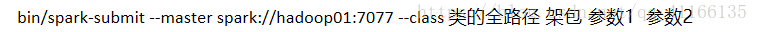Spark递交任务原理
类似于Yarn调度任务的过程
-
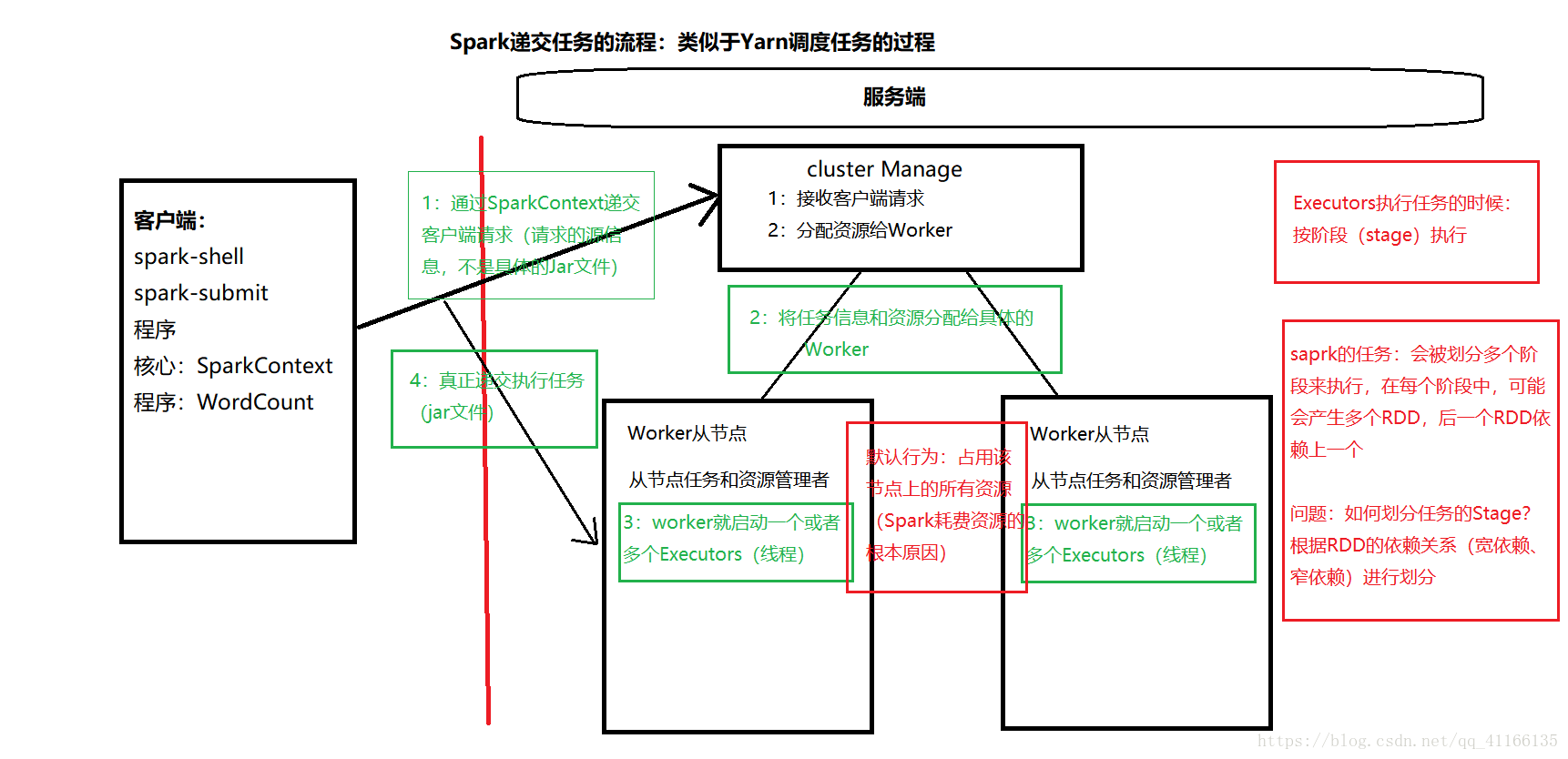
首先得客户端提交请求
核心是SparkContext,通过SparkContext递交客户端请求(请求的源文件信息(描述数据的数据),不是具体的jar文件) -
服务端接收客户端请求,分配资源给Worker
将任务信息和资源分配给具体的Worker -
这时候Worker从节点(从节点任务和资源管理者),就启动一个或者多个Executors(线程)
-
启动完之后客户端直接和Worker对接,递交执行任务
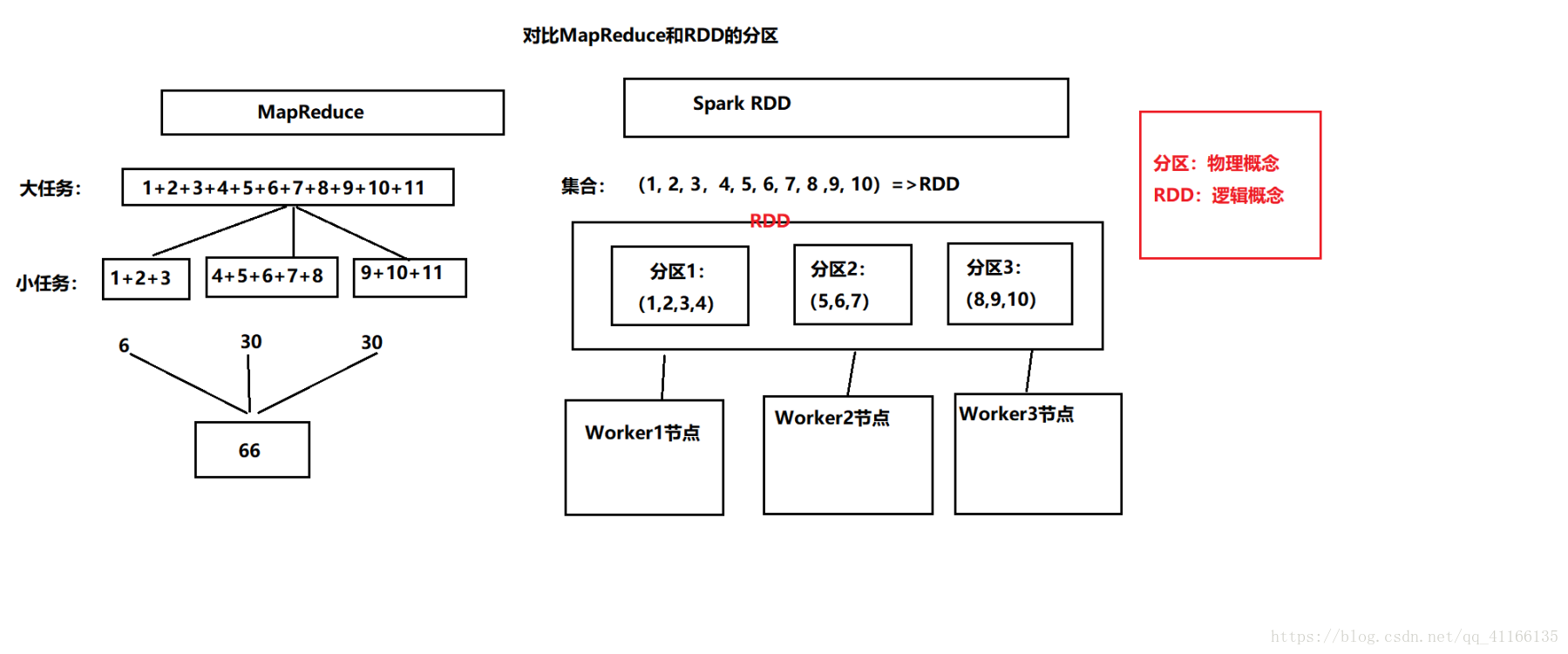
**需要注意的是:
线程执行任务的时候按阶段执行
spark任务会被划分成多个阶段来执行,在每个阶段中,可能会产生多个RDD,后一个RDD依赖上一个(通过宽依赖和窄依赖)进行划分
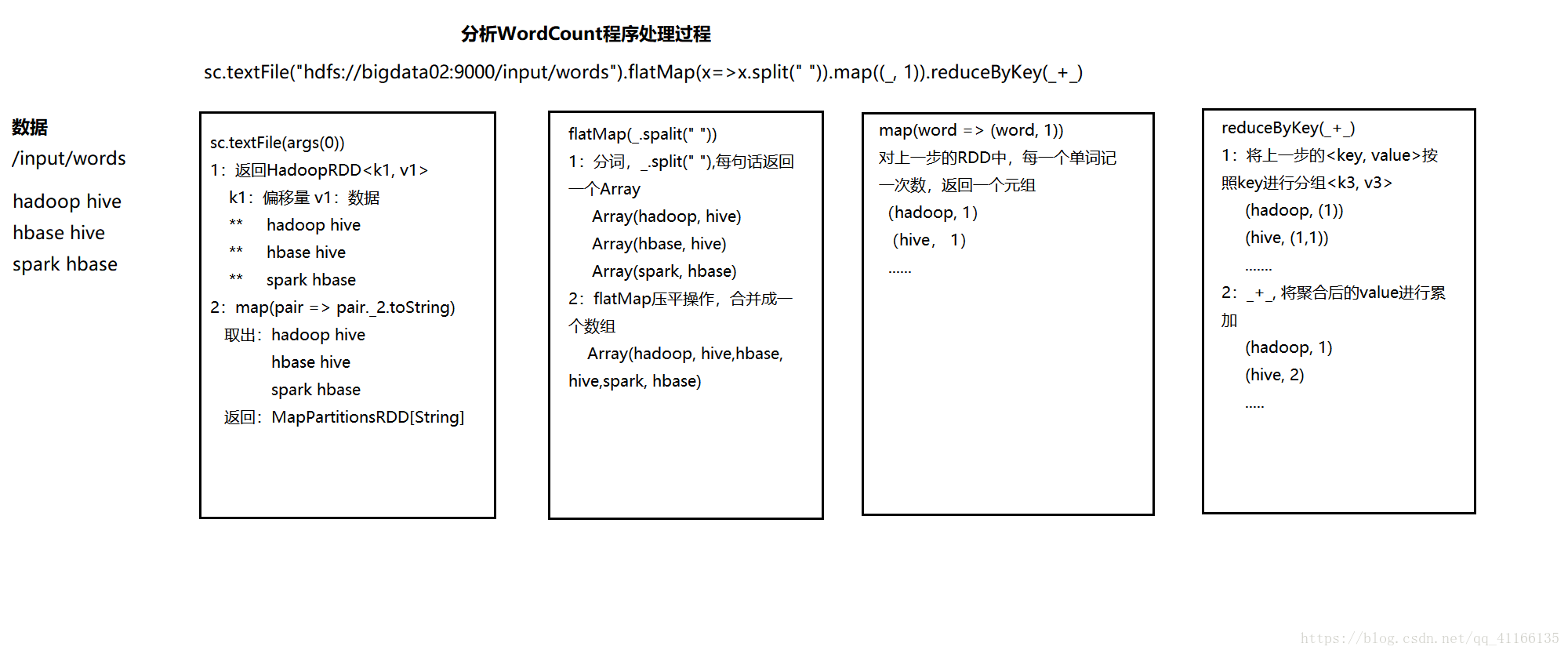
经典案例WordCount
- shell端运行,必须HDFS上面有文件。
运行结果
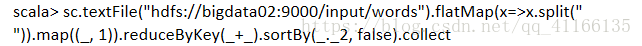


2.在IDEA上用SCALA写
package day02
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
/**
-
这是一个scala版本的Spark词频统计程序
-
Created by zhangjingcun on 2018/9/17 16:01.
*/
object ScalaWordCount {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName(“ScalaWordCount”)
//SparkContext,是Spark程序执行的入口
val sc = new SparkContext(conf)//通过sc指定以后从哪里读取数据
//RDD弹性分布式数据集,一个神奇的大集合
val lines: RDD[String] = sc.textFile(args(0))//将内容分词后压平
val words: RDD[String] = lines.flatMap(_.split(" "))//将单词和1组合到一起
val wordAndOne: RDD[(String, Int)] = words.map((_, 1))//分组聚合
val reduce: RDD[(String, Int)] = wordAndOne.reduceByKey(+)//排序
val sorted = reduce.sortBy(_._2, false)//保存结果
sorted.saveAsTextFile(args(1))//释放资源
sc.stop()
}
}
3.JAVA写
package day02;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.PairFunction;
import scala.Tuple2;
import java.util.Arrays;
import java.util.Iterator;
import java.util.List;
/**
-
@program: hello.spark
-
@description: JAVA的词频统计
-
本地模式
-
@author: Hailong
-
@create: 2018-09-17 20:58
**/
public class JavaWordCount {
public static void main(String[] args) {
SparkConf conf = new SparkConf().setAppName(“JavaWordCount”).setMaster(“local[2]”);//创建SparkContext,是Spark应用程序的入口 JavaSparkContext jsc = new JavaSparkContext(conf); //指定以后从那里读取数据 JavaRDD<String> lines = jsc.textFile("D:\\data\\in\\index\\b.txt"); //分词压平 JavaRDD<String> words = lines.flatMap(new FlatMapFunction<String, String>() { @Override public Iterator<String> call(String line) throws Exception { return Arrays.asList(line.split(" ")).iterator(); } }); //将单词和1组合到一起 JavaPairRDD<String,Integer> wordAndOne = words.mapToPair(new PairFunction<String, String, Integer>() { @Override public Tuple2<String, Integer> call(String word) throws Exception { return new Tuple2<>(word,1); } }); //分组聚合 JavaPairRDD<String,Integer> reduce = wordAndOne.reduceByKey(new Function2<Integer, Integer, Integer>() { @Override public Integer call(Integer v1, Integer v2) throws Exception { return v1+v2; } }); //将key和value的顺序颠倒(颠倒目的为了排序) JavaPairRDD<Integer,String> swaped = reduce.mapToPair(new PairFunction<Tuple2<String, Integer>, Integer, String>() { @Override public Tuple2<Integer, String> call(Tuple2<String, Integer> tp) throws Exception { return tp.swap(); } }); //排序 JavaPairRDD<Integer,String> sorted = swaped.sortByKey(false); //将key和和value顺序颠倒(颠倒目的为了排序) JavaPairRDD<String, Integer> result = sorted.mapToPair(new PairFunction<Tuple2<Integer, String>, String, Integer>() { @Override public Tuple2<String, Integer> call(Tuple2<Integer, String> tp) throws Exception { return tp.swap(); } }); //触发一个计算,并且输出到屏幕 List<Tuple2<String,Integer>> finalResult = result.collect(); //输出到某个路径 for (Tuple2<String,Integer> r:finalResult ) { System.out.println(r._1+" "+r._2); } //释放资源 jsc.stop();}
}
4.JAVA函数式语言
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import scala.Tuple2;
import java.util.Arrays;
/**
-
@program: HelloSparkNew
-
@description: Lambda版的WC
-
@author: Hailong
-
@create: 2018-09-18 09:05
**/
public class JavaLambdaWC {
public static void main(String[] args) {
SparkConf conf = new SparkConf().setAppName(“JavaLambdaWC”);JavaSparkContext jsc = new JavaSparkContext(conf); //以后从来数据 JavaRDD<String> lines = jsc.textFile(args[0]); //切分压平 JavaRDD<String> words = lines.flatMap(line -> Arrays.asList(line.split(" ")).iterator()); //将每个单词记一次数 JavaPairRDD<String, Integer> wordAndOne = words.mapToPair(w -> new Tuple2<>(w, 1)); //分组聚合 JavaPairRDD<String, Integer> reduce = wordAndOne.reduceByKey((x, y) -> x + y); //因为必须使用key排序,所以需要交换一下key、value的位置 reduce.mapToPair(tp -> tp.swap()); reduce.sortByKey(); reduce.mapToPair(tp -> tp.swap()); reduce.saveAsTextFile(args[1]); //释放资源 jsc.stop();}
}
5.***重点---->如何运行,
将程序打成jar包

解释: