什么是模块?
常见的场景:一个模块就是一个包含了python定义和声明的文件,文件名就是模块名字加上.py的后缀。
1.使用python编写的代码(.py文件)
2.已被编译为共享库或DLL的C 或者C++扩展
3. 包好一组模块的包
4. 使用C编写并链接到python解释器的内置模块
常用模块
collections模块
在内置数据类型(dict、list、set、tuple)的基础上,collections模块还提供了几个额外的数据类型:Counter、deque、defaultdict、namedtuple和OrderedDict等。
1.namedtuple: 生成可以使用名字来访问元素内容的tuple
2.deque: 双端队列,可以快速的从另外一侧追加和推出对象
3.Counter: 计数器,主要用来计数
4.OrderedDict: 有序字典
5.defaultdict: 带有默认值的字典
这个只需了解一下就行了,不用深究
python3.6+版本字典开始变得有序
时间模块
推迟运行
time.sleep()
时间戳
time.time()
结构化时间
time.asctime() 如果不传参数,直接返回当前那时间的格式化串
时间戳 --> 结构化时间
time.gmtime(时间戳) time.localtime (时间戳)
结构化时间 --> 时间戳
time.mktime(结构化时间)
结构化时间 --> 字符串时间
time.strftime('格式定义','结构化时间') 结构化时间参数若不传,则显示当前时间
字符串时间 --> 结构化时间
time.strptime('时间字符串,字符串对应格式')
time.strptime ('2018-08-08','%Y-%m-%d')
| 索引(Index) | 属性(Attribute) | 值(Values) |
| 0 | tm_year(年) | 比如2018 |
| 1 | tm_mon(月) | 1-12 |
| 2 | tm_mday(日) | 1-31 |
| 3 | tm_hour(时) | 0-23 |
| 4 | tm_min(分) | 0-59 |
| 5 | tm_sec(秒) | 0-60 |
| 6 | tm_wday(weekday) | 0 - 6(0表示周一) |
| 7 | tm_yday(一年中的第几天) | 1-366 |
| 8 | tm_isdst(是否是夏令时) | 默认为0 |
时间戳是计算机能够识别的时间;时间字符串是人能够看懂的时间;元组则是用来操作时间的
几种格式之间的转化

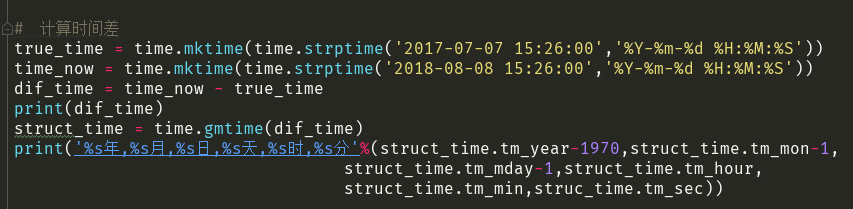
计算时间差
random模块
import random
随机数: 在某个范围内取到每一个值的概率是相同的
随机小数
1. 0-1之内的随机小数 random.random() 这个表示0-1之间的随机小数
2. 1-5之间的随机小数 random.unifrom(1-5)
随机整数
random.randint(1,2) 1-2之间的随机整数 [1-2]范围内随机取
random.randrange(1,2) 不包含2在内的随机整数
random.randrange(1,10,2) 1-10 之间随机取奇数
随机抽取
l = [1,2,3,'aaa',('wahaha','qqxing ')]
random.choice(l) choice 随机抽取一个值
random.sample(1,10) 随机抽取多个值
打乱顺序
lst = [1,2,3,'aaa',('wahaha','qqxing ')]
random.shuffle(lst)
print(lst) 在原列表的基础上做乱序; 只能操作列表
序列化模块
什么叫做序列化 ----- 将原本的字典,列表等内容转换成一个字符串的过程就叫做序列化
序列化的目的
1. 以某种存储形式使自定义对象持久化
2. 将对象从一个地方传递到另一个地方
3. 使程序更具维护性
json
json.dumps ()
dic = {'k1':'v1','k2':'v2','k3':'v3'}
str_dic = json.dumps(dic)
序列化: 将一个字典转换成一个字符串
print(type(str_dic),str_dic)
json转换完成的字符串类型的字典中的字符串是由" " (双引号)表示

json.loads()
dic = {'k1':'v1','k2':'v2','k3':'v3'}
dic2 = json.loads(str_dic)
print(dic2)
反序列化: 将一个字符串格式的字典转化成一个字典
用json的loads功能处理的字符串类型的字典中的字符串必须由""表示

# f = open('json_file','w')
# dic = {'k1':'v1','k2':'v2','k3':'v3'}
# json.dump(dic,f)
# f.close()
'''dump 方法接收一个文件句柄,直接将字典转换成json字符串写入文件'''

# f = open('json_file')
# dic2 = json.load(f)
# f.close()
# print(dic2)
'''load方法接收一个文件句柄,直接将文件中的json字符串转换成数据结构返回'''
