Python函数:
Python提供了许多内建函数,比如print()。你也可以自己创建函数,这叫用户自定义函数。
定义函数:
Python中,定义一个函数要使用def语句,依次写出函数名、括号、括号中的参数和冒号:,然后,在缩进块中编写函数体,函数的返回值用return语句返回。函数执行完毕也没有return语句时,自动return None。函数可以同时返回多个值,但其实返回的是一个元组(tuple)。
如:
def my_abs(x):
if x >= 0:
return x
else:
return -x默认情况下,参数值和参数名称是按函数声明中定义的顺序匹配起来的。
空函数:
如果想定义一个什么事也不做的空函数,可以用pass语句:
def nop():
pass
pass可以用来作为占位符,比如现在还没想好怎么写函数的代码,就可以先放一个pass,让代码能运行起来。
pass还可以用在其他语句里,比如:
if age >= 18:
pass
缺少了pass,代码运行就会有语法错误。
匿名函数:
python中使用 lambda 来创建匿名函数。
所谓匿名就是不再使用 def 语句这样标准的形式定义一个函数。
lambda的主体是一个表达式,而不是一个代码块。我们仅仅能在lambda表达式中封装有限的逻辑进去。
lambda 函数拥有自己的命名空间,且不能访问自己参数列表之外或全局命名空间里的参数。
注意:
lambda函数不等同于C或C++的内联函数,后者的目的是调用小函数时不占用栈内存从而增加运行效率。
lambda函数的形式:
lambda [arg1 [,arg2,.....argn]]:expression
如:
>>> list(map(lambda x: x * x, [1, 2, 3, 4, 5, 6, 7, 8, 9]))
[1, 4, 9, 16, 25, 36, 49, 64, 81]关键字lambda表示匿名函数,冒号前面的x表示函数参数。
注意:
匿名函数有个限制,就是只能有一个表达式,不用写return,返回值就是该表达式的结果。匿名函数没有名字,所以不必担心函数名冲突。此外,匿名函数也是一个函数对象,也可以把匿名函数赋值给一个变量,再利用变量来调用该函数。同样,也可以把匿名函数作为返回值返回。
如:
>>> f = lambda x: x * x
>>> f
<function <lambda> at 0x101c6ef28>
>>> f(5)
25
def build(x, y):
return lambda: x * x + y * y函数的参数:
在Python中定义函数,可以用必选参数、默认参数、可变参数、关键字参数和命名关键字参数,这5种参数都可以组合使用。参数定义的顺序必须是:必选参数、默认参数、可变参数、命名关键字参数和关键字参数。
命名关键字参数:
函数的调用者可以传入任意不受限制的关键字参数。至于到底传入了哪些,就需要在函数内部通过kw检查。
以person()函数为例,我们希望检查是否有city和job参数:
def person(name, age, **kw):
if 'city' in kw:
# 有city参数
pass
if 'job' in kw:
# 有job参数
pass
print('name:', name, 'age:', age, 'other:', kw)
但是调用者仍可以传入不受限制的关键字参数:
>>> person('Jack', 24, city='Beijing', addr='Chaoyang', zipcode=123456)
如果要限制关键字参数的名字,就可以用命名关键字参数。这种方式定义的函数如下:
def person(name, age, *, city, job):
print(name, age, city, job)
和关键字参数**kw不同,命名关键字参数需要一个特殊分隔符*,*后面的参数被视为命名关键字参数。
调用方式如下:
>>> person('Jack', 24, city='Beijing', job='Engineer')
Jack 24 Beijing Engineer
如果函数定义中已经有了一个可变参数,后面跟着的命名关键字参数就不再需要一个特殊分隔符*。
def person(name, age, *args, city, job):#可变参数*args
print(name, age, args, city, job)
命名关键字参数必须传入参数名,这和位置参数不同。如果没有传入参数名,调用将报错:
>>> person('Jack', 24, 'Beijing', 'Engineer')
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: person() takes 2 positional arguments but 4 were given
由于调用时缺少参数名city和job,Python解释器把这4个参数均视为位置参数,但person()函数仅接受2个位置参数。
命名关键字参数可以有缺省值,从而简化调用。
def person(name, age, *, city='Beijing', job):
print(name, age, city, job)
由于命名关键字参数city具有默认值,调用时,可不传入city参数:
>>> person('Jack', 24, job='Engineer')
Jack 24 Beijing Engineer
使用命名关键字参数时,要特别注意,如果没有可变参数,就必须加一个*作为特殊分隔符。
如果缺少*,Python解释器将无法识别位置参数和命名关键字参数:
def person(name, age, city, job):
# 缺少 *,city和job被视为位置参数
pass
>>> args = (1, 2, 3, 4)
>>> kw = {'d': 99, 'x': '#'}
>>> f1(*args, **kw)
a = 1 b = 2 c = 3 args = (4,) kw = {'d': 99, 'x': '#'}
>>> args = (1, 2, 3)
>>> kw = {'d': 88, 'x': '#'}
>>> f2(*args, **kw)
a = 1 b = 2 c = 3 d = 88 kw = {'x': '#'}
对于任意函数,都可以通过类似func(*args, **kw)的形式调用它,无论它的参数是如何定义的。
注意:
注意定义可变参数和关键字参数的语法:
*args是可变参数,args接收的是一个tuple;
**kw是关键字参数,kw接收的是一个dict。
可变参数既可以直接传入:func(1, 2, 3),又可以先组装list或tuple,再通过*args传入:func(*(1, 2, 3));
关键字参数既可以直接传入:func(a=1, b=2),又可以先组装dict,再通过**kw传入:func(**{'a': 1, 'b': 2})。
使用*args和**kw是Python的习惯写法,当然也可以用其他参数名,但最好使用习惯用法。
命名的关键字参数是为了限制调用者可以传入的参数名,同时可以提供默认值。
定义命名关键字参数在前面没有可变参数的情况下一定要写分隔符*,否则定义的将是位置参数。
函数调用:
Python内置了很多有用的函数,我们可以直接调用。
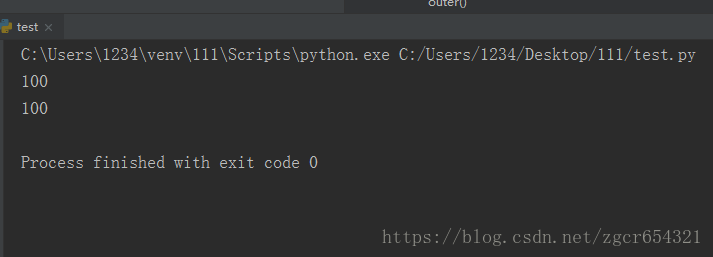
如调用abs函数(求绝对值的函数):
>>> abs(100)
100
>>> abs(-20)
20
>>> abs(12.34)
12.34函数名其实就是指向一个函数对象的引用,完全可以把函数名赋给一个变量,相当于给这个函数起了一个“别名”。
>>> a = abs # 变量a指向abs函数
>>> a(-1) # 所以也可以通过a调用abs函数
1如上面所示,把函数名赋给a后,相当于给函数起了一个别名a,可以直接调用函数的别名a(-1),即相当于调用了abs(-1)。
递归调用:
在函数内部,可以调用其他函数。如果一个函数在内部调用自身本身,这个函数就是递归函数。
如:
计算阶乘n! = 1 x 2 x 3 x ... x n
def fact(n):
if n==1:
return 1
return n * fact(n - 1)使用递归函数需要注意防止栈溢出。在计算机中,函数调用是通过栈(stack)这种数据结构实现的,每当进入一个函数调用,栈就会加一层栈帧,每当函数返回,栈就会减一层栈帧。由于栈的大小不是无限的,所以,递归调用的次数过多,会导致栈溢出。
解决递归调用栈溢出的方法是通过尾递归优化,事实上尾递归和循环的效果是一样的,可以把循环看成是一种特殊的尾递归函数。
尾递归:
在函数返回的时候,调用自身本身,并且,return语句不能包含表达式。这样,编译器或者解释器就可以把尾递归做优化,使递归本身无论调用多少次,都只占用一个栈帧,不会出现栈溢出的情况。
如把上例优化成尾递归函数:
def fact(n):
return fact_iter(n, 1)
def fact_iter(num, product):
if num == 1:
return product
return fact_iter(num - 1, num * product)此时return fact_iter(num - 1, num * product)仅返回递归函数本身,num - 1和num * product在函数调用前就会被计算,不影响函数调用。
事实上,大多数编程语言没有针对尾递归做优化,Python解释器也没有做优化,所以,即使把上面的fact(n)函数改成尾递归方式,也会导致栈溢出。
参数传递:
可更改(mutable)与不可更改(immutable)对象:
python 中,strings, tuples, 和 numbers 是不可更改的对象,而 list,dict 等则是可以修改的对象。
不可变类型:变量赋值 a=5 后再赋值 a=10,这里实际是新生成一个 int 值对象 10,再让 a 指向它,而 5 被丢弃,不是改变a的值,相当于新生成了a。
可变类型:变量赋值 la=[1,2,3,4] 后再赋值 la[2]=5 则是将 list la 的第三个元素值更改,本身la没有动,只是其内部的一部分值被修改了。
python 函数的参数传递:
不可变类型:类似 c++ 的值传递,如 整数、字符串、元组。如fun(a),传递的只是a的值,没有影响a对象本身。比如在 fun(a)内部修改 a 的值,只是修改另一个复制的对象,不会影响 a 本身。
可变类型:类似 c++ 的引用传递,如 列表,字典。如 fun(la),则是将 la 真正的传过去,修改后fun外部的la也会受影响
python 中一切都是对象,严格意义我们不能说值传递还是引用传递,我们应该说传不可变对象和传可变对象。
变量作用域:
Python的作用域一共有4种,分别是:
L (Local) 局部作用域
E (Enclosing) 闭包函数外的函数中
G (Global) 全局作用域
B (Built-in) 内建作用域
以 L –> E –> G –>B 的规则查找,即:在局部找不到,便会去局部外的局部找(例如闭包),再找不到就会去全局找,再者去内建中找。
x = int(2.9) # 内建作用域
g_count = 0 # 全局作用域
def outer():
o_count = 1 # 闭包函数外的函数中
def inner():
i_count = 2 # 局部作用域Python 中只有模块(module),类(class)以及函数(def、lambda)才会引入新的作用域,其它的代码块(如 if/elif/else/、try/except、for/while等)是不会引入新的作用域的,也就是说这些语句内定义的变量,外部也可以访问。
如:
>>> if True:
... msg = 'I am from Runoob'
...
>>> msg
'I am from Runoob'
>>> msg 变量定义在 if 语句块中,没有引用新作用域,其作用域等同于外面一层的局部作用域,外部可以访问。
如果将 msg 定义在函数中,则它就是局部变量,外部不能访问:
>>> def test():
... msg_inner = 'I am from Runoob'
...
>>> msg_inner
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
NameError: name 'msg_inner' is not defined
>>> 全局变量和局部变量的区别:
定义在函数内部的变量拥有一个局部作用域,定义在函数外的拥有全局作用域。局部变量只能在其被声明的函数内部访问,而全局变量可以在整个程序范围内访问。调用函数时,所有在函数内声明的变量名称都将被加入到作用域中。
global 和 nonlocal关键字:
当函数在局部作用域内想修改全局作用域的变量时,就要用到global关键字。
如修改全局变量 num:
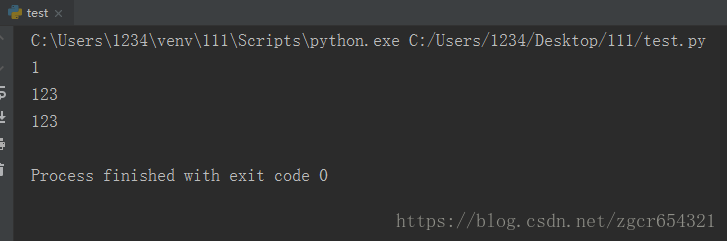
num = 1
def fun1():
global num # 需要使用 global 关键字声明
print(num)
num = 123
print(num)
fun1()
print(num)运行截图如下:
如果要修改嵌套作用域(闭包函数外的函数中作用域,即外层非全局作用域)中的变量则需要 nonlocal 关键字。
如:
def outer():
num = 10
def inner():
nonlocal num # nonlocal关键字声明
num = 100
print(num)
inner()
print(num)
outer()运行截图如下: