一、案例介绍
1、目的:利用上市公司当年的公开财务指标预测来年盈利情况最重要的投资人决策依据。
2、数据来源:随机抽取深市和沪市2002和2003年的500个上市公司样本预测来年的净资产收益率。
3、解释变量包括:资产周转率、当年净资产收益率、债务资本比率、市盈率、应收账款/主营业务收入、主营业务利润、存货/资产总计(反映公司存货状况)、对数资产总计(反映公司规模)
二、描述性分析
1、各个标量的均值、最小值、中位数、最大数和标准差
2、变量相关性分析:相关性矩阵
3、当期净资产收益率和往期净资产收益率的散点图
三、建立模型:
1、多元线性回归模型:

2、模型假设:
(1)解释变量是非随机的,且各解释变量之间互不相关(多重共线性)
(2)随机误差项具有零均值、同方差和不序列相关性
(3)解释变量和随机项不相关
(4)随机项满足正态分布
总结即:随机项满足零均值、同方差、不序列相关的正态分布;解释变量和随机项不相关且解释变量之间互不相关
3、参数估计:
(1)最小二乘估计量:
(2)方差估计量:
(3)拟合优度:
总平方和:
残差平方和:
R-square:
4、显著性检验:
(1)F检验
假设:
检验统计量:
(2)t检验
假设:
检验统计量:
5、模型检验
(1)异方差性
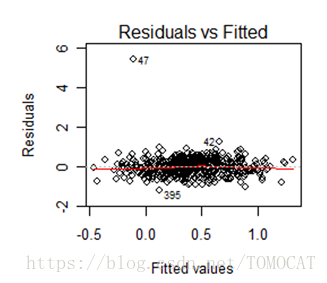

(2)正态性检验:
QQ图:残差的分位数和正态分布的分位数呈线性关系
Shapiro-Wilk normality test
Kolmogorov-Smirnov test
(3)异常值检验:待补充
Cook距离
(4)多重共线性检验:
见五介绍多重共线性
四、变量选择与预测:
只有三个变量显著性通过,但是无法排除其他变量是否有预测能力。从而我们通过AIC和BIC准则选择。原理:同时考虑到了模型复杂度和拟合效果。
五、多重共线性问题:
1、变量相关性对模型造成的影响:
(1)完全多重共线性会使OLS(普通最小二乘)系数矩阵方程
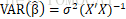
(2)多重共线性由于自变量之间的相关性,从而变量估计系数可能出现完全相反的符号或者难以置信的数值。
(3)可能出现显著自变量回归系数不显著:因为标准误较大,从而t检验的t值较小,倾向于接受原假设。
(4)R方值较高,但t值并不都是统计显著的。R²等于回归平方和在总平方和中所占的比率,即回归方程所能解释的因变量变异性的百分比。具体解释见补充资料1:回归拟合增加解释变量为什么增加拟合优度。方差膨胀因子越接近1,多重共线性越严重。这个时候R2越接近1。
2、多重共线性的诊断方法:
(1)R2较高但t值统计显著的不多。
(2)解释变量两两高度相关。
(3)方差膨胀因子
3、方差膨胀因子:
(1)考虑辅助回归:
(2)是辅助回归的拟合优度
(3)方差膨胀因子:
在一定程度上在多大程度上第i个变量所包含的信息被其他变量覆盖。一般认为小于10就没有多重共线性问题。