Numbersand Strings:
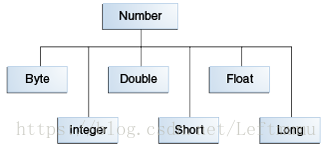
注:抽象类Number还有四个子类,BigDecimal and BigInteger 用于高精度计算。AtomicInteger and AtomicLong 用于多线程应用。
在以下三种情况你可能使用Number对象而不是原生数据类型:
1. 当方法的参数期望对象类型(经常在处理数字集合时使用List<Integer>)。
2. 当用于类定义的常量时,例如MIN_VALUE和 MAX_VALUE提供数据类型的上限和下限。
3. 使用类方法将值转换为其他基本类型以及从其他基本类型转换值,转换为字符串和从字符串转换,以及在数字系统(十进制,八进制,十六进制,二进制)。

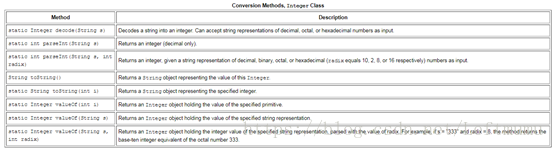

把数字转化为字符串
第一种:
int i;
// Concatenate "i" with an emptystring; conversion is handled for you.
String s1 = "" + i;
第二种:
// The valueOf class method.
String s2 = String.valueOf(i);
Each of the Number subclasses includes aclass method, toString(), that will convert its primitive type to a string. Forexample:
第三种:
int i;
double d;
String s3 = Integer.toString(i);
String s4 = Double.toString(d);
泛型:
使用泛型的好处:
1、编译时更强大的类型检查。
Java编译器将强类型检查应用于泛型代码,并在代码违反类型安全性时发出错误。修复编译时错误比修复运行时错误要容易得多。
2、消除类型转换。
The following code snippet without genericsrequires casting:
Listlist = new ArrayList();
list.add("hello");
String s= (String) list.get(0);
Whenre-written to use generics, the code does not require casting:
List<String>list = new ArrayList<String>();
list.add("hello");
String s= list.get(0); // no cast
3、让程序员实现泛型算法。
通过使用泛型,程序员可以实现泛型算法,这些泛型算法可以处理不同类型的集合,可以进行定制,并且类型安全,易于阅读。
The mostcommonly used type parameter names are:
E -Element (used extensively by the Java Collections Framework)
K - Key
N -Number
T - Type
V -Value
S,U,Vetc. - 2nd, 3rd, 4th types
Box<String>stringBox = new Box<>();
BoxrawBox = stringBox; // OK
But ifyou assign a raw type to a parameterized type, you get a warning:
BoxrawBox = new Box(); // rawBoxis a raw type of Box<T>
Box<Integer>intBox = rawBox; // warning:unchecked conversion
You alsoget a warning if you use a raw type to invoke generic methods defined in thecorresponding generic type:
Box<String>stringBox = new Box<>();
BoxrawBox = stringBox;
rawBox.set(8); // warning: unchecked invocation to set(T)
并发:
进程:一个进程有一个独立的执行环境。一个进程通常具有一套完整的私有基本运行时资源; 特别是每个进程都有自己的内存空间。
进程通常被视为程序或应用程序的代名词。但是,用户认为的单个应用程序实际上可能是一组协作的进程。为了促进进程之间的通信,大多数操作系统都支持进程间通信(IPC)资源,例如管道和套接字。 IPC不仅用于同一系统上的进程之间的通信,还用于不同系统上的进程。
线程:线程有时称为轻量级进程。进程和线程都提供了一个执行环境,但是创建一个新的线程比创建一个新的进程需要更少的资源。线程存在于一个进程内 - 每个进程至少有一个线程。 线程共享进程的资源,包括内存和开放的文件。这使得通信更为有效,但存在潜在的问题。
多线程执行是Java平台的一个基本特性。每个应用程序至少有一个线程,如果加上做内存管理和信号处理的“system”线程,则每个应用程序至少有几个线程。 但是从应用程序员的角度来看,你刚开始只启动了一个主线程,而这个线程有能力创建其他的线程。
The synchronized and volatile constructs,as well as the Thread.start() and Thread.join() methods, can formhappens-before relationships.
Reads and writes are atomic for referencevariables and for most primitive variables (all types except long and double).
Reads and writes are atomic for allvariables declared volatile (including long and double variables).
大型网站服务器案例
承受海量访问的动态Web应用
服务器配置:8 CPU, 8G MEM, JDK 1.6.X
参数方案:
-server -Xmx3550m -Xms3550m -Xmn1256m-Xss128k -XX:SurvivorRatio=6 -XX:MaxPermSize=256m -XX:ParallelGCThreads=8-XX:MaxTenuringThreshold=0 -XX:+UseConcMarkSweepGC
调优说明:
● -Xmx 与 -Xms 相同以避免JVM反复重新申请内存。-Xmx 的大小约等于系统内存大小的一半,即充分利用系统资源,又给予系统安全运行的空间。
● -Xmn1256m 设置年轻代大小为1256MB。此值对系统性能影响较大,Sun官方推荐配置年轻代大小为整个堆的3/8。
● -Xss128k 设置较小的线程栈以支持创建更多的线程,支持海量访问,并提升系统性能。
● -XX:SurvivorRatio=6 设置年轻代中Eden区与Survivor区的比值。系统默认是8,根据经验设置为6,则2个Survivor区与1个Eden区的比值为2:6,一个Survivor区占整个年轻代的1/8。
● -XX:ParallelGCThreads=8 配置并行收集器的线程数,即同时8个线程一起进行垃圾回收。此值一般配置为与CPU数目相等。
● -XX:MaxTenuringThreshold=0 设置垃圾最大年龄(在年轻代的存活次数)。如果设置为0的话,则年轻代对象不经过Survivor区直接进入年老代。对于年老代比较多的应用,可以提高效率;如果将此值设置为一个较大值,则年轻代对象会在Survivor区进行多次复制,这样可以增加对象再年轻代的存活时间,增加在年轻代即被回收的概率。根据被海量访问的动态Web应用之特点,其内存要么被缓存起来以减少直接访问DB,要么被快速回收以支持高并发海量请求,因此其内存对象在年轻代存活多次意义不大,可以直接进入年老代,根据实际应用效果,在这里设置此值为0。
● -XX:+UseConcMarkSweepGC 设置年老代为并发收集。CMS(ConcMarkSweepGC)收集的目标是尽量减少应用的暂停时间,减少Full GC发生的几率,利用和应用程序线程并发的垃圾回收线程来标记清除年老代内存,适用于应用中存在比较多的长生命周期对象的情况。
基本I/O流:
I / O流,这是一个功能强大的概念,大大简化了I / O操作。
序列化,它使程序可以将整个对象写入流中并再次读取。
I/O Streams:java.io包 File I/O:java.nio.file包
- Byte Streams handle I/O of raw binary data.
- Character Streams handle I/O of character data, automatically handling translation to and from the local character set.
- Buffered Streams optimize input and output by reducing the number of calls to the native API.
- Scanning and Formatting allows a program to read and write formatted text.
- I/O from the Command Line describes the Standard Streams and the Console object.
- Data Streams handle binary I/O of primitive data type and String values.
- Object Streams handle binary I/O of objects.
- What is a Path? examines the concept of a path on a file system.
- The Path Class introduces the cornerstone class of the java.nio.file package.
- Path Operations looks at methods in the Path class that deal with syntactic operations.
- File Operations introduces concepts common to many of the file I/O methods.
- Checking a File or Directory shows how to check a file's existence and its level of accessibility.
- Deleting a File or Directory.
- Copying a File or Directory.
- Moving a File or Directory.
- Managing Metadata explains how to read and set file attributes.
- Reading, Writing and Creating Files shows the stream and channel methods for reading and writing files.
- Random Access Files shows how to read or write files in a non-sequentially manner.
- Creating and Reading Directories covers API specific to directories, such as how to list a directory's contents.
- Links, Symbolic or Otherwise covers issues specific to symbolic and hard links.
- Walking the File Tree demonstrates how to recursively visit each file and directory in a file tree.
- Finding Files shows how to search for files using pattern matching.
- Watching a Directory for Changes shows how to use the watch service to detect files that are added, removed or updated in one or more directories.
- Other Useful Methods covers important API that didn't fit elsewhere in the lesson.
- Legacy File I/O Code shows how to leverage Path functionality if you have older code using the java.io.File class. A table mapping java.io.File API to java.nio.file API is provided.
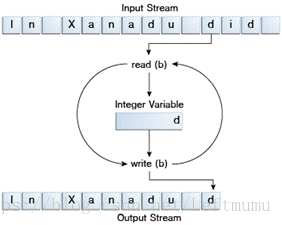
I / O流表示输入源或输出目标。 流可以表示许多不同类型的源和目标,包括磁盘文件,设备,其他程序和内存数组。流支持许多不同类型的数据,包括简单字节,原始数据类型,本地化字符和对象。有些流只是传递数据。其他流以适当的方式操作和转换数据。
无论内部是如何工作的,所有流都使用相同的简单模型:流是数据序列。程序使用输入流从源读取数据,每次一项:
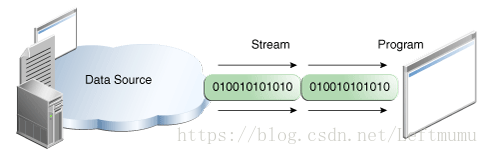
Readinginformation into a program.
程序使用输出流将数据写入目标数据源,每次一项:
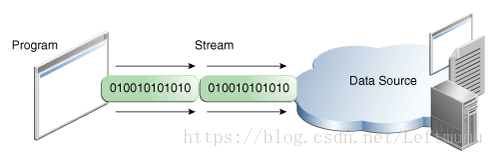
Writinginformation from a program.
上图中的数据源和数据目标可以是保存、生成或使用数据的任何东西。显然这包括磁盘文件,但源或目标也可以是另一个程序,外围设备,网络套接字或阵列。
Byte Streams:
程序使用byte streams来执行8位字节的输入和输出。所有的字节流类都来自InputStream和OutputStream。
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
public class CopyBytes {
public static void main(String[] args) throws IOException {
FileInputStream in = null;
FileOutputStream out = null;
try {
in = new FileInputStream("xanadu.txt");
out = new FileOutputStream("outagain.txt");
int c;
while ((c = in.read()) != -1) {
out.write(c);
}
} finally {
if (in != null) {
in.close();
}
if (out != null) {
out.close();
}
}
}
}
AlwaysClose Streams:
当不再需要流时关闭流非常重要 - 如此重要以至于CopyBytes使用finally块来保证即使程序发生错误,两个流也将被关闭。这种做法有助于避免严重的资源泄漏。
一个可能的错误是CopyBytes无法打开一个或两个文件。当发生这种情况时,对应于该文件的流变量不会从其初始空值更改。这就是为什么CopyBytes在调用close之前确保每个流变量都包含对象引用的原因。
Character Streams
Java平台约定使用Unicode存储字符值。字符流I / O会自动将此内部格式转换为本地字符集并从本地字符集转换。在西方语言环境中,本地字符集通常是ASCII的8位超集。
对于大多数应用程序来说,字符流的I / O不会比字节流的I / O复杂。使用流类进行的输入和输出将自动转换为本地字符集,并从本地字符集自动转换。使用字符流代替字节流的程序会自动适应本地字符集,并且可以进行国际化 - 所有这些都不需要编程人员的额外努力。
如果国际化不是一个优先事项,那么您可以简单地使用字符流类而不必太在意字符集问题。之后,如果需要考虑国际化,那么您的程序就可以在不进行大量重新编码的情况下满足要求。更多信息,请参阅国际化章节。
Using Character Streams
import java.io.FileReader;
import java.io.FileWriter;
import java.io.IOException;
public class CopyCharacters {
public static void main(String[] args) throws IOException {
FileReader inputStream = null;
FileWriter outputStream = null;
try {
inputStream = new FileReader("xanadu.txt");
outputStream = new FileWriter("characteroutput.txt");
int c;
while ((c = inputStream.read()) != -1) {
outputStream.write(c);
}
} finally {
if (inputStream != null) {
inputStream.close();
}
if (outputStream != null) {
outputStream.close();
}
}
}
}
重要:CopyCharacters is verysimilar to CopyBytes. The most important difference is that CopyCharacters usesFileReader and FileWriter for input and output in place of FileInputStream andFileOutputStream. Notice that both CopyBytes and CopyCharacters use an intvariable to read to and write from. However, in CopyCharacters, the int variableholds a character value in its last 16 bits; in CopyBytes, the int variableholds a byte value in its last 8 bits.
Character Streams that Use Byte Streams:
字符流通常是字节流的“包装”。 字符流使用字节流来执行物理I / O,而字符流处理字符和字节之间的转换。例如,FileReader使用FileInputStream,而FileWriter使用FileOutputStream。
有两个通用的字节到字符“桥”流:InputStreamReader和OutputStreamWriter。当没有预先包装的字符流类满足您的需求时,使用它们来创建字符流。之后会学到如何从socket类提供的字节流中创建字符流。
Line-Oriented I/O:
字符I / O通常出现在比单个字符更大的单位中。一个常见的单位是行:在末尾有一个行结束符的字符串。 一个行终止符可以是一个回车换行符(“\ r \ n”),一个单一的回车符(“\r”)或一个换行符(“\ n”)。支持所有可能的行终止符允许程序读取任何广泛使用的操作系统上创建的文本文件。
line-orientedI/O:BufferedReader and PrintWriter
import java.io.FileReader;
import java.io.FileWriter;
import java.io.BufferedReader;
import java.io.PrintWriter;
import java.io.IOException;
public class CopyLines {
public static void main(String[] args) throws IOException {
BufferedReader inputStream = null;
PrintWriter outputStream = null;
try {
inputStream = new BufferedReader(newFileReader("xanadu.txt"));
outputStream = new PrintWriter(new FileWriter("characteroutput.txt"));
String l;
while ((l = inputStream.readLine()) != null) {
outputStream.println(l);
}
} finally {
if (inputStream != null) {
inputStream.close();
}
if (outputStream != null) {
outputStream.close();
}
}
}
}
Invoking readLine returnsa line of text with the line. CopyLines outputs each line using println, which appends the line terminator for thecurrent operating system. This might not be the sameline terminator that was used in the input file.
Buffered Streams
到目前为止,我们看到的大多数例子都是使用无缓冲的I / O。这意味着每个读取或写入请求都是由底层OS直接处理的。这可能会使程序效率低得多,因为每个这样的请求通常会触发磁盘访问,网络访问或其他相对代价高的操作。
为了减少这种开销,Java平台实现了缓冲的I / O流。缓冲输入流从称为缓冲区的存储区读取数据; 本机输入API仅在缓冲区为空时调用。同样,缓冲输出流将数据写入缓冲区,只有在缓冲区满时才调用本地输出API。
程序可以使用我们已经使用过几次的包装方式将未缓冲的流转换为缓冲流,其中未缓冲的流对象被传递给缓冲流类的构造函数。以下是如何修改CopyCharacters示例中的构造函数调用以使用缓冲的I / O:
inputStream =new BufferedReader(new FileReader("xanadu.txt"));
outputStream =new BufferedWriter(new FileWriter("characteroutput.txt"));
有四个缓冲流类用于包装未缓冲的流:BufferedInputStream和BufferedOutputStream创建缓冲的字节流,而BufferedReader和BufferedWriter创建缓冲的字符流。
Flushing Buffered Streams
在关键时候把数据写出缓冲区通常很有意义,而不用等待缓冲区满。这通常被称为刷新缓冲区。
一些缓冲的输出类支持由一个可选的构造函数参数指定的autoflush。 当启用autoflush时,某些关键事件会导致缓冲区被刷新。 例如,一个autoflush的 PrintWriter对象在每次调用println或format时刷新缓冲区。有关这些方法的更多信息,请参阅具体章节。
要手动刷新流,请调用其flush方法。 flush方法可以应用在任何输出流上,不过,除非是缓冲流,否则没效果。
Scanning and Formatting
编程I / O通常涉及在人类喜欢使用的整齐格式化的数据与机器数据之间的转换。 为了帮助你完成这些杂事,Java平台提供了两个API。Scanner API将输入分为与数据位相关的单个token。Formattin API负责将数据组装成格式良好,人性化的格式。
Scanning
Scanner类型的对象可用于将格式化的输入分解为token,并根据其数据类型来转换单个token。
Breaking Input into Tokens
默认情况下,scanner使用空白区分tokens。(空白字符包括空格,制表符和行结束符,完整列表请参考Character.isWhitespace的文档)。为了了解scanner是如何工作的,我们来看看ScanXan,一个用来读取xanadu.txt中的单词的程序 并打印出来,每行一个。
import java.io.*;
import java.util.Scanner;
public class ScanXan {
public static void main(String[] args) throws IOException {
Scanner s = null;
try {
s = new Scanner(new BufferedReader(newFileReader("xanadu.txt")));
while (s.hasNext()) {
System.out.println(s.next());
}
} finally {
if (s != null) {
s.close();
}
}
}
}
Noticethat ScanXan invokes Scanner's close method when it isdone with the scanner object. Even though a scanner is not a stream, you needto close it to indicate that you're done with its underlying stream.
To use adifferent token separator, invoke useDelimiter(), specifying a regularexpression. For example, suppose you wanted the token separator to be a comma,optionally followed by white space. You would invoke,
s.useDelimiter(",\\s*");
Translating Individual Tokens
ScanXan示例将所有输入tokens视为简单的String值。Scanner还支持所有Java语言的基本类型(char除外)以及BigInteger和BigDecimal。 此外,数值可以使用千位分隔符。因此,在美国语言环境中,Scanner正确读取字符串“32,767”作为整数值。
我们不得不提到语言环境,因为千位分隔符和小数点符号是特定于语言环境的。因此,如果我们没有指定scanner应该使用美国语言环境,则以下示例将不能在所有语言环境中都正常工作。这通常不需要担心,因为输入数据通常来自使用相同语言环境的源。但是这个例子是Java教程的一部分,并且分布在世界各地。
import java.io.FileReader;
import java.io.BufferedReader;
import java.io.IOException;
import java.util.Scanner;
import java.util.Locale;
public class ScanSum {
public static void main(String[] args) throws IOException {
Scanner s = null;
double sum = 0;
try {
s = new Scanner(new BufferedReader(new FileReader("usnumbers.txt")));
s.useLocale(Locale.US);
while (s.hasNext()) {
if (s.hasNextDouble()) {
sum += s.nextDouble();
} else {
s.next();
}
}
} finally {
s.close();
}
System.out.println(sum);
}
}
Formatting
实现格式化的Stream对象是PrintWriter(字符流类)或PrintStream(一个字节流类)。
Note: The only PrintStream objects you are likely to need areSystem.out and System.err. (See I/O fromthe Command Line for more on these objects.) Whenyou need to create a formatted output stream, instantiate PrintWriter, notPrintStream.
像所有的字节和字符流对象一样,PrintStream和PrintWriter的实例为简单的字节和字符输出实现了一套标准的写入方法。另外,PrintStream和PrintWriter都实现了将内部数据转换为格式化输出的同一套方法。提供了两个级别的格式:
- print and println format individual values in a standard way.
- format formats almost any number of values based on a format string, with many options for precise formatting.
The format Method
The format methodformats multiple arguments based on a format string. The formatstring consists of static text embedded with format specifiers;except for the format specifiers, the format string is output unchanged.
Format stringssupport many features. In this tutorial, we'll just cover some basics. For acomplete description, see format string syntax in the API specification.
public class Root2 {
public static void main(String[] args) {
int i = 2;
double r = Math.sqrt(i);
System.out.format("The square root of %d is %f.%n", i, r);
}
}
Here is the output:
The square root of 2 is 1.414214.
Like the threeused in this example, all format specifiers begin with a % and endwith a 1- or 2-character conversion that specifies the kind offormatted output being generated. The three conversions used here are:
- d formats an integer value as a decimal value.
- f formats a floating point value as a decimal value.
- n outputs a platform-specific line terminator.
Here are someother conversions:
- x formats an integer as a hexadecimal value.
- s formats any value as a string.
- tB formats an integer as a locale-specific month name.
Note:
Except for %% and %n, all format specifiersmust match an argument. If they don't, an exception is thrown.
In the Java programming language, the \n escapealways generates the linefeed character (\u000A). Don't use \n unlessyou specifically want a linefeed character. To get the correct line separatorfor the local platform, use %n.
The additionalelements are all optional. The following figure shows how the longer specifierbreaks down into elements.
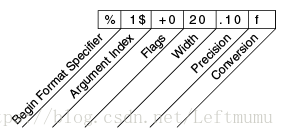
Elements of a Format Specifier.
The elementsmust appear in the order shown. Working from the right, the optional elementsare:
- Precision. For floating point values, this is the mathematical precision of the formatted value. For s and other general conversions, this is the maximum width of the formatted value; the value is right-truncated if necessary.
- Width. The minimum width of the formatted value; the value is padded if necessary. By default the value is left-padded with blanks.
- Flags specify additional formatting options. In the Format example, the + flag specifies that the number should always be formatted with a sign, and the 0 flag specifies that 0 is the padding character. Other flags include - (pad on the right) and , (format number with locale-specific thousands separators). Note that some flags cannot be used with certain other flags or with certain conversions.
- The Argument Index allows you to explicitly match a designated argument. You can also specify < to match the same argument as the previous specifier. Thus the example could have said: System.out.format("%f, %<+020.10f %n", Math.PI);
I/O from the Command Line
程序通常从命令行运行,并在命令行环境中与用户交互。Java平台通过两种方式支持这种交互:通过标准流(StandardStreams)和控制台(Console)。
Standard Streams
标准流是许多操作系统的特征。默认情况下,它们从键盘读取输入并将输出写入显示器。它们还支持文件和程序之间的I / O,但是该功能是由命令行解释器而不是程序控制的。
The Javaplatform supports three Standard Streams: Standard Input, accessed throughSystem.in; Standard Output, accessed through System.out; and Standard Error,accessed through System.err. These objects are defined automatically and do notneed to be opened. Standard Output and Standard Error are both for output;having error output separately allows the user to divert regular output to afile and still be able to read error messages. For more information, refer tothe documentation for your command line interpreter.
You might expectthe Standard Streams to be character streams, but, for historical reasons, theyare byte streams. System.out and System.err aredefined as PrintStream objects. Although it is technically a byte stream,PrintStream utilizes an internal character stream object to emulate many of thefeatures of character streams.
By contrast,System.in is a byte stream with no character streamfeatures. To use Standard Input as a character stream, wrap System.in inInputStreamReader.
InputStreamReader cin = newInputStreamReader(System.in);
The Console
控制台是标准数据流的更高级替代品。这个Console是单独的、预定义对象,具有标准流提供的大部分功能,而且还有其他功能。控制台对安全的密码输入特别有用。Console对象还通过其reader和writer方法提供真正的字符流的输入和输出流。
在程序可以使用Console之前,它必须尝试通过调用System.console()来检索Console对象。 如果Console对象可用,则此方法返回它。 如果System.console返回NULL,则不允许使用控制台操作,要么是因为操作系统不支持它们,或者因为程序是在非交互式环境中启动的。
Console对象通过readPassword方法支持安全的密码输入。这种方法有两种方式来帮助确保密码输入。首先,它抑制回声,所以密码在用户的屏幕上是不可见的。其次,readPassword返回一个字符数组,而不是一个String,所以密码可以被覆盖,一旦不再需要,就从内存中删除它。
Data Streams
数据流支持基本数据类型值(布尔型,字符型,字节型,短整型,整型,长整型,浮点型和双精度型)的二进制I / O以及字符串值。所有数据流都实现DataInput接口或DataOutput接口。 本节重点介绍这些接口中最广泛使用的实现,DataInputStream和DataOutputStream。
Notice thatDataStreams detects an end-of-file condition by catching EOFException, instead of testing for an invalid returnvalue. All implementations of DataInput methods use EOFException instead ofreturn values.
Also notice thateach specialized write in DataStreams is exactly matched by the correspondingspecialized read. It is up to the programmer to make sure that output types andinput types are matched in this way: The input stream consists of simple binarydata, with nothing to indicate the type of individual values, or where theybegin in the stream.
DataStreams usesone very bad programming technique: it uses floating point numbers to representmonetary values. In general, floating point is bad for precise values. It'sparticularly bad for decimal fractions, because common values (such as 0.1) donot have a binary representation.
The correct typeto use for currency values is java.math.BigDecimal. Unfortunately, BigDecimal is anobject type, so it won't work with data streams. However, BigDecimal will workwith object streams, which are covered in the next section.
Object Streams
正如数据流支持基本数据类型的I / O一样,对象流支持对象的I / O。大多数(但不是全部)标准类支持对象的序列化。那些确实实现标记接口Serializable的。
对象流类是ObjectInputStream和ObjectOutputStream。这些类实现了ObjectInput和ObjectOutput,它们是DataInput和DataOutput的子接口。这意味着数据流中包含的所有基本数据I / O方法也都在对象流中实现。 所以对象流可以包含基本数据类型值和对象值的混合。
如果readObject()没有返回期望的对象类型,试图将其转换为正确的类型可能会抛出ClassNotFoundException异常。 在这个简单的例子中,这是不可能发生的,所以我们不试图捕捉异常。相反,我们通知编译器,我们知道这个问题,通过在main方法的throws子句中添加ClassNotFoundException。
Output and Input of Complex Objects
writeObject和readObject方法使用简单,但它们包含一些非常复杂的对象管理逻辑。 这对于像Calendar这样封装原始值的类来说并不重要。 但是许多对象包含对其他对象的引用。如果readObject要从流中重构对象,则必须能够重构原始对象所引用的所有对象。这些额外的对象可能有自己的引用,等等。在这种情况下,writeObject将遍历整个对象引用网,并将该网中的所有对象写入流中。 因此,writeObject的单个调用可以导致大量的对象被写入到流中。

I/O of multiple referred-to objects
You might wonderwhat happens if two objects on the same stream both contain references to asingle object. Will they both refer to a single object when they're read back?The answer is "yes." A stream can only contain one copy of an object,though it can contain any number of references to it. Thus if you explicitlywrite an object to a stream twice, you're really writing only the referencetwice. For example, if the following code writes an object ob twiceto a stream:
Object ob = newObject();
out.writeObject(ob);
out.writeObject(ob);
Each writeObject hasto be matched by a readObject, so the code that reads the stream back willlook something like this:
Object ob1 =in.readObject();
Object ob2 =in.readObject();
This results intwo variables, ob1 and ob2, that are references to a singleobject.
However, if asingle object is written to two different streams, it is effectively duplicated— a single program reading both streams back will see two distinct objects.
File I/O (Featuring NIO.2)
文件系统以某种形式的媒介(通常是一个或多个硬盘驱动器)存储和组织文件,以便于检索。目前使用的大多数文件系统都以树(或分层)结构存储文件。树顶部是一个(或多个)根节点。在根节点下,有文件和目录(Microsoft Windows中的文件夹)。 每个目录可以包含文件和子目录,这些文件和子目录又可以包含文件和子目录等等,可能具有几乎无限的深度。
Relative and absolute
路径要么是相对的要么是绝对的。绝对路径总是包含根元素和查找文件所需的完整目录列表。例如,/ home / sally / statusReport是一个绝对路径。找到文件所需的所有信息都包含在路径字符串中。
相对路径需要与其他路径结合才能访问文件。例如,joe / foo是一个相对路径。 没有更多的信息,程序就无法可靠地在文件系统中找到joe / foo目录。
symbloic links
符号链接也被称为符号链接或软链接。一个符号链接是一个特殊的文件,作为另一个文件的引用。大多数情况下,符号链接对应用程序是透明的,符号链接上的操作会自动重定向到链接的目标。(被指向的文件或目录被称为链接的target。)例外情况是当符号链接被删除或重命名时,在这种情况下,被删除或重命名的是符号链接本身,而不是链接的目标。