本篇文章继续给大家介绍ELFK,介绍logstash的商品分析实战练习,通过logstash写入es数据,通过kibana可视化输出,还介绍pipline实现多实例,详解filebeat部署使用,实现轻量化数据采集。再将ELK架构升级为ELFK架构,实现采集数据,数据转换,存储数据,数据可视化的全部功能。
目录
二、三台主机均安装filebeat,分别编写主机的filebeat的配置文件
三、编写logstash的配置文件和pipeline配置文件
商品分析实战练习
一、固定商品格式
将1组数据通过logstash写入es,通过kibana对所有商品数据进行指标分析,根据IP地理位置画出统计图、地图、组内多少商品,画条形统计图、有多少品牌画条形统计图
1、准备都是json格式的商品信息
[root@ELK102 ~]# cat /tmp/car.txt
{ "ip_addr": "221.194.154.181" ,"title":"BMW1系运动轿车 125i M运动曜夜版","price":249900,"brand":"宝马","item":"https://www.bmw-emall.cn/newcar/design?series=1&rangeCode=F52&packageCode=2W71_0ZMB&sop=1672502400000","group":3,"author":"koten"}
......2、编辑配置文件
[root@ELK102 ~]# cat config/12-file-filter-es.conf
input {
file {
start_position => "beginning"
path => ["/tmp/car.txt"]
}
}
filter {
json {
source => "message"
}
geoip {
source => "ip_addr"
}
}
output {
elasticsearch {
hosts => ["10.0.0.101:19200","10.0.0.102:19200","10.0.0.103:19200"]
index => "koten-car-%{+yyyy.MM.dd}"
}
stdout {
codec => rubydebug
}
}
3、运行logstash
将数据写入ES,之后可以在kibana进行数据可视化
[root@ELK102 ~]# rm -rf /usr/share/logstash/data/plugins/inputs/file/.sincedb_*
[root@ELK102 ~]# logstash -rf config/12-file-filter-es.conf
......
{
"price" => 298900,
"message" => "{ \"ip_addr\": \"221.194.154.181\" ,\"title\":\"BMW2系四门轿跑车 225i M运动曜夜套装\",\"price\":298900,\"brand\":\"宝马\",\"item\":\"https://www.bmw-emall.cn/newcar/design?series=2&rangeCode=F44&packageCode=31AK_0ZSM&sop=1667232000000\",\"group\":3,\"author\":\"koten\"}\r",
"title" => "BMW2系四门轿跑车 225i M运动曜夜套装",
"author" => "koten",
"item" => "https://www.bmw-emall.cn/newcar/design?series=2&rangeCode=F44&packageCode=31AK_0ZSM&sop=1667232000000",
"path" => "/tmp/car.txt",
"@timestamp" => 2023-05-30T00:52:58.511Z,
"brand" => "宝马",
"@version" => "1",
"host" => "ELK102",
"ip_addr" => "221.194.154.181",
"group" => 3
}
......

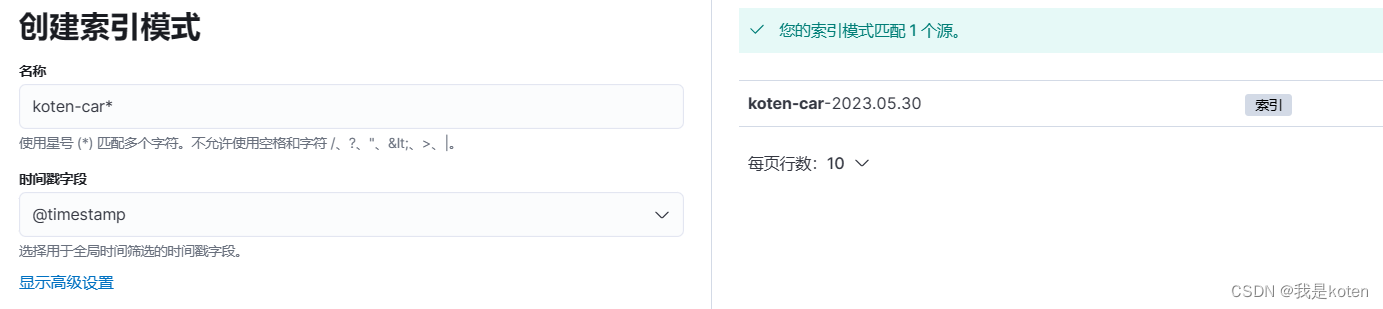
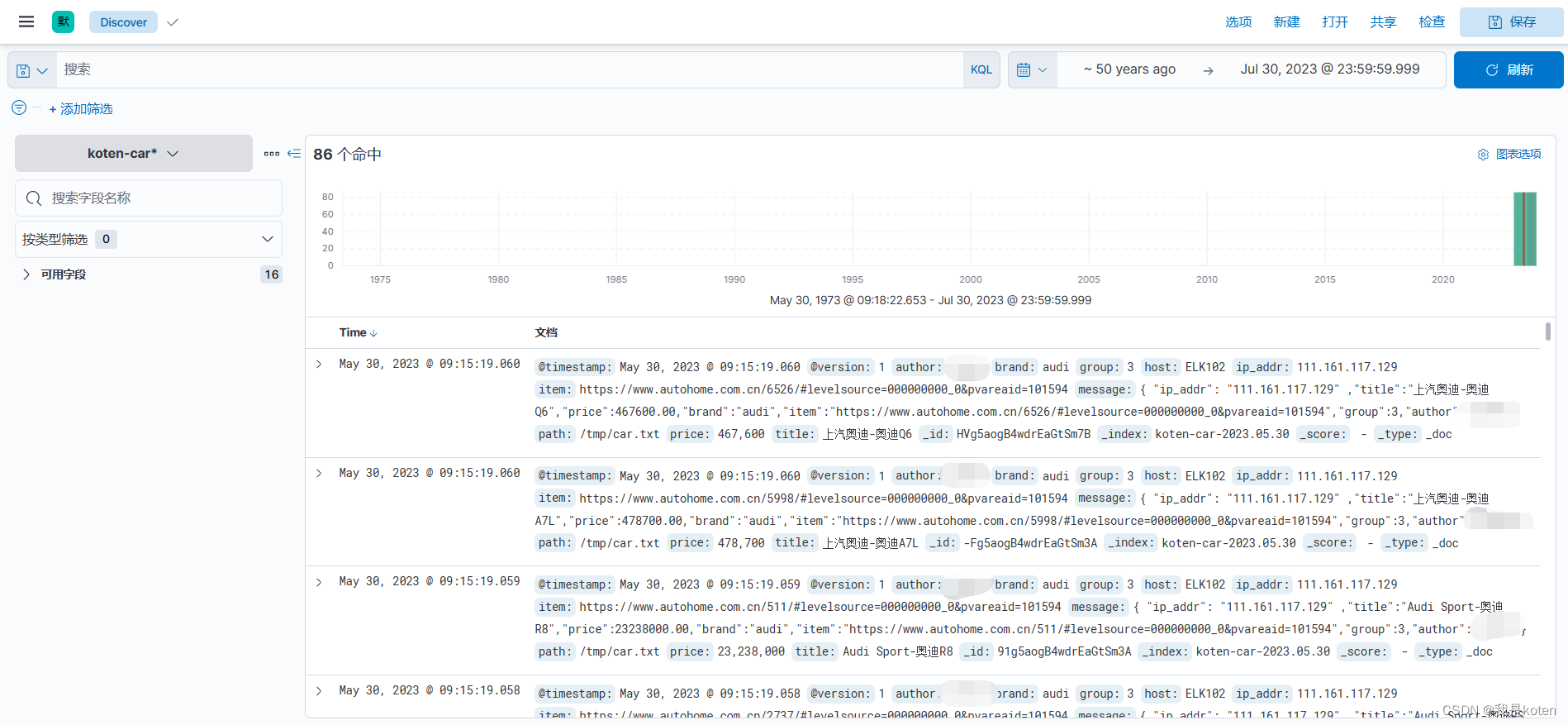
4、创建索引模式
创建好后可以看到数据
5、制作可视化
省略,见文末的LFK架构实战练习可视图
二、多种商品格式
将所有组数据通过logstash写入es,通过kibana对所有商品数据进行指标分析,根据IP地理位置画出统计图、地图、组内多少商品,画条形统计图、有多少品牌画饼图、统计出各组的商品数量,统计出各组最贵、最便宜的商品,及商品的平均价格和总价格
现在难度增加,我们有不同格式的数据需要导入ES中,有用逗号分割字段的txt,有bulk_api格式的,有json格式的,这种情况一般是开发将数据写入kafka,logstash去kafka调用,如果不用kafka,我们可以将txt格式和json格式的通过logstash写入,bulk可以通过api调试工具写入,但是如果bulk文件有很多,我们用调试工具写入不方便时,我们就都用logstash,用多条件语句给不同数据打上标签,依照不同标签去执行不同的filter转换。
1、准备商品信息数据
[root@ELK102 homework]# ls
1.txt 3.bulk 5.bulk 7.bulk
2.bulk 4.bulk 6.json 8.json
[root@ELK102 homework]# head -1 1.txt
ip_addr,129.157.137.130,title,曲奇,price,954,brand,曲奇品牌,item,https://item.jd.com/10066410938387.html,group,1,author,koten1
[root@ELK102 homework]# head -2 2.bulk
{ "create": { "_index": "oldboyedu-shopping"} }
{ "ip_addr": "211.144.24.221" ,"title":"赞鹰防弹插板防弹钢板 NIJ IV级碳化硅陶瓷PE复合防弹胸插板2.45KG","price":950,"brand":"赞鹰","item":"https://item.jd.com/100054634181.html?bbtf=1","group":2,"author":"koten2"}
[root@ELK102 homework]# head -1 6.json
{ "ip_addr": "202.189.3.253" ,"title":"果宾斯泰国进口金枕榴莲 新鲜水果 时令生鲜 金枕榴莲3-4斤(精品果1个装)","price":148.00,"brand":"果宾斯","item":"https://item.jd.com/10069719921889.html?bbtf=1","group":6,"author":"koten6"}
2、编辑配置文件
[root@ELK102 ~]# cat config/13-file-filter-es.conf
input {
file {
start_position => "beginning"
path => ["/tmp/homework/*.txt"]
type => "txt"
}
file {
start_position => "beginning"
path => ["/tmp/homework/*.bulk"]
type => "bulk"
}
file {
start_position => "beginning"
path => ["/tmp/homework/*.json"]
type => "json"
}
}
filter {
if [type] == "txt" {
mutate {
split => { "message" => "," }
}
mutate {
add_field => {
ip_addr => "%{[message][1]}"
title => "%{[message][3]}"
price => "%{[message][5]}"
brand => "%{[message][7]}"
item => "%{[message][9]}"
group => "%{[message][11]}"
author => "%{[message][13]}"
}
}
} else if [type] == "bulk" {
if [message] =~ /create/ { #正则匹配,匹配到就过滤掉不去采集
drop { }
}
json {
source => "message"
}
} else if [type] == "json" {
json {
source => "message"
}
}
geoip {
source => "ip_addr"
}
}
output {
elasticsearch {
hosts => ["10.0.0.101:19200","10.0.0.102:19200","10.0.0.103:19200"]
index => "koten-shop-%{+yyyy.MM.dd}"
}
stdout {
codec => rubydebug
}
}
3、运行logstash
将数据写入ES,之后可以在kibana进行数据可视化
[root@ELK102 ~]# rm -rf /usr/share/logstash/data/plugins/inputs/file/.sinced*
[root@ELK102 ~]# logstash -rf config/13-file-filter-es.conf
......
{
"@timestamp" => 2023-05-30T04:17:38.812Z,
"type" => "bulk",
"ip_addr" => "203.107.44.133",
"brand" => "REGISSÖR 瑞吉索",
"group" => 7,
"title" => "以经典设计,满足现代需求——集传统与现代优点于一身的出色家具",
"host" => "ELK102",
"geoip" => {
"timezone" => "Asia/Shanghai",
"ip" => "203.107.44.133",
"continent_code" => "AS",
"latitude" => 34.7732,
"country_name" => "China",
"longitude" => 113.722,
"location" => {
"lon" => 113.722,
"lat" => 34.7732
},
"country_code3" => "CN",
"country_code2" => "CN"
},
"path" => "/tmp/homework/7.bulk",
"message" => "{ \"ip_addr\": \"203.107.44.133\" ,\"title\":\"以经典设计,满足现代需求——集传统与现代优点于一身的出色家具\",\"price\":2999,\"brand\":\"REGISSÖR 瑞吉索\",\"item\":\"https://www.ikea.cn/cn/zh/p/regissoer-rui-ji-suo-gui-zi-he-se-10342079/\",\"group\":7,\"author\":\"koten\"}\r",
"author" => "koten",
"price" => 2999,
"item" => "https://www.ikea.cn/cn/zh/p/regissoer-rui-ji-suo-gui-zi-he-se-10342079/",
"@version" => "1"
}4、kibana数据可视化操作
省略,见文末的LFK架构实战练习可视图
logstash中JVM调优
[root@ELK102 ~]# egrep -v '^$|^#' /etc/logstash/jvm.options
-Xms256m
-Xmx256m
......pipline实现多实例
我们想要运行多个logstash可以有三个方法,一个是用--path.data指定的
nohup logstash -rf /root/config/13-01-file-filter-es.conf --path.data /tmp/logstsh-txt &>/tmp/logstsh-txt.log &
nohup logstash -rf /root/config/13-02-file-filter-es.conf --path.data /tmp/logstsh-bulk &>/tmp/logstsh-bulk.log &
nohup logstash -rf /root/config/13-03-file-filter-es.conf --path.data /tmp/logstsh-json &>/tmp/logstsh-json.log &第二个是用if多条件语句,就是上面多种商品格式用的那种,最后一个就是pipline实现多实例;第一个方法需要开启三个线程,比较麻烦,第二个方法的配置文件可读性比较差,而且容易造成环境污染,我们将配置文件拆分成三个,利用pipline实现多实例,拆分结果如下。
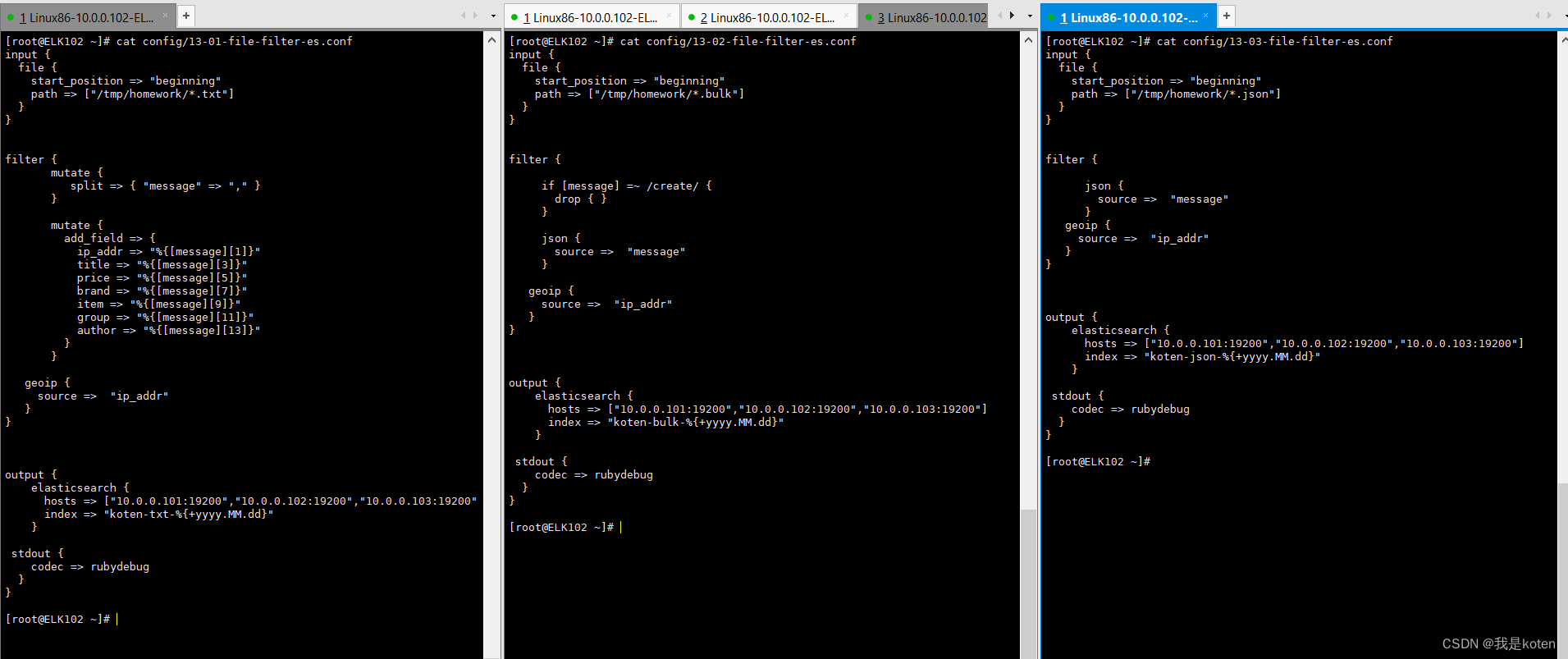
编辑配置文件
[root@ELK102 ~]# egrep -v '^$|^#' /etc/logstash/pipelines.yml
- pipeline.id: txt
path.config: "/root/config/13-01-file-filter-es.conf"
- pipeline.id: bulk
path.config: "/root/config/13-02-file-filter-es.conf"
- pipeline.id: json
path.config: "/root/config/13-03-file-filter-es.conf"
运行logstarsh会默认在/usr/share/logstash/config/pipelines.yml下面找pipelines,所以我们做软链接后运行,将默认找的位置做成软链接
[root@ELK102 ~]# mkdir /usr/share/logstash/config
[root@ELK102 ~]# ln -sv /etc/logstash/pipelines.yml /usr/share/logstash/config
‘/usr/share/logstash/config/pipelines.yml’ -> ‘/etc/logstash/pipelines.yml’
[root@ELK102 ~]# rm -rf /usr/share/logstash/data/plugins/inputs/file/.sincedb_*
[root@ELK102 ~]# logstash
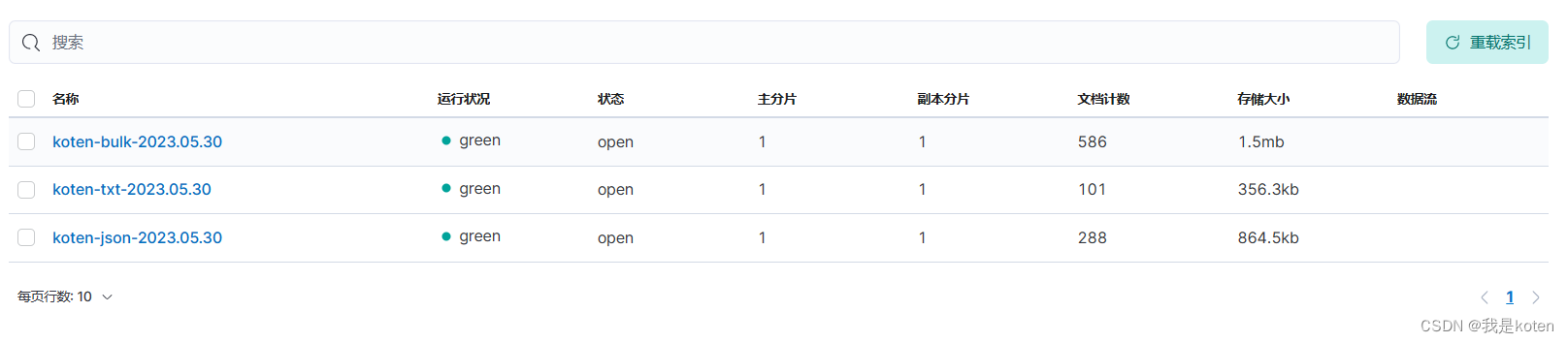
pipline3个配置文件会生成3个.sincedb
[root@ELK102 ~]# ll /usr/share/logstash/data/plugins/inputs/file/.sincedb_
.sincedb_1583e79de3bd324d23b3e420afcc0941
.sincedb_6820bcc3f810e2b39492040f34e3fc55
.sincedb_e0766a8bc4e462ea1f39b4cd06e1dc58
可以在kibana查看索引
一、实现热更新
运行logstash后,我们想停掉某个配置文件的采集和开启新的配置文件的采集,如果每次都停止,写piplines.yml的配置文件,很不方便,所以我们可以在配置文件里写通配符,然后运行logstash -r实现重载
[root@ELK102 ~]# egrep -v '^$|^#' /etc/logstash/pipelines.yml
- pipeline.id: txt
path.config: "/root/config/*.conf"
[root@ELK102 ~]# logstash -r
filebeat部署使用
参考官网链接:https://www.elastic.co/guide/en/beats/filebeat/7.17/configuring-howto-filebeat.html
一、安装部署
1、下载filebeat,与es版本一致,我这边使用7.17.5
[root@ELK103 ~]# wget https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-7.17.5-x86_64.rpm
2、安装filebeat
[root@ELK103 ~]# rpm -ivh filebeat-7.17.5-x86_64.rpm 3、创建工作目录
[root@ELK103 ~]# mkdir config
[root@ELK103 ~]# ln -sv /root/config/ /etc/filebeat/config #这里谁做谁的软链接其实无所谓,反正filebeat默认读etc下的,做软链接,能读到root下的就行
‘/etc/filebeat/config’ -> ‘/root/config/’4、编写配置文件
[root@ELK103 ~]# cat config/01-stdin-to-console.yaml
#指定input插件
filebeat.inputs:
# 类型为标准输出
- type: stdin
# 指定output插件类型为console
output.console:
pretty: true
5、运行输入输出案例,-c是指定配置文件,-e是把日志输出到当前终端
[root@ELK103 ~]# filebeat -e -c config/01-stdin-to-console.yaml
......
1
{
"@timestamp": "2023-05-30T09:39:42.755Z",
"@metadata": {
"beat": "filebeat",
"type": "_doc",
"version": "7.17.5"
},
"host": {
"name": "ELK103"
},
"agent": {
"ephemeral_id": "2e3c2623-23d5-401a-b564-70e18adbe979",
"id": "e4c15441-9b1f-454d-b484-38e809d43a51",
"name": "ELK103",
"type": "filebeat",
"version": "7.17.5",
"hostname": "ELK103"
},
"log": {
"offset": 0,
"file": {
"path": ""
}
},
"message": "1",
"input": {
"type": "stdin"
},
"ecs": {
"version": "1.12.0"
}
}
......二、filebeat采集文本日志
1、编写配置文件
[root@ELK103 ~]# cat config/02-log-to-console.yaml
# 指定input插件的配置
filebeat.inputs:
# 类型为log
- type: log
# 指定日志的路径
paths:
- /tmp/filebeat/*.log
# 指定output插件类型为console
output.console:
pretty: true
2、启动filebeat实例
[root@ELK103 ~]# filebeat -e -c config/02-log-to-console.yaml
3、将数据加进指定路径,查看是否能采集
[root@ELK103 ~]# mkdir /tmp/filebeat
[root@ELK103 ~]# echo 111 > /tmp/filebeat/1.log
[root@ELK103 ~]# echo 222 > /tmp/filebeat/2.log
4、数据成功采集
{
"@timestamp": "2023-05-30T12:59:17.270Z",
"@metadata": {
"beat": "filebeat",
"type": "_doc",
"version": "7.17.5"
},
"log": {
"offset": 0, #从哪个位置输出,可以在日志中修改此值
"file": {
"path": "/tmp/filebeat/1.log"
}
},
"message": "111",
"input": {
"type": "log"
},
"ecs": {
"version": "1.12.0"
},
"host": {
"name": "ELK103"
},
"agent": {
"type": "filebeat",
"version": "7.17.5",
"hostname": "ELK103",
"ephemeral_id": "9fde02dc-f719-4b9c-b52b-d035a5123cdc",
"id": "e4c15441-9b1f-454d-b484-38e809d43a51",
"name": "ELK103"
}
}
2023-05-30T20:59:27.271+0800 INFO [input.harvester] log/harvester.go:309 Harvester started for paths: [/tmp/filebeat/*.log] {"input_id": "3e6b2b68-da05-4ce6-878f-d4fede6dd461", "source": "/tmp/filebeat/2.log", "state_id": "native::18375024-2051", "finished": false, "os_id": "18375024-2051", "harvester_id": "8368ca54-7956-4a55-b93f-f9c64e0bea39"}
{
"@timestamp": "2023-05-30T12:59:27.271Z",
"@metadata": {
"beat": "filebeat",
"type": "_doc",
"version": "7.17.5"
},
"log": {
"offset": 0,
"file": {
"path": "/tmp/filebeat/2.log"
}
},
"message": "222",
"input": {
"type": "log"
},
"ecs": {
"version": "1.12.0"
},
"host": {
"name": "ELK103"
},
"agent": {
"hostname": "ELK103",
"ephemeral_id": "9fde02dc-f719-4b9c-b52b-d035a5123cdc",
"id": "e4c15441-9b1f-454d-b484-38e809d43a51",
"name": "ELK103",
"type": "filebeat",
"version": "7.17.5"
}
}
5、修改运行日志后重新运行会重新读取
需要删除记录的时候直接删除/var/lib/filebeat下的所有
[root@ELK103 ~]# tail -1 /var/lib/filebeat/registry/filebeat/log.json
{"k":"filebeat::logs::native::18375024-2051","v":{"offset":4,"ttl":-1,"prev_id":"","source":"/tmp/filebeat/2.log","timestamp":[2061883432564,1685451872],"type":"log","FileStateOS":{"inode":18375024,"device":2051},"identifier_name":"native","id":"native::18375024-2051"}}
将"offset":4改为"offset":2
[root@ELK103 ~]# tail -1 /var/lib/filebeat/registry/filebeat/log.json
{"k":"filebeat::logs::native::18375024-2051","v":{"offset":2,"ttl":-1,"prev_id":"","source":"/tmp/filebeat/2.log","timestamp":[2061883432564,1685451872],"type":"log","FileStateOS":{"inode":18375024,"device":2051},"identifier_name":"native","id":"native::18375024-2051"}}
#再次运行发现输出了刚刚echo进去的最后一个字符(其实是俩,还有一个换行符)
[root@ELK103 ~]# filebeat -e -c config/02-log-to-console.yaml
......
{
"@timestamp": "2023-05-30T13:17:14.449Z",
"@metadata": {
"beat": "filebeat",
"type": "_doc",
"version": "7.17.5"
},
"message": "2",
"input": {
"type": "log"
},
"ecs": {
"version": "1.12.0"
},
"host": {
"name": "ELK103"
},
"agent": {
"hostname": "ELK103",
"ephemeral_id": "9280127a-b1da-48a5-aa91-e60378fa54a1",
"id": "e4c15441-9b1f-454d-b484-38e809d43a51",
"name": "ELK103",
"type": "filebeat",
"version": "7.17.5"
},
"log": {
"offset": 2,
"file": {
"path": "/tmp/filebeat/2.log"
}
}
}
三、filebeat输出进logstash案例
这种情况要先处理logstash,启动logstash防止filebeat输出的请求接收不到
1、编辑logstash配置文件启动logstash
[root@ELK102 ~]# cat config/14-beats-to-stdout.conf
input {
# 指定输入端为beats
beats {
# 指定监听端口
port => 8888
}
}
output {
stdout {
codec => rubydebug
}
}
[root@ELK102 ~]# logstash -rf config/14-beats-to-stdout.conf
2、编辑filebeat配置文件并启动filebeat
[root@ELK103 ~]# cat config/03-log-to-logstash.yaml
# 指定input插件的配置
filebeat.inputs:
# 类型为log
- type: log
# 指定日志的路径
paths:
- /tmp/filebeat/**/*.log #**代表中间文件夹可有可无,且可有多层文件夹
# 将数据发送到logstash
output.logstash:
hosts: ["10.0.0.102:8888"]
[root@ELK103 ~]# filebeat -e -c config/03-log-to-logstash.yaml
3、写入日志数据查看logstash输出状态
[root@ELK103 ~]# echo aaa > /tmp/filebeat/a.log
[root@ELK102 ~]# logstash -rf config/14-beats-to-stdout.conf
......
{
"@timestamp" => 2023-05-30T13:30:30.118Z,
"log" => {
"file" => {
"path" => "/tmp/filebeat/a.log"
},
"offset" => 0
},
"host" => {
"name" => "ELK103"
},
"ecs" => {
"version" => "1.12.0"
},
"@version" => "1",
"input" => {
"type" => "log"
},
"message" => "aaa",
"tags" => [
[0] "beats_input_codec_plain_applied"
],
"agent" => {
"ephemeral_id" => "9950c19d-912c-457c-881a-0c242de2a04a",
"hostname" => "ELK103",
"type" => "filebeat",
"version" => "7.17.5",
"id" => "e4c15441-9b1f-454d-b484-38e809d43a51",
"name" => "ELK103"
}
}
[root@ELK103 ~]# mkdir /tmp/filebeat/b #测试多级目录是否能采集
[root@ELK103 ~]# echo bbb > /tmp/filebeat/b/b.log
[root@ELK102 ~]# logstash -rf config/14-beats-to-stdout.conf
......
{
"@timestamp" => 2023-05-30T13:31:30.129Z,
"host" => {
"name" => "ELK103"
},
"log" => {
"offset" => 0,
"file" => {
"path" => "/tmp/filebeat/b/b.log"
}
},
"ecs" => {
"version" => "1.12.0"
},
"input" => {
"type" => "log"
},
"@version" => "1",
"message" => "bbb",
"tags" => [
[0] "beats_input_codec_plain_applied"
],
"agent" => {
"ephemeral_id" => "9950c19d-912c-457c-881a-0c242de2a04a",
"hostname" => "ELK103",
"type" => "filebeat",
"version" => "7.17.5",
"id" => "e4c15441-9b1f-454d-b484-38e809d43a51",
"name" => "ELK103"
}
}
4、发现logstash日志比较杂乱,可以筛选出去不想要的字段
[root@ELK102 ~]# cat config/14-beats-to-stdout.conf
input {
# 指定输入端为beats
beats {
# 指定监听端口
port => 8888
}
}
filter {
mutate{
remove_field => [ "@version","agent","host","input","ecs","log","tags" ]
}
}
output {
stdout {
codec => rubydebug
}
}5、再次测试发现字段已经被筛选掉了,变得整洁了许多
[root@ELK102 ~]# logstash -rf config/14-beats-to-stdout.conf
[root@ELK103 ~]# filebeat -e -c config/03-log-to-logstash.yaml
[root@ELK103 ~]# echo ccc > /tmp/filebeat/c.log
[root@ELK102 ~]# logstash -rf config/14-beats-to-stdout.conf
......
{
"@timestamp" => 2023-05-30T13:39:08.946Z,
"message" => "ccc"
}
四、Filebeat输出进ES案例
[root@ELK103 ~]# cat config/06-log-to-es.yaml
filebeat.inputs:
- type: log
paths: ["/tmp/filebeat/*.log"]
output.elasticsearch:
# hosts: ["http://10.0.0.101:19200","http://10.0.0.102:19200","http://10.0.0.103:19200"] #两种格式均可
hosts:
- "http://10.0.0.101:19200"
- "http://10.0.0.102:19200"
- "http://10.0.0.103:19200"五、Input通用字段
1、enabled
默认值为true,指是否启用此字段
2、tags
可以给event打标签,生成tags定义的字段
3、fields
自定义字段,默认自定义的字段在fields字段下面
4、fields_under_root
可以指定值为true,将自定义的字段放在顶级字段,若不指定,则默认储存在fields字段下面
5、测试字段效果
[root@ELK103 ~]# cat config/04-log-to-logstash.yaml
# 指定input插件的配置
filebeat.inputs:
# 类型为log
- type: log
# 指定日志的路径
paths:
- /tmp/filebeat/**/*.log
# 是否启用该配置
enabled: true
# 给event打标签
tags: ["json"]
# 给event添加字段
fields:
name: koten
subject: linux
# 将自定义添加的字段放在顶级字段中,若不指定,则默认存储在"fields"下级字段。
fields_under_root: true
- type: log
paths:
- /tmp/filebeat/**/*.txt
enabled: false
# 将数据发送到logstash
output.logstash:
hosts: ["10.0.0.102:8888"]
[root@ELK103 ~]# echo 1 > /tmp/filebeat/1.txt #enabled:false 不会采集
[root@ELK103 ~]# echo 2 > /tmp/filebeat/2.log #enabled:false 不会采集
[root@ELK102 ~]# logstash -rf config/14-beats-to-stdout.conf
......
{
"message" => "2",
"@timestamp" => 2023-05-30T13:56:36.805Z,
"subject" => "linux",
"name" => "koten"
}六、processors解析
参考官网链接:
https://www.elastic.co/guide/en/beats/filebeat/7.17/filtering-and-enhancing-data.html
有些类似logstash中的filter,但是没有filter强大,也就是说filebeat把类似filter的功能集成在了input的processors中,可以添加字段,指定字段,将字段放在顶级字段,删除事件,json格式解析,删除收集到的字段(默认字段无法删除),对字段进行重命名
[root@ELK103 ~]# cat config/05-log-to-logstash.yaml
filebeat.inputs:
- type: log
paths: ["/tmp/filebeat/*.bulk"]
processors:
# 添加字段
- add_fields:
# 指定将字段放在哪个位置,若不指定,则默认值为"fields"
# 指定为""时,则放在顶级字段中
# target: koten-linux
target: ""
fields:
name: koten
hobby: "nginx,k8s,elk"
# 刪除事件
- drop_event:
# 删除message字段中包含create字样的事件(event)
when:
contains:
message: "create"
# 解码json格式数据
- decode_json_fields:
fields: ["message"]
target: ""
# 删除指定字段,但无法删除filebeat内置的字段,若真有这个需求,请在logstash中删除即可。
#- drop_fields:
# fields: ["name","hobby"]
# ignore_missing: false
# 对字段进行重命名
- rename:
fields:
- from: "name"
to: "name2023"
output.logstash:
hosts: ["10.0.0.102:8888"]
[root@ELK103 ~]# filebeat -e -c config/05-log-to-logstash.yaml
[root@ELK103 ~]# cat /tmp/filebeat/1.bulk
{ "create": { "_index": "oldboyedu-shopping"} }
{ "ip_addr": "221.194.154.181" ,"title":"BMW1系运动轿车 125i M运动曜夜版","price":249900,"brand":"宝马","item":"https://www.bmw-emall.cn/newcar/design?series=1&rangeCode=F52&packageCode=2W71_0ZMB&sop=1672502400000","group":3,"author":"koten"}
[root@ELK102 ~]# logstash -rf config/14-beats-to-stdout.conf
......
{
"name2023" => "koten",
"item" => "https://www.bmw-emall.cn/newcar/design?series=1&rangeCode=F52&packageCode=2W71_0ZMB&sop=1672502400000",
"hobby" => "nginx,k8s,elk",
"@timestamp" => 2023-05-30T14:11:00.873Z,
"group" => 3,
"brand" => "宝马",
"title" => "BMW1系运动轿车 125i M运动曜夜版",
"message" => "{ \"ip_addr\": \"221.194.154.181\" ,\"title\":\"BMW1系运动轿车 125i M运动曜夜版\",\"price\":249900,\"brand\":\"宝马\",\"item\":\"https://www.bmw-emall.cn/newcar/design?series=1&rangeCode=F52&packageCode=2W71_0ZMB&sop=1672502400000\",\"group\":3,\"author\":\"koten\"}",
"author" => "koten",
"ip_addr" => "221.194.154.181",
"price" => 249900
}
logstash总结
logstash介绍了filter插件drop、json,通过pipline实现多实例
filebeat介绍了input的字段,enable,tags,fields,fields_under_root,processors(add_fields、drop_event、decode_json_fields、drop_fields、rename)
还有type(stdin、log)还有 filestream、kafka 没有介绍到
output的类型,stdout、logstash、elasticsearch、kafka
ELFK实战练习
将上面的ELK架构升级为ELFK架构并出图展示,我们将txt格式、bulk格式、json格式分别放入ELK101、ELK102、ELK103节点,用filebeat去采集数据,采集后输出到logstash进行数据转换,提取公网IP的经纬度,由logstash再输出到ES中存储,kibana在ES中查看数据,实现数据可视化。
我的大致思路是由filebeat跳过bulk中的creates的json语句,减轻logstash的压力,这样bulk输出的内容就跟json格式一样了,然后我准备两个logstash配置文件,一个准备接收txt的文件输出,一个准备接收bulk、json的文件输出,将不需要的字段删除掉,然后用pipeline都运行起来,其实filbeat做的操作可以更多,我这边不过多展示了,还可以以指定字符分割文本解析成json
一、准备需要采集的数据
[root@ELK101 ~]# mkdir data
[root@ELK102 ~]# mkdir data
[root@ELK103 ~]# mkdir data
[root@ELK102 ~]# scp /tmp/homework/*.txt 10.0.0.101:/root/data
[root@ELK102 ~]# scp /tmp/homework/*.json 10.0.0.103:/root/data
[root@ELK102 ~]# cp /tmp/homework/*.bulk /root/data
[root@ELK101 data]# head -1 1.txt
ip_addr,129.157.137.130,title,曲奇,price,954,brand,曲奇品牌,item,https://item.jd.com/10066410938387.html,group,1,author,koten1
[root@ELK102 data]# head -2 2.bulk
{ "create": { "_index": "oldboyedu-shopping"} }
{ "ip_addr": "211.144.24.221" ,"title":"赞鹰防弹插板防弹钢板 NIJ IV级碳化硅陶瓷PE复合防弹胸插板2.45KG","price":950,"brand":"赞鹰","item":"https://item.jd.com/100054634181.html?bbtf=1","group":2,"author":"koten2"}
[root@ELK103 data]# head -1 6.json
{ "ip_addr": "202.189.3.253" ,"title":"果宾斯泰国进口金枕榴莲 新鲜水果 时令生鲜 金枕榴莲3-4斤(精品果1个装)","price":148.00,"brand":"果宾斯","item":"https://item.jd.com/10069719921889.html?bbtf=1","group":6,"author":"koten6"}
二、三台主机均安装filebeat,分别编写主机的filebeat的配置文件
#安装配置步骤省略
[root@ELK101 ~]# cat config/01-log-to-logstash.yaml
filebeat.inputs:
- type: log
paths:
- /root/data/*.txt
output.logstash:
hosts: ["10.0.0.102:8888"]
[root@ELK102 ~]# cat config/01-log-to-logstash.yaml
filebeat.inputs:
- type: log
paths:
- /root/data/*.bulk
processors:
# 刪除事件
- drop_event:
# 删除message字段中包含create字样的事件(event)
when:
contains:
message: "create"
output.logstash:
hosts: ["10.0.0.102:9999"]
[root@ELK103 ~]# cat config/08-log-to-logstash.yaml
filebeat.inputs:
- type: log
paths:
- /root/data/*.json
output.logstash:
hosts: ["10.0.0.102:9999"]三、编写logstash的配置文件和pipeline配置文件
[root@ELK102 ~]# cat config_logstash/15-01-filebeat-filter-es.conf
input {
beats {
port => 8888
}
}
filter {
mutate {
split => { "message" => "," }
}
mutate {
add_field => {
ip_addr => "%{[message][1]}"
title => "%{[message][3]}"
price => "%{[message][5]}"
brand => "%{[message][7]}"
item => "%{[message][9]}"
group => "%{[message][11]}"
author => "%{[message][13]}"
}
}
geoip {
source => "ip_addr"
}
}
output {
elasticsearch {
hosts => ["10.0.0.101:19200","10.0.0.102:19200","10.0.0.103:19200"]
index => "koten-shop-%{+yyyy.MM.dd}"
}
stdout {
codec => rubydebug
}
}
[root@ELK102 ~]# cat config_logstash/15-02-filebeat-filter-es.conf
input {
beats {
port => 9999
}
}
filter {
json {
source => "message"
}
geoip {
source => "ip_addr"
}
}
output {
elasticsearch {
hosts => ["10.0.0.101:19200","10.0.0.102:19200","10.0.0.103:19200"]
index => "koten-shop-%{+yyyy.MM.dd}"
}
stdout {
codec => rubydebug
}
}
[root@ELK102 ~]# egrep -v '^$|^#' /etc/logstash/pipelines.yml
- pipeline.id: txt
path.config: "/root/config_logstash/15-01-filebeat-filter-es.conf"
- pipeline.id: bulk-json
path.config: "/root/config_logstash/15-02-filebeat-filter-es.conf"
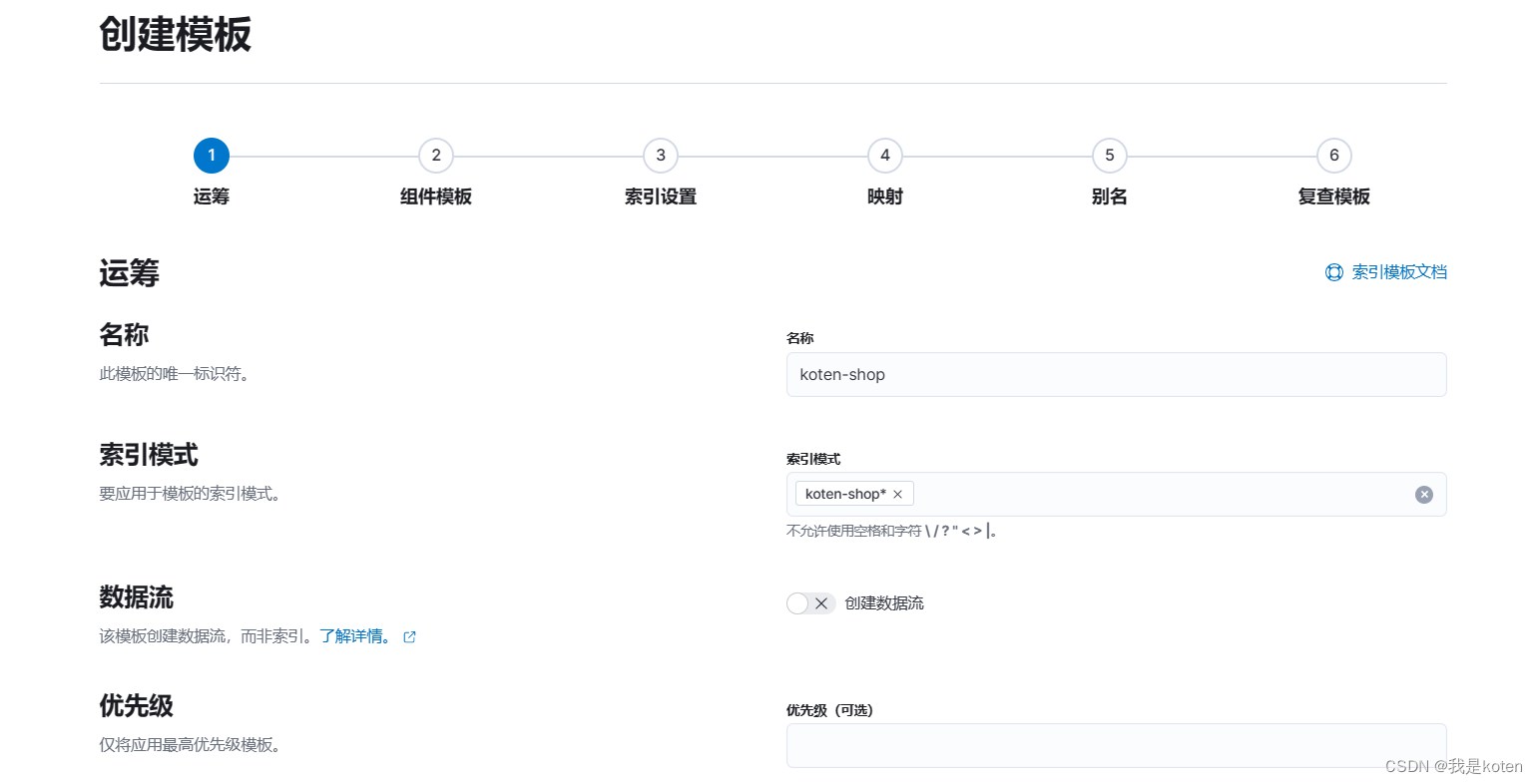
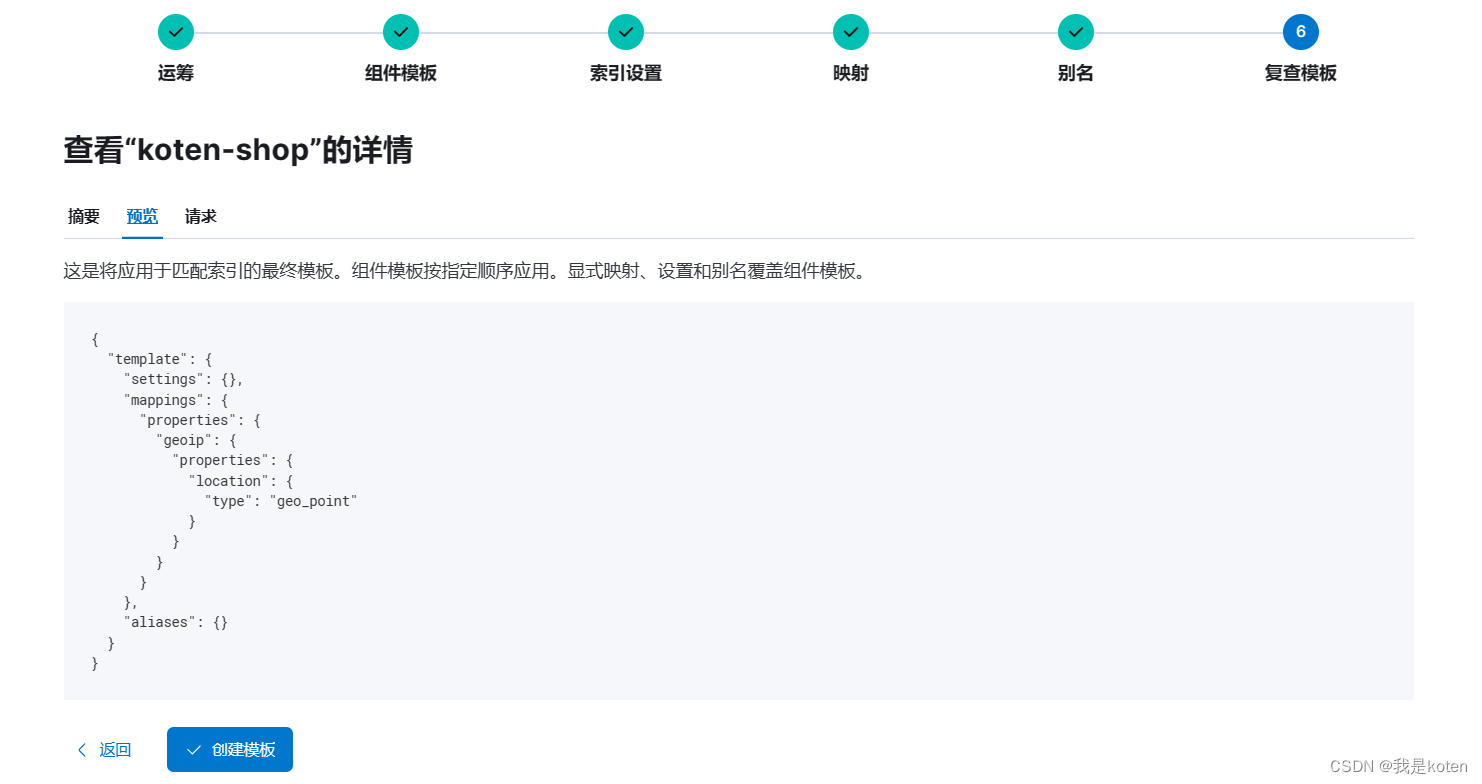
四、在kibana创建索引模板


五、运行logstash、filebeat写入数据到ES
#删除全部索引和logstash写入记录
[root@ELK102 ~]# rm -rf /usr/share/logstash/data/plugins/inputs/file/.sincedb_*
#如果之前执行过filebeat没成功可以把filebeat写入记录也删下
[root@ELK101 ~]#rm -rf /var/lib/filebeat/*
[root@ELK102 ~]#rm -rf /var/lib/filebeat/*
[root@ELK103 ~]#rm -rf /var/lib/filebeat/*
[root@ELK102 ~]# logstash #等待logstash运行起来再执行filebeat
[root@ELK101 ~]# filebeat -e -c config/01-log-to-logstash.yaml
[root@ELK102 ~]# filebeat -e -c config/01-log-to-logstash.yaml
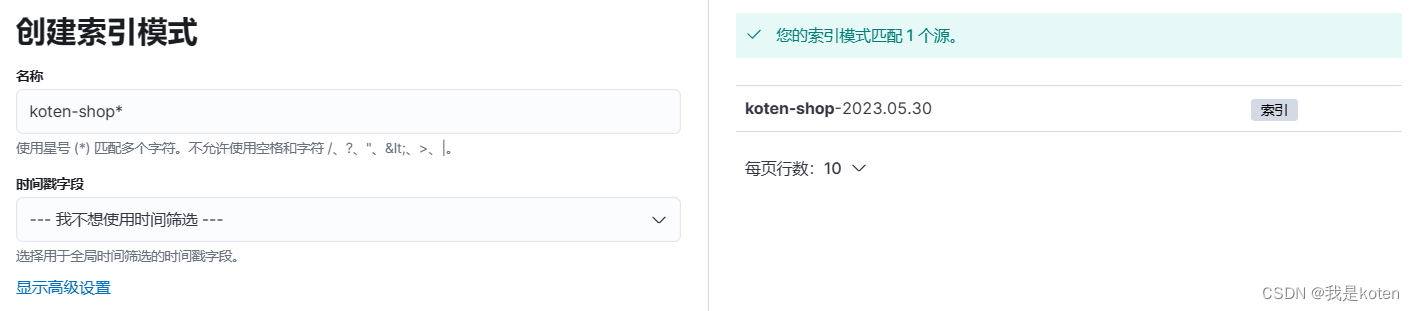
[root@ELK103 ~]# filebeat -e -c config/08-log-to-logstash.yaml 六、kibana创建索引模式查看数据

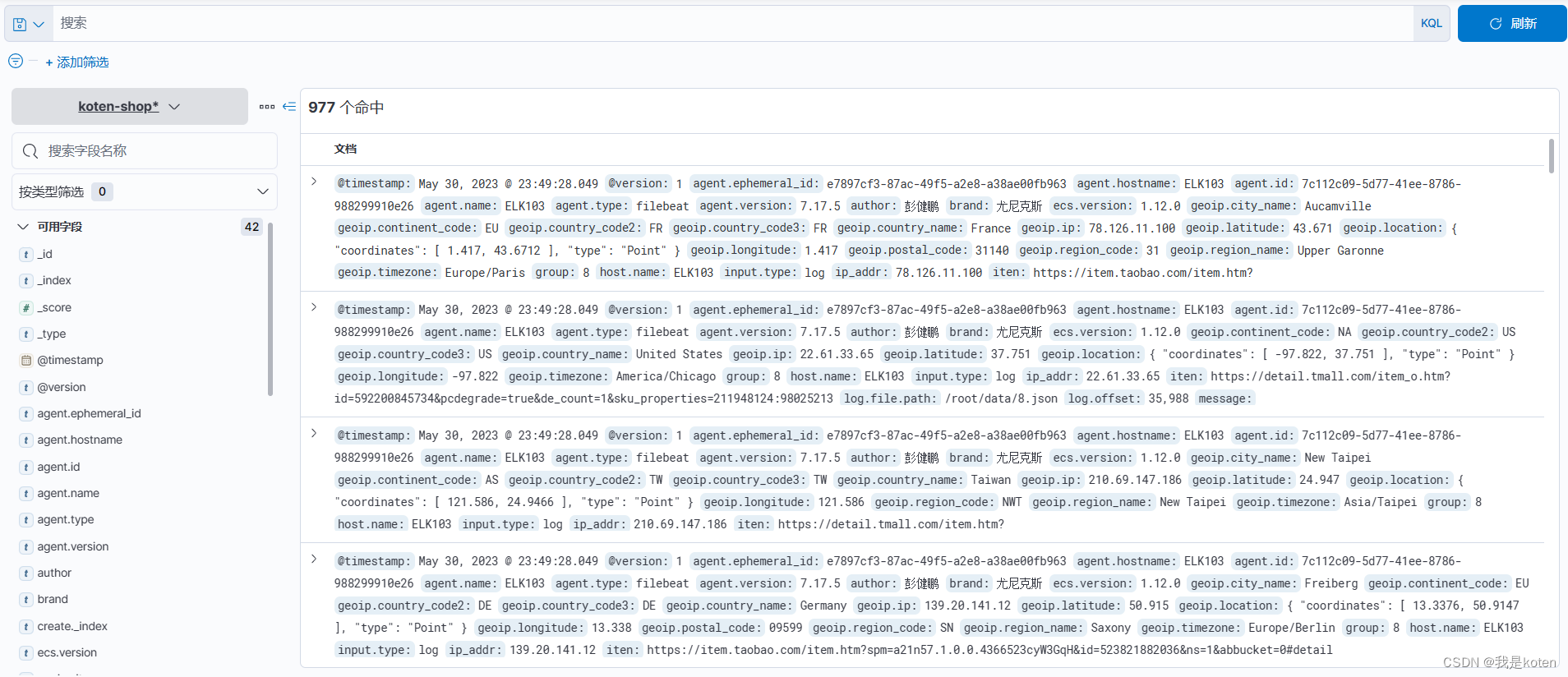
七、kibana分析数据制作可视化
制作并保存地图
图片违规不展示了......

保存新建的仪表盘
创建新的可视化



在时间这里可以设置图定时刷新数据,每5秒刷新一次,点击启动。

可以切换到查看模式和大屏方便查看


我是koten,10年运维经验,持续分享运维干货,感谢大家的阅读和关注!