文章列表
1.深度学习基础模型算法原理及编程实现–01.感知机.
2.深度学习基础模型算法原理及编程实现–02.线性单元 .
3.深度学习基础模型算法原理及编程实现–03.全链接 .
4.深度学习基础模型算法原理及编程实现–04.改进神经网络的方法 .
5.深度学习基础模型算法原理及编程实现–05.卷积神经网络.
6.深度学习基础模型算法原理及编程实现–06.循环神经网络.
9.深度学习基础模型算法原理及编程实现–09.自编码网络.
10.深度学习基础模型算法原理及编程实现–10.优化方法:从梯度下降到NAdam.
11.深度学习基础模型算法原理及编程实现–11.构建简化版的tensorflow—MiniFlow【实现MLP对MNIST数据分类】.
…
1 构建简化版的tensorflow—MiniFlow,并实现MLP对MNIST数据进行分类
本节将介绍如何开发一个小型的神经网络库,通过这个过程的学习,我们会理解微分图及方向传播的机理。
1.1 抽象节点类—Node
首先建立一个Node类来抽象表示所有普通节点。不难知道,每个节点都有输入节点及输出节点,在Node类的构造函数中添加了两个列表:inbound_nodes表示对用于存储传入节点的列表的引用;outbound_nodes表示对用于存储输出节点的列表的引用。虽然输出节点个数可能很多,但每个节点的输出值只有一个,用value表示,初始化为None,表示该值存在,但具体值尚未设定。
对神经网络了解的话就不难知道,每个节点都应该有前向计算和反向计算这两个过程。这里暂时为这两个过程添加一个占位符方法。
class Node(object):
'''Node类表示普通节点,定义了每个节点都具有的基本属性'''
def __init__(self, inbound_nodes=[]):
'''
每个节点可以从其他多个节点那接收输入 ---> 添加列表:用于存储对传入节点的引用
每个节点都会有一个输出【用于传递给其他多个节点】 ---> 添加列表:用于存储对传出节点的引用。
每个节点将最终计算出一个表示输出的值。我们将 value 初始化为 None,表示该值存在,但是尚未设定。
'''
#从构造函数的形参中获得当前节点的传入节点
self.inbound_nodes= inbound_nodes
#设定当前节点的输出节点,输出节点为空列表[],表示该值存在,但具体节点有哪些还没确定
#具体的输出节点会在 其输出节点的初始化函数中 被添加到输出节点列表中, 实现如下
self. outbound_nodes = []
# 对每个传入节点的属性outbound_nodes添加当前节点,表示当前节点是传入节点的输出节点之一
for n in self.inbound_nodes:
n.outbound_nodes.append(self)
# A calculated value
self.value = None
def forward(self):
"""
前向传播函数【如果没有实现,称为占位符方法】
"""
# return NotImplemented
raise NotImplemented
def backward(self):
"""
反向传播函数【如果没有实现,称为占位符方法,子类如果调用该函数的前提是必须实现它】
"""
raise NotImplementedError1.2 Node的子类
Node类是一个抽象类,定义了每个节点都具有的基本属性,但是只有Node的特殊子类会出现在图表中。下面将构建可进行计算和存储值的Node子类。例如,考虑Node的Input子类。
1.2.1 placeholder(占位符节点,功能仿造tensorflow中的placeholder, 用于存放输入数据和标签数据)
class placeholder(Node):
'''占位符节点,功能仿造tensorflow中的placeholder,用于存放输入数据'''
def __init__(self,name=[]):
'''输入层的节点没有传入节点(inbound nodes),所有无需向构造函数中传递任何inbound nodes'''
Node.__init__(self,name=name)
feed_dict_inside[self] = None #在字典feed_dict_inside中添加占位符节点的键值,并初始化为None
def forward(self, value=None):
if value is not None:
self.value = value成员变量value可以被明确地设置,也可以用 forward() 方法进行设置。该值然后会传递给神经网络的其他节点。
1.2.2 variable(变量节点,功能仿造tensorflow中的variable,用于存放输入权重系数及偏执系数)
class variable(Node):
'''变量节点,功能仿造tensorflow中的variable,用于存放输入权重系数及偏执系数'''
def __init__(self, value, name=[]):
'''输入层的节点没有传入节点(inbound nodes),所有无需向构造函数中传递任何inbound nodes'''
self.value = value
Node.__init__(self,name=name,value=value)
L.append(self) #将variable存入节点列表L中
trainables.append(self) #将variable添加进trainables列表中
def forward(self, value=None):
if value is not None:
self.value = value成员变量value可以被明确地设置,也可以用 forward() 方法进行设置。该值然后会传递给神经网络的其他节点。
1.2.3 Add子类(对Input实例进行加法运算)
Add是对多个输入节点进行相加,因此Add类必须有传入节点,且传入节点需要封装成列表传入基类Node的构造函数中。
class Add(Node):
'''add 是 Node 的另一个子类,实际上可以进行计算(加法)。'''
def __init__(self, x, y):
'''Input类没有传入节点,而Add类具有2个传入节点x和y,并将这两个节点的值相加。'''
Node.__init__(self, [x, y]) # 调用Node的构造函数
def forward(self):
x_value = self.inbound_nodes[0].value
y_value = self.inbound_nodes[1].value
self.value = x_value + y_value1.3 前向传播
定义好节点后,需要定义节点的操作顺序。因为部分节点的输入取决于其他节点的输出,需要按拓扑排序的方法扁平化图表(示例如下)。
1.3.1 topological_sort() ,拓扑排序方法:Kahn算法
如图中有向图所示,箭头的起点(前驱)必须在箭头终点(后继)之前完成,这种有向图称为活动网络,记做AOV网络。不含有向回路的有向图称为有向无环图。将有向无环图全部顶点排列成一个线性有序的序列、使得AOV网络中所有存在前驱和后继关系都得到满足的过程,称为拓扑排序。AOV网络的拓扑有序序列可能不唯一。常用的Kahn算法拓扑排序算法为Kahn算法:
(1)从有向图中选择一个没有前驱(即入度为0)的顶点并且输出它;
(2)从网中删去该顶点,并且删去从该顶点发出的全部有向边;
(3)重复上述两步,直到剩余的网中不再存在没有前趋的顶点为止。
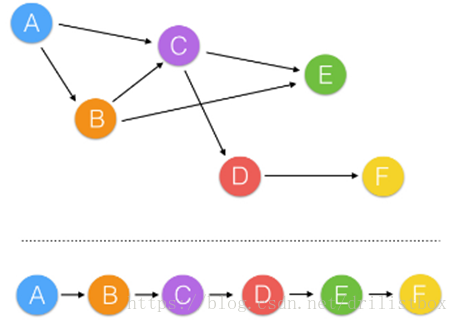
程序中topological_sort()函数用Kahn算法实现拓扑排序。该方法返回一个排好序的节点列表,所有计算都可排列列表进行。
def topological_sort(feed_dict):
"""
用Kahn算法进行拓扑排序
(1)从有向图中选择一个没有前驱(即入度为0)的顶点并且输出它;
(2)从网中删去该顶点,并且删去从该顶点发出的全部有向边;
(3)重复上述两步,直到剩余的网中不再存在没有前趋的顶点为止。
"""
input_nodes = [n for n in feed_dict.keys()]
G = {}
nodes = [n for n in input_nodes]
while len(nodes) > 0:
n = nodes.pop(0)
if n not in G:
G[n] = {'in': set(), 'out': set()}
for m in n.outbound_nodes:
if m not in G:
G[m] = {'in': set(), 'out': set()}
G[n]['out'].add(m)
G[m]['in'].add(n)
nodes.append(m)
L = []
S = set(input_nodes)
while len(S) > 0:
n = S.pop()
if isinstance(n, Input):
n.value = feed_dict[n]
L.append(n)
for m in n.outbound_nodes:
G[n]['out'].remove(m)
G[m]['in'].remove(n)
# if no other incoming edges add to S
if len(G[m]['in']) == 0:
S.add(m)
return Lopological_sort() 传入 feed_dict,我们按此方法为 Input 节点设置初始值。feed_dict 由 Python 字典数据结构表示。
1.3.2 forward_pass:按拓扑排序前向计算节点value
该方法按拓扑排序计算网络中每个节点的值,并返回输出节点的value值
def forward_pass(output_node, sorted_nodes):
for n in sorted_nodes:
n.forward()
output_node.forward()
return output_node.value1.3.3 简单前向计算实现算例
# -*- coding: utf-8 -*-
from miniFlow import *
x, y = placeholder(), placeholder()
f = Add(x, y)
feed_dict = {x: 10, y: 20}
global_variables_initializer()
sorted_nodes = topological_sort (feed_dict=feed_dict)
output = forward_pass(f,sorted_nodes)
print("{}+{}={}(according to miniflow)".format(feed_dict[x], feed_dict[y], output))先用x, y = Input(), Input()构建图表中的输入节点,用f = Add(x,y)构建了对输入节点相加的节点,但此时的输入节点x和y的值value还没有被初始化。然后用topological_sort对所有节点进行拓扑排序,并用形参feed_dict向图表中灌入数据(各个节点中的value值是在这个函数里依据feed_dict进行赋值的),最后再用forward_pass按节点排序顺序依次计算各个节点中的forward函数,并返回输出节点的value。
1.4 线性加权类 Linear
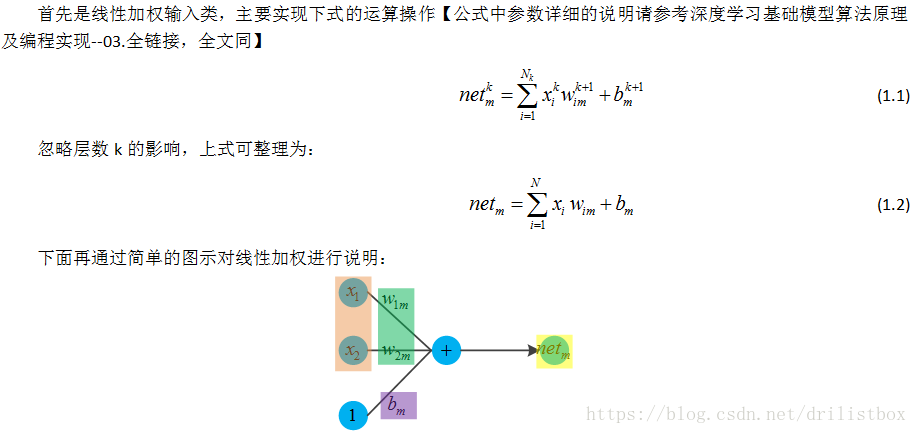
相应的代码实现如下:
class Linear(Node):
'''线性加权神经元类,实现节点加权输入'''
def __init__(self, X, W, b, name=[]):
Node.__init__(self, inbound_nodes=[X,W,b], name=name)
def forward(self):
X = self.inbound_nodes[0].value
W = self.inbound_nodes[1].value
b = self.inbound_nodes[2].value
self.value = np.dot(X, W) + b1.4.1 简单算例
# -*- coding: utf-8 -*-
import numpy as np
from miniFlow import *
inputs = variable(value=np.array([1,2]),name='X')
weight, bias = variable(value=np.array([[1,2,3],[4,5,6]]), name='W1'), variable(value=np.array([1,2,3]), name='b1')
L1 = Linear(inputs, weight, bias, name = 'L1')
L1.forward()
print(L1.value)1.5 sigmoid激活函数类

相应的实现代码如下:
class Sigmoid(Node):
'''sigmoid激活函数节点类型,实现对节点加输入的非线性变换'''
def __init__(self, node, name=[]):
Node.__init__(self, inbound_nodes=[node], name=name)
def _sigmoid(self, x):
return (1./(1+np.exp(-x)))
def forward(self):
self.value=self._sigmoid(self.inbound_nodes[0].value)1.6 损失函数
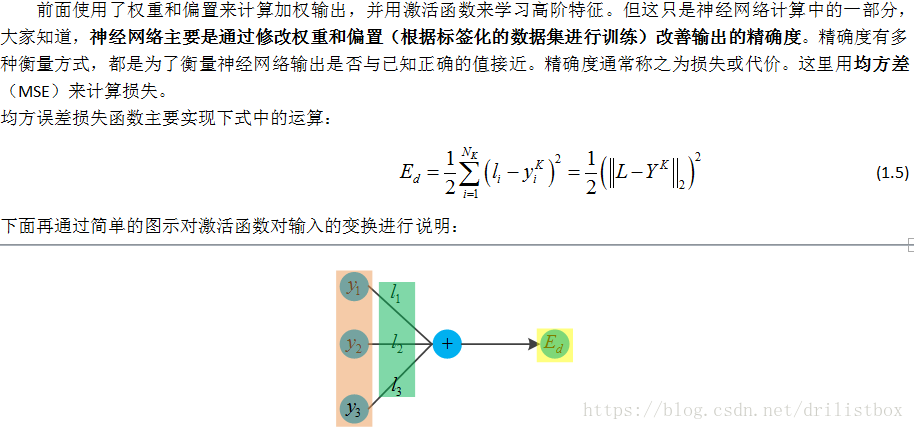
相应的实现代码如下:
class MSE(Node):
def __init__(self, labels, logits, name = []):
"""均方误差损失函数"""
Node.__init__(self, inbound_nodes=[labels, logits], name=name)
def forward(self):
labels = self.inbound_nodes[0].value
logits = self.inbound_nodes[1].value
self.m = self.inbound_nodes[0].value.shape[0]
self.diff = labels - logits
# self.value = np.mean(self.diff**2,1)
self.value = np.sum(self.diff**2,1)1.6.1 简单算例
# -*- coding: utf-8 -*-
from miniFlow import *
y, a = Input(), Input()
cost = MSE(y,a)
y_ = np.array([1,2,3])
a_ = np.array([4.5,5,10])
feed_dict = {y:y_, a:a_}
graph = topological_sort(feed_dict)
output = forward_pass(cost, graph)
print(output)
print(cost.value)结果:
70.25
70.25
1.7 反向传播
神经网络训练的目标就是调整参数使得神经网络的输出逼近标签数据,或者就是说减小损失函数,常用的方法就是梯度下降,梯度实际上是指上坡的方向,梯度下降就是指最陡的下降的方向。学习率就是控制梯度下降步伐的。为了实现方向传播,原来程序也需要做相应的修改。需要为相关类添加backward 方法,并且添加了新的属性 self.gradients,用于在反向传递过程中存储和缓存梯度。
1.7.1 为抽象节点类Node添加backward方法
Node类中将backward方法定义为占位符方法
class Node(object):
……
def backward(self):
"""
反向传播函数【如果没有实现,称为占位符方法,子类如果调用该函数的前提是必须实现它】
"""
raise NotImplementedError1.7.2 为placeholder添加backward方法
由于placeholder存放的是输入数据和标签数据,因此无需对其进行更新。所以其backward方法的函数体为pass
class placeholder(Node):
……
def backward(self):
pass1.7.3 为variable添加backward方法
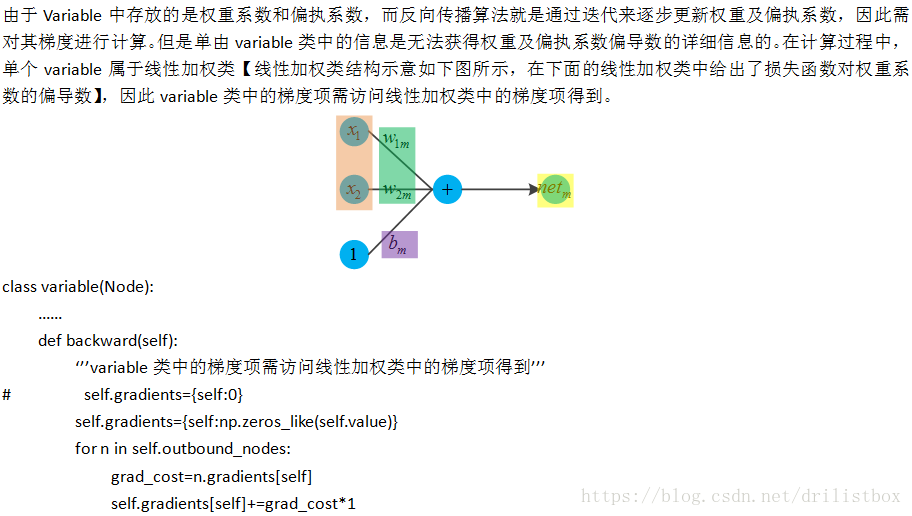
1.7.4 为Linear添加backward方法

上图中详细的符号定义及代码推导请参考【深度学习基础模型算法原理及编程实现–03.全链接】。
class Linear(Node):
……
def backward(self):
self.gradients = {n: np.zeros_like(n.value) for n in self.inbound_nodes}
for n in self.outbound_nodes:
grad_cost = n.gradients[self]
self.gradients[self.inbound_nodes[0]] += np.dot(grad_cost, self.inbound_nodes[1].value.T)
self.gradients[self.inbound_nodes[1]] += np.dot(self.inbound_nodes[0].value.T, grad_cost)
self.gradients[self.inbound_nodes[2]] += np.sum(grad_cost, axis=0, keepdims=False) #axis=0表示对列求和1.7.5 为Sigmoid添加backward方法

相应的实现代码如下:
class Sigmoid(Node): #激活函数节点类型
……
def backward(self):
self.gradients = {n: np.zeros_like(n.value) for n in self.inbound_nodes}
for n in self.outbound_nodes:
grad_cost = n.gradients[self]
sigmoid = self.value
self.gradients[self.inbound_nodes[0]] += sigmoid * (1 - sigmoid) * grad_cost1.7.6 为MSE添加backward方法

上图中详细的符号定义及代码推导请参考【深度学习基础模型算法原理及编程实现–03.全链接】。相应的实现代码如下:
class MSE(Node):
……
def backward(self):
self.gradients = {n:np.zeros_like(n.value) for n in self.inbound_nodes}
self.gradients[self.inbound_nodes[0]]=2./self.m*self.diff
self.gradients[self.inbound_nodes[1]]=-2./self.m*self.diff ###1.7.7 为forward_pass添加backward计算功能
第二项更改是辅助函数 forward_pass()。该函数被替换成了 forward_and_backward()。
def forward_and_backward(graph):
for n in graph:
n.forward()
for n in graph[::-1]:
n.backward()1.8 参数更新
def sgd_update(trainables, learning_rate=1e-2):
for t in trainables:
partial = t.gradients[t]
t.value -= learning_rate * partial1.9 算例实现-MLP实现MNIST数据分类
# -*- coding: utf-8 -*-
import matplotlib.pyplot as plt
import numpy as np
import random
from sklearn.datasets import load_boston
from sklearn.utils import shuffle, resample
import sys
from miniFlow import *
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("./MNISTDat", one_hot=True)
in_units = 784
h1_units = 300
o_units = 10
random.seed (1)
W1_ = 1./np.sqrt(in_units*h1_units)*np.random.randn(in_units, h1_units)
b1_ = np.zeros(h1_units)
W2_ = 0.1*np.random.randn(h1_units, o_units)
b2_ = np.zeros(o_units)
# Neural network
X, y = placeholder(name='X'), placeholder(name='y')
W1, b1 = variable(value=W1_, name='W1'), variable(value=b1_, name='b1')
W2, b2 = variable(value=W2_, name='W2'), variable(value=b2_, name='b2')
#hidden1 = Sigmoid(Linear(X, W1, b1))
#out = Sigmoid(Linear(hidden1, W2, b2))
hidden1 = ReLU(Linear(X, W1, b1))
out = ReLU(Linear(hidden1, W2, b2),name='out')
cost = MSE(y, out)
epochs = 2
m = 50000
batch_size = 64
learning_rate=2e-2
steps_per_epoch = m // batch_size
print("Total number of examples = {}".format(m))
global_variables_initializer()
loss_list = []
acc_list = []
for i in range(epochs):
loss = 0
for j in range(steps_per_epoch):
X_batch, y_batch = mnist.train.next_batch(batch_size)
feed_dict = {X: X_batch,y: y_batch.reshape(batch_size,-1)}
graph = forward_and_backward(feed_dict)
sgd_update(learning_rate)
loss = np.mean(graph[-1].value)
acc = np.mean((np.argmax(out.value,1) == np.argmax(y_batch,1)).astype(int))
loss_list.append(loss)
acc_list.append(acc)
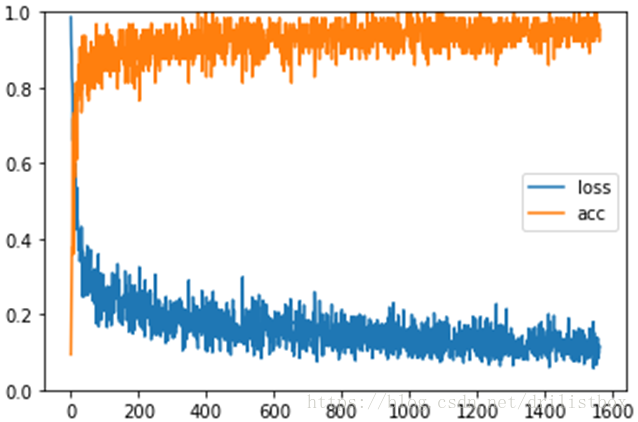
sys.stdout.write("\rprocess: {}/{}, loss:{}, acc:{}".format(j, steps_per_epoch, loss, acc))
plt.figure()
plt.plot(range(len(loss_list)),loss_list,label=u'loss')
plt.plot(range(len(loss_list)),acc_list,label=u'acc')
plt.ylim([0,1])
plt.legend()
plt.show()