1 Azkaban任务调度管理
1.1 执行任务的脚本编写和说明
在做任务调度的过程中,要编写相应的脚本。
-rwxrwxrwx 1 root root 809 6月 12 19:52 auto-exec-1-mr.sh
-rwxrwxrwx 1 root root 975 6月 12 19:53 auto-exec-2-load-logger-data.sh
-rwxrwxrwx 1 root root 1459 6月 12 19:53 auto-exec-3-kylin-build.sh
-rwxrwxrwx 1 root root 446 6月 16 14:34 auto-exec-4-analyze.sh
-rwxrwxrwx 1 root root 110 6月 12 19:54 auto-exec-5-sqoop-mysql.sh
-rwxrwxrwx 1 root root 313 6月 16 14:55 auto-exec-6-pv-uv.sh然后让这些脚本具有可执行权限:
[root@bigdata1 logger-handler]# pwd
/home/bigdata/workspace/logger-handler
[root@bigdata1 logger-handler]# chmod +x *.sh1.1.1 auto-exec-1-mr.sh
该脚本主要用于执行数据清洗应用
#!/bin/bash
sync
echo 3 > /proc/sys/vm/drop_caches
echo "步骤1:执行logger的mr数据清洗程序"
yesterday=`date --date='1 days ago' +%y-%m-%d`
#删除mapreduce清洗文件夹(存储上一天的那个文件夹)
#yesterdayFolder=/output/nginx/$yesterday
#判断上一天的这个文件夹是否存在
hdfs dfs -test -e /output/nginx/$yesterday
if [ $? -eq 0 ]
then
echo "存在上一天这个文件夹"
hdfs dfs -rm -r /output/nginx/$yesterday
else
#字符串中带有变量时,这里的引号必须是双引号
echo "不存在$yesterday这个文件夹"
fi
echo "开始进行日志文件的mapreduce的清洗程序"
cd /home/bigdata/workspace/logger-handler
hadoop jar bigdata-logger-mr-1.0.0-SNAPSHOT-jar-with-dependencies.jar com.youx.bigdata.logger.driver.loggerRunner1.1.2 auto-exec-2-load-logger-data.sh
该脚本主要用于执行将清洗的数据load到hive库中的操作。
#!/bin/bash
sync
echo 3 > /proc/sys/vm/drop_caches
echo "步骤2:执行hive命令load数据到hive中"
#如果时间定义成+%Y-%m-%d 则时间变成了2018-05-24了
yesterday=`date --date='1 days ago' +%y-%m-%d`
echo $yesterday
#定义变量
str1="part-r-"
#获取到hdfs中中文件列表,awk '{print $8}'获取到第八列
for hdfsFile in `hdfs dfs -ls /output/nginx/$yesterday | awk '{print $8}'`
do
echo $hdfsFile
result=$(echo $hdfsFile | grep "${str1}")
if [[ "$result" != "" ]]
then
#表示包含这个part-r-这类前缀的文件的,然后开始做数据导入操作。
#使用hive -e的方式执行hive命令
#要注意的是,当执行过一遍之loaddata后,原来放置mapreduce处理结果位置的这个数据就没了。
hive -e "
use nginx_log;
load data inpath 'hdfs://bigdata1:9000$hdfsFile' into table nginx_log_info;
"
else
#表示不包含这个文件的
continue
fi
done
#hive -e "
#use nginx_log;"1.1.3 auto-exec-3-kylin-build.sh
该脚本主要用于让kylin自动预编译。
#!/bin/bash
sync
echo 3 > /proc/sys/vm/drop_caches
echo "步骤3:kylin-build"
#################################################################################
#脚本功能:在数据被load到hive之后,使用kylin进行Build,增量更新kylin cube
#################################################################################
#cubeName cube名称
#endTime 执行build cube的结束时间(命令传给Kylin的kylinEndTime = readEndTime + (8小时,转化为毫秒))。
# 只需要给kylin传入build cube的结束时间即可。
#buildType BUILD构建cube操作(还有Refresh、Merge等操作,增量构建为BUILD)
#endTime=`date "+%Y-%m-%d 00:00:00"`
endTime=`date +%Y-%m-%d -d "+1days"`
echo "$endTime"
endTimeTimeStamp=`date -d "$endTime" +%s`
echo $endTimeTimeStamp
#将时间戳编程毫秒值
endTimeTimeStampMs=$(($endTimeTimeStamp * 1000))
echo $endTimeTimeStampMs
cubeName=logger_cube
#curl -X PUT --user ADMIN:KYLIN -H "Content-Type: application/json;charset=utf-8" -d '{ "startTime"}'
curl -X PUT --user ADMIN:KYLIN -H "Content-Type: application/json;charset=utf-8" -d '{ "endTime":'$endTimeTimeStampMs', "buildType": "BUILD"}' http://bigdata1:7070/kylin/api/cubes/logger_cat/rebuild
#curl -X PUT --user ADMIN:KYLIN -H "Content-Type: application/json;charset=utf-8" -d '{ "startTime": 820454400000, "endTime": 821318400000, "buildType": "BUILD"}' http://localhost:7070/kylin/api/cubes/kylin_sales/build1.1.4 auto-exec-4-analyze.sh
该脚本主要用于执行分析url访问次数,url平均访问时间
#!/bin/bash
sync
echo 3 > /proc/sys/vm/drop_caches
#echo "步骤4:执行分析程序"
#echo "休眠10秒"
#sleep 10s
#echo "休眠1分钟"
#sleep 1m
#echo "休眠1小时"
#sleep 1h
echo "休眠2个小时,开始"
sleep 120m
echo "休眠2个小时,结束"
cd /home/bigdata/workspace/logger-handler
#执行分析程序
hadoop jar bigdata-logger-kylin-1.0.0-SNAPSHOT-jar-with-dependencies.jar com.youx.bigdata.logger.kylin.LoggerKylinAnalyze1.1.5 auto-exec-5-sqoop-mysql.sh
该脚本暂时未做功能
1.1.6 auto-exec-6-pv-uv.sh
该脚本主要用于调用执行分析程序pv,uv的程序。
#!bin/bash
sync
echo 3 > /proc/sys/vm/drop_caches
echo "休眠140分钟,开始"
sleep 140m
echo "休眠140分钟,结束"
#执行分析程序
cd /home/bigdata/workspace/logger-handler
hadoop jar bigdata-operation-info-1.0.0-SNAPSHOT-jar-with-dependencies.jar com.youx.bigdata.logger.analyze.OperationInfoAnalyze1.2 Job任务编写
Azkaban的任务脚本是以.job结尾的文件。
1.2.1 auto-exec-1-mr.job
具体内容是:
#auto-exec-1-mr.job
type=command
command=sh /home/bigdata/workspace/logger-handler/auto-exec-1-mr.sh说明:
通过上面的写法,通过命令的方式执行job,其中命令是:
command=sh /home/bigdata/workspace/logger-handler/auto-exec-1-mr.sh1.2.2 auto-exec-2-load-logger-data.job
下面的job主要的作用是将数据清洗的结果load到hive仓库中。
#auto-exec-2-load-logger-data.job
type=command
dependencies=auto-exec-1-mr
command=sh /home/bigdata/workspace/logger-handler/auto-exec-2-load-logger-data.sh上面增加了一个关键字:dependencies,表示这个任务依赖任务auto-exec-1-mr,只有当auto-exec-1-mr任务执行完毕之后才会进行后续操作。
1.2.3 auto-exec-3-kylin-build.job
执行kylin的build任务。
#auto-exec-3-kylin-build.job
type=command
dependencies=auto-exec-2-load-logger-data
command=sh /home/bigdata/workspace/logger-handler/auto-exec-3-kylin-build.sh1.2.4 auto-exec-4-analyze.job
执行url访问统计和访问量统计的任务
#auto-exec-4-analyze.job
type=command
dependencies=auto-exec-3-kylin-build
command=sh /home/bigdata/workspace/logger-handler/auto-exec-4-analyze.sh1.2.5 auto-exec-5-sqoop-mysql.job
执行将hive中数据导入到mysql中的操作。
1.2.6 auto-exec-6-pv-uv.job
执行pv,uv分析任务
#auto-exec-6-pv-uv.job
type=command
dependencies=auto-exec-5-sqoop-mysql
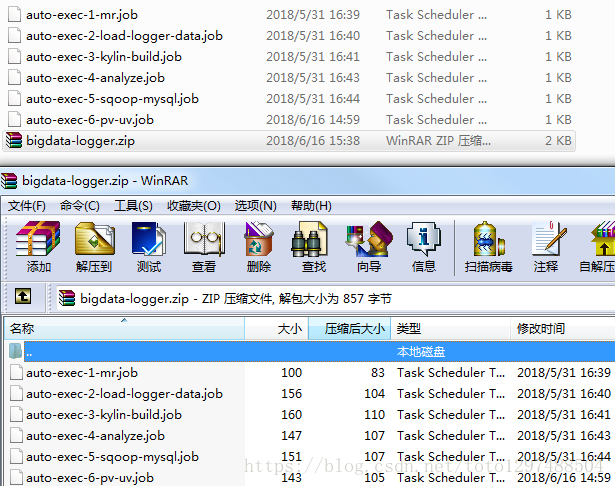
command=sh /home/bigdata/workspace/logger-handler/auto-exec-6-pv-uv.sh1.2.7 统一压缩job到zip包
Azkaban的执行需要一个压缩包,所以需要将上面编写的job统一压缩到一个zip中。效果图下:
1.3 项目创建/上传任务包/配置任务调度
当job都编写完成之后,开始创建azkaban的任务调度的项目,并上传任务执行包。
创建项目。
访问:https://bigdata1:8443/index,输入用户名/密码: admin / admin之后进入azkaban界面。

创建项目:
点击上面的”Create Project”
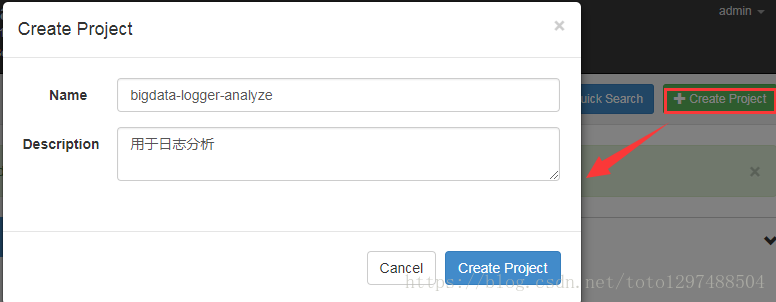
点击”Create Project”,进入一下界面:
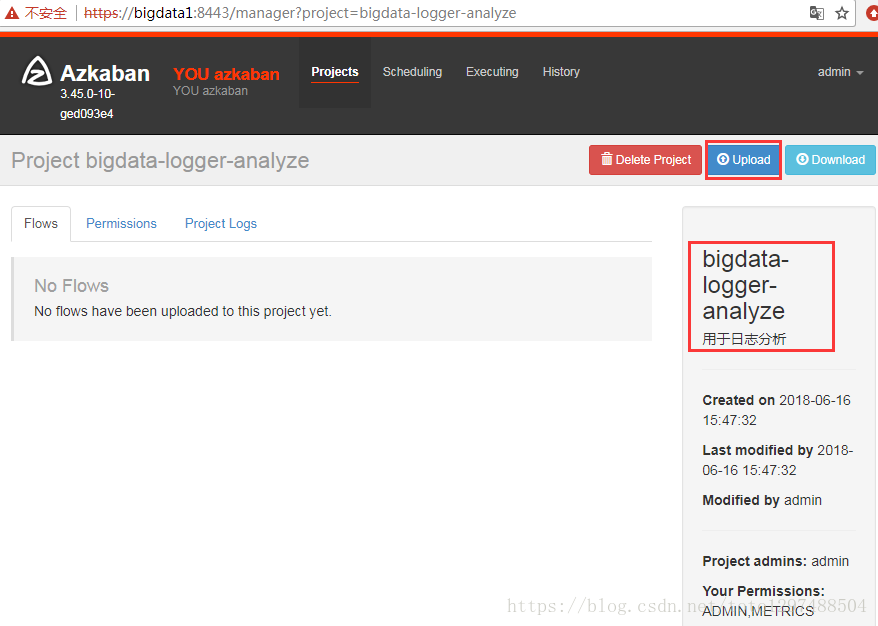
点击“upload”

点击”选择文件”
点击Upload按钮,进入以下界面:
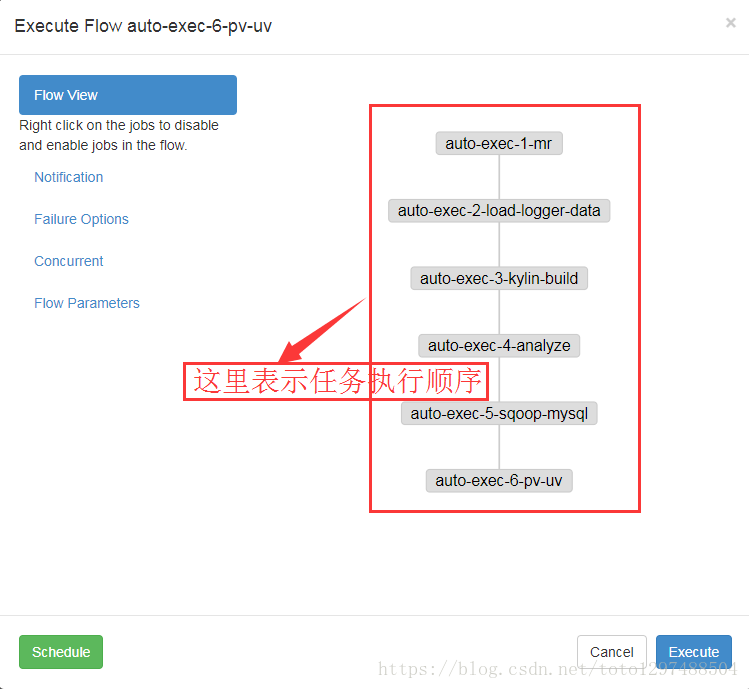
点击”Execute Flow”,进入以下界面:
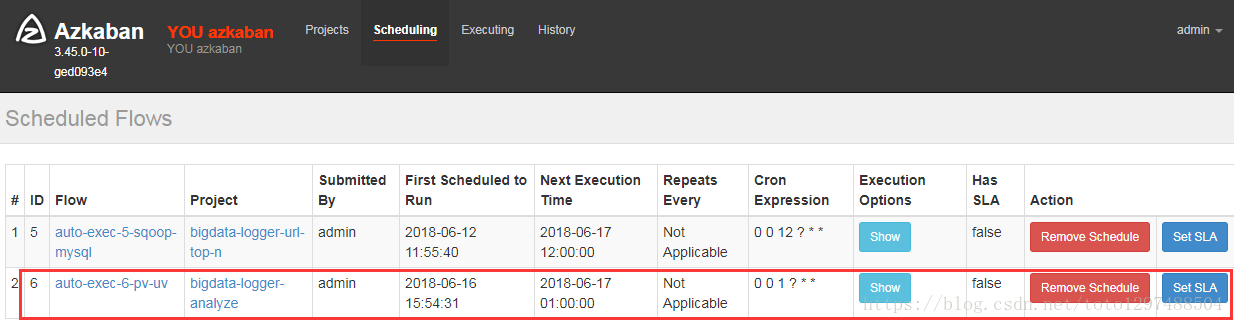
点击Schedule,进入以下界面:
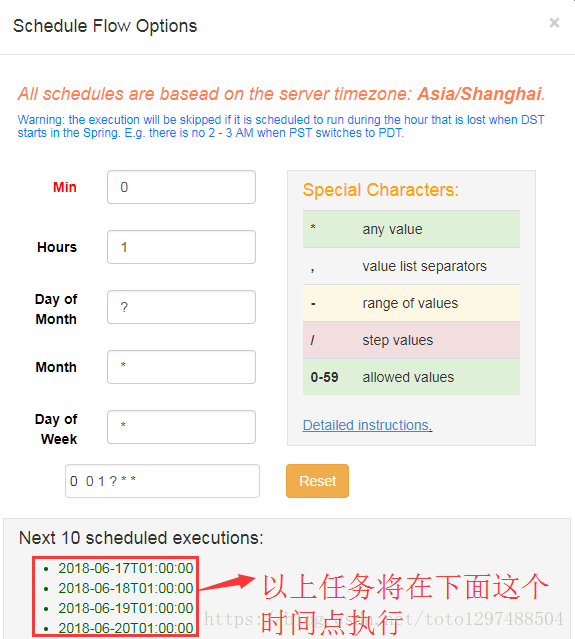
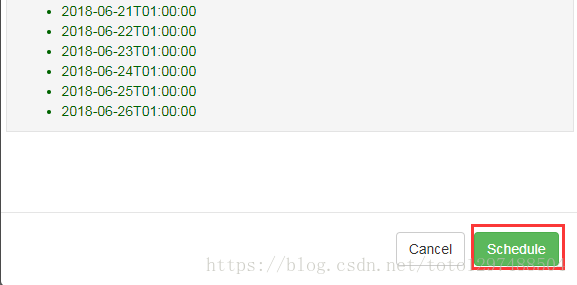
点击schddule,任务配置完成
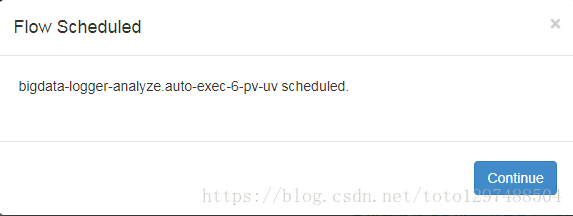
最终进入以下界面: