王家林人工智能AI 从零起步(无需数学和Python基础)编码实现AI框架之第八节课:AI的上帝视角Why、How、What,及Perceptron彻底解密及计算机视觉的觉醒 老师微信13928463918












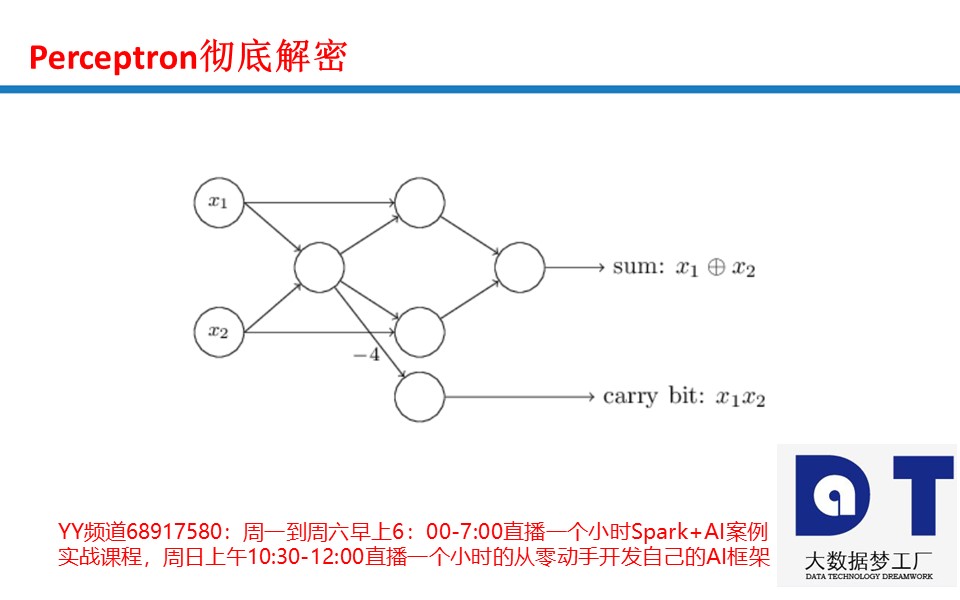

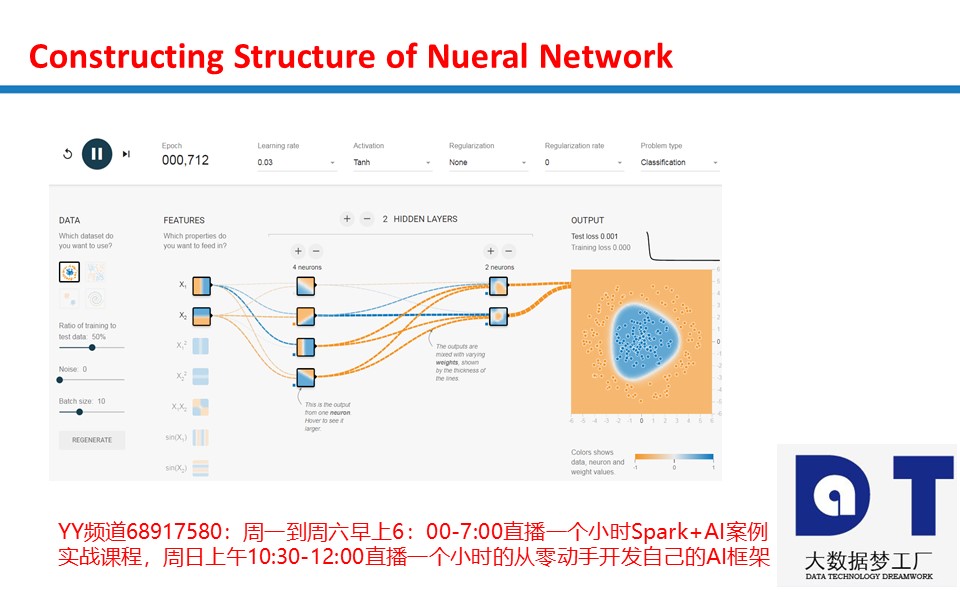



王家林老师的总结:
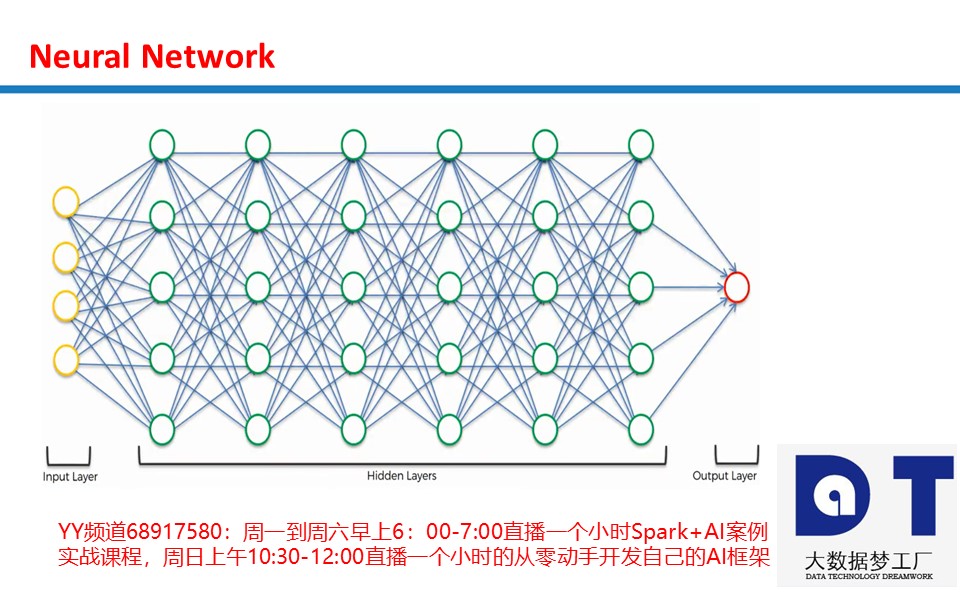
为什么分层导致了人工智能前所未有的突破?做了以前人类从没想过计算机能做的事情,是因为:
分层之后,第一层进行最原始的处理,第二层可以在第一层的处理结果上进行抽象,第三层可以在第二层的处理结果上进一步抽象,第四层可以在第三层的处理结果上进一步抽象,整个文类社会文明的精髓就在于一层又一层的抽象,当你抽象程度越高的时候,你就越能做出具有洞察力的决策和获得智慧!整个人类社会的文明史,所有国家的发展过程,都是在一步又一步的抽象过程,类似于金字塔的结构的过程。而我们一层又一层的神经网络,可以把它向上旋转90度,其实是一层又一层的抽象,这个过程是所有伟大的数学家,所有伟大的哲学家、文学家,及政治领域取得伟大成就的人,他们共同采取的路径!所以,神经网络真正代表的意义是人类在现实经验不断进行抽象产生洞察力和智慧的过程,这是分层的神经网络有力量的根源!这也是人类自古以来的有力量的根源!所以分层的深度神经网络系统完整的实现了人类获得所有的洞察力的模型的过程!不要仅仅看见第一层,第二层,第三层,这个没有意义,第三层可以在第二层的基础上抽象,第四层可以在第三层的基础上抽象....这是神经网络真正的强大之处,这也是在视觉识别系统,语音识别系统,自然语言处理等诸多方面产生超越人类预期的根源!因为这反映了整个人类的文明史到底怎么运行的,怎么进化的!

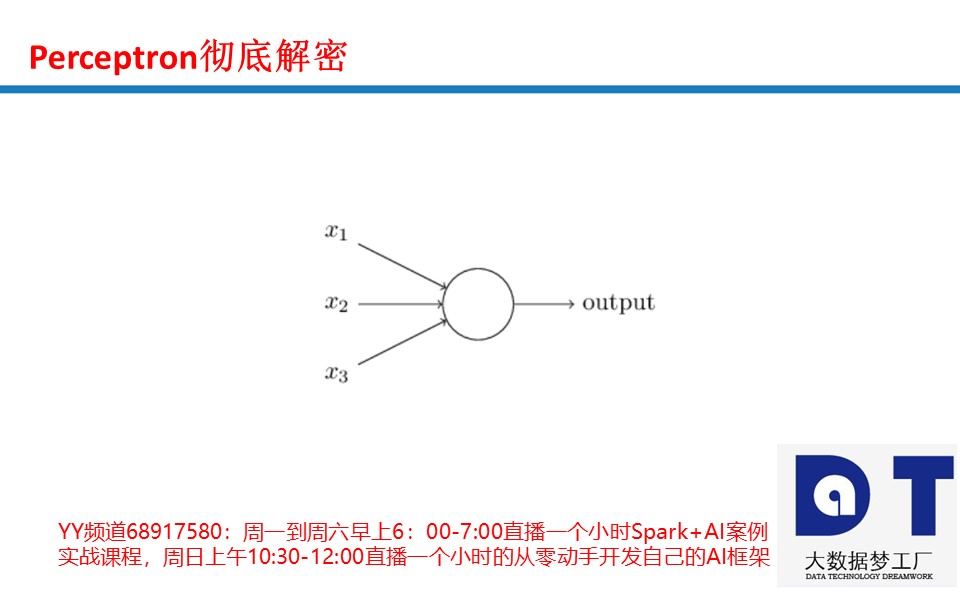
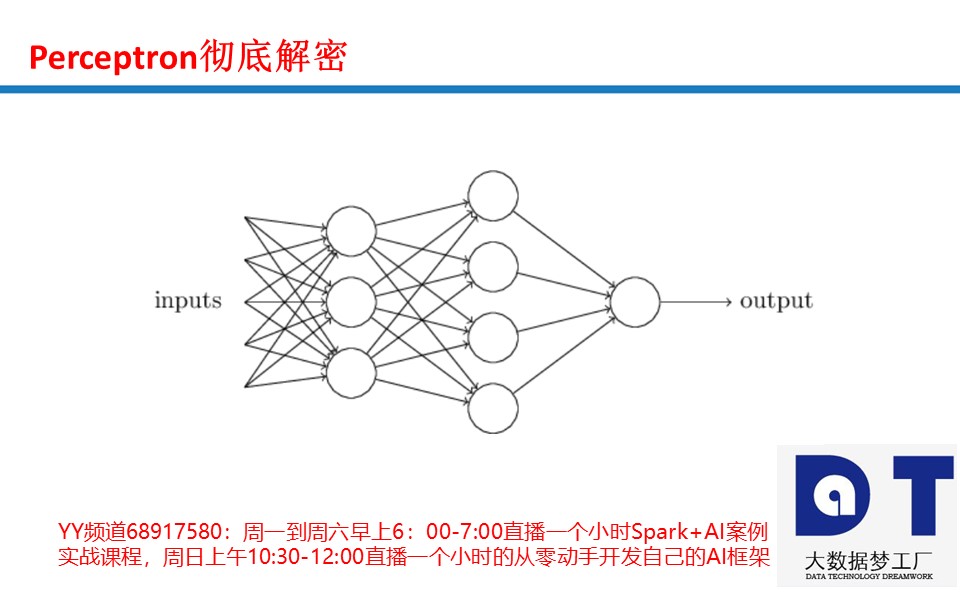
家林老师关于Bias的总结
Bias是前面的因素和权重相乘累加是否能达到某个值,就像决定能不能看电影,Bias就是一个门槛,就像达不到哈佛大学的分数,就不能录取。Bias是决定是否看电影的一个标准,满足了什么条件,对条件进行了衡量之后,达到我们的预期才决定是否看电影,达到这个预期就看电影,达不到预期,就不看电影。Bias是偏好,是Preference。Bias不是随便能调的,涉及一个标准和门槛,这不是加0.1和减0.1的问题。Bias是神经网络系统判断图片是否是一只猫,还是一只狗,是一辆汽车还是一辆飞机,最后综合得到的标准,这不是乱调就能调出来的。
作业:自己设想一下计算机图像识别的实现思路。
参考网络资料,接下来我们对计算机进行图像识别,实际编码实现识别图像(手写数字识别),将会使用Python以及Python的许多模块,例如numpy、PIL等。
#从PIL库中导入Image
from PIL import Image
#导入numpy
import numpy as np
#从文件中载入图像
i = Image.open('images/dot.png')
#将图像转换成矩阵形式
iar = np.asarray(i)
'''
Alright, so an image array comes out as a 3-dimensional array. This means an
array within an array an array, or list. So the entire list is the whole image.
The 2nd dimension in,
corresponds to the row, and the 3rd dimension in
corresponds to each pixil in that row.. or u can
think of it like a column.
within the pixil arrays, you have your typical Red Green Blue, or RGB, and then you
are also supplied with an "alpha"... and this is for each pixil.
So that's just a quick example. In the next example, we'll be breaking things
down further, and beginning to build some recognition.
'''
print(iar)图像“dot.png”基本如下:

运行结果如下:
[[[ 0 0 0 255]
[255 255 255 255]
[255 255 255 255]
[255 255 255 255]
[255 255 255 255]
[255 255 255 255]
[255 255 255 255]
[255 255 255 255]]
[[255 255 255 255]
[255 255 255 255]
[255 255 255 255]
[255 255 255 255]
[255 255 255 255]
[255 255 255 255]
[255 255 255 255]
[255 255 255 255]]
[[255 255 255 255]
[255 255 255 255]
[255 255 255 255]
[255 255 255 255]
[255 255 255 255]
[255 255 255 255]
[255 255 255 255]
[255 255 255 255]]
[[255 255 255 255]
[255 255 255 255]
[255 255 255 255]
[255 255 255 255]
[255 255 255 255]
[255 255 255 255]
[255 255 255 255]
[255 255 255 255]]
[[255 255 255 255]
[255 255 255 255]
[255 255 255 255]
[255 255 255 255]
[255 255 255 255]
[255 255 255 255]
[255 255 255 255]
[255 255 255 255]]
[[255 255 255 255]
[255 255 255 255]
[255 255 255 255]
[255 255 255 255]
[255 255 255 255]
[255 255 255 255]
[255 255 255 255]
[255 255 255 255]]
[[255 255 255 255]
[255 255 255 255]
[255 255 255 255]
[255 255 255 255]
[255 255 255 255]
[255 255 255 255]
[255 255 255 255]
[255 255 255 255]]
[[255 255 255 255]
[255 255 255 255]
[255 255 255 255]
[255 255 255 255]
[255 255 255 255]
[255 255 255 255]
[255 255 255 255]
[255 255 255 255]]]注意:A(α值)表示图像的透明度。α值越低,透明度越高,相反α值越高,透明度越低。
因此,这里共有8行类似这样的结果,剩下的都是白色。
当计算机尝试识别数字时,会碰到一个问题,有些数字可能会看上去模糊、褪色或变形,就像验证码中或带有彩色零的图像中显示的那样。机器要处理数百万种颜色,增加了计算的复杂度。并不是所有的图像都有机器容易识别的白色或深色的背景。对于这个问题我们通过设定阈值来解决。我们分析图像的平均颜色,将它作为阈值。高于阈值则认为更接近白色,低于阈值认为接近黑色。我们用阈值函数来解决这个问题。使用阈值函数,我们将把任何图像变成黑白两色,这种方法使得计算机不必困惑于数百万种颜色(256*256*256*256),简化了图像识别的工作量。我们提出了将超过阈值的值转化为白色(很明显,一个图像的色彩越多,越接近与白色),同时低于阈值的值转化为黑色。因此现在最有挑战的部分是阈值的确定,该函数基本上是改变数组的值,使每个像素转换为白色或黑色。
'''
Thresholding!
'''
from PIL import Image
import numpy as np
#import matplotlib
import matplotlib.pyplot as plt
import time
from functools import reduce
def threshold(imageArray):
balanceAr = []
newAr = imageArray
for eachRow in imageArray:
for eachPix in eachRow:
#print eachPix
avgNum = reduce(lambda x, y: x + y, eachPix[:3]) / len(eachPix[:3])
balanceAr.append(avgNum)
#time.sleep(3)
balance = reduce(lambda x, y: x + y, balanceAr) / len(balanceAr)
#print balance
for eachRow in newAr:
for eachPix in eachRow:
if reduce(lambda x, y: x + y, eachPix[:3]) / len(eachPix[:3]) > balance:
eachPix[0] = 255
eachPix[1] = 255
eachPix[2] = 255
eachPix[3] = 255
else:
eachPix[0] = 0
eachPix[1] = 0
eachPix[2] = 0
eachPix[3] = 255
return newAr
i = Image.open('images/numbers/0.1.png')
iar = np.array(i)
i2 = Image.open('images/numbers/y0.4.png')
iar2 = np.array(i2)
i3 = Image.open('images/numbers/y0.5.png')
iar3 = np.array(i3)
i4 = Image.open('images/sentdex.png')
iar4 = np.array(i4)
fig = plt.figure()
ax1 = plt.subplot2grid((8,6),(0,0), rowspan=4, colspan=3)
ax2 = plt.subplot2grid((8,6),(4,0), rowspan=4, colspan=3)
ax3 = plt.subplot2grid((8,6),(0,3), rowspan=4, colspan=3)
ax4 = plt.subplot2grid((8,6),(4,3), rowspan=4, colspan=3)
ax1.imshow(iar)
ax2.imshow(iar2)
ax3.imshow(iar3)
ax4.imshow(iar4)
plt.show()
iar = threshold(iar)
iar2 = threshold(iar2)
iar3 = threshold(iar3)
iar4 = threshold(iar4)
fig = plt.figure()
ax1 = plt.subplot2grid((8,6),(0,0), rowspan=4, colspan=3)
ax2 = plt.subplot2grid((8,6),(4,0), rowspan=4, colspan=3)
ax3 = plt.subplot2grid((8,6),(0,3), rowspan=4, colspan=3)
ax4 = plt.subplot2grid((8,6),(4,3), rowspan=4, colspan=3)
ax1.imshow(iar)
ax2.imshow(iar2)
ax3.imshow(iar3)
ax4.imshow(iar4)
#threshold(iar4)
plt.show()运行结果如下:
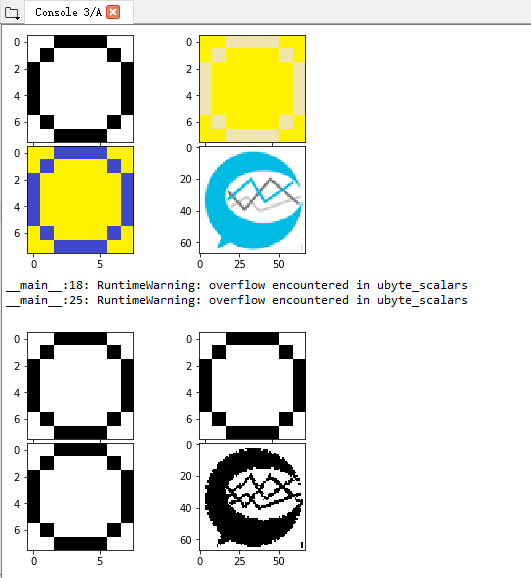
注意到所有的图像都被转化成黑白图像。阈值设定是图像识别的首要步骤之一。
在阀值函数里,我们通过运行二重循环来读取每个像素行并将该像素行中所有的RGB值取平均值,然后将其添加到balanceAr数组中。这一循环会涉及所有的像素行,计算每一行的像素平均值,然后将其添加到balanceAr数组中。接下来我们将对balanceAr数组中所有的值取平均,并将该平均值存入balance变量中。
我们再回到每个像素行,取平均值并将均值与阈值相比较。如果该均值大于阈值,我们将像素转换为白色,反之转换为黑色。
现在我们已经解决了阈值的问题,并且将所有的图像(彩色或黑白)统一转换成了黑白图像。接下来是比较有趣的部分。我们首先要训练数据,然后教会它如何识别和预测图像。
我们将通过存储本地数据(一些图像)来训练和测试它们,以帮助我们识别图像。
现在, 我的文件夹里已经有了一些图像(数字)文件。我将要做的是用我的numpy函数将这些图像都转化成数组,然后存入数据库中。这样可以节约时间,不必每次处理图像时都要先将其转化为数组。

from PIL import Image
import numpy as np
import matplotlib.pyplot as plt
import time
from collections import Counter
from matplotlib import style
style.use("ggplot")
def createExamples():
numberArrayExamples = open('numArEx.txt','a')
numbersWeHave = range(1,10)
for eachNum in numbersWeHave:
for furtherNum in numbersWeHave:
imgFilePath = 'images/numbers/'+str(eachNum)+'.'+str(furtherNum)+'.png'
ei = Image.open(imgFilePath)
eiar = np.array(ei)
eiarl = str(eiar.tolist())
lineToWrite = str(eachNum)+'::'+eiarl+'\n'
numberArrayExamples.write(lineToWrite)
def threshold(imageArray):
balanceAr = []
newAr = imageArray
for eachPart in imageArray:
for theParts in eachPart:
avgNum = reduce(lambda x, y: x + y, theParts[:3]) / len(theParts[:3])
balanceAr.append(avgNum)
balance = reduce(lambda x, y: x + y, balanceAr) / len(balanceAr)
for eachRow in newAr:
for eachPix in eachRow:
if reduce(lambda x, y: x + y, eachPix[:3]) / len(eachPix[:3]) > balance:
eachPix[0] = 255
eachPix[1] = 255
eachPix[2] = 255
eachPix[3] = 255
else:
eachPix[0] = 0
eachPix[1] = 0
eachPix[2] = 0
eachPix[3] = 255
return newAr
def whatNumIsThis(filePath):
matchedAr = []
loadExamps = open('numArEx.txt','r').read()
loadExamps = loadExamps.split('\n')
i = Image.open(filePath)
iar = np.array(i)
iarl = iar.tolist()
inQuestion = str(iarl)
for eachExample in loadExamps:
try:
splitEx = eachExample.split('::')
currentNum = splitEx[0]
currentAr = splitEx[1]
eachPixEx = currentAr.split('],')
eachPixInQ = inQuestion.split('],')
x = 0
while x < len(eachPixEx):
if eachPixEx[x] == eachPixInQ[x]:
matchedAr.append(int(currentNum))
x+=1
except Exception as e:
print(str(e))
x = Counter(matchedAr)
print(x)
graphX = []
graphY = []
ylimi = 0
for eachThing in x:
print(str(eachThing) + " " +str(x[eachThing]))
graphX.append(eachThing)
graphY.append(x[eachThing])
ylimi = x[eachThing]
fig = plt.figure()
ax1 = plt.subplot2grid((4,4),(0,0), rowspan=1, colspan=4)
ax2 = plt.subplot2grid((4,4),(1,0), rowspan=3,colspan=4)
ax1.imshow(iar)
ax2.bar(graphX,graphY,align='center')
plt.ylim(400)
xloc = plt.MaxNLocator(12)
ax2.xaxis.set_major_locator(xloc)
plt.show()
whatNumIsThis('images/test.png')
whatNumIsThis('images/numbers/9.5.png')
在代码中加入了createExamples()函数 。文本文件中基本包含了所有不同的数字以及它们的数组形式。现在我们只需要一个步骤:对比。当我们拿到一个数字并需要识别它时,我们只需尝试将该数字的图像数组和数据库中已有的数组进行对比。如果对比结果是一致的,则输出这个数字。 用一个函数用来对比指定图像和数据库中的图像数组。whatNumIsThis(filePath)这函数,参数为文件路径(filePath)。这个函数的基本功能是根据文件路径提取图像,将其转为数组,并跟数据库中的数组进行比对。分割函数可以分割所有像素数组。计数器可以记录每一次成功的对比。
运行结果:
list index out of range
Counter({2: 2766, 3: 2334, 6: 2244, 9: 2196, 5: 2190, 7: 2184, 8: 2166, 1: 1950, 4: 1926})
1 1950
2 2766
3 2334
4 1926
5 2190
6 2244
7 2184
8 2166
9 2196
像素数组最多次对比成功的数是2(2766次),并输入图像中的数也是2。因此,我们成功地识别图像。
再测试一个的示例:
list index out of range
Counter({9: 3060, 3: 2598, 8: 2514, 4: 2454, 6: 2388, 5: 2358, 7: 2340, 2: 2298, 1: 1878})
1 1878
2 2298
3 2598
4 2454
5 2358
6 2388
7 2340
8 2514
9 3060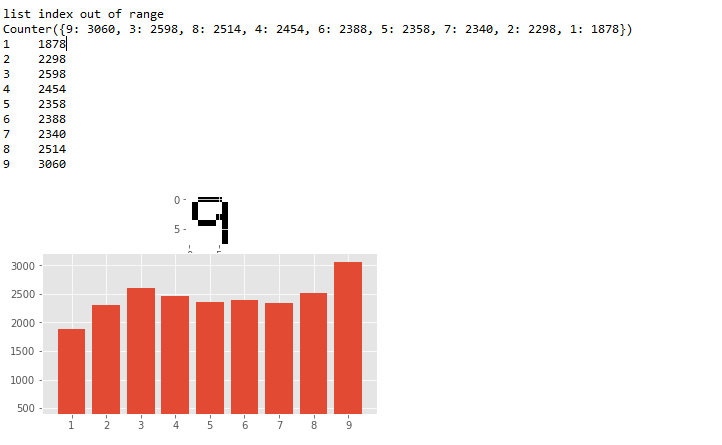
像素数组最多次对比成功的数是9(3060次),并输入图像中的数也是9。因此,我们成功地识别图像。
接下来,我们使用SciKitLearn提供的数据集,用Support Vector machine来进行分类。 SVM是监督学习分类器,它的工作原理是在我们给出一些标签数据之后,才开始对数据分类。
#导入matplotlib、sklearn
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn import svm
#skLearn带有数据集,导入这些数据集
digits =datasets.load_digits()
#使用SVM分类器
clf =svm.SVC(gamma =0.001,C=100)
# SVM是我们要用的分类器,digits.data是图像数组的特征集,digits.target是实际的数字
#digits.target是我们已经赋值给digits.data的标签
#取图像数组的特征集和标签的最后40个数据赋值给x,y
X,y =digits.data[:-40],digits.target[:-40]
#给数据和相应的图像数组数据贴标签
clf.fit(X,y)
# 训练数据集并拟合,输出结果并画图,预测第42个数。
print (" Prediction: " , clf.predict(digits.data[-42].reshape(1,-1)))
plt.imshow(digits.images[-42],cmap =plt.cm.gray_r,interpolation ='nearest')
plt.show()
#colormaps
#gray:0-255 级灰度,0:黑色,1:白色,黑底白字;
#gray_r:翻转 gray 的显示,如果 gray 将图像显示为黑底白字,gray_r 会将其显示为白底黑字;
运行结果如下:
SVM进行预测并正确标记,得到了数字6,也就是第42个数的值!
输入的第42个数的图片如下:

3980元团购原价19800元的AI课程,团购请加王家林老师微信13928463918
基于王家林老师独创的人工智能“项目情景投射”学习法,任何IT人员皆可在无需数学和Python语言的基础上的情况下3个月左右的时间成为AI技术实战高手:
1,五节课(分别在4月9-13号早上YY视频直播)教你从零起步(无需Python和数学基础)开发出自己的AI深度学习框架,五节课的学习可能胜过你五年的自我摸索;
2,30个真实商业案例代码中习得AI(从零起步到AI实战专家之路):10大机器学习案例、13大深度学习案例、7大增强学习案例(本文档中有案例的详细介绍和案例实现代码截图);
3,100天的涅槃蜕变,平均每天学习1个小时(周一到周六早上6:00-7:00YY频道68917580视频直播),周末复习每周的6个小时的直播课程(报名学员均可获得所有的直播视频、全部的商业案例完整代码、最具阅读价值的AI资料等)。
五节课从零起步(无需数学和Python基础)编码实现AI人工智能框架电子书V1
https://download.csdn.net/download/duan_zhihua/10380279
30个真实商业案例代码中成为AI实战专家(10大机器学习案例、13大深度学习案例、7大增强学习案例)课程大纲
https://download.csdn.net/download/duan_zhihua/10366665