并行数据处理与性能
在Java 7之前,并行处理数据集合非常麻烦。第一,你得明确地把包含数据的数据结构分成若干子部分。第二,你要给每个子部分分配一个独立的线程。第三,你需要在恰当的时候对它们进行同步来避免不希望出现的竞争条件,等待所有线程完成,最后把这些部分结果合并起来。Java 7引入了一个叫作分支/合并的框架,让这些操作更稳定、更不易出错。 在本章中,你将了解Stream接口如何让你不用太费力气就能对数据集执行并行操作。它允许你声明性地将顺序流变为并行流。此外,你将看到Java是如何变戏法的,或者更实际地来说,流是如何在幕后应用Java 7引入的分支/合并框架的。你还会发现,了解并行流内部是如何工作的很重要,因为如果你忽视这一方面,就可能因误用而得到意外的(很可能是错的)结果。我们会特别演示,在并行处理数据块之前,并行流被划分为数据块的方式在某些情况下恰恰是这些错误且无法解释的结果的根源。因此,你将会学习如何通过实现和使用你自己的Spliterator来控制这个划分过程。
并行数据处理
我们简要地提到了Stream接口可以让你非常方便地处理它的元素:可以通过对收集源调用parallelStream方法来把集合转换为并行流。并行流就是一个把内容分成多个数据块,并用不同的线程分别处理每个数据块的流。这样一来,你就可以自动把给定操作的工作负荷分配给多核处理器的所有内核,让它们都忙起来。
public void demo1(){
// 生成自然数无限流,对前1000个数字求和
Long reduce = Stream.iterate(1L, i -> i + 1)
.limit(1000)
.reduce(0L, Long::sum);
System.out.println(reduce);
// 用更为传统的Java术语来说,这段代码与下面的迭代等价:
// public static long iterativeSum(long n) {
// long result = 0;
// for (long i = 1L; i <= n; i++) {
// result += i;
// }
// return result;
// }
// 你可以把流转换成并行流,从而让前面的函数归约过程(也就是求和)并行运行——对顺序流调用parallel方法:
Long reduceParallel = Stream.iterate(1L, i -> i + 1)
.limit(1000)
.parallel()
.reduce(0L, Long::sum);
System.out.println(reduceParallel);
/**
* 请注意,在现实中,对顺序流调用parallel方法并不意味着流本身有任何实际的变化。它
* 在内部实际上就是设了一个boolean标志,表示你想让调用parallel之后进行的所有操作都并
* 行执行。类似地,你只需要对并行流调用sequential方法就可以把它变成顺序流。请注意,你
* 可能以为把这两个方法结合起来,就可以更细化地控制在遍历流时哪些操作要并行执行,哪些要
* 顺序执行。例如,你可以这样做:
*/
ArrayList<User> userList = Lists.newArrayList();
userList.add(User.builder().sex("女").name("小红").type(true).uId(10).build());
userList.add(User.builder().sex("女").name("小花").type(false).uId(11).build());
userList.add(User.builder().sex("男").name("小张").type(true).uId(12).build());
userList.add(User.builder().sex("男").name("小网").type(false).uId(13).build());
userList.add(User.builder().sex("男").name("小里").type(true).uId(14).build());
Integer reduceSequential = userList.stream().parallel()
.filter(val -> val.getUId() > 10)
.sequential()
.map(user -> user.getUId())
.limit(3)
.parallel()
.reduce(0, Integer::sum);
System.out.println(reduceSequential);
/**
* 留意装箱。自动装箱和拆箱操作会大大降低性能。Java 8中有原始类型流(IntStream、
* LongStream、DoubleStream)来避免这种操作,但凡有可能都应该用这些流。
*
* 要考虑流背后的数据结构是否易于分解。例如,ArrayList的拆分效率比LinkedList
* 高得多,因为前者用不着遍历就可以平均拆分,而后者则必须遍历
*/
}图7-3 分支/合并过程

你可能已经注意到,这只不过是著名的分治算法的并行版本而已。这里举一个用分支/合并框架的实际例子,还以前面的例子为基础,让我们试着用这个框架为一个数字范围(这里用一个long[]数组表示)求和。如前所述,你需要先为RecursiveTask类做一个实现,就是下面代码清单中的ForkJoinSumCalculator。

现在编写一个方法来并行对前
n
个自然数求和就很简单了。你只需把想要的数字数组传给
ForkJoinSumCalculator
的构造函数:
public static long forkJoinSum(long n) {
long[] numbers = LongStream.rangeClosed(1, n).toArray();
ForkJoinTask<Long> task = new ForkJoinSumCalculator(numbers);
return new ForkJoinPool().invoke(task);
}运行ForkJoinSumCalculator
当把ForkJoinSumCalculator任务传给ForkJoinPool时,这个任务就由池中的一个线程
执行,这个线程会调用任务的compute方法。该方法会检查任务是否小到足以顺序执行,如果不
够小则会把要求和的数组分成两半,分给两个新的ForkJoinSumCalculator,而它们也由
ForkJoinPool安排执行。因此,这一过程可以递归重复,把原任务分为更小的任务,直到满足
不方便或不可能再进一步拆分的条件(本例中是求和的项目数小于等于10 000)。这时会顺序计
算每个任务的结果,然后由分支过程创建的(隐含的)任务二叉树遍历回到它的根。接下来会合
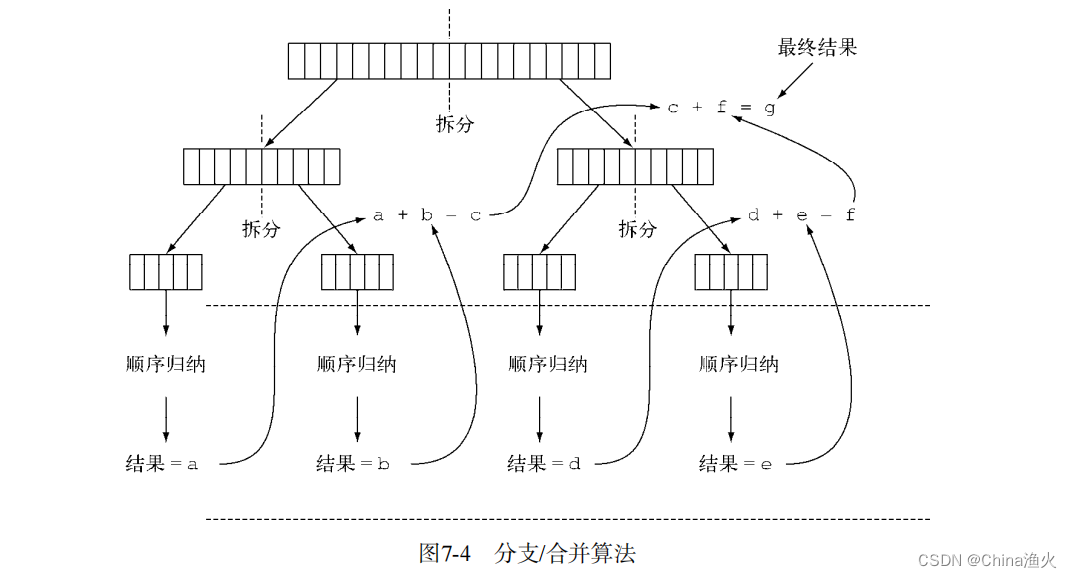
并每个子任务的部分结果,从而得到总任务的结果。这一过程如图7-4所示:
Spliterator接口
Spliterator是Java 8中加入的另一个新接口;这个名字代表“可分迭代器”(splitable
iterator)。和Iterator一样,Spliterator也用于遍历数据源中的元素,但它是为了并行执行
而设计的。虽然在实践中可能用不着自己开发Spliterator,但了解一下它的实现方式会让你
对并行流的工作原理有更深入的了解。
Java 8已经为集合框架中包含的所有数据结构提供了一个
默认的Spliterator实现。集合实现了Spliterator接口,接口提供了一个spliterator方法。
这个接口定义了若干方法,如下面的代码清单所示。
public interface Spliterator<T> {
boolean tryAdvance(Consumer<? super T> action);
Spliterator<T> trySplit();
long estimateSize();
int characteristics();
}与往常一样,T是Spliterator遍历的元素的类型。tryAdvance方法的行为类似于普通的 Iterator,因为它会按顺序一个一个使用Spliterator中的元素,并且如果还有其他元素要遍 历就返回true。但trySplit是专为Spliterator接口设计的,因为它可以把一些元素划出去分 给第二个Spliterator(由该方法返回),让它们两个并行处理。
Spliterator还可通过 estimateSize方法估计还剩下多少元素要遍历,因为即使不那么确切,能快速算出来是一个值 也有助于让拆分均匀一点。 重要的是,要了解这个拆分过程在内部是如何执行的,以便在需要时能够掌控它。
拆分过程:

将Stream拆分成多个部分的算法是一个递归过程,如图7-6所示。第一步是对第一个
Spliterator调用trySplit,生成第二个Spliterator。
第二步对这两个Spliterator调用 trysplit,这样总共就有了四个Spliterator。这个框架不断对Spliterator调用trySplit 直到它返回null,表明它处理的数据结构不能再分割,如第三步所示。最后,这个递归拆分过 程到第四步就终止了,这时所有的Spliterator在调用trySplit时都返回了null。
这个拆分过程也受Spliterator本身的特性影响,而特性是通过characteristics方法声
明的。
Spliterator的特性:
Spliterator接口声明的最后一个抽象方法是characteristics,它将返回一个int,代
表Spliterator本身特性集的编码。使用Spliterator的客户可以用这些特性来更好地控制和
优化它的使用。
最后实现你自己的 Spliterator...