Python的os.walk()方法详细讲解
<div class="article-info-box">
<div class="article-bar-top d-flex">
<span class="time">2015年07月03日 19:05:31</span>
<div class="float-right">
<span class="read-count">阅读数:11160</span>
</div>
</div>
</div>
<article>
<div id="article_content" class="article_content clearfix csdn-tracking-statistics" data-pid="blog" data-mod="popu_307" data-dsm="post">
<link rel="stylesheet" href="https://csdnimg.cn/release/phoenix/template/css/ck_htmledit_views-e2445db1a8.css">
<div class="htmledit_views">
http://www.cnblogs.com/herbert/archive/2013/01/07/2848892.html 写的特别清楚的一篇
http://alanland.iteye.com/blog/612459
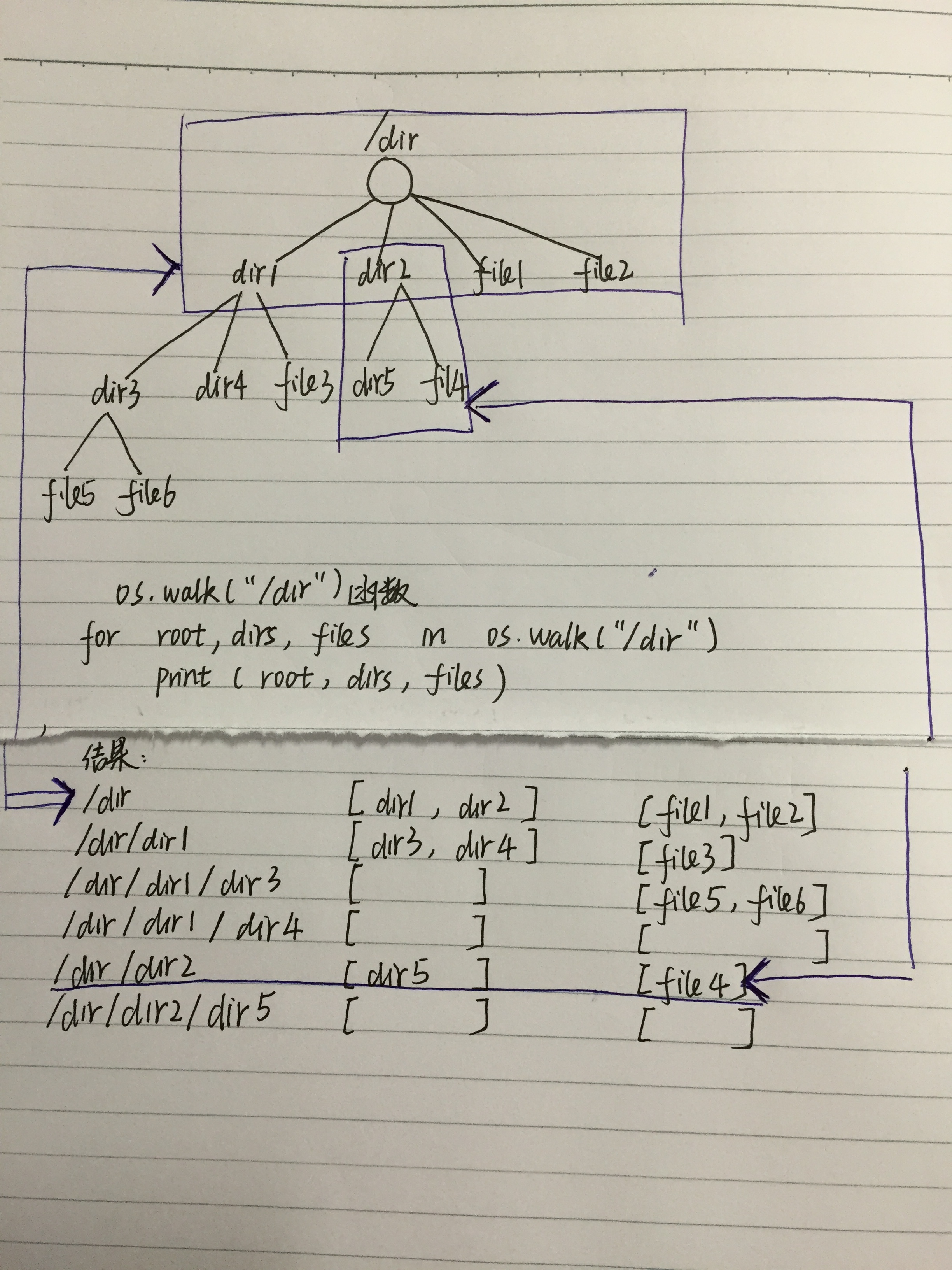
我们可以看到,返回的是一个元组,元祖每一个元素即上面一行的内容,所以用for去遍历它。
然后对应的将这行的第一列的内容给root
第二列 给dirs
第三列 给files

元组每一个元素就是遍历一棵树(包括子树) 根的孩子(注意 不是子孙),如上图中蓝色框中的内容
[(根,孩子文件夹,孩子文件),
(子根,孩子文件夹,孩子文件),
(子根,孩子文件夹,孩子文件),
(子根,孩子文件夹,孩子文件)]
应用:
1.遍历文件夹下的所有文件(为了方便,假设只有一层文件夹)
-
for parent, dir_names, file_names
in os.walk(person_dir):
-
for file_name
in file_names:
-
print file_name
就可以遍历所有的file了
解析:os.walk(“/dir”)返回的结果是这样的
( /dir, [dir1,dir2……], [ file1,file2,…………….] ),
( /dir/dir1 , [] , [file10,file12……] ) ,
( /dir/dir2 , [] [file20,………..] ) ,
…………………………..
第一趟循环
parent 为: /dir
dir_names为:[dir1,dir2,…..dirn],
file_names为:[file1,file2,……………]
此时执行for file_name in file_names:
则内循环print出file1,file2………
即打印出根目录dir下所有文件
第二趟循环
parent 为: /dir/dir1
dir_names为: [],
file_names为:[file10,file12……]
此时执行
for file_name in file_names:
则内循环print出file10,file12………
即打印出dir2下的所有文件
第三趟循环……………….
2.那么如何读取所有文件夹名字呢?
-
for parent, dir_names, file_names
in os.walk(person_dir):
-
for dir_name
in dir_names:
-
print dir_name
第一趟循环
parent 为/dir
dir_names为 [dir1,dir2,…..dirn],
file_names为[file1,file2,…………… ]
此时执行
for dir_name in dir_names
则内循环print出dir1,dir2, dir3………
即打印出根目录dir下所有文件夹
第二趟循环
parent 为/dir/dir1
dir_names为 [],
file_names为[file10,file12……]
此时执行
for file_name in file_names:
则内循环为空
第三趟循环内循环同样为空
剩下的内循环同样为空(见上述假设)
这样就打印出了所有文件夹
3.如果只想读取根目录下文件夹下的文件,不想读取根目录下的文件(假设根目录下的文件夹中没有文件夹,只有文件)
-
for parent, dir_names, file_names
in os.walk(dir):
-
for dir_name
in dir_names:
-
for parent2, dir_names2, file_names2
in os.walk(dir+dir_name):
-
for file_name
in file_names2:
请自行体会
</div>
</div>
</article>
<div class="article-bar-bottom">
<div class="tags-box artic-tag-box">
<span class="label">文章标签:</span>
<a class="tag-link" href="http://so.csdn.net/so/search/s.do?q=python&t=blog" target="_blank">python </a><a class="tag-link" href="http://so.csdn.net/so/search/s.do?q=os.walk&t=blog" target="_blank">os.walk </a>
</div>
<div class="tags-box hot-word">
<span class="label">相关热词:</span>
<a class="tag-link" href="https://blog.csdn.net/wzx1286474341/article/details/80465794" target="_blank">
和python </a>
<a class="tag-link" href="https://blog.csdn.net/data8866/article/details/62884210" target="_blank">
python和 </a>
<a class="tag-link" href="https://blog.csdn.net/ieearth/article/details/72910204" target="_blank">
python【】 </a>
<a class="tag-link" href="https://blog.csdn.net/yhs_cy/article/details/79438706" target="_blank">
python下 </a>
<a class="tag-link" href="https://blog.csdn.net/data8866/article/details/62884210" target="_blank">
python的与 </a>
</div>
</div>
<!-- !empty($pre_next_article[0]) -->
<div class="related-article related-article-prev text-truncate">
<a href="https://blog.csdn.net/silviakafka/article/details/46647953">
<span>上一篇</span>java虚拟机类加载过程内存情况底层源码分析及ClassLoader讲解 </a>
</div>
<div class="related-article related-article-next text-truncate">
<a href="https://blog.csdn.net/silviakafka/article/details/46931857">
<span>下一篇</span>Spring AOP三种配置详细介绍 </a>
</div>
</div>
**
**
下面是Python二维数组的定义:
直接定义 a=[[1,1],[1,1]],这里定义了一个2*2的,且初始为0的二维数组。
间接定义 a=[[0 for x in range(10)] for y in range(10)],这里定义了10*10初始为0的二维数组。
后来,我在网上找到了更简单的字义二维数组的方法:
b = [[0]*10]*10,定义10*10初始为0的Python二维数组。
与a=[[0 for x in range(10)] for y in range(10)]比较:print a==b的结果为True。
但用b的定义方法代替a后,以前的可以正常运行的程序也出错了,经过仔细分析得出区别:
a[0][0]=1时,只有a[0][0]为1,其他全为0。
b[0][0]=1时,b[0][0],b[1][0],直到 b[9,0] 全部为 1。由此得到大数组中的10个小的一维数据全是一个相同的引用,即指向同一地址。故 b = [[0]*10]*10 并不符合我们常规意义上的二维数组。
同时经过试验:c=[0]*10的定义与c=[0 for x in range(10)]有同样的效果,而没有上面相同引用的问题,估计数组c的定义时是值类型相乘,而前面b的定义是引用类型的相乘,因为一维数组是一个引用(借用C#中的值类型和引用类型,不知是否合适)。