五. JavaSE 基础学习 —— IO 操作 (java. io.*)
1. 编码
字符编码就是按照某种格式某种规定将字符存储在计算机中。字符编码有非常多,每个国家都有自己规定的字符编码。常见的字符编码有几种:ASCII, Unicode, UTF-8, GBK(简体繁体融于一库)等
几种不同常用编码模式的特征:
- GBK: 中文字符 2 字节,英文字符 1 字节;(多用于中文系统的默认编码,如 Windows 系统的中文系统默认编码)
- UTF-8: 中文字符 3 字节,英文字符 1 字节;
- Unicode: 中文、英文字符都是 2 字节;
2. java.io.File 的基本操作
java.io.File 包含了一系列文件和目录路径名的抽象表示方法。
- isFile(): 判断是否为文件;
- isDirectory(): 判断是否为路径;
- delete(): 删除文件或路径
基本操作可在下面例程中展示:
例 1:
遍历一个目录下包括子目录在内的所有 .java 文件打印出来;
public class Demo3 {
public static void main(String[] args) {
printFile3(new File("e:\\coreJava4-26"));
}
public static void printFile3(File file){
File[] files = file.listFiles(new FileFilter() {
public boolean accept(File pathname) {
if(pathname.isFile()){
return pathname.getName().endsWith(".java");
}else if(pathname.isDirectory()){
printFile3(pathname);
}
return false;
}
});
for (File file2 : files) {
System.out.println(file2);
}
}
}
例 2:
删除一个目录(目录为空才能删除)
public class Demo3 {
public static void main(String[] args) {
delDirection(new File("/Users/upcautolong/coreJava4-27"));
}
public static void delDirection(File file){
File[] files = file.listFiles();
// 如果当前路径已经为空,则直接删除当前路径
if(files.length==0){
System.out.println(file);
file.delete();
}
// 当前路径不为空
else {
// 遍历当前路径
for(File file2 : files){
// 当前文件是否为文件
if(file2.isFile()){
System.out.println(file2);
file2.delete();
}
// 当前文件是路径,递归运行
else if(file2.isDirectory()){
delDirection(file2);
}
}
System.out.println(file);
// 将当前路径内的所有文件与路径删除完毕后,最后删除当前路径
file.delete();
}
}
}
由上例可以观察到,文件操作中递归操作很重要。
2. 字节流
文件在 Java 中通过流进行操作,基本可以分为读与写两种操作。在 Java 中,可以把文件流分为字节流和字符流两种。由于读和写基本是一对操作,所以将功能完全相反的输入 / 输出流放在一起进行说明。
整体的继承关系如下图所示:
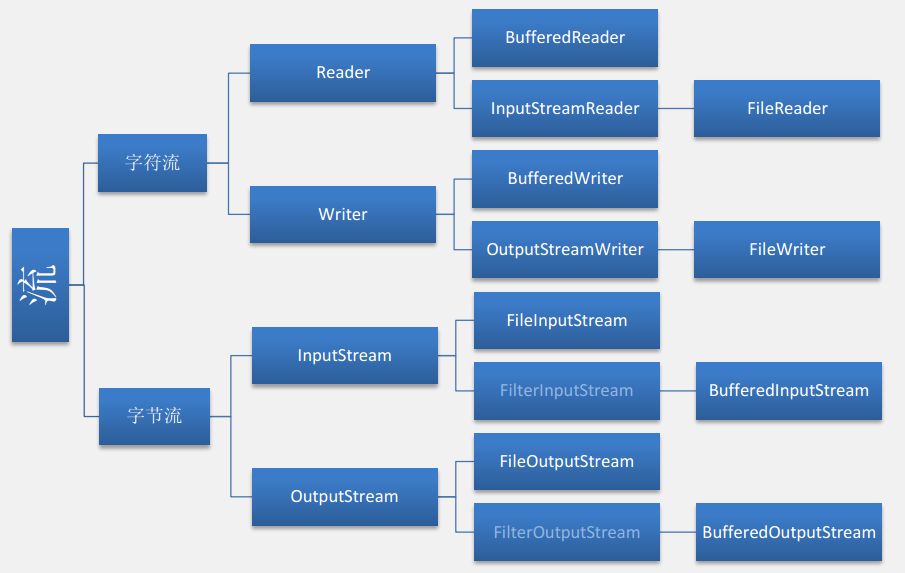
(1) InputStream, OutputStream
InputStream, OutputStream 是最基本的输入流与输出流,即若干输入流、输出流的抽象父类。InputStream 的 read() 方法,以及 OutputStream 的 write() 方法,是它们功能丰富多彩的子类的基本方法。
InputStream 的 read() 方法如下:
int read();
int read(byte[] bytes, int offset, int length);- int read() 方法:每次读一个字节;如果读到 -1,则表示读到了文件结尾;
- int read(byte[] bytes, int offset, int length): 批量缓冲读取
- 每次批量读取,往字节数组 bytes 中放,从 offset 位置开始读取,长度为 length 的字符串;
- 返回的是读到的字节的个数;
- 返回 -1 就读到了文件结尾;
OutputStream 的 write() 方法如下:
void write(int);
void write(byte[] bytes, int offset, int length);- void write(int) 方法:抽象方法,每次写一个字节,即每次写 int 的低 8 位,剩余 24 位补零;
- void write(byte[] bytes, int offset, int length): 抽象方法,批量缓冲写入
- 每次批量写入,往字节数组 bytes 中放,从 offset 位置开始写入,长度为 length 的字符串;
(2) FileInputStream, FileOutputStream
FileInputStream 为文件字节输入流,FileOutputStream 为文件字节输出流,两者都是 InputStream 与 OutputStream 的重要子类。
- FileInputStream:把一个文件作为字节流,进行读操作;
- FileOutputStream:把一个文件作为字节流,进行写操作;而且在写数据的时候,往往只写低 8 位;
例 1:用 FileInputStream, FileOutputStream 复制文件:
public class Demo5 {
public static void main(String[] args) {
try {
FileInputStream in =
new FileInputStream("e:\\bootstrap.rar");
FileOutputStream out =
new FileOutputStream("e:\\xx.rar");
int c ;
// 文件缓冲区
byte[] bytes = new byte[1024 * 40];
// 复制文件(先读后写的过程)
while((c = in.read(bytes,0,bytes.length))!=-1){
out.write(bytes,0,c);
}
in.close();
out.close();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}(3) FilterInputStream, FilterOutputStream
FilterInputStream 的作用是封装其它的输入流,并为它们提供额外的功能。它的常用的子类有 BufferedInputStream 和 DataInputStream。
FilterOutputStream 的作用是封装其它的输出流,并为它们提供额外的功能。它的常用子类主要包括 BufferedOutputStream, DataOutputStream。
(4) DataInputStream, DataOutputStream
DataInputStream 说明基本如下:
- DataInputStream 继承于 FilterInputStream,主要是用来装饰其他输入流。DataInputStream 允许应用程序以与机器无关方式从底层输入流中读取基本 Java 数据类型;
- DataInputStream 本质上也是对 InputStream.read() 方法进行调用,具体方法是连续四次使用基础 read() 方法:InputStream.read() 方法只能对低 8 位有效(即前 24 位置 0),而 DataInputStream.read() 方法每次用 InputStream.read() 方法,分别读取原始数据的右移 24 位、16 位、8 位、0 位,如此连续读取四次,就得到了一个连续的 32 位数据。
DataOutputStream 基本同理于 DataInputStream:
- DataOutputStream 继承于 FilterOutputStream,主要用来装饰其他输出流。DataOutputStream 允许应用程序以与机器无关方式向底层输入流中写入基本 Java 数据类型;
- DataOutputStream 本质上也是对 OutputStream.write() 方法进行调用,具体方法是连续四次使用基础 write() 方法:OutputStream.write() 方法只能对低 8 位有效(即前 24 位置 0),而 DataOutputStream.write() 方法每次用 OutputStream.write() 方法,分别读取原始数据的右移 24 位、16 位、8 位、0 位,如此连续写入四次,就得到了一个连续的 32 位数据。
两者之间也存在一定的联系:应用程序可以使用 DataOutputStream 写入由 DataInputStream 读取的数据。
(5) 关于字节流的总结
由上面的字节流可知,大部分功能强大的字节流,都是通过原始的一次读写一个字节的字节流装饰而来,即功能都由最底层的 read(), write() 向上扩展而来。这种扩展的过程中,使用了装饰者模式。
装饰者模式动态地将责任附加到对象上。若要扩展功能,装饰者提供了比继承更有弹性的替代方案。适合使用装饰者模式的情况如下:
- 在不影响其他对象的情况下,以动态、透明的方式给单个对象添加职责。
- 处理那些可以撤消的职责。
- 当不能采用生成子类的方法进行扩充时。
- 一种情况是可能有大量独立的扩展,为支持每一种组合将产生大量的子类,使得子类数目呈爆炸性增长;
- 另一种情况可能是因为类定义被隐藏,或类定义不能用于生成子类。
另外需要注意的还有:
- 装饰者与被装饰者必须是同样的类型(即具有同样的抽象基类)。
- 装饰者与被装饰者继承于同样的抽象基类,是为了有正确的类型,而不是继承抽象基类的行为。
- 相对而言,行为来自装饰者和基础组件,或与其他装饰者之间的组合关系。例如对于字节流的装饰者模式而言,最内层最原始的字节流方法决定了读写的源头;
3. 字符流
字符流只对文本文件有效。最基本的字符流是 Reader 与 Writer。由于读和写基本是一对操作,所以将功能完全相反的输入 / 输出流放在一起进行说明。
(1) Reader, Writer
Reader, Writer 对于字符流,就相当于 InputStream, OutputStream 相对于字节流,都是最基本的输入流与输出流。Reader 的 read() 方法,以及 Writer 的 write() 方法,是它们子类的基本方法。
Reader 的 read() 方法如下:
int read();
int read(char[] bytes, int offset, int length);- int read(): 每次读到一个字符,读到 -1 就结束;
- int read(char[] bytes, int offset, int length):批量缓冲读取;
- 放入到 char 字符数组中,从第 offset 位置开始读,最多读 length 个;
- 返回的是读到的字符的个数;
Writer 的 write() 方法如下:
void write(int): 每次写一个字符
void write(char[] bytes, int offset, int length):- void write(int): 抽象类,每次写一个字符;
- void write(char[] bytes, int offset, int length):抽象类
(2) InputStreamReader, OutputStreamWriter
InputStreamReader 与 OutputStreamWriter 最内层的核心,依旧是使用了字节流 InputStream.read(), OutputStream.write()方法,它们才是实现所有读写操作的源头。通过 read(), write() 方法,使 InputStreamReader, OutputStreamWriter 成为了字节流与字符流之间的桥梁,能将字节流输入 / 输出为字符流,并且能为字节流指定字符集,可输入 / 输出一个个的字符。
这里说到了字符流与字节流的关系,字符流实现了自己的方法,然而却与字节流的方法具有相同的方法签名与参数列表。这里使用到的设计模式是适配器模式;
(3) BufferedReader, BufferedWriter
BufferedReader 提供了通用的缓冲方式文本读取,readLine 读取一个文本行,从字符输入流中读取文本,缓冲各个字符,从而提供字符、数组和行的高效读取。
BufferedWriter 提供了缓冲方式文本写入,主要和 Writer 抽象类相同。
对于 BufferedReader, BufferedWriter 的详细解析,可以参照下面的网址:《Java8 I/O源码-BufferedReader与BufferedWriter》
例 2:使用 BufferedReader / BufferedWriter,把一个文本文件的内容写到另给一个文件中。
public class Demo10 {
public static void main(String[] args) {
try {
BufferedReader br =
new BufferedReader(
new InputStreamReader(
new FileInputStream("e:\\Demo1.java")));
BufferedWriter bw =
new BufferedWriter(
new OutputStreamWriter(
new FileOutputStream("e:\\2.txt")));
String str = null;
// 读取一行
while((str = br.readLine()) != null){
// 将一行写入
bw.write(str);
// BufferedWriter 换行
bw.newLine();
// BufferedWrited 刷新缓存
bw.flush();
}
br.close();
bw.close();
} catch (Exception e) {
e.printStackTrace();
}
}
}
3. 序列化 / 反序列化
Java 的序列化是指把 Java 对象转换为二进制字节序列的过程;而 Java 反序列化是指把字节序列恢复为 Java 对象的过程。
为什么需要序列化与反序列化?当两个进程进行远程通信时,可以相互发送各种类型的数据,包括文本、图片、音频、视频等,而这些数据都会以二进制序列的形式在网络上传送。那么当两个 Java 进程进行通信时,能否实现进程间的对象传送呢?答案是可以的。这就需要 Java 序列化与反序列化了。换句话说,一方面,发送方需要把这个 Java 对象转换为字节序列,然后在网络上传送;另一方面,接收方需要从字节序列中恢复出 Java 对象。
当我们明晰了为什么需要 Java 序列化和反序列化后,我们很自然地会想 Java 序列化的好处。
- 实现了数据的持久化,通过序列化可以把数据永久地保存到硬盘上(通常存放在文件里);
- 实现远程通信,即在网络上传送对象的字节序列。
如果要实现序列化,要用到 java.io.ObjectOutputStream 和 java.io.ObjectInputStream。
java.io.ObjectOutputStream,表示对象输出流。它的 writeObject(Object obj) 方法可以对参数指定的 obj 对象进行序列化,把得到的字节序列写到一个目标输出流中。
java.io.ObjectInputStream,表示对象输入流。它的 readObject() 方法从源输入流中读取字节序列,再把它们反序列化成为一个对象,并将其返回。
实现序列化的要求:只有实现了 Serializable 或 Externalizable 接口的类的对象才能被序列化,否则抛出异常。
注:
- 简单地说明 Serializable 接口,就是可以将一个对象(标志对象的类型)及其状态转换为字节码,然后保存起来(可以保存在数据库,内存,文件等),即序列化过程;然后可以在适当的时候再将其状态恢复,即反序列化过程。
- Serializable 只是一个规范。
4. transient 关键字
我们都知道一个对象只要实现了 Serilizable 接口,这个对象就可以被序列化,java 的这种序列化模式为开发者提供了很多便利,我们可以不必关系具体序列化的过程,只要这个类实现了Serilizable 接口,这个类的所有属性和方法都会自动序列化。
但有的时候会遇到一种情况:某个类的有些属性需要序列化,而其他属性不需要被序列化,打个比方,如果一个用户有一些敏感信息(如密码,银行卡号等),为了安全起见,不希望在网络操作(主要涉及到序列化操作,本地序列化缓存也适用)中被传输,这些信息对应的变量就可以加上transient关键字。换句话说,这个字段的生命周期仅存于调用者的内存中而不会写到磁盘里持久化。
java 的 transient 关键字为我们提供了便利,你只需要实现 Serilizable 接口,将不需要序列化的属性前添加关键字 transient,序列化对象的时候,这个属性就不会序列化到指定的目的地中。transient 关键字修饰的成员变量,就不做 jvm 默认的序列化了(但是可以自己写序列化)。
附作业: