目录
通过不同的算法来创建模型,并评估它们的准确度,以便找到最合适的算法。
5 模型实现
5.1 分离出评估数据集
分离出评估数据集是机器学习中常见的步骤,通常通过将数据集分为训练集和测试集来完成。在Python中,你可以使用train_test_split函数来实现这一步骤。以下是一个简单的示例代码:
from sklearn.model_selection import train_test_split
# 假设X是特征数据,y是目标标签
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# test_size表示测试集的比例,这里设置为0.2,即20%的数据作为测试集
# random_state用于设置随机种子,确保每次运行代码时划分的训练集和测试集保持一致
在这个例子中,X是特征数据,y是目标标签。train_test_split函数将数据集划分为训练集和测试集,其中80%的数据用于训练,20%的数据用于评估模型的性能。
5.2 创建不同的模型来预测新数据
from sklearn.model_selection import train_test_split, cross_val_score
from sklearn.linear_model import LogisticRegression
from sklearn.neighbors import KNeighborsClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.svm import SVC
from sklearn.ensemble import RandomForestClassifier
from sklearn.naive_bayes import GaussianNB
from sklearn.metrics import accuracy_score
# 假设X是特征数据,y是目标标签
# 这里使用train_test_split分离出评估数据集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 生成不同的模型
models = {
'Logistic Regression': LogisticRegression(),
'K Neighbors Classifier': KNeighborsClassifier(),
'Decision Tree Classifier': DecisionTreeClassifier(),
'SVM Classifier': SVC(),
'Random Forest Classifier': RandomForestClassifier(),
'Naive Bayes Classifier': GaussianNB()
}
这段代码使用了Python中的
scikit-learn库来创建、训练和评估不同的分类模型。
导入必要的库和模块:
train_test_split: 用于将数据集分割为训练集和测试集。- 每个模型的具体分类算法:
LogisticRegression: 逻辑回归KNeighborsClassifier: K近邻分类器DecisionTreeClassifier: 决策树分类器SVC: 支持向量机分类器RandomForestClassifier: 随机森林分类器GaussianNB: 朴素贝叶斯分类器accuracy_score: 用于计算分类模型的准确度。分割训练集和测试集: 使用
train_test_split函数将特征数据X和目标标签y分割为训练集和测试集。test_size=0.2表示将20%的数据用于测试,random_state=42是为了确保每次运行代码时分割结果的一致性。生成不同的模型: 使用字典
models存储了六个不同的分类模型,每个模型都由相应的算法实例化。这些模型包括逻辑回归、K近邻、决策树、支持向量机、随机森林和朴素贝叶斯。
5.3 采用10折交叉验证来评估算法模型
10折交叉验证是一种常用的模型评估方法,它将训练集分成10个相似的子集,然后进行10轮训练和评估。每一轮,模型都会在其中9个子集上训练,并在剩余的一个子集上进行评估。这样,每个子集都有机会成为评估集,而模型的性能指标是这10轮评估的平均值。
from sklearn.model_selection import cross_val_score
# 生成不同的模型
models = {
'Logistic Regression': LogisticRegression(),
'K Neighbors Classifier': KNeighborsClassifier(),
'Decision Tree Classifier': DecisionTreeClassifier(),
'SVM Classifier': SVC(),
'Random Forest Classifier': RandomForestClassifier(),
'Naive Bayes Classifier': GaussianNB()
}
# 采用10折交叉验证评估算法模型
for model_name, model in models.items():
scores = cross_val_score(model, X_train, y_train, cv=10, scoring='accuracy')
print(f"{model_name} Cross-Validation Accuracy: {scores.mean():.2f} (Std: {scores.std():.2f})")
这里的关键部分包括:
cross_val_score: 用于执行交叉验证。cv=10表示采用10折交叉验证。scoring='accuracy': 表示使用准确度来评估模型的性能。其他评估指标也可以选择,例如精确度、召回率等。在每个模型上,
cross_val_score会执行10折交叉验证,输出每折的准确度(Accuracy)并计算均值和标准差。这有助于了解模型在不同数据子集上的表现,并提供更稳健的性能估计。
5.4 生成最优模型
# 选择最优模型
best_model_name = max(models, key=lambda k: cross_val_score(models[k], X_train, y_train, cv=10, scoring='accuracy').mean())
best_model_instance = models[best_model_name]
# 在测试集上评估最优模型
best_model_instance.fit(X_train, y_train)
y_pred = best_model_instance.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print(f"\nBest Model: {best_model_name}")
print(f"Test Accuracy: {accuracy:.2f}")
这里使用了
max函数和key参数,通过比较每个模型在交叉验证中的准确度均值,选择性能最好的模型名称best_model_name。然后,通过该名称从模型字典models中获取最优模型的实例best_model_instance。接着,对最优模型进行训练,并在测试集上进行预测,计算模型在测试集上的准确度。最后,输出最优模型的名称和测试准确度。
6 实施预测
实施预测并生成评估报告,你可以使用模型的predict方法对评估数据集进行预测,然后使用classification_report函数生成包含准确率、精确率、召回率等指标的报告。以下是一个示例代码:
from sklearn.metrics import classification_report
# 实施预测
y_pred = best_model_instance.predict(X_test)
# 生成评估报告
report = classification_report(y_test, y_pred)
# 输出报告
print("Evaluation Report:\n", report)
上述代码中使用了
classification_report函数,该函数接受真实标签y_test和预测标签y_pred作为参数,计算并生成包含准确率、精确率、召回率等指标的评估报告。你可以根据具体需要调整评估指标,例如通过修改
classification_report函数的参数。
7 模型评估
在机器学习中,评估模型的性能通常需要选择适当的评估指标和评估方法。以下是一些常用的评估模型性能的模式:
7.1 准确度(Accuracy):
准确度是分类问题中最常用的评估指标,表示正确预测的样本占总样本的比例。计算方式为正确预测的样本数除以总样本数。
from sklearn.metrics import accuracy_score
accuracy = accuracy_score(y_true, y_pred)
7.2 精确度(Precision):
精确度表示在所有被模型预测为正类别的样本中,真正为正类别的样本的比例。适用于关注假正例的问题。
from sklearn.metrics import precision_score
precision = precision_score(y_true, y_pred)
7.3 召回率(Recall):
召回率表示在所有实际正类别的样本中,被模型正确预测为正类别的样本的比例。适用于关注假负例的问题。
from sklearn.metrics import recall_score
recall = recall_score(y_true, y_pred)
7.4 F1 分数:
F1分数综合考虑了精确度和召回率,是精确度和召回率的调和平均值。
from sklearn.metrics import f1_score
f1 = f1_score(y_true, y_pred)
7.5 混淆矩阵:
提供了模型在不同类别上的详细性能指标,包括真正例、假正例、真负例和假负例的数量。
from sklearn.metrics import confusion_matrix
conf_matrix = confusion_matrix(y_true, y_pred)
这些是常用于评估分类模型性能的模式。选择适当的模式取决于问题的特性和关注的方面。
8 完整代码
(1)鸾尾花分类的完整代码
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split, cross_val_score
from sklearn.linear_model import LogisticRegression
from sklearn.neighbors import KNeighborsClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.svm import SVC
from sklearn.ensemble import RandomForestClassifier
from sklearn.naive_bayes import GaussianNB
from sklearn.metrics import accuracy_score, classification_report
# 加载鸾尾花数据集
iris = load_iris()
X = iris.data
y = iris.target
# 分割数据集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 生成不同的模型
models = {
'Logistic Regression': LogisticRegression(),
'K Neighbors Classifier': KNeighborsClassifier(),
'Decision Tree Classifier': DecisionTreeClassifier(),
'SVM Classifier': SVC(),
'Random Forest Classifier': RandomForestClassifier(),
'Naive Bayes Classifier': GaussianNB()
}
# 采用10折交叉验证评估算法模型
for model_name, model in models.items():
scores = cross_val_score(model, X_train, y_train, cv=10, scoring='accuracy')
print(f"{model_name} Cross-Validation Accuracy: {scores.mean():.2f} (Std: {scores.std():.2f})")
# 选择最优模型
best_model_name = max(models, key=lambda k: cross_val_score(models[k], X_train, y_train, cv=10, scoring='accuracy').mean())
best_model_instance = models[best_model_name]
# 在测试集上评估最优模型
best_model_instance.fit(X_train, y_train)
y_pred = best_model_instance.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print(f"\nBest Model: {best_model_name}")
print(f"Test Accuracy: {accuracy:.2f}")
# 生成评估报告
report = classification_report(y_test, y_pred)
print("\nEvaluation Report:\n", report)
运行:
Logistic Regression Cross-Validation Accuracy: 0.95 (Std: 0.08)
K Neighbors Classifier Cross-Validation Accuracy: 0.94 (Std: 0.07)
Decision Tree Classifier Cross-Validation Accuracy: 0.92 (Std: 0.10)
SVM Classifier Cross-Validation Accuracy: 0.95 (Std: 0.07)
Random Forest Classifier Cross-Validation Accuracy: 0.93 (Std: 0.10)
Naive Bayes Classifier Cross-Validation Accuracy: 0.94 (Std: 0.08)Best Model: Logistic Regression
Test Accuracy: 1.00
Evaluation Report:
precision recall f1-score support
0 1.00 1.00 1.00 10
1 1.00 1.00 1.00 9
2 1.00 1.00 1.00 11
accuracy 1.00 30
macro avg 1.00 1.00 1.00 30
weighted avg 1.00 1.00 1.00 30
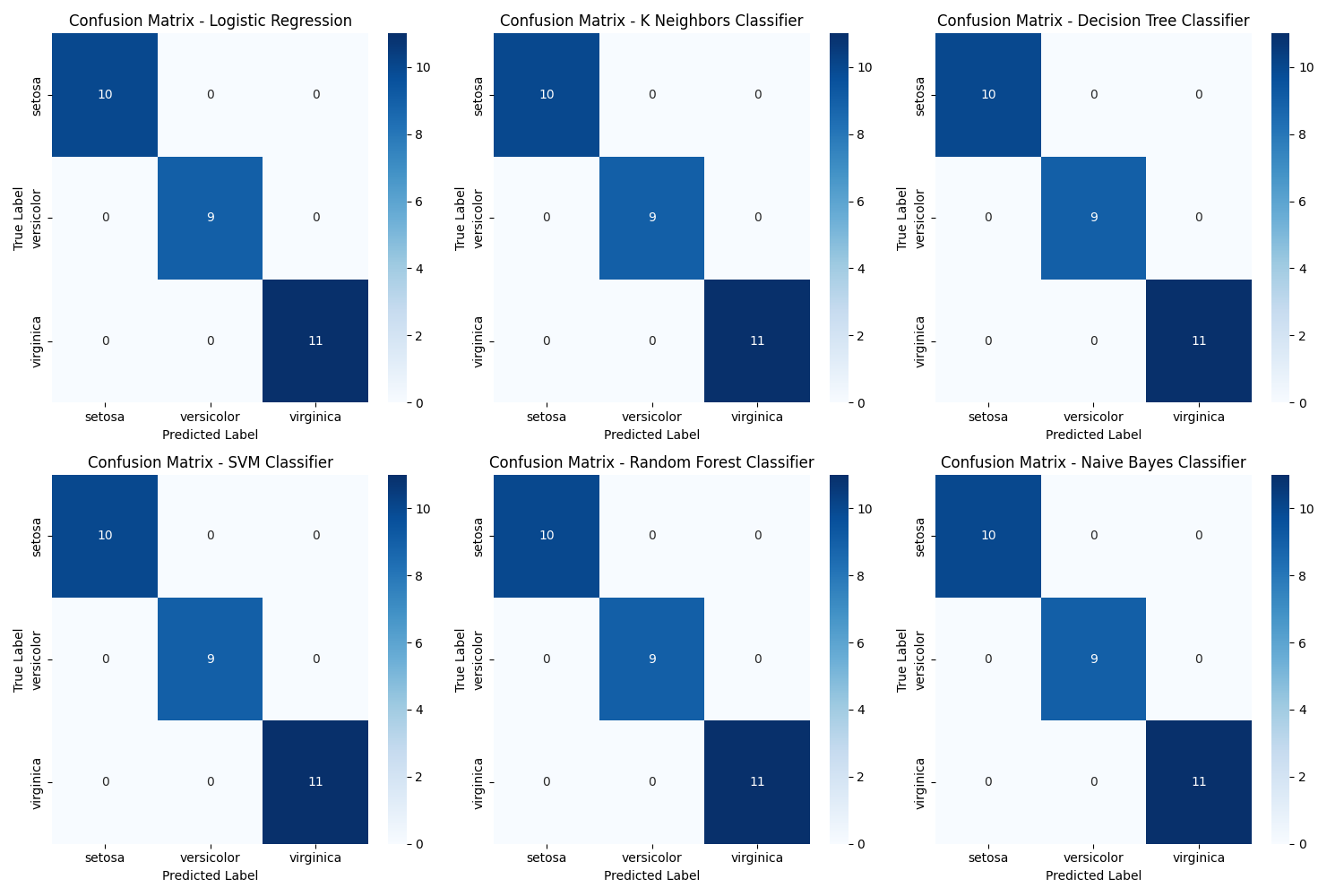
(2)可视化以上不同模型预测的评估结果
下面是对不同模型进行10折交叉验证准确率的可视化代码。在这个例子中,我们将每个模型的交叉验证准确率以子图的形式展示:
# 初始化画布
fig, axes = plt.subplots(nrows=2, ncols=3, figsize=(15, 10))
axes = axes.flatten()
# 遍历每个模型
for i, (model_name, model) in enumerate(models.items()):
# 采用10折交叉验证获取准确率
scores = cross_val_score(model, X_train, y_train, cv=10, scoring='accuracy')
# 绘制准确率直方图
axes[i].hist(scores, bins=np.arange(0, 1.1, 0.1), edgecolor='black', alpha=0.7)
axes[i].set_title(model_name)
axes[i].set_xlabel('Accuracy')
axes[i].set_ylabel('Frequency')
# 调整子图布局
plt.tight_layout()
plt.show()
为了输出不同模型的预测评估参数图表,我们可以使用混淆矩阵来展示每个模型的分类性能。添加了混淆矩阵的绘制功能需要的代码:
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.metrics import confusion_matrix
# 生成混淆矩阵
# 设置子图布局
fig, axes = plt.subplots(2, 3, figsize=(15, 10))
# 在测试集上评估每个模型并生成混淆矩阵
for (model_name, model), ax in zip(models.items(), axes.flatten()):
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
# 生成混淆矩阵
cm = confusion_matrix(y_test, y_pred)
# 绘制混淆矩阵
sns.heatmap(cm, annot=True, fmt='d', cmap='Blues', xticklabels=iris.target_names, yticklabels=iris.target_names, ax=ax)
ax.set_title(f'Confusion Matrix - {model_name}')
ax.set_xlabel('Predicted Label')
ax.set_ylabel('True Label')
# 调整子图布局
plt.tight_layout()
plt.show()结果: