Part 3: 利用LSTM即兴创作Jazz
欢迎来到本周的最后一个作业!在这个作业中,你将利用LSTM建立一个生成音乐的模型。在作业的最后你将可以听到你自己的音乐。
你将学会:
- 在音乐生成中使用 LSTM
- 利用深度学习生成你的 jazz 音乐
导包
from __future__ import print_function
import IPython
import sys
from music21 import *
import numpy as np
from grammar import *
from qa import *
from preprocess import *
from music_utils import *
from data_utils import *
from keras.models import load_model, Model
from keras.layers import Dense, Activation, Dropout, Input, LSTM, Reshape, Lambda, RepeatVector
from keras.initializers import glorot_uniform
from keras.utils import to_categorical
from keras.optimizers import Adam
from keras import backend as K
# Using TensorFlow backend.1 问题描述
你想为你朋友的生日创作一段jazz音乐。然而,你不了解任何乐器和音乐作品。幸运的是,你了解深度学习,并将使用 LSTM 网络解决这个问题。
您将训练一个网络,以作品风格代表爵士音乐来创作爵士乐独奏。

1.1 数据集
你将在爵士音乐的语料库上训练你的算法。 运行下面的代码收听训练集中的音频片断:
IPython.display.Audio('./data/30s_seq.mp3')我们已经对音乐数据做了预处理,以”values”来表示。可以非正式地将每个”value”看作一个音符,它包含音高和持续时间。 例如,如果您按下特定钢琴键0.5秒,那么您刚刚弹奏了一个音符。 在音乐理论中,”value” 实际上比这更复杂。 特别是,它还捕获了同时播放多个音符所需的信息。 例如,在播放音乐作品时,可以同时按下两个钢琴键(同时播放多个音符生成所谓的“和弦”)。 但是这里我们不需要关系音乐理论的细节。对于这个作业,你需要知道的是,我们获得一个”values”的数据集,并将学习一个RNN模型来生成一个序列的”values”。
我们的音乐生成系统将使用78个独特的值。 运行以下代码以加载原始音乐数据并将其预处理为”value”。
X, Y, n_values, indices_values = load_music_utils()
print('shape of X:', X.shape)
print('number of training examples:', X.shape[0])
print('Tx (length of sequence):', X.shape[1])
print('total # of unique values:', n_values)
print('Shape of Y:', Y.shape)
# shape of X: (60, 30, 78)
# number of training examples: 60
# Tx (length of sequence): 30
# total # of unique values: 78
# Shape of Y: (30, 60, 78)- X: 这是一个(m,Tx,78)维数组。 m 表示样本数量,Tx 表示时间步(也即序列的长度),在每个时间步,输入是78个不同的可能值之一,表示为一个one-hot向量。 因此,例如,X [i,t,:]是表示第i个示例在时间t的值的one-hot向量。
- Y: 与X基本相同,但向左(向前)移动了一步。 与恐龙分配类似,使用先前值预测下一个值,所以我们的序列模型将尝试预测给定的 ,…, 。 但是,Y中的数据被重新排序为维(Ty,m,78),其中 = 。 这种格式使得稍后进入LSTM更方便。
- n_value: 数据集中独立”value”的个数,这里是78
- indices_values: python 字典:key 是0-77,value 是特定音符
1.2 模型概述
模型结构如下:
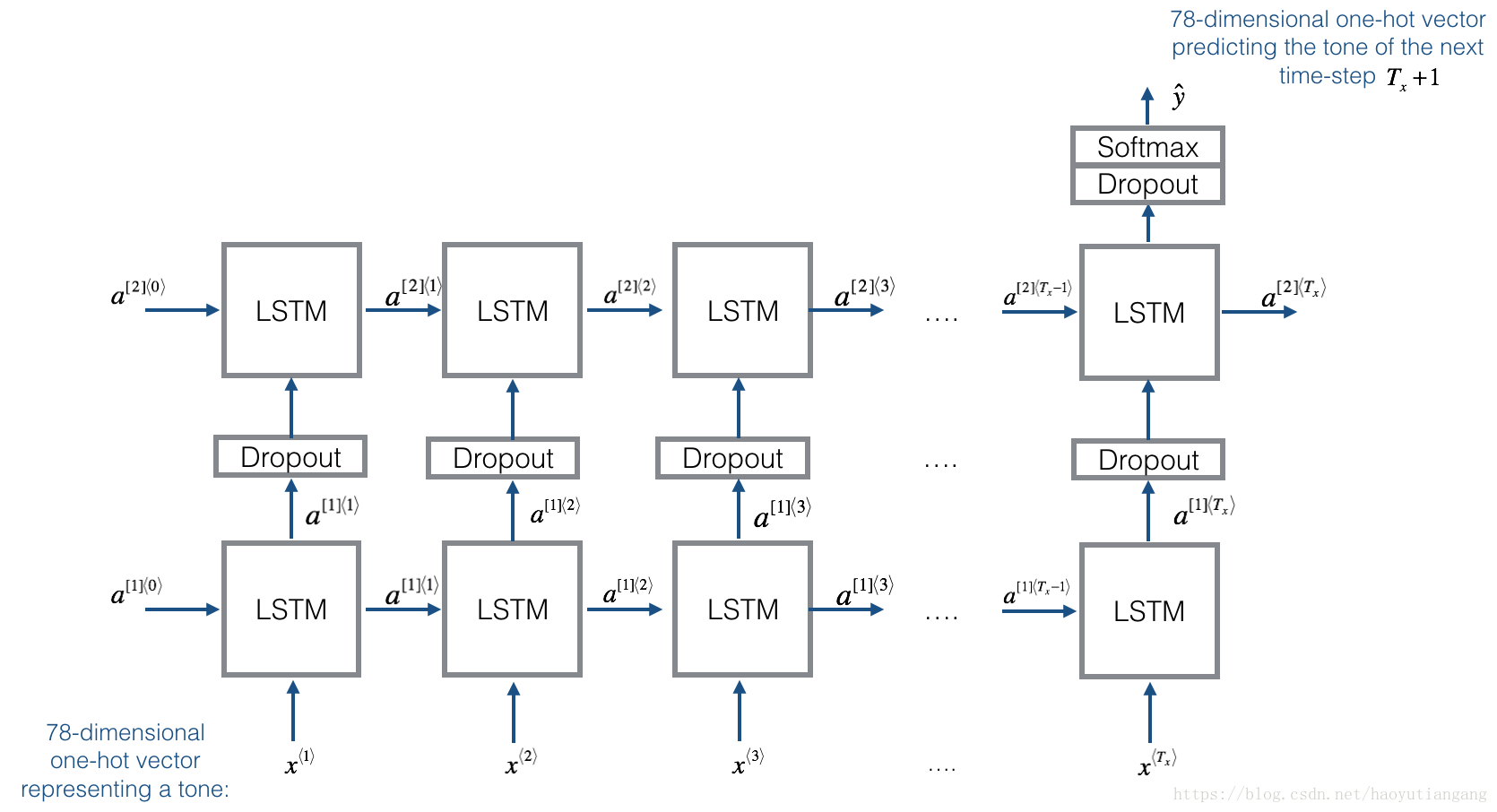
根据从更长的音乐中取得的30个随机片段来训练模型。 因此,这里不用设置第一个输入 =0⃗, 因为大多数片段的音频片段开始于某片音乐。 可以将每个snippts设置为具有相同长度 = 30,以使向量化更容易。
2 构建模型
在这部分你将建立并训练一个学习音乐模式的模型。
要做到这一点,您需要建立一个模型,该模型X 维度为(m,Tx,78),Y 维度为(Ty,m,78). 我们将使用64维隐藏状态的LSTM。
n_a = 64下面是如何创建具有多个输入和输出的Keras模型。
如果您正在构建一个RNN,即使在测试时间,整个输入序列
,
,…,
都是事先给定的,例如,如果输入是单词并且输出是标签, 那么Keras拥有简单的内置函数来构建模型。 但是,对于序列生成,在测试时我们并不知道
的所有值, 相反,我们使用
=
一次生成一个。 所以代码会更复杂一点,你需要实现自己的for 循环来遍历不同的时间步。
函数 djmodel()将使用for循环调用LSTM层的
次,所有
副本具有相同的权重是很重要的。 即,每次都不应该重新初始化权重–Tx步骤应该具有共享权重。
在Keras中实现可共享权重的关键步骤是:
- 定义各层对象(我们将使用全局变量)。
- 传播输入时调用这些对象。
我们已将你需要的各层对象定义为全局变量。
请检查Keras文档以确保您了解这些层是什么:Reshape(),LSTM(),Dense()
reshapor = Reshape((1, 78)) # Used in Step 2.B of djmodel(), below
LSTM_cell = LSTM(n_a, return_state = True) # Used in Step 2.C
densor = Dense(n_values, activation='softmax') # Used in Step 2.Dreshapor,LSTM_cell和densor 现在都是层对象,你可以使用它们来实现djmodel()。 为了通过层传播Keras 的X,请使用layer_object(X)(或layer_object([X,Y])如果需要多个输入)。 例如,reshapor(X)将通过上面定义的Reshape((1,78))层传播X。
练习:实现 djmodel()
分两步
- 创建一个空列表”output”用来保存每个时间步骤LSTM单元的输出。
循环 t: 1 –>
A. 从X中选择”t”时间步的向量。维度应该是(78,)。 为此,需要在Keras中创建一个lambda层,
见代码:x = Lambda(lambda x: X[:,t,:])(X)lambda 函数创建一个匿名函数来提取合适的 one-shot 向量,并作为一个层来作用 X。
B. 转换x为(1,78)。用函数
reshapor()。
C. 执行单步 LSTM 单元,用上一个时间步的隐藏状态a和单元状态 c 来初始化 LSTM 单元。
python
a, _, c = LSTM_cell(input_x, initial_state=[previous hidden state, previous cell state])
D. 使用densor层,通过softmax预测 LSTM 单元的输出.
E. 将预测的输出写入 “outputs” 列表中
# GRADED FUNCTION: djmodel
def djmodel(Tx, n_a, n_values):
"""
Implement the model
Arguments:
Tx -- length of the sequence in a corpus
n_a -- the number of activations used in our model
n_values -- number of unique values in the music data
Returns:
model -- a keras model with the
"""
# Define the input of your model with a shape
X = Input(shape=(Tx, n_values))
# Define s0, initial hidden state for the decoder LSTM
a0 = Input(shape=(n_a,), name='a0')
c0 = Input(shape=(n_a,), name='c0')
a = a0
c = c0
### START CODE HERE ###
# Step 1: Create empty list to append the outputs while you iterate (≈1 line)
outputs = []
# Step 2: Loop
for t in range(Tx):
# Step 2.A: select the "t"th time step vector from X.
x = Lambda(lambda x: X[:,t,:])(X)
# Step 2.B: Use reshapor to reshape x to be (1, n_values) (≈1 line)
x = reshapor(x)
# Step 2.C: Perform one step of the LSTM_cell
a, _, c = LSTM_cell(x, initial_state=[a, c])
# Step 2.D: Apply densor to the hidden state output of LSTM_Cell
out = densor(a)
# Step 2.E: add the output to "outputs"
outputs.append(out)
# Step 3: Create model instance
model = Model(inputs=[X, a0, c0], outputs=outputs)
### END CODE HERE ###
return model定义模型
model = djmodel(Tx = 30 , n_a = 64, n_values = 78)优化和编译模型
opt = Adam(lr=0.01, beta_1=0.9, beta_2=0.999, decay=0.01)
model.compile(optimizer=opt, loss='categorical_crossentropy', metrics=['accuracy'])初始化 LSTM 的初始状态 和 为 0
m = 60
a0 = np.zeros((m, n_a))
c0 = np.zeros((m, n_a))现在调整模型!首先将Y变成一个列表,因为cost函数期望Y以这种格式提供(每个时间步一个列表项)。 因此,列表(Y)是一个包含30个项目的列表,其中每个项目都的维度为(60,78)。 训练100个epochs。
model.fit([X, a0, c0], list(Y), epochs=100)可以看到模型cost正在下降。 现在你已经训练了一个模型,让我们继续最后一节来实现相关算法,并生成一些音乐!
3 生成音乐
现在你训练了一个模型,模型学习了爵士音乐的格式。现在我们利用这个模型来创作一些新的音乐。
3.1 预测和采样
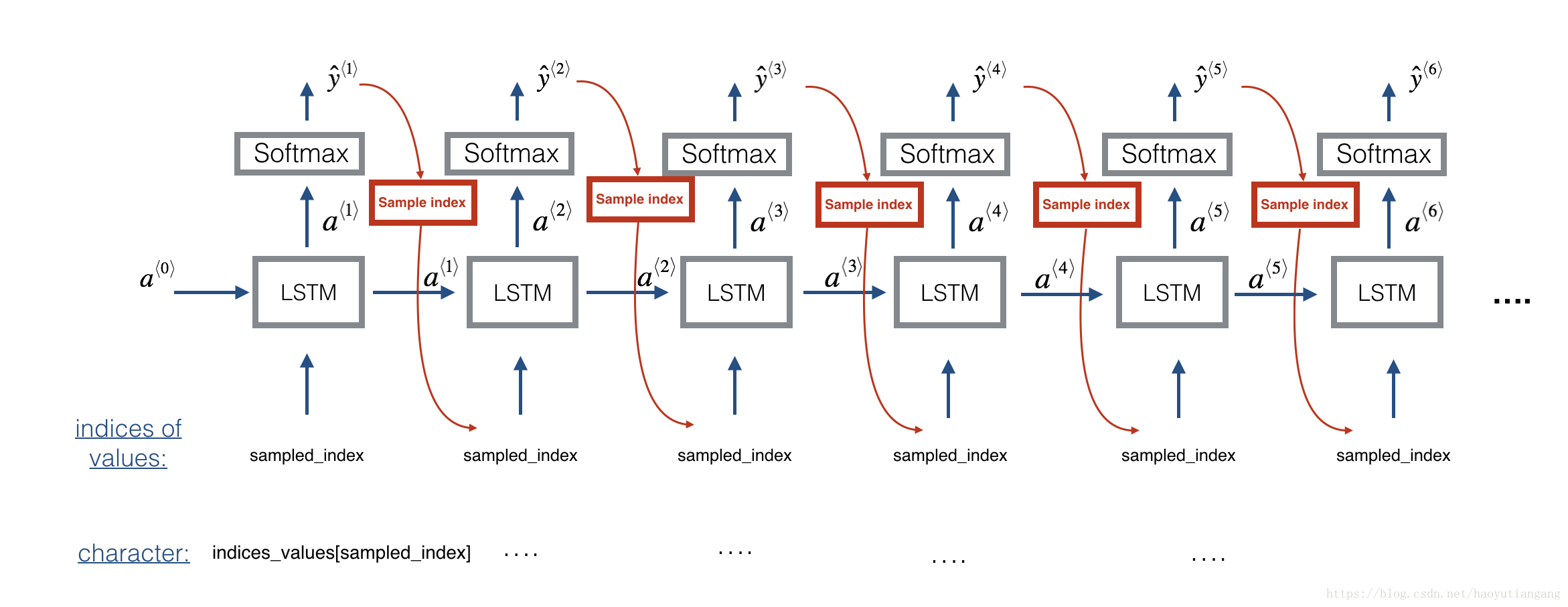
在每个采样步骤中,您将使用LSTM的激活函数a和单元状态c作为输入,向前传播一步,并获得新的激活函数以及单元状态。然后可以使用新的激活函数a来使用传感器来生成输出。
为了启动模型,我们将初始化 , 和 为0。
练习:实现音乐值序列采样函数
- A: 使用LSTM,利用上一步的输入c和a生成当前步的c和a
- B: 使用densor,在a上使用softmax函数计算当前时间步的输出
- C: 将输出追加到列表outputs中
- D: 将采样X转换成one-hot输出向量,以便传给下一步的LSTM
x = Lambda(one_hot)(out) 技术说明:这一行代码实际上是在每个步骤中使用argmax选择单个最可能的音符,而不是随机抽取一个值
# GRADED FUNCTION: music_inference_model
def music_inference_model(LSTM_cell, densor, n_values = 78, n_a = 64, Ty = 100):
"""
Uses the trained "LSTM_cell" and "densor" from model() to generate a sequence of values.
Arguments:
LSTM_cell -- the trained "LSTM_cell" from model(), Keras layer object
densor -- the trained "densor" from model(), Keras layer object
n_values -- integer, umber of unique values
n_a -- number of units in the LSTM_cell
Ty -- integer, number of time steps to generate
Returns:
inference_model -- Keras model instance
"""
# Define the input of your model with a shape
x0 = Input(shape=(1, n_values))
# Define s0, initial hidden state for the decoder LSTM
a0 = Input(shape=(n_a,), name='a0')
c0 = Input(shape=(n_a,), name='c0')
a = a0
c = c0
x = x0
### START CODE HERE ###
# Step 1: Create an empty list of "outputs" to later store your predicted values (≈1 line)
outputs = []
# Step 2: Loop over Ty and generate a value at every time step
for t in range(Ty):
# Step 2.A: Perform one step of LSTM_cell (≈1 line)
a, _, c = LSTM_cell(x, initial_state=[a, c])
# Step 2.B: Apply Dense layer to the hidden state output of the LSTM_cell (≈1 line)
out = densor(a)
# Step 2.C: Append the prediction "out" to "outputs". out.shape = (None, 78) (≈1 line)
outputs.append(out)
# Step 2.D: Select the next value according to "out", and set "x" to be the one-hot representation of the
# selected value, which will be passed as the input to LSTM_cell on the next step. We have provided
# the line of code you need to do this.
x = Lambda(one_hot)(out)
# Step 3: Create model instance with the correct "inputs" and "outputs" (≈1 line)
inference_model = Model(inputs=[x0, a0, c0], outputs=outputs)
### END CODE HERE ###
return inference_model
###########################################################
# Define your inference model
inference_model = music_inference_model(LSTM_cell, densor, n_values = 78, n_a = 64, Ty = 50)
# Initialize x and the LSTM state variables a and c to zero-valued vectors
x_initializer = np.zeros((1, 1, 78))
a_initializer = np.zeros((1, n_a))
c_initializer = np.zeros((1, n_a))练习:实现 predict_and_sample()
这个函数有很多参数,包括输入[x_initializer,a_initializer,c_initializer]。
3个步骤:
- 根据输入集合,使用推理模型来预测输出。 输出pred应该是一个长度为Ty的列表,其中每个元素是一个如下维度的numpy数组(1,n_values)。
- 将pred转换为 大小的一个numpy数组。 每个索引对应的是通过取pred列表的一个元素的argmax来计算的。
- 将索引转换为one-hot向量
# GRADED FUNCTION: predict_and_sample
def predict_and_sample(inference_model, x_initializer = x_initializer, a_initializer = a_initializer,
c_initializer = c_initializer):
"""
Predicts the next value of values using the inference model.
Arguments:
inference_model -- Keras model instance for inference time
x_initializer -- numpy array of shape (1, 1, 78), one-hot vector initializing the values generation
a_initializer -- numpy array of shape (1, n_a), initializing the hidden state of the LSTM_cell
c_initializer -- numpy array of shape (1, n_a), initializing the cell state of the LSTM_cel
Returns:
results -- numpy-array of shape (Ty, 78), matrix of one-hot vectors representing the values generated
indices -- numpy-array of shape (Ty, 1), matrix of indices representing the values generated
"""
### START CODE HERE ###
# Step 1: Use your inference model to predict an output sequence given x_initializer, a_initializer and c_initializer.
pred = inference_model.predict([x_initializer, a_initializer, c_initializer])
# Step 2: Convert "pred" into an np.array() of indices with the maximum probabilities
indices = np.argmax(pred, axis=-1)
# Step 3: Convert indices to one-hot vectors, the shape of the results should be (1, )
results = to_categorical(indices, num_classes=x_initializer.shape[-1])
### END CODE HERE ###
return results, indices
##########################################################
results, indices = predict_and_sample(inference_model, x_initializer, a_initializer, c_initializer)
print("np.argmax(results[12]) =", np.argmax(results[12]))
print("np.argmax(results[17]) =", np.argmax(results[17]))
print("list(indices[12:18]) =", list(indices[12:18]))
# np.argmax(results[12]) = 33
# np.argmax(results[17]) = 40
# list(indices[12:18]) = [array([33]), array([40]), array([66]), array([56]), array([33]), array([40])]期待的输出
您的结果可能会有所不同,因为Keras的结果不完全可预测。 然而,如果你已经用model.fit()训练了你的LSTM_cell,正好有100个时期,你应该很可能观察到一系列不完全相同的索引。此外,您应该注意:np.argmax(results [12])是列表中的第一个元素(indices [12:18]),np.argmax(results [17])是列表的最后一个元素(indices [12:18])。
| key | value |
|---|---|
| np.argmax(results[12]) | 1 |
| np.argmax(results[12]) | 42 |
| list(indices[12:18]) | [array([1]), array([42]), array([54]), array([17]), array([1]), array([42])] |
3.3 生成音乐
最后,您已准备好制作音乐了。您的RNN生成了一系列值。 以下代码首先调用predict_and_sample()函数来生成音乐。之后这些值被后期处理成音乐和弦(意味着可以同时播放多个值或音符)。
大多数计算音乐算法都使用一些后期处理,因为如果没有这样的后期处理,很难生成听起来很好的音乐。 后期处理通过确保相同的声音不重复太多次,两个连续的音符彼此间距不太远等来清理所生成的音频。 有人可能会说,很多这些后处理步骤都是黑客行为; 另外,很多音乐创作文献也专注于手工制作后期处理器,并且很多输出质量取决于后期处理的质量,而不仅仅取决于RNN的质量。 但是这个后期处理确实有很大的影响,所以我们也可以在我们的实现中使用它。
让我们来只做一些音乐吧!
out_stream = generate_music(inference_model)
# Predicting new values for different set of chords.
# Generated 51 sounds using the predicted values for the set of chords ("1") and after pruning
# Generated 51 sounds using the predicted values for the set of chords ("2") and after pruning
# Generated 51 sounds using the predicted values for the set of chords ("3") and after pruning
# Generated 51 sounds using the predicted values for the set of chords ("4") and after pruning
# Generated 51 sounds using the predicted values for the set of chords ("5") and after pruning
# Your generated music is saved in output/my_music.midi你可以打开生成的output/my_music.midi收听生成的音乐,如果没有相应播放器也可以转换为mp3再收听。
下面是我们用这个算法生成的一段30s的音乐。
IPython.display.Audio('./data/30s_trained_model.mp3')谨记
- 循环神经网络模型可以用来生成音乐”values”, 然后酒气处理为midi音乐
- 生成恐龙名称或生成音乐的模型非常相似,主要区别在于模型的输入
- 在keras中,循环生成器涉及定义共享权重的层,然后循环时间步1–>
恭喜你完成了这个作业,生成了一段jazz独奏!
引用
本作业的想法主要来自下面引用的三个计算音乐论文。 这里的实现也获得了很大的启发,并使用了Ji-Sung Kim的github仓库中的许多组件。
- Ji-Sung Kim, 2016, deepjazz
- Jon Gillick, Kevin Tang and Robert Keller, 2009. Learning Jazz Grammars
- Robert Keller and David Morrison, 2007, A Grammatical Approach to Automatic Improvisation
- François Pachet, 1999, Surprising Harmonies
我们也感谢FrançoisGermain宝贵的反馈意见。