本篇文章继续给大家介绍ELFK日志分析的有关内容,我们的ES和Kibana都介绍的差不多了,所以本篇文章重点介绍Logstash的有关内容,介绍完毕后,我们的ELFK架构将初步形成,此外还有ES读写文档的原理,了解原理,更深层次的理解,使用ES,集群角色和master节点与数据节点分离,当我们的数据量较大的时候会用到此操作,Logstash的部署与操作,实现数据的采集与输出。
ES读写文档原理
在创建分片底层对应的是一个Lucene库,而Lucene底层使用倒排索引技术实现,那么什么是倒排索引。
我们先说下什么是正排索引(正向索引),我们以MySQL为例,用id字段储存博客文章的编号,用context储存文件的内容。
CREATE TABLE blog (id INT PRIMARY KEY AUTO_INCREMENT, context TEXT);
INSERT INTO blog VALUES (1,'I am koten, I love Linux ...')此时,如果我们想要查询内容包含koten的词汇时,只能进行全表扫描
SELECT * FROM blog WHERE context LIKE 'koten';一、倒排索引(反向索引)
ES使用一种称为倒排索引的结构,它适用于快速的全文检索,倒排索引中有以下三个专业术语。
词条:指最小的存储和查询单元,换句话说,指的是您想要查询的关键词,对于英文而言通常指的是一个单词,而对于中文而言,对应的是一个词组;
词典:是词条的集合,底层通常基于Btree+和HASHMap实现;
倒排表:记录了词条出现在什么位置,出现的频率是多少,倒排表中的每一条记录我们称为倒排项。
二、倒排索引的搜索过程
1、首先根据用户需要查询的词条进行分词,将分词后的各个词条字典进行匹配,验证词条在词典中是否存在;
2、如果上一步搜索结果发现词条不在字典中,则结束本次搜索,如果在词典中,就需要去查看倒排表中的记录(倒排项);
3、根据倒排表中记录的倒排项来定位数据在哪个文档中存在,而后根据这些文档的id来获取指定的数据。
综上,假设有10亿篇文章,在mysql不创建索引的情况下会进行全表扫描搜索koten,而对于ES而言,其只需要将倒排表中返回的id进行扫描即可,而无须进行全量查询。
三、ES写文档原理
用户在客户端发起请求,通过HTTP请求到任意一个节点,我们暂且叫他为请求接收节点,接收到请求后会将信息发送给主节点,主节点负责集群状态,如果是带路由请求,就文档id生成哈希值除以分片数量取余决定将文档放入哪个分片,如果是不带路由请求,就随机生成文档id,再由id生成哈希值除以分片数量取余决定将文档放入哪个分片,决定好后,主分片会写入数据,同时副本分片会同步数据,数据同步好后会告知主节点,数据写入完毕(主分片+副本分片的总数除以2加1写入成功,视为数据写入成功),再由主节点去通知请求接收的节点,将信息再返回到用户的客户端。
四、ES读文档原理
用户在客户端发起请求,通过HTTP请求到任意一个节点,由该节点进行路由分片计算,计算出来存储在哪个分片当中,再计算副本分片和主分片哪个繁忙,会在相对不繁忙的分片中取出数据,再返回给客户端。
五、ES修改文档原理
用户在客户端发起请求,通过HTTP请求到任意一个节点,节点首先获取原文档的版本号,如果采用文档id的更新方式,会将修改后的文档和版本号一起写进原文档的分片中,这过程和新增相同,同时旧文档也被标志成删除文档,同样能被检索到,只不过最终被过滤掉而已,如果原文档分片不可用会写入新分片中。如果采用的是基于路由键(routing key)的更新方式,那么更新的文档可能会被路由到和原始文档所在不同的分片上。路由键通常与文档中的一个字段有关联,可以通过该字段将文档路由到相同的分片上,从而实现更好的查询性能和负载均衡。
六、ES删除文档原理
用户在客户端发起请求,通过HTTP请求到任意一个节点,文档并不会真正被删除,而是del文件中记录被删除的文档,但该文档依然能被检索到,只是在最后过滤掉,当segment合并时,才会真正地删除del标志的文档。
七、ES底层存储文档原理
用户在客户端发起请求,通过HTTP请求到任意一个节点,数据会先到内存,通过WAN机制,预写日志,记录本次的事件,然后在flush阶段,会将ES的段文件数据提交OS cache,未提交的数据不能被外界搜索,进入OS cache后会进入reflush阶段,经过一定的时间或到达一定的大小,将内存的数据同步给磁盘,如果此时突然断电,我们更新的数据将无法写入磁盘,但是因为我们预写了日志,在取数据的时候会同时取到磁盘中旧数据与新数据,经过版本对比,会保留新数,再对外提供服务,最后在磁盘区域中,会将多个段文件合并,减少磁盘IO占用,读取.del文件,将标记删除的数据进行物理删除。
集群角色
查看集群节点,可以看到node.role集群角色,可以在配置文件里去修改,实现主节点与数据节点的分离
[root@ELK101 ~]# curl 10.0.0.101:19200/_cat/nodes?v
ip heap.percent ram.percent cpu load_1m load_5m load_15m node.role master name
10.0.0.103 54 88 0 0.00 0.01 0.05 cdfhilmrstw - ELK103
10.0.0.102 75 96 2 0.01 0.05 0.10 cdfhilmrstw * ELK102
10.0.0.101 74 95 2 0.03 0.10 0.12 cdfhilmrstw - ELK101
角色声明
c :
Cold data
d :
data node 指的是存储数据的节点,可以使用node.data:true写入配置文件
f :
frozen node
h :
hot node
i :
ingest node
l :
machine learning node
m :
master eligible node 控制ES集群,并维护集群的状态(cluster state,包括节点信息,索引信息,ES集群每个节点都有一份)
r :
remote cluster client node
s :
content node
t :
transform node
v :
voting-only node
w :
warm node
- :
coordinating node only 协调节点可以处理请求的节点,ES集群所有的节点均为协调节点,该角色无法取消master节点与数据节点分离
1、所有节点停止ES服务
[root@ELK101 ~]#systemctl stop es7
[root@ELK102 ~]#systemctl stop es7
[root@ELK103 ~]#systemctl stop es72、所有节点清空数据
[root@ELK101 ~]# rm -rf /koten/{data,logs}/es7/* /tmp/*
[root@ELK102 ~]# rm -rf /koten/{data,logs}/es7/* /tmp/*
[root@ELK103 ~]# rm -rf /koten/{data,logs}/es7/* /tmp/*3、修改配置文件
[root@ELK101 ~]# egrep -v "^#|^$" /koten/softwares/elasticsearch-7.17.5/config/elasticsearch.yml
cluster.name: koten-es7
path.data: /koten/data/es7
path.logs: /koten/logs/es7
network.host: 0.0.0.0
http.port: 19200
transport.tcp.port: 19300
discovery.seed_hosts: ["10.0.0.101","10.0.0.102","10.0.0.103"]
cluster.initial_master_nodes: ["10.0.0.101"] #修改选举主节点为101
node.data: false #修改数据节点为false
node.master: true #修改主节点为true
[root@ELK102 ~]# egrep -v "^#|^$" /koten/softwares/elasticsearch-7.17.5/config/elasticsearch.yml
cluster.name: koten-es7
path.data: /koten/data/es7
path.logs: /koten/logs/es7
network.host: 0.0.0.0
http.port: 19200
transport.tcp.port: 19300
discovery.seed_hosts: ["10.0.0.101","10.0.0.102","10.0.0.103"]
cluster.initial_master_nodes: ["10.0.0.101"]
node.data: true
node.master: false
[root@ELK103 ~]# egrep -v "^#|^$" /koten/softwares/elasticsearch-7.17.5/config/elasticsearch.yml
cluster.name: koten-es7
path.data: /koten/data/es7
path.logs: /koten/logs/es7
network.host: 0.0.0.0
http.port: 19200
transport.tcp.port: 19300
discovery.seed_hosts: ["10.0.0.101","10.0.0.102","10.0.0.103"]
cluster.initial_master_nodes: ["10.0.0.101"]
node.data: true
node.master: false
4、所有节点启动ES服务
[root@ELK101 ~]# systemctl start es7
[root@ELK102 ~]# systemctl start es7
[root@ELK103 ~]# systemctl start es75、访问ES服务
[root@ELK101 ~]# curl 10.0.0.101:19200/_cat/nodes
10.0.0.103 60 62 56 1.25 0.44 0.20 cdfhilrstw - ELK103
10.0.0.101 65 73 57 1.31 0.48 0.24 ilmr * ELK101
10.0.0.102 58 57 48 0.93 0.35 0.16 cdfhilrstw - ELK1026、验证ES的数据节点分离,观察ES-HEAD的分片情况
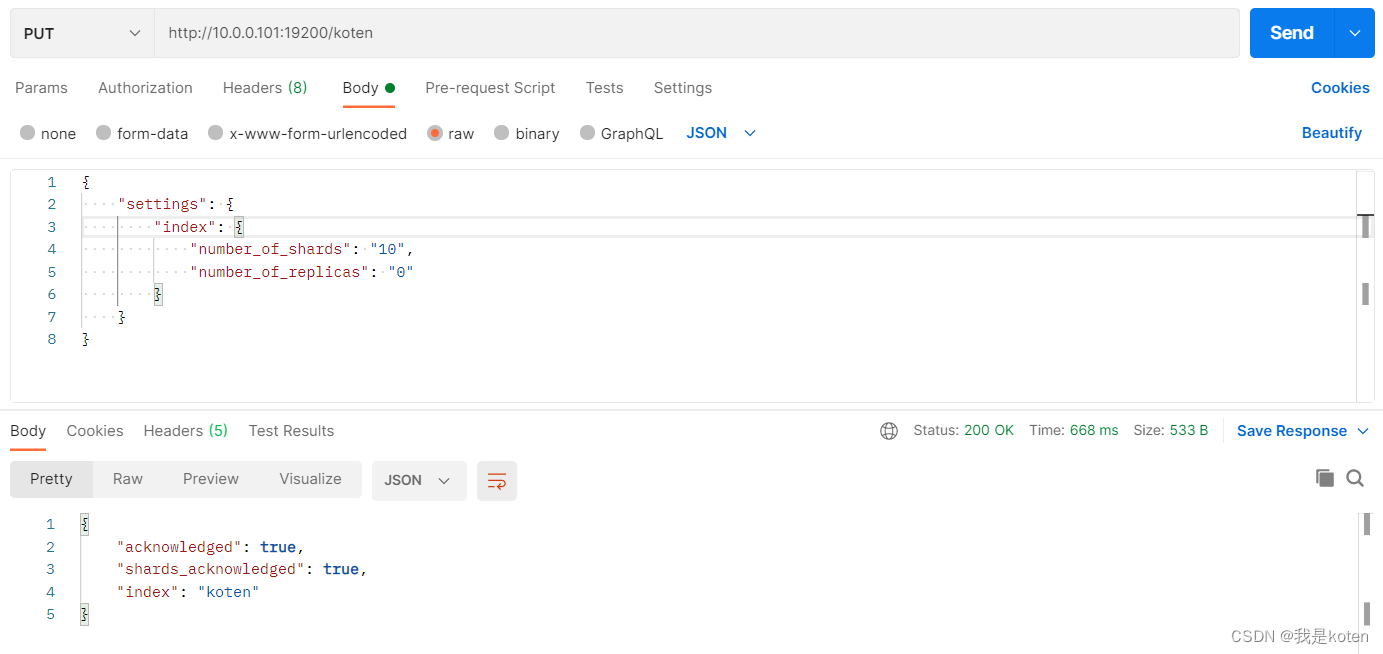
PUT http://10.0.0.101:19200/koten
{
"settings": {
"index": {
"number_of_shards": "10",
"number_of_replicas": "0"
}
}
}

7、停止master节点,观察集群是否正常工作
[root@ELK101 ~]# systemctl stop es7
发现集群直接瘫痪,数据节点也无法链接,无法curl节点信息
[root@ELK101 ~]# curl 10.0.0.102:19200/_cat/nodes
^C

Logstash安装部署
1、下载软件
注意选择与ES一致的版本,我这边选择7.17.5
[root@ELK102 ~]# wget https://artifacts.elastic.co/downloads/logstash/logstash-7.17.5-x86_64.rpm
2、安装软件并创建符号连接,实现可以直接调用命令
[root@ELK102 ~]# rpm -ivh logstash-7.17.5-x86_64.rpm
[root@ELK102 ~]# ln -sv /usr/share/logstash/bin/logstash /usr/local/sbin/
‘/usr/local/sbin/logstash’ -> ‘/usr/share/logstash/bin/logstash’3、基于命令行运行logstash的配置参数,并指定日志级别
[root@ELK102 ~]# logstash -e "input { stdin { type => stdin } } output { stdout { codec => rubydebug } }" --log.level warn
......
The stdin plugin is now waiting for input:
111
{
"message" => "111",
"@version" => "1",
"host" => "ELK102",
"type" => "stdin",
"@timestamp" => 2023-05-28T07:16:46.351Z
}
4、编写配置文件并检查语法
[root@ELK102 ~]# cat /etc/logstash/conf.d/01-stdin-to-stdout.conf
input {
stdin {
type => stdin
}
}
output {
stdout {
codec => rubydebug
}
}
[root@ELK102 ~]# logstash -tf /etc/logstash/conf.d/01-stdin-to-stdout.conf --log.level fatal #语法检查
......
Configuration OK
5、基于配置文件启动logstash
[root@ELK102 ~]# logstash -f /etc/logstash/conf.d/01-stdin-to-stdout.conf --log.level fatalLogstash采集本地日志文件
一、采集本地日志文件到标准输出
1、添加logstash配置文件
[root@ELK102 ~]# cat /etc/logstash/conf.d/02-file-to-stdout.conf
input {
file {
# 指定读取新文件的起始位置,有效值为"beginning","end",默认值为"end"
start_position => "beginning"
# 指定要采集文件路径
path => ["/tmp/*.info","/tmp/*/*.txt"]
}
}
output {
stdout {
# 指定输出的编码格式,默认是rubydebug
codec => rubydebug
# codec => json
}
}
2、测试标准输出
[root@ELK102 ~]# logstash -rf /etc/logstash/conf.d/02-file-to-stdout.conf
[root@ELK102 ~]# echo 111 > /tmp/1.info
[root@ELK102 ~]# logstash -rf /etc/logstash/conf.d/02-file-to-stdout.conf
...
{
"@version" => "1",
"@timestamp" => 2023-05-28T08:54:00.415Z,
"host" => "ELK102",
"path" => "/tmp/1.info",
"message" => "111"
}
[root@ELK102 ~]# echo 222 > /tmp/test/2.txt
{
"@version" => "1",
"@timestamp" => 2023-05-28T08:55:30.868Z,
"host" => "ELK102",
"path" => "/tmp/test/2.txt",
"message" => "222"
}
二、采集Nginx日志文件到标准输出
1、安装启动nginx
[root@ELK102 ~]# cat > /etc/yum.repos.d/nginx.repo <<'EOF'
[nginx-stable]
name=nginx stable repo
baseurl=http://nginx.org/packages/centos/$releasever/$basearch/
gpgcheck=1
enabled=1
gpgkey=https://nginx.org/keys/nginx_signing.key
module_hotfixes=true
[nginx-mainline]
name=nginx mainline repo
baseurl=http://nginx.org/packages/mainline/centos/$releasever/$basearch/
gpgcheck=1
enabled=0
gpgkey=https://nginx.org/keys/nginx_signing.key
module_hotfixes=true
EOF
[root@ELK102 ~]# yum -y install nginx
[root@ELK102 ~]# systemctl enable --now nginx
2、使用logstash采集Nginx日志并到标准输出
[root@ELK102 ~]# cat /etc/logstash/conf.d/03-nginx-to-stdout.conf
input {
file {
# 指定读取新文件的起始位置,有效值为"beginning","end",默认值为"end"
start_position => "beginning"
# 指定要采集文件路径
path => ["/var/log/nginx/access.log*"]
}
}
output {
stdout {
# 指定输出的编码格式,默认是rubydebug
codec => rubydebug
# codec => json
}
}浏览器访问10.0.0.102
通过刚刚修改的logstash配置文件,实现标准化输入输出,访问一次就能自动采集进去一次
[root@ELK102 ~]# logstash -rf /etc/logstash/conf.d/03-nginx-to-stdout.conf
......
{
"@timestamp" => 2023-05-28T09:05:31.885Z,
"message" => "10.0.0.1 - - [28/May/2023:17:03:53 +0800] \"GET / HTTP/1.1\" 304 0 \"-\" \"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36 Edg/113.0.1774.50\" \"-\"",
"host" => "ELK102",
"path" => "/var/log/nginx/access.log",
"@version" => "1"
}
三、Nginx日志文件指定索引、主分片数、副本分片数输出
我们在input输入和output输出的时候有很多字段可以定义,实现我们个性化的需求,例如我们使用logstatsh采集Nginx日志到ES集群,要求10分片,0副本。logstash中并没有指定分片和副本的字段,所以我们可以采取索引模板的方式。
[root@elk102 ~]# cat config/04-nginx-to-elasticsearch.conf
input {
file {
# id字段用于唯一标识一个input插件,但是无法实现
id => "nginx-001"
start_position => "beginning"
path => ["/var/log/nginx/access.log*"]
}
}
output {
elasticsearch {
# 指定ES的主机地址
hosts => ["10.0.0.101:19200","10.0.0.102:19200","10.0.0.103:19200"]
# 自定义写入数据的索引,时间变量参考:
# https://www.joda.org/joda-time/apidocs/org/joda/time/format/DateTimeFormat.html
index => "koten-nginx-%{+yyyy.MM.dd}" #我们先创建索引模板再指定索引姓名,就可以实现指定分片数了
}
}创建索引模板

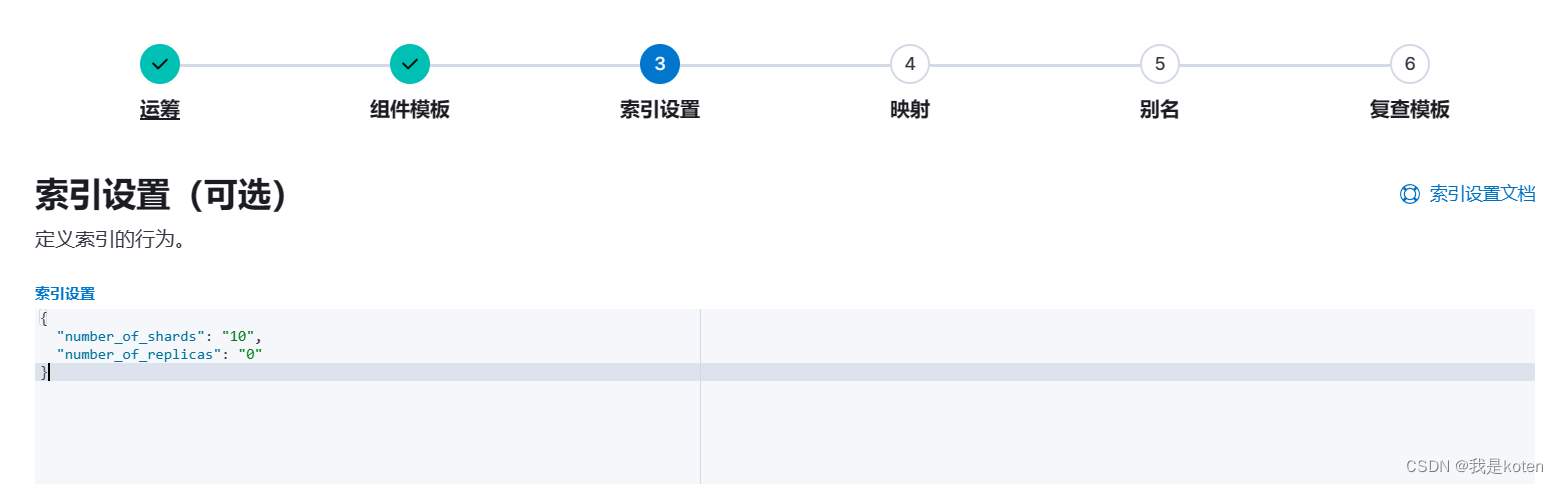
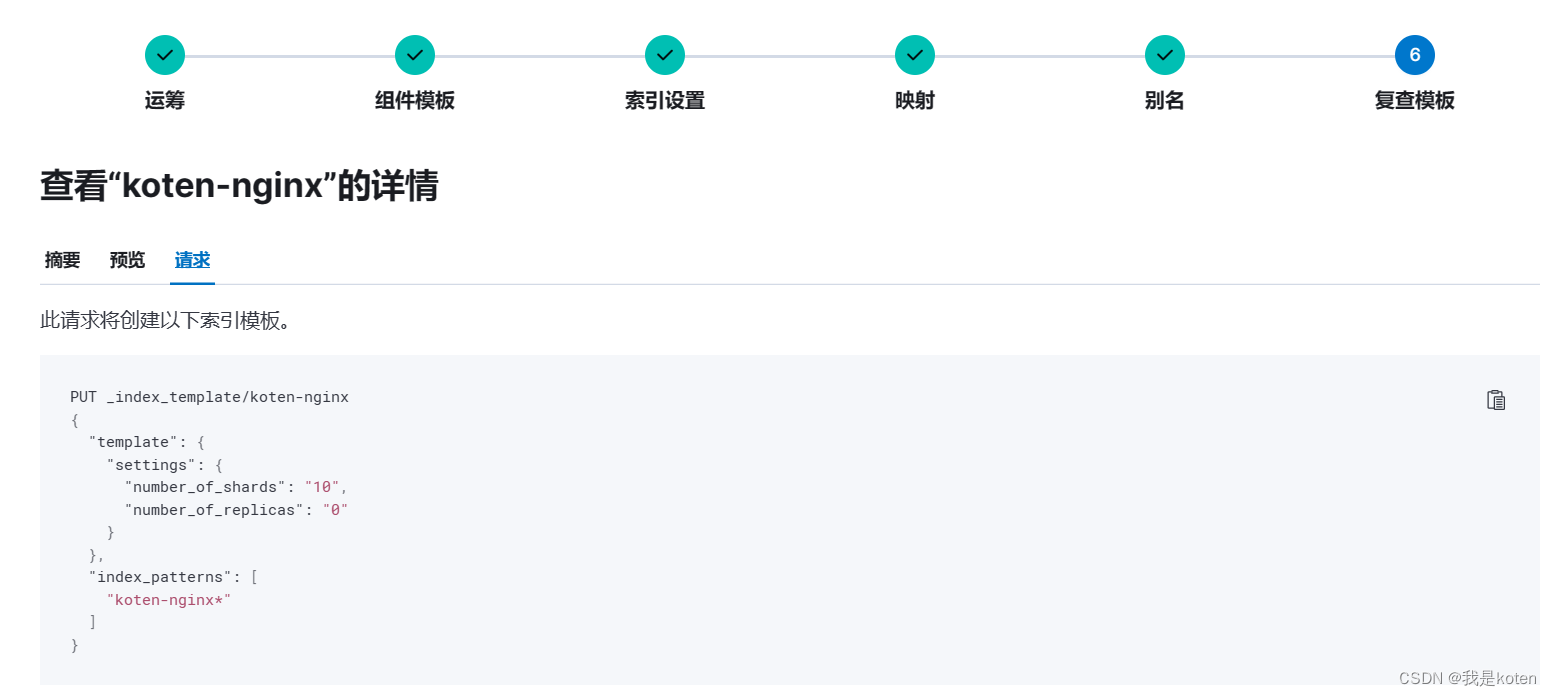
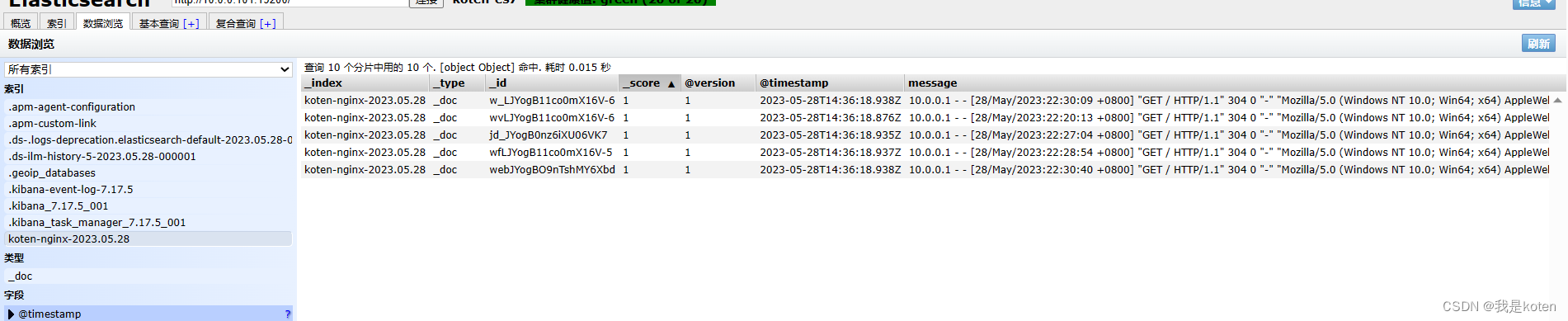
启用logstash,刷新下10.0.0.102网页,在ES-head和kibana中观察索引
[root@ELK102 ~]# logstash -rf /etc/logstash/conf.d/03-nginx-to-stdout.conf --log.level fatal
#-r 修改配置文件后,已经启用的logstash会自动reload读取该配置文件,不用关闭再重启即可生效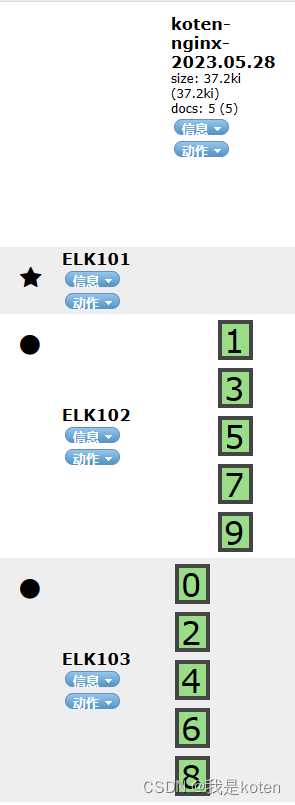

我是koten,10年运维经验,持续分享运维干货,感谢大家的阅读和关注!