数是为占位 Tensor 提供输入数据
sess = tf.Session()
print(sess.run(adder, {node1: 3, node2: 4.5}))
print(sess.run(adder, {node1: [1, 3], node2: [2, 4]}))运行结果如下:

构建和执行计算图:
TensorFlow采用数据流图(data flow graphs)来计算,所以首先我们得创建一个数据流流图,然后再将我们的数据(以张量(tensor)的形式存在)放在数据流图中计算。
如:
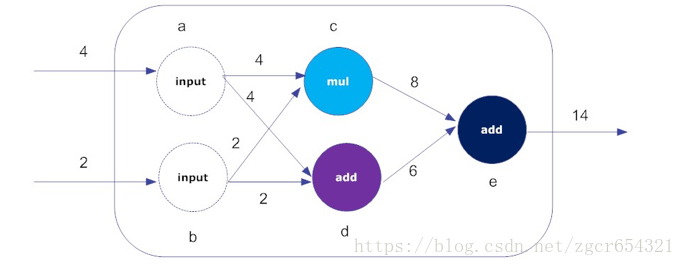
节点(Nodes)在图中表示数学操作。
图中的线(edges)则表示在节点间相互联系的多维数据数组, 即张量(tensor)。
训练模型时tensor会不断的从数据流图中的一个节点flow到另一节点,这就是TensorFlow名字的由来。
如:
import os
import tensorflow as tf
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
# 解决警告:Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX AVX2
a = tf.constant(4, name="input_a")
b = tf.constant(2, name="input_b")
c = tf.multiply(a, b, name="mul_c")
d = tf.add(a, b, name="add_d")
e = tf.add(c, d, name="add_e")
# 创建图上五个节点
sess = tf.Session()
# 会话负责管理协调整个数据流图的计算过程
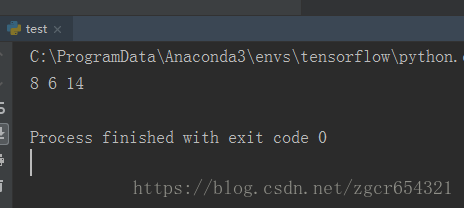
print(sess.run(c), sess.run(d), sess.run(e))
# 打印计算结果
sess.close()运行结果如下:
总结:TensorFlow的工作流程
构建一个计算图。图中的节点可以是TensorFlow支持的任何数学操作;
初始化变量。将前期定义的变量赋初值;
创建一个会话。这才是图计算开始的地方,也是体现它“惰性”的地方,也就是说,仅仅构建一个图,这些图不会自动执行计算操作,而是还要显式提交到一个会话去执行,也就是说,它的执行,是滞后的;
在会话中运行图的计算。把编译通过的合法计算流图传递给会话,这时张量(tensor)才真正“流动(flow)”起来;
关闭会话。当整个图无需再计算时,则关闭会话,以回收系统资源。
Tensorflow训练一个线性回归模型:
import os
import tensorflow as tf
import numpy as np
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
# 解决警告:Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX AVX2
# 创造一些数据
x_data = np.random.random(100).astype(np.float32)
y_data = x_data * 0.1 + 0.3
# 我们用tf.Variable 来创建描述 y 的参数
# 我们可以把 y_data = x_data*0.1 + 0.3 想象成 y=Weights * x + biases
# 然后神经网络也就是学着把 Weights 变成 0.1, biases 变成 0.3.
Weights = tf.Variable(tf.random_uniform([1], -1.0, 1.0))
# Variables是计算图中的某类节点(node),一般是参数变量。
# random_uniform随机均匀分布,-1.0和1.0是最大和最小值范围
biases = tf.Variable(tf.zeros([1]))
# biases初始为0
y = Weights * x_data + biases
loss = tf.reduce_mean(tf.square(y - y_data))
# reduce_mean求平均值
optimizer = tf.train.GradientDescentOptimizer(0.5)
# 建立误差优化器optimizer,0.5是学习效率,一般为不大于1的数
train = optimizer.minimize(loss)
# optimizer用来反向传递误差, 误差传递方法是梯度下降法: Gradient Descent
# 然后我们使用optimizer来进行参数的更新
# 这样tensorflow的结构就搭建好了
init = tf.global_variables_initializer()
# 初始化所有变量和结构的函数
sess = tf.Session()
sess.run(init)
# 创建一个会话,并激活init,即初始化并激活了整个结构
# 训练201次
for step in range(201):
sess.run(train)
if step % 20 == 0:
print(step, sess.run(Weights), sess.run(biases))
#每训练20次,打印Weights和biases的训练结果运行结果如下:
0 [0.00278392] [0.48985556]
20 [0.06680065] [0.31798247]
40 [0.09287401] [0.3038598]
60 [0.09847047] [0.3008285]
80 [0.09967171] [0.30017784]
100 [0.09992956] [0.30003816]
120 [0.09998487] [0.3000082]
140 [0.09999678] [0.30000177]
160 [0.09999933] [0.30000037]
180 [0.09999985] [0.3000001]
200 [0.09999991] [0.30000007]