TensorFlow
tensorflow 技术学习:
https://blog.csdn.net/freewebsys/article/category/6872378
1,关于gpu
https://blog.csdn.net/freewebsys/article/details/81276120
上次在windows上面安装了gpu的版本。还没有体会到这个速度。
找了个网站学习下 gpu的计算速度。
速度还是杠杠的。
我的电脑是 thinkpad的 t470 看到检测的显卡是:
name: GeForce 940MX major: 5 minor: 0 memoryClockRate(GHz): 1.189
pciBusID: 0000:02:00.0
totalMemory: 2.00GiB freeMemory: 1.66GiB2,查看gpu 型号
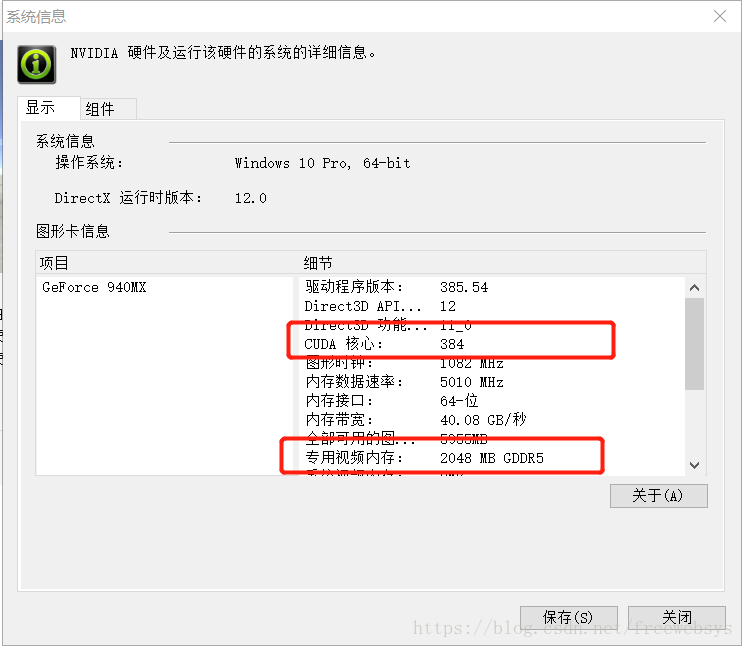
cuda 有384 个核心。内存 2G。
https://www.geforce.cn/hardware/notebook-gpus/geforce-940mx/specifications
https://www.geforce.cn/notebook-gpus-specifications
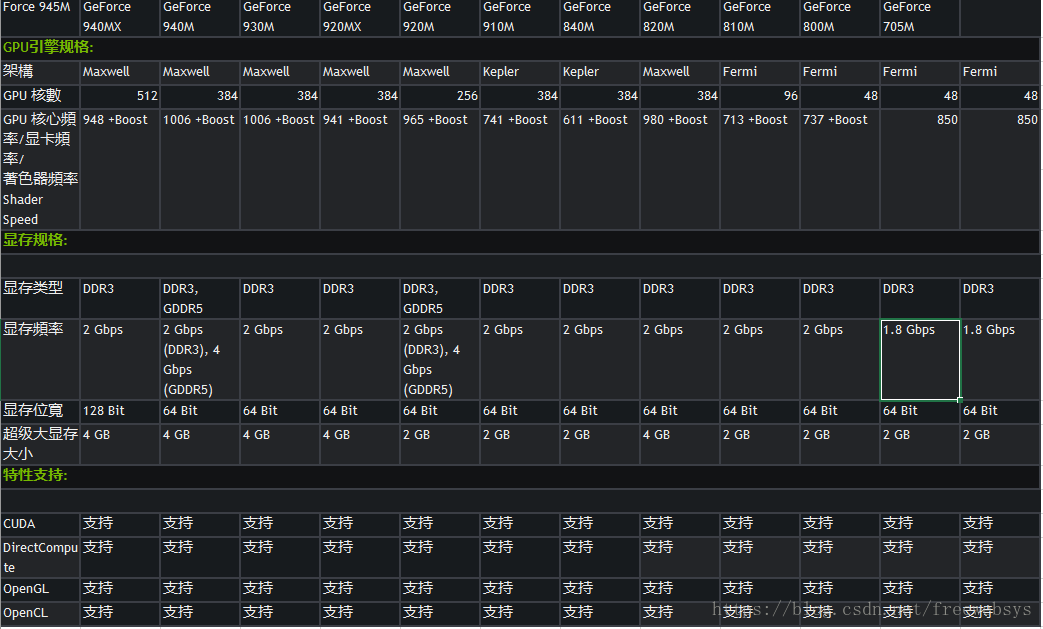
显卡是2G的,支持cuda 才行呢。
在本机电脑就能跑tensorflow了。
3,测试gpu
有个学习网站:
https://learningtensorflow.com/lesson10/
代码如下:
import sys
import numpy as np
import tensorflow as tf
from datetime import datetime
device_name = sys.argv[1] # Choose device from cmd line. Options: gpu or cpu
shape = (int(sys.argv[2]), int(sys.argv[2]))
if device_name == "gpu":
device_name = "/gpu:0"
else:
device_name = "/cpu:0"
with tf.device(device_name):
random_matrix = tf.random_uniform(shape=shape, minval=0, maxval=1)
dot_operation = tf.matmul(random_matrix, tf.transpose(random_matrix))
sum_operation = tf.reduce_sum(dot_operation)
startTime = datetime.now()
with tf.Session(config=tf.ConfigProto(log_device_placement=True)) as session:
result = session.run(sum_operation)
print(result)
# It can be hard to see the results on the terminal with lots of output -- add some newlines to improve readability.
print("\n" * 5)
print("Shape:", shape, "Device:", device_name)
print("Time taken:", datetime.now() - startTime)
print("\n" * 5)详细日志:
python .\demo01.py gpu 1500
2018-07-29 23:45:53.521707: I T:\src\github\tensorflow\tensorflow\core\platform\cpu_feature_guard.cc:141] Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX2
2018-07-29 23:45:54.093709: I T:\src\github\tensorflow\tensorflow\core\common_runtime\gpu\gpu_device.cc:1392] Found device 0 with properties:
name: GeForce 940MX major: 5 minor: 0 memoryClockRate(GHz): 1.189
pciBusID: 0000:02:00.0
totalMemory: 2.00GiB freeMemory: 1.66GiB
2018-07-29 23:45:54.109284: I T:\src\github\tensorflow\tensorflow\core\common_runtime\gpu\gpu_device.cc:1471] Adding visible gpu devices: 0
2018-07-29 23:45:55.044900: I T:\src\github\tensorflow\tensorflow\core\common_runtime\gpu\gpu_device.cc:952] Device interconnect StreamExecutor with strength 1 edge matrix:
2018-07-29 23:45:55.055221: I T:\src\github\tensorflow\tensorflow\core\common_runtime\gpu\gpu_device.cc:958] 0
2018-07-29 23:45:55.061725: I T:\src\github\tensorflow\tensorflow\core\common_runtime\gpu\gpu_device.cc:971] 0: N
2018-07-29 23:45:55.070524: I T:\src\github\tensorflow\tensorflow\core\common_runtime\gpu\gpu_device.cc:1084] Created TensorFlow device (/job:localhost/replica:0/task:0/device:GPU:0 with 1422 MB memory) -> physical GPU (device: 0, name: GeForce 940MX, pci bus id: 0000:02:00.0, compute capability: 5.0)
Device mapping:
/job:localhost/replica:0/task:0/device:GPU:0 -> device: 0, name: GeForce 940MX, pci bus id: 0000:02:00.0, compute capability: 5.0
2018-07-29 23:45:55.217599: I T:\src\github\tensorflow\tensorflow\core\common_runtime\direct_session.cc:288] Device mapping:
/job:localhost/replica:0/task:0/device:GPU:0 -> device: 0, name: GeForce 940MX, pci bus id: 0000:02:00.0, compute capability: 5.0
random_uniform/RandomUniform: (RandomUniform): /job:localhost/replica:0/task:0/device:GPU:0
2018-07-29 23:45:55.240213: I T:\src\github\tensorflow\tensorflow\core\common_runtime\placer.cc:886] random_uniform/RandomUniform: (RandomUniform)/job:localhost/replica:0/task:0/device:GPU:0
random_uniform/sub: (Sub): /job:localhost/replica:0/task:0/device:GPU:0
2018-07-29 23:45:55.253903: I T:\src\github\tensorflow\tensorflow\core\common_runtime\placer.cc:886] random_uniform/sub: (Sub)/job:localhost/replica:0/task:0/device:GPU:0
random_uniform/mul: (Mul): /job:localhost/replica:0/task:0/device:GPU:0
2018-07-29 23:45:55.263435: I T:\src\github\tensorflow\tensorflow\core\common_runtime\placer.cc:886] random_uniform/mul: (Mul)/job:localhost/replica:0/task:0/device:GPU:0
random_uniform: (Add): /job:localhost/replica:0/task:0/device:GPU:0
2018-07-29 23:45:55.277615: I T:\src\github\tensorflow\tensorflow\core\common_runtime\placer.cc:886] random_uniform: (Add)/job:localhost/replica:0/task:0/device:GPU:0
transpose/Rank: (Rank): /job:localhost/replica:0/task:0/device:GPU:0
2018-07-29 23:45:55.290588: I T:\src\github\tensorflow\tensorflow\core\common_runtime\placer.cc:886] transpose/Rank: (Rank)/job:localhost/replica:0/task:0/device:GPU:0
transpose/sub: (Sub): /job:localhost/replica:0/task:0/device:GPU:0
2018-07-29 23:45:55.302476: I T:\src\github\tensorflow\tensorflow\core\common_runtime\placer.cc:886] transpose/sub: (Sub)/job:localhost/replica:0/task:0/device:GPU:0
transpose/Range: (Range): /job:localhost/replica:0/task:0/device:GPU:0
2018-07-29 23:45:55.312525: I T:\src\github\tensorflow\tensorflow\core\common_runtime\placer.cc:886] transpose/Range: (Range)/job:localhost/replica:0/task:0/device:GPU:0
transpose/sub_1: (Sub): /job:localhost/replica:0/task:0/device:GPU:0
2018-07-29 23:45:55.325154: I T:\src\github\tensorflow\tensorflow\core\common_runtime\placer.cc:886] transpose/sub_1: (Sub)/job:localhost/replica:0/task:0/device:GPU:0
transpose: (Transpose): /job:localhost/replica:0/task:0/device:GPU:0
2018-07-29 23:45:55.338301: I T:\src\github\tensorflow\tensorflow\core\common_runtime\placer.cc:886] transpose: (Transpose)/job:localhost/replica:0/task:0/device:GPU:0
MatMul: (MatMul): /job:localhost/replica:0/task:0/device:GPU:0
2018-07-29 23:45:55.349577: I T:\src\github\tensorflow\tensorflow\core\common_runtime\placer.cc:886] MatMul: (MatMul)/job:localhost/replica:0/task:0/device:GPU:0
Sum: (Sum): /job:localhost/replica:0/task:0/device:GPU:0
2018-07-29 23:45:55.359293: I T:\src\github\tensorflow\tensorflow\core\common_runtime\placer.cc:886] Sum: (Sum)/job:localhost/replica:0/task:0/device:GPU:0
random_uniform/shape: (Const): /job:localhost/replica:0/task:0/device:GPU:0
2018-07-29 23:45:55.372087: I T:\src\github\tensorflow\tensorflow\core\common_runtime\placer.cc:886] random_uniform/shape: (Const)/job:localhost/replica:0/task:0/device:GPU:0
random_uniform/min: (Const): /job:localhost/replica:0/task:0/device:GPU:0
2018-07-29 23:45:55.386133: I T:\src\github\tensorflow\tensorflow\core\common_runtime\placer.cc:886] random_uniform/min: (Const)/job:localhost/replica:0/task:0/device:GPU:0
random_uniform/max: (Const): /job:localhost/replica:0/task:0/device:GPU:0
2018-07-29 23:45:55.396248: I T:\src\github\tensorflow\tensorflow\core\common_runtime\placer.cc:886] random_uniform/max: (Const)/job:localhost/replica:0/task:0/device:GPU:0
transpose/sub/y: (Const): /job:localhost/replica:0/task:0/device:GPU:0
2018-07-29 23:45:55.409642: I T:\src\github\tensorflow\tensorflow\core\common_runtime\placer.cc:886] transpose/sub/y: (Const)/job:localhost/replica:0/task:0/device:GPU:0
transpose/Range/start: (Const): /job:localhost/replica:0/task:0/device:GPU:0
2018-07-29 23:45:55.423110: I T:\src\github\tensorflow\tensorflow\core\common_runtime\placer.cc:886] transpose/Range/start: (Const)/job:localhost/replica:0/task:0/device:GPU:0
transpose/Range/delta: (Const): /job:localhost/replica:0/task:0/device:GPU:0
2018-07-29 23:45:55.435466: I T:\src\github\tensorflow\tensorflow\core\common_runtime\placer.cc:886] transpose/Range/delta: (Const)/job:localhost/replica:0/task:0/device:GPU:0
Const: (Const): /job:localhost/replica:0/task:0/device:GPU:0
2018-07-29 23:45:55.447107: I T:\src\github\tensorflow\tensorflow\core\common_runtime\placer.cc:886] Const: (Const)/job:localhost/replica:0/task:0/device:GPU:0
842822460.0这个代码可以分别测试下 cup 和 gup 进行学习的情况:
cpu 花了3分钟:
Shape: (1500, 1500) Device: /cpu:0
Time taken: 0:03:09.855242gup 花了4秒钟:
Shape: (1500, 1500) Device: /gpu:0
Time taken: 0:00:04.823442还是挺快的。
有个警告:
Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX2这个是对cpu的优化,这边用gpu 进行计算,可以忽略了。
4,总结
使用gpu进行优化还是不错的。
速度超级快,4 秒就行,要是cpu的还要跑个3 分钟。
现在看来在windows 上面开发个 tensorlfow的代码还可以。
除了编译,要用还行,同样的安装cuda,cudnn 在 linux上面也是类似的。
优化还是很方便的。以后学习起来就方便多了。
本文的原文连接是:
https://blog.csdn.net/freewebsys/article/details/81277857
博主地址是:http://blog.csdn.net/freewebsys
