数据库博客中左右的中括号内容全是可选的
1.0 基本格式
select [all|distinct] 目标列表表达式 [,目标列表表达式]
from 表名或者视图名 [ 表名或者视图名 ] (select 语句) as 别名
where 条件表达式
group by 列名 [having 条件表达式]
order by 列名 [asc|desc];
说明:
这一个大概的格式 其中 中括号里的内容是可有可无的
第一行为必写项目 其他的行 没一行代表一个功能 根据需要些或者不写
distinct 是取消结果中重复的元组 只显示一条 默认是all 即不取消重复
select 语句的含义是 根据where字句的条件表达式 从 from 字句指定的表中 视图 或者派生表中找出满足条件的元祖,在按select中的目标表达式生成结果表
如果有group by 字句 则会按列名进行分组,该属性值相等的元素分为一组 通常会在每组中作用聚集函数
如果group by 中含有having 子句 则只有满足指定条件才输出
如果有 order by 语句 则会按列名进行升序或者降序排列
其中 asc 是升序, desc 是降序
2.0 例子 单表查询
已知student 表的内容如下

2.1 接下来我们查询student 表中 Sno 的值
因为没有插入数据我们查询为空
为了便于查看结果 我们先在student 表中插入数据 sql语句中字符串或者字符用单引号
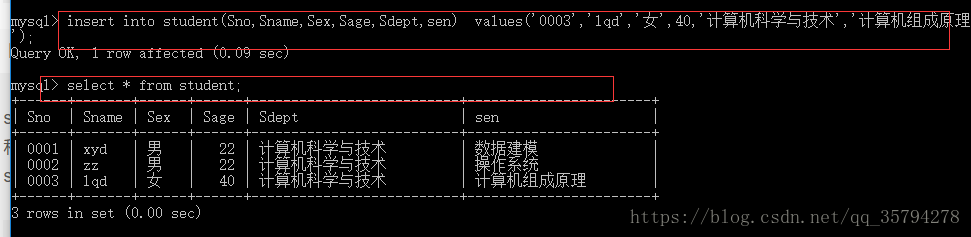
insert into student(Sno,Sname,Sex,Sage,Sdept,sen) values(‘0001’,’xyd’,’男’,22,’计算机科学与技术’,’数据建模’);

eg1: 查询所有数据
方式1 select * from student;
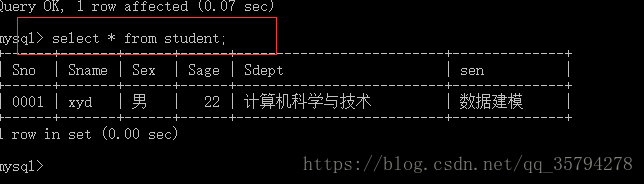
没毛病 很ok
方式2 select Sno,Sname,Sex,Sage,Sdept,sen from student;

eg2: 查询其中的某一项 或者某两项 例如查询学号 姓名
select Sno,Sname from student;
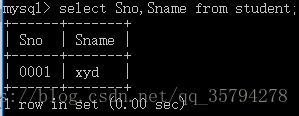
查询一个或者两个的方法是一样的
eg3: 查询经过计算的值
select Sno,Sname,Sage+1000 from student;
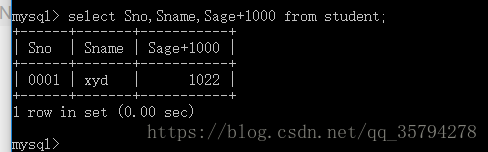
eg4: 目标列表表达式不仅可以是算数表达式 还可以是字符串常量 函数等
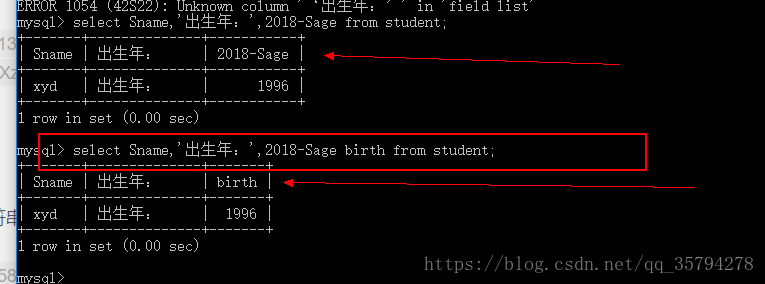
select Sname,’出生年:’,2018-Sage from student;
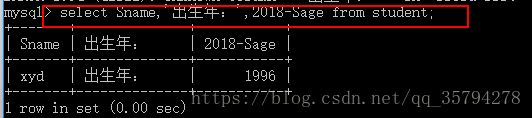
eg5: 上图中 2018-Sage 是出生年 但是我们如果查询出来列名是这样 那就不是很ok 所以我们可以给他起别名 birth
select Sname,’出生年:’,2018-Sage birth from student;
我们继续向表中插入数据
insert into student(Sno,Sname,Sex,Sage,Sdept,sen) values(‘0002’,’zz’,’男’,22,’计算机科学与技术’,’操作系统’);
然后查询一下性别
select Sex from student;
和
select distinct Sex from student;

乐意看出只显示一个重复记录 默认的是ALL
2.2 查询满足条件的元组 where
我们在向数据库中 插入有个元组
insert into student(Sno,Sname,Sex,Sage,Sdept,sen) values(‘0003’,’lqd’,’女’,40,’计算机科学与技术’,’计算机组成原理’);
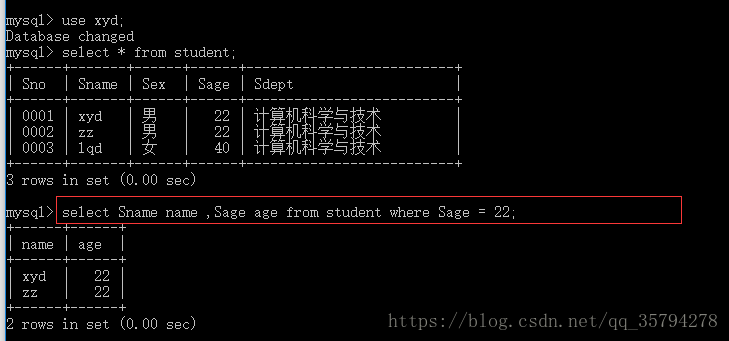
查询年龄等于22 的所有人
select Sname name ,Sage age from student where Sage = 22;
where 字句常用的查询条件如下:
| 标号 | 查询条件 | 谓词 |
|---|---|---|
| 1 | 比较 | = , < , >, <= , >= ,!= , <> ,!>, !<; |
| 2 | 确定范围 | between 。。。and。。, not between 。。。and。。。 |
| 3 | 确定集合 | in , not in |
| 4 | 字符匹配 | like, not like |
| 5 | 空值 | is null ,is not null |
| 6 | 逻辑运算 也叫多重条件 | and ,or , not |
!= , <> 一个意思就是不等于的意思
每一行的用法
1. 第一行:
select Sname name ,Sage age from student where Sage = 22;
其他的就是换掉等号就可以
**2. 第二行:**between后面是下限,and 后面是上限
select Sname name ,Sage age from student where Sage between 30 and 1000; 查询Sage 在30-100之间的所有数据

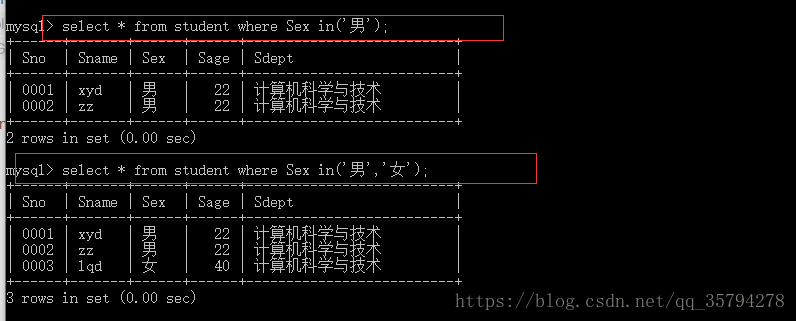
3. 第三行:in() 括号内是个自定义集合 还可以是结果集
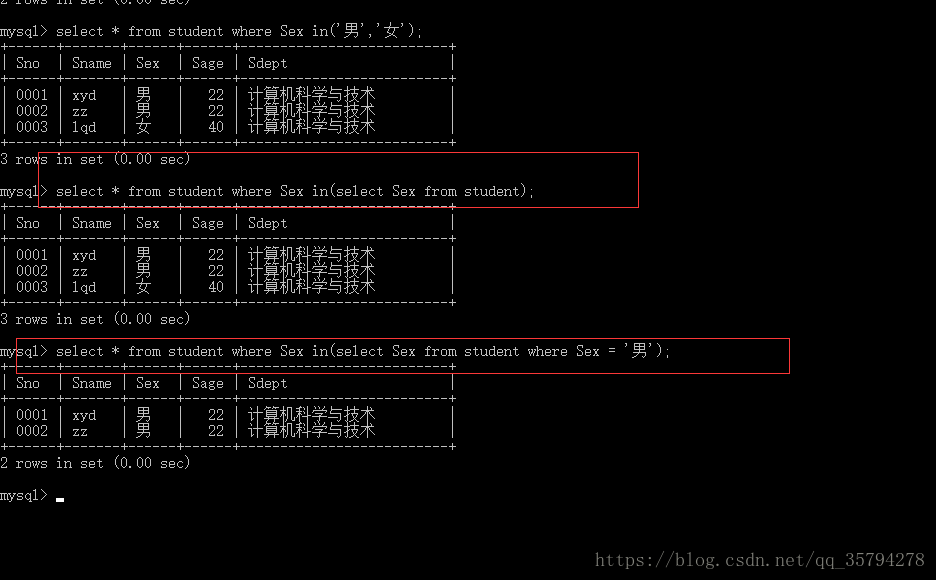
select * from student where Sex in(‘男’,’女’);
4. 第四行:语法格式如下 [not] like 匹配串 [escape 换码字符]
匹配串可以是一个完整的字符串,也可以包含% 和 _
% 代表任意长度的字符串 例如a%b 代表a开头 b结尾 中间任意多个字符串
_ 代表任意单个字符 例如a_b 中间只能有一个字符
eg: select * from student where Sname = ‘xyd’; 等同select * from student where Sname like ‘xyd’;
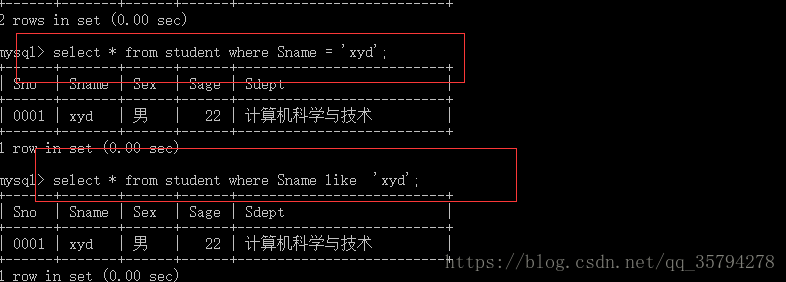
select * from student where Sname like ‘x_d’;

如果数据库字符集是ASCII 码字符集 一个汉字用两个_ 如果是gbk 就用一个
那么如果我们查询的内容本身就含有% 或者_ 怎么办呢?
例如我们重新插入有个姓名是xy%d 的人
insert into student(Sno,Sname,Sex,Sage,Sdept) values(‘0005’,’xy%d’,’男’,22,’计算机科学与技术’);
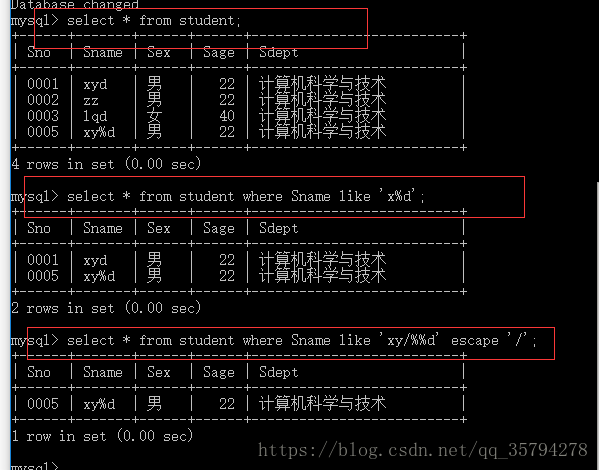
这样我们定义的转义字符后面的% 或者_ 就不再有通配符的含义了 而是仅仅代表他们本身
5. 第五行:select * from student where Sname is null;
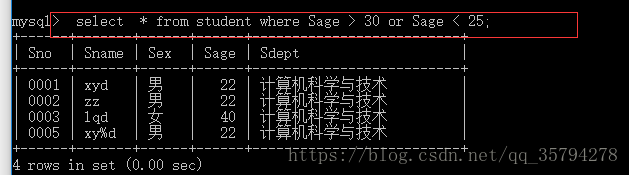
6. 第六行:查询学生年龄大于30或者小于25的
select * from student where Sage > 30 or Sage < 25;
2.3 order by 子句
select * from student order by Sage asc; 查询结果按 Sage的结果升序排列
select * from student order by Sage desc;查询结果按 Sage的结果降序排列
2.4 聚集函数
| 函数 | 解释 |
|---|---|
| count(*) | 统计元组个数 |
| count ( [distinct|all] 列名) | 统计一列中值得个数 |
| sum ( [distinct|all] 列名) | 统计这列值得总和 数据类型必须是数值型的 |
| avg ( [distinct|all] 列名) | 计算一列值得平均值 数据类型必须是数值型的 |
| max ( [distinct|all] 列名) | 求一列值得最大值 |
| min ( [distinct|all] 列名) | 求一列值得最小值 |
eg: 我们计算 计算机科学与技术专业人的平均年龄
select avg(Sage) from student where Sdept like ‘计算机%’;
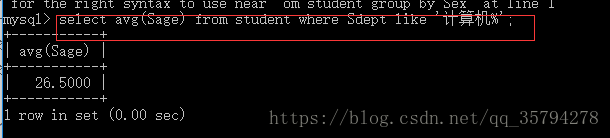
当聚集函数遇见空值的时候,除了count() 外 其余都跳过不进行处理*
聚集函数只能出现在select 后面或者 having 后面
2.4 group by
group by 语句是把结果集按照某一列或者多列进行分组 值相等的一组
分组的目的是细化聚集函数 不分组 聚集函数将作用在这个列上 把这个列分组后
聚集函数会作用在每一列上
eg:
select Sex, count(Sex) from student group by Sex;

如果我们查询没有分组的内容,那么他不会全部显示的
分组够 每个聚集函数作用在这一列的每个组上
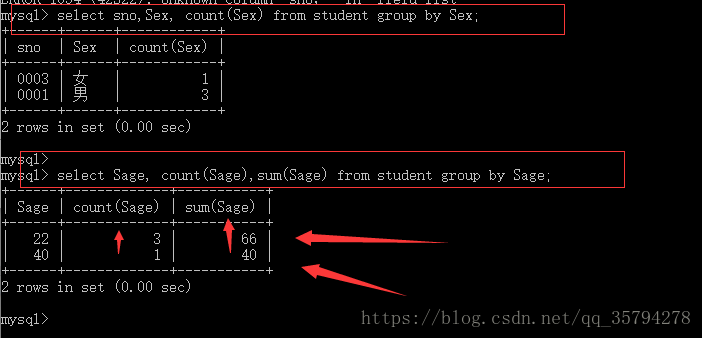
也就是说 年龄原来的数据是22 22 22 40 分组后分为两组
22 *3
40 *1
然后每个聚集元素分别对每组进行计算 例如求和 sum
22+22+22 = 66
40 = 40;
2.4.1 如果分组后还要进行筛选 那么就需要having语句
还是对年龄分组 我们要对年龄小于30的进行分组
select Sage,count(Sage),sum(Sage) from student group by Sage having Sage <30;

这句话的意思是
查询年龄 年龄的总数 年龄的总和 从student 表中按年龄分组 并且要求年龄要小于30