这是最近看生成模型的first paper:
摘要:PixelCNN在自然图像的密度评估中获得了最先进的结果。尽管训练速度很快,但推理成本高昂,需要每个像素进行一次网络评估;对于N pixel 的图像需要O(N)的复杂度。虽然这可以通过缓存激活来加快速度,但仍然需要生成每个像素的序列。在这项工作中,我们提出了一个可以并行化的PixelCNN,它允许通过对某些像素组进行建模,使其成为条件独立的。我们新的PixelCNN模型实现了有竞争力的密度估计和大小加速-O(logN)采样,而不是O(N)-支持512x512图像的实际应用。我们评估了某类条件图像生成、文本到图像合成和动作条件视频生成的模型,表明我们的模型在非像素-自回归的模型中获得了最好的结果,并且这些模型允许特定的采样。
理想情况下,我们可以并行地生成多个像素,这将大大加快采样速度。在自回归的框架中,只有当像素间是独立时,这才起作用。因此,我们需要一种方法来明智地打破像素之间的弱相关性;例如,与之相关的相邻像素不应该被建模为依赖于相关性因为它们往往是高度相关的。
在这项工作中,我们展示了PixelCNN中很大一部分空间依赖关系是如何被削减的,在性能上只会有适度的退化。我们在O(logN)的时间内对N个像素进行了抽样,而不是像原来的PixelCNN那样的O(N),在实践中导致了数量级的加速。在视频的例子中,我们可以访问高分辨率的前帧,我们甚至可以在O(1)时间内进行采样,性能比比较快的基线要好得多。
下图展示了模型思路:
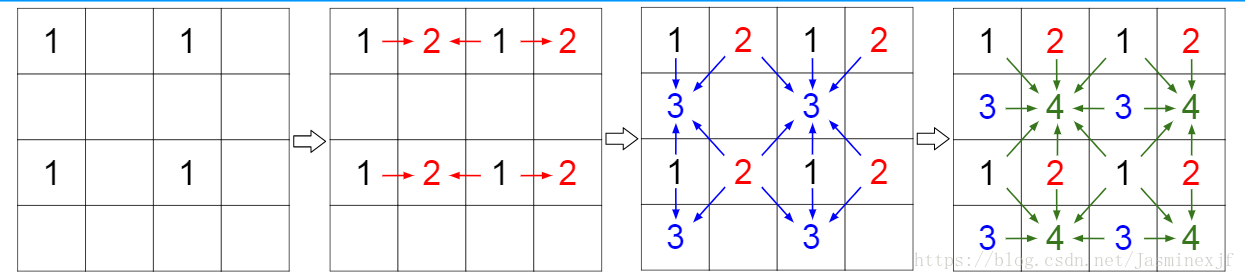
上图:示例是对于4x4的图像进行像素分组。左上角是第1组,右上组2,以此类推。为了清晰起见,我们只使用箭头来表示紧邻的依赖关系,但是注意前面组中的所有像素都可以用来预测给定组中的所有像素。例如,组2中的所有像素都可以用来预测第4组中的像素。在我们的图像实验中,第一组的像素来自于一个低分辨率的图像。对于视频,它们是根据前面的帧生成的。(即一个组里的像素点是相互独立的)------独立集划分。
实验:
1.Text and location-conditional generation
2.Action-conditional video generation
3.Class-conditional generation
自己总结:在本文之前已有pixelRNN,pixelCNN, gated pixelCNN等自回归模型用于生成模型,从第一个的 速度慢改进到可以并行运算的pixel CNN(mask A and mask B),但是其又有盲点问题(Blind spot);所以引入两种不同的掩膜方式:horizontical stack and vertical stack,从而解决了Blind spot问题。本文在此基础上,为了更快的提高速度,引入了多尺度自回归并行密度估计模型:将每张图片的像素值进行分组成独立group,在每个这个group里面,其像素值是相互独立的,所以一个group里面的像素值可以同时并行计算。然后前一个group里的像素值可以用于生成后面group的像素值(如Figure 2 所示)