MySQL的逻辑结构如下:
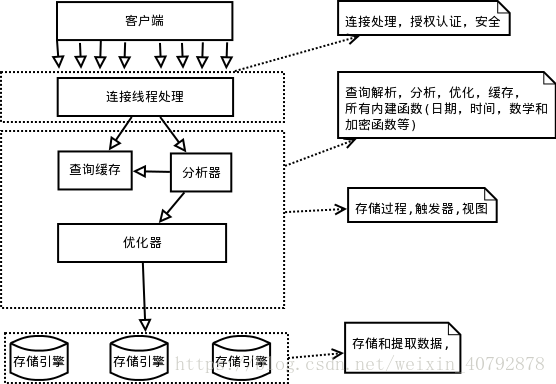
每个虚线框都是一层:
第一层:最上层的服务器不是MySql所独有的,大多数基于网络的客户端/服务器工具或者服务都有类似的系统。比如链接处理,授权认证,安全等等。
第二层:大多数的MySql的核心服务功能都在这一层,包括查询解析、分析、优化、缓存以及所有的内置函数(例如:日期,时间,数学和加密函数等)。所有跨存储引擎的功能都在这一层实现:存储过程,触发器,视图。
第三层:包含了存储引擎。存储引擎负责MySql中的数据存储和提取。服务器通过API和存储引擎进行通信,这些接口屏蔽了不同存储引擎之间的差异,使得这些差异对上层的查询过程透明。存储引擎API包含了几十个底层函数,用于执行诸如”开始一个事务“或者”根据主键提取一行记录“等操作。但存储引擎不会去解析SQL(InnoDB是一个例外,它会解析外键定义,因为MySQL服务器本身没有实现该功能)。
1.索引的存储分类
1.1从存储结构上分类
在MySQL中,索引是在存储引擎层实现的,而不是在服务器层。MySQL支持的索引方法,也可以说成是索引的类型(这是广义层面上的),主要有以下几种
| B_Tree | 最常见的索引类型,大部分引擎都支持B树引擎 |
| HASH | 只有Memory引擎支持,使用场景简单,适用key-value查询,不适用在范围查询如>,<,>=,<= |
| R_Tree | 空间索引,是MyISAM的一个特殊索引类型,主要用于地理空间数据类型,使用较少 |
| Full-text | 全文索引,也是MyISAM的一个索引,主要用于全文索引 |
mysql默认存储引擎innodb只显式支持B-Tree( 从技术上来说是B+Tree)索引,对于频繁访问的表,innodb会透明建立自适应hash索引,即在B树索引基础上建立hash索引,可以显著提高查找效率,对于客户端是透明的,不可控制的,隐式的。
1.1.1 HASH索引:
基于哈希表实现,只有精确匹配索引所有列的查询才有效,对于每一行数据,存储引擎都会对所有的索引列计算一个哈希码(hash code),并且Hash索引将所有的哈希码存储在索引中,同时在索引表中保存指向每个数据行的指针。

1.1.2 B-Tree索引(MySQL使用B+Tree)
B-Tree能加快数据的访问速度,因为存储引擎不再需要进行全表扫描来获取数据,数据分布在各个节点之中。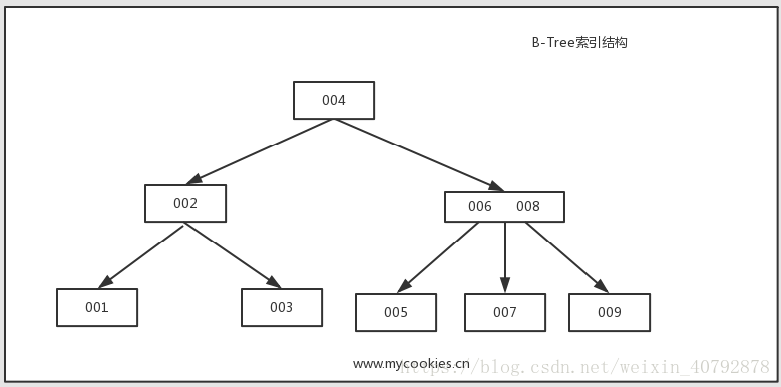
1.1.3 B+Tree索引
是B-Tree的改进版本,同时也是数据库索引索引所采用的存储结构。数据都在叶子节点上,并且增加了顺序访问指针,每个叶子节点都指向相邻的叶子节点的地址。相比B-Tree来说,进行范围查找时只需要查找两个节点,进行遍历即可。而B-Tree需要获取所有节点,相比之下B+Tree效率更高。

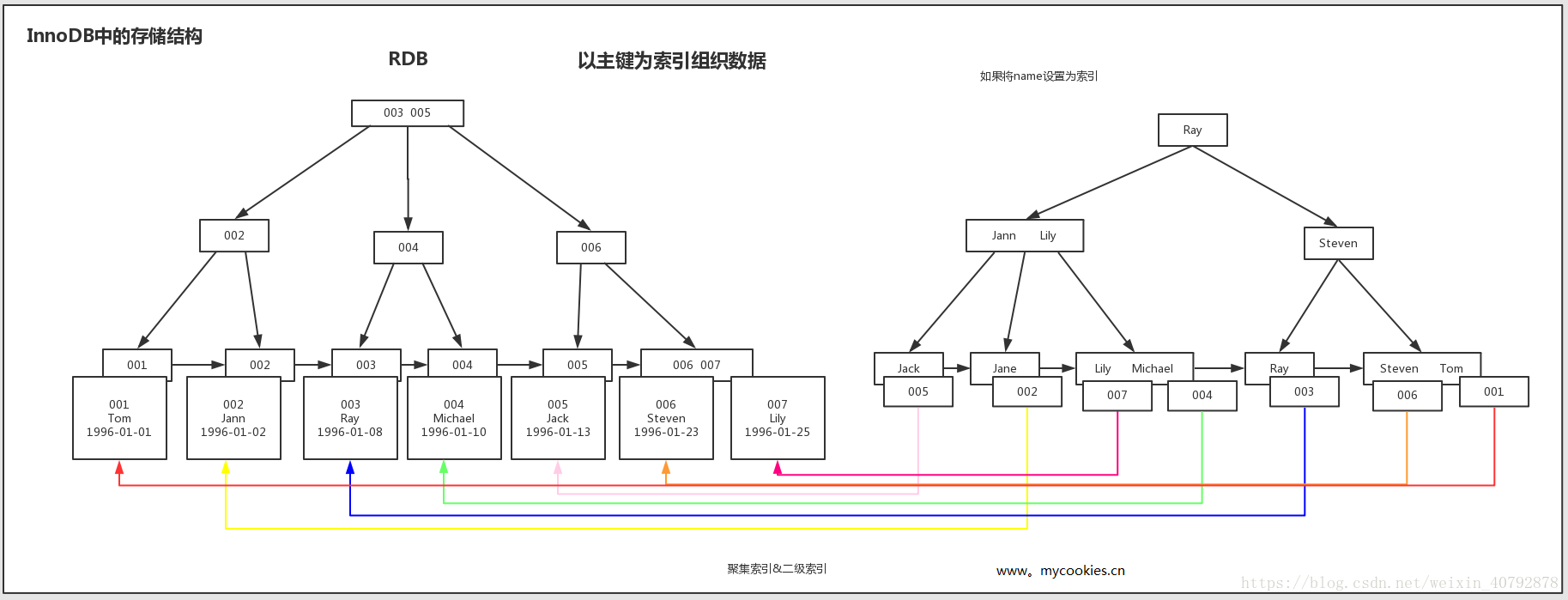
例子:假设有一张学生表,id为主键
| id | name | birthday |
|---|---|---|
| 1 | Tom | 1996-01-01 |
| 2 | Jann | 1996-01-04 |
| 3 | Ray | 1996-01-08 |
| 4 | Michael | 1996-01-10 |
| 5 | Jack | 1996-01-13 |
| 6 | Steven | 1996-01-23 |
| 7 | Lily | 1996-01-25 |
在MyISAM引擎中的实现(二级索引也是这样实现的)

在InnoDB中的实现

1.2 从应用角度上分类
| 普通索引 | 也叫普通索引(index或key),它可以常规地提高查询效率。一张数据表中可以有多个常规索引。 常规索引是使用最普遍的索引类型,如果没有明确指明索引的类型,我们所说的索引都是指常规索引 |
| 唯一索引 | 唯一索引(Unique Key),可以提高查询效率,并提供唯一性约束。一张表中可以有多个唯一索引。允许为空值 |
| 主键索引 | 主键索引(Primary Key),也简称主键。它可以提高查询效率,并提供唯一性约束。一张表中只能有一个主键; 被标志为自动增长的字段一定是主键,但主键不一定是自动增长。一般把主键定义在无意义的字段上(如:编号) 主键的数据类型最好是数值。 |
| 复合索引 | 即一个索引包含多个列 |
| 全文索引 | 全文索引(Full Text),可以提高全文搜索的查询效率 |
| 外键索引 | 外键索引(Foreign Key),简称外键,它可以提高查询效率,外键会自动和对应的其他表的主键关联。 外键的主要作用是保证记录的一致性和完整性 |
注意:只有InnoDB存储引擎的表才支持外键。外键字段如果没有指定索引名称,会自动生成。如果要删除父表(如分类表)中的记录,必须先删除子表(带外键的表,如文章表)中的相应记录,否则会出错。 创建表的时候,可以给字段设置外键,如 foreign key(cate_id) references cms_cate(id),由于外键的效率并不是很好,因此并不推荐使用外键,但我们要使用外键的思想来保证数据的一致性和完整性。
1.2.1 复合索引
可以包含一个列(即字段)或多个列的值。如果索引包含多个列,一般会将其称作复合索引,此时,列的顺序就十分重要,因为MySQL只能高效的使用索引的最左前缀列。创建一个包含两个列的索引,和创建两个只包含一列的索引是大不相同的。
一个索引包含很多列。例子:
create table people (
id int unsigned not null auto_increment primary key comment '主键id',
last_name varchar(20) not null default '' comment '姓',
first_name varchar(20) not null default '' comment '名',
birthday date not null default '1970-01-01' comment '出生日期',
gender tinyint unsigned not null default 3 comment '性别:1男,2女,3未知',
key(last_name, first_name, birthday)
) engine=innodb default charset=utf8;people表中也已经插入了如下一些数据:
| id | last_name | first_name | birthday | gender |
|---|---|---|---|---|
| 1 | Clinton | Bill | 1970-01-01 | 2 |
| 2 | Allen | Cuba | 1960-01-01 | 1 |
| 3 | Bush | George | 1970-01-01 | 1 |
| 4 | Smith | Kim | 1970-01-01 | 1 |
| 5 | Allen | Cally | 1989-06-08 | 2 |
.....
我们创建了一个复合索引 key(last_name, first_name, birthday),对于表中的每一行数据,该索引中都包含了姓、名和出生日期这三列的值。索引也是根据这个顺序来排序存储的,如果某两个人的姓和名都一样,就会根据他们的出生日期来对索引排序存储。
B-Tree 索引适用于全键值、键值范围或键前缀查找,其中键前缀查找只适用于根据最左前缀查找。
复合索引对如下类型的查询有效:
(1)匹配全值(Match the full value),即对索引中的所有类都有等值匹配的条件。
例如:查找姓Allen、名Cuba、出生日期为1960-01-01的人。SQL语句为:select * from people where last_name=’Allen’ and first_name=’Cuba’ and birthday=’1960-01-01’;
(2)匹配值的范围查询(Match a range of values),对索引的值能够进行范围查找
例如: select id,last_name,first_name,birthday from people where last_name BETWEEN ‘Allen’ And ‘Clinton’;这里也只使用了索引的第一列。
(3)匹配最左前缀(Match a leftmost prefix),仅仅使用索引中的最左边列进行查找。
比如在col1+col2+col3字段上的联合索引能够被包含col1、col1+col2、col+col2+col3的等值查询能够利用得到
例如:select * from people where last_name=’Allen’ and first_name='Cuba’;
(4)仅仅对索引进行查询(Index only query),就是查询的字段都包含在复合索引中。查询效率更高,因为索引上包含所需要的数据,这样就不需要回表进行再次查询。用EXPLAIN看Extra的部分直接为Using Index.
例如: select id,last_name,first_name,birthday from people where last_name=’Allen’ and first_name=’Cuba’ and birthday=’1960-01-01’;。
(5)匹配列前缀(Match a column prefix),表示仅仅使用索引中的第一列,并且只包含第一列的开头一部分进行查找。
例如:create index idx_last_name on people(last_name(10),first_name(15)); //新建一个索引
explain select * from people where last_name like ’Allen%’;。
结果中的Extra值是Using where 表示优化器需要通过索引回表查询数据,这里的Allen模糊查询就是匹配前缀
(6)匹配部分精度,部分范围查询(Match one part exactly and match a range on another part)
例如: select * from people where last_name = ‘Allen’ and first_name BETWEEN ’Auba’and‘Clinton’;
(7)如果列是索引,那么使用column_name is null 也会使用到索引(区别于Oracle)
例如:select * from people where last_name = null;
存在索引,但是索引无效的情况:
(1)以%开头的LIKE查询不能利用B-TREE索引。
一般推荐全文检索(MyISM引擎);
采用聚簇表(Innodb引擎),采用一种轻量级的解决方法。一般情况下,扫描索引必要扫描表快(也有特殊),而Innodb表上的二级索引(包含 idx_last_name,还有主键id),那么理想的方式是通过条件获取主键id,再通过id回表检索数据。
例如: select * from (select id from people where last_name like '%usin%') a ,people b where a.id =b.id;
(2)数据出现隐式转换也不会使用索引,例如:last_name是字符串类型的。但是sql语句中使用数值型来查询,中间有转换过程。
例如:select * from people where last_name =1; //这样不会使用索引
select * from people where last_name ='1' //这里会使用索引
(3)复合索引情况,加入查询条件不包含索引列最左边部分。即不满足最左原则leftmost。是不会使用复合索引的。
例如:select * from people where first_name=’Cuba’ and birthday=’1960-01-01’;
(4)用or分割开的条件,如果or前的条件的列有索引,而后面的列中没有索引,那么涉及的索引都不会被用到。
例如:select * from people where last_name=’Cuba’ or gender =’1’;
这里的gender没有索引,所以后面的扫描就会扫描全表,那么在要扫描全表的情况下,就不会扫描索引增加一次I/O操作了,一次全表扫描过滤就可以了。
(5)条件被使用了函数表达式,如下id所以不能使用
例如:select id,last_name,first_name,birthday from people where id+1=3;
1.3 从数据的物理顺序与键值的逻辑(索引)顺序关系分类
| 聚簇索引 | InnoDB的聚簇索引其实就是在同一个结构中保存了B-Tree索引(技术上来说是B+Tree)和数据行。 |
| 非聚簇索引 | 不是聚簇索引,就是非聚簇索引 |
当表中有聚簇索引时,它的数据行实际上存放在索引的叶子页(leaf page)中,也就是说,叶子页包含了行的全部数据,而节点页只包含了索引列的数据。
因为是存储引擎负责实现索引,因此并不是所有的存储引擎都支持聚簇索引。本节我们主要关注InnoDB,这里讨论的内容对于任何支持聚簇索引的存储引擎都是适用的。
InnoDB 通过主键聚集数据,如果没有定义主键,InnoDB 会选择一个唯一的非空索引代替。如果没有这样的索引,InnoDB 会隐式定义一个主键来作为聚簇索引。
聚簇索引的优点:
可以把相关的数据保存在一起。数据访问更快。聚簇索引将索引和数据保存在同一个B-Tree中,因此,从聚簇索引中获取数据通常比非聚簇索引要快。使用覆盖索引扫描的查询可以直接使用节点页中的主键值。
如果在设计表和查询时,能充分利用上面的优点,就可以极大地提升性能。
聚簇索引的缺点:
聚簇索引最大限度地提高了I/O密集型应用的性能,但如果数据全部放在内存中,则访问的顺序就没那么重要了,聚簇索引也就没什么优势了。插入速度严重依赖于插入顺序。按照主键的顺序插入是插入数据到InnoDB表中速度最快的方式。但如果不是按照主键顺序插入数据,那么,在操作完毕后,最好使用 OPTIMIZE TABLE 命令重新组织一下表。更新聚簇索引列的代价很高,因为会强制InnoDB将每个被更新的行移动到新的位置。基于聚簇索引的表在插入新行,或者主键被更新,导致需要移动行的时候,可能面临“页分裂(page split)”的问题。页分裂会导致表占用更多的磁盘空间。
在InnoDB中,聚簇索引“就是”表,所以不像MyISAM那样需要独立的行存储。聚簇索引的每一个叶子节点都包含了主键值、事务ID、用于事务和MVCC(多版本控制)的回滚指针以及所有的剩余列。
InnoDB的二级索引(非聚簇索引)和聚簇索引差别很大,二级索引的叶子节点中存储的不是“行指针”,而是主键值。故通过二级索引查找数据时,会进行两次索引查找。存储引擎需要先查找二级索引的叶子节点来获得对应的主键值,然后根据这个主键值到聚簇索引中查找对应的数据行。
为了保证数据行按顺序插入,最简单的方法是将主键定义为 auto_increment 自动增长。使用InnoDB时,应该尽可能地按主键顺序插入数据,并且尽可能地使用单调增加的主键值来插入新行。
对于高并发工作负载,在InnoDB中按主键顺序插入可能会造成明显的主键值争用的问题。这个问题非常严重,可自行百度解决。
1.4 覆盖索引
如果一个索引包含(或者覆盖)了所有需要查询的字段(列)的值,我们称之为“覆盖索引”。
通常大家都会根据查询的where条件来创建合适的索引,但这只是索引优化的一个方面。设计优秀的索引,应该考虑整个查询,而不单单是where条件部分。
索引确实是一种查找数据的高效方式,但是MySQL也可以使用索引来直接获取列的数据,这样就不必再去读取数据行。如果索引的叶子节点中已经包含了要查询的全部数据,那么,还有什么必要再回表查询呢?
覆盖索引是非常有用的,能够极大地提高性能。考虑一下,如果查询只需要扫描索引,而无须回表获取数据行,会带来多少好处:
索引条目通常远小于数据行大小,所以如果只需要读取索引,那MySQL就会极大地减少数据访问量。覆盖索引对I/O密集型的应用也有帮助,因为索引比数据更小,更容易全部放入内存中。因为索引是按照列值顺序存储的(至少在单个页内是这样),所以对于I/O密集型的范围查询比随机从磁盘读取每一行的数据I/O要少得多。由于InnoDB的聚簇索引,覆盖索引对InnoDB表特别有用。InnoDB的二级索引(非聚簇索引)在叶子节点中保存了行的主键值,所以如果二级主键能够覆盖查询,则可以避免对主键索引的二次查询。
在索引中就完成所有查询的成本一般比再回表查询小得多。B-Tree索引可以成为覆盖索引,但哈希索引、空间索引和全文索引等均不支持覆盖索引。
例如下面都是覆盖索引:
explain select id from people;
explain select last_name from people;
explain select id,first_name from people;
explain select last_name,first_name,birthday from people;
explain select last_name,first_name,birthday from people where last_name='Allen';
参考博客:https://www.cnblogs.com/liqiangchn/p/9060521.html
https://www.2cto.com/database/201611/562165.html