文章目录
00 写在前面
- 蓝色括号里面带了os的,是我自己的内心所想,仅供参考
- 最后面有一些疑问,欢迎各位大佬解答
0 参考链接
- 代码参考–B站视频:YOLOV8改进(三),下采样Conv替换为更细粒度的SPDConv,亲测小目标长点!
- 概念参考–知乎文章:YOLOv5、v7改进之四十一:引入SPD-Conv处理低分辨率图像和小对象问题
- ⭐重点参考的简明版CSDN博文:针对低分辨率或小目标的卷积-SPDConv,有论文、源码地址
- 论文地址:No More Strided Convolutions or Pooling: A New CNN Building Block for Low-Resolution
Images and Small Objects - 仓库地址:https://gitcode.com/mirrors/labsaint/spd-conv/tree/main,重点查看
YOLOv5-SPD文件夹,里面的网络结构YOLOv5-SPD/models/space_depth_s.yaml定义了SPDConv应用在YOLOv5s里面的网络结构,核心代码是YOLOv5-SPD/models/common.py里面的函数space_to_depth - 本文的基本原理部分的图片来自这篇博文
- 论文地址:No More Strided Convolutions or Pooling: A New CNN Building Block for Low-Resolution
1 摘要
解决问题:用于图像处理中低分辨率图像和小对象难以检测的问题
在本文中,我们指出,这根源于现有CNN架构中存在的一个有缺陷但常见的设计,即使用strided convolution或pooling layers,这导致细粒度信息的丢失和不够有效的特征表示的学习。为此,我们提出了一个新的CNN构建快, 称为SPD-Conv,取代每个strided convolution层和每个pool层(因为完全消除他们)。SPD-Conv由一个space-to-depth(SPD)层和一个non-strided convolution层组成,可以应用于大多数CNN架构。
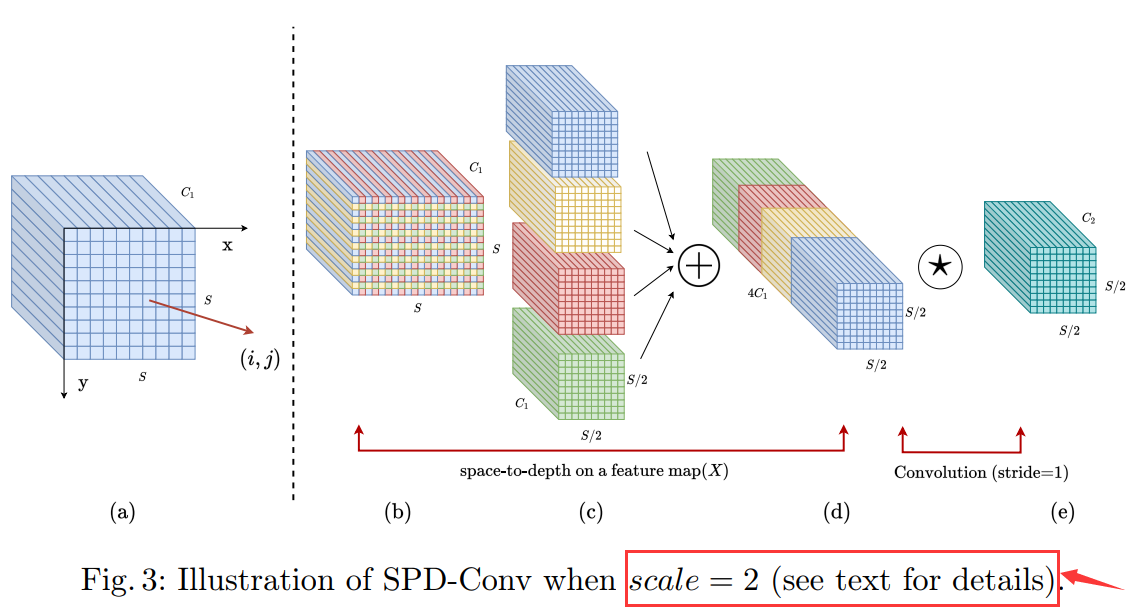
2 基本原理
为了解决这一问题,我们提出了一种CNN的新构建快,称为SPD-Conv 完全替代了下采样和池化(os:特征图高宽将缩小为原始的1/2)。SPD-Conv是一个空间到深度层,仅跟随一个非步幅卷积层。SPD层对特征图X进行将采样,当保留了通道维度中的所有信息,因此没有信息损失,我们受到了图像转换技术的启发,该技术在将原始图像馈送到神经网络之前对其进行重新缩放,但我们将其广泛推广到网络内部和整个网络中的特征图的将采样,此外,我们在每个SPD之后添加了一卷积操作,使用科学系的参数减少通道数量,我们提出的方法即通用又统一,即SPD可以应用于大多数CNN架构,并且以相同的方式替代了步幅卷积和池化。


3 代码(前面是对比介绍,最后是直接可用的代码)
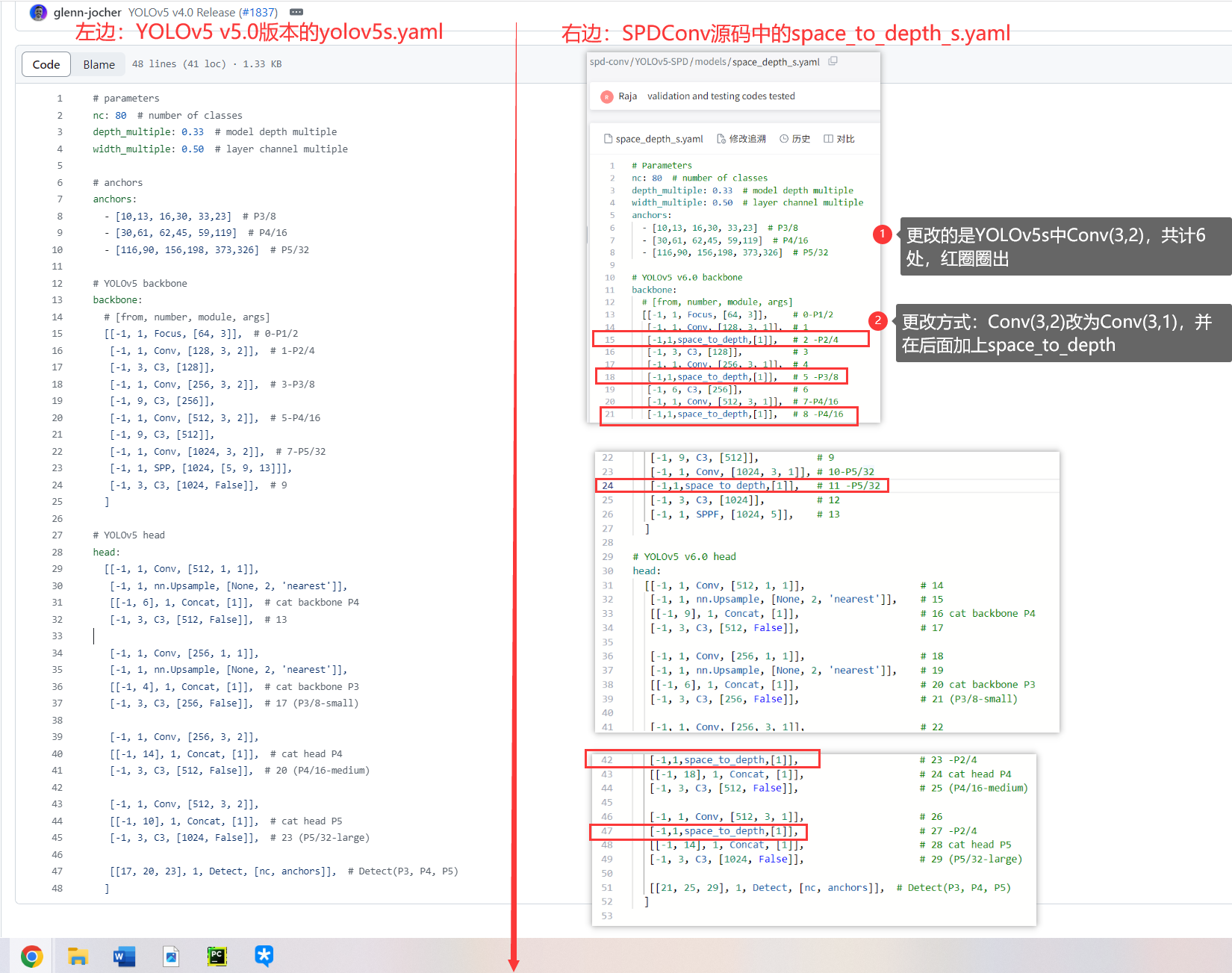
就是将YOLOv7-tiny里面的Conv(3,2)替换为SPDConv(3,1),共更改了4处
- Conv(3,2)是简写,表示为使用卷积核大小为3×3,步长为2,按照计算公式,特征图尺寸将缩小为原始的一半
- SPDConv(3,1)也是简写,表示为使用卷积核大小为3×3,步长为1,按照计算公式,特征图尺寸将保持不变
- 计算公式:输出图像尺寸 = (输入图像尺寸 - 卷积核尺寸 + 2 * 填充)/ 步长 + 1
(os:如果参考文章上面写的那个B站视频,使用大小为1×1的、步长为1的卷积核,计算量和参数量会减少一些,但是可能效果没有那么好(看评论好像效果不大行),然后参考SPDConv的源码,它们也是使用的3×3卷积核,所以本文用到的SPDConv是3×3大小的,实验结果mAP50能提升1.2个百分点)
3.1 SPDConv源码中的space_to_depth代码
- 仓库地址:https://gitcode.com/mirrors/labsaint/spd-conv/tree/main,重点查看
YOLOv5-SPD文件夹,里面的网络结构YOLOv5-SPD/models/space_depth_s.yaml定义了SPDConv应用在YOLOv5s里面的网络结构,核心代码是YOLOv5-SPD/models/common.py里面的函数space_to_depth - 下列代码是将函数
space_to_depth截取出来后,导包和写main函数,使得可以打印出经过spd后的特征图尺寸- 对比output和input可以发现,经过spd之后,特征图的通道数成为了原来的4倍,高宽变为了原来的1/2
import torch
import torch.nn as nn
class space_to_depth(nn.Module):
# Changing the dimension of the Tensor
def __init__(self, dimension=1):
super().__init__()
self.d = dimension
def forward(self, x):
return torch.cat([x[..., ::2, ::2], x[..., 1::2, ::2], x[..., ::2, 1::2], x[..., 1::2, 1::2]], 1)
if __name__ == '__main__':
input = torch.randn(1, 128, 8, 8) # bachsize, c, h, w
spd = space_to_depth()
output = spd(input)
print(output.shape) # torch.Size([1, 512, 4, 4])
来自chatgpt的解释:
在前向传播过程中,torch.cat函数将输入张量 x 按照以下方式进行拼接:
第一个拼接项:x[…, ::2, ::2],表示取输入张量 x 在高度和宽度上步长为2的偶数位置的子图像。
第二个拼接项:x[…, 1::2, ::2],表示取输入张量 x 在高度上步长为2的奇数位置、宽度上步长为2的偶数位置的子图像。
第三个拼接项:x[…, ::2, 1::2],表示取输入张量 x 在高度上步长为2的偶数位置、宽度上步长为2的奇数位置的子图像。
第四个拼接项:x[…, 1::2, 1::2],表示取输入张量 x 在高度和宽度上步长为2的奇数位置的子图像。
3.2 SPDConv源码中是怎么使用spd的呢?
- 查看源码,发现没有直接可用的
SPDConv模块,作者是在网络结构space_depth_s.yaml中定义成了这种 - 以15行的
[-1,1,space_to_depth,[1]],为例,最后面的[1]代表的是space_to_depth中需要的dimension参数,定义从哪个维度进行操作,默认为1
3.3 直接可用的代码
3.3.1 定义SPDConv模块:将源码space_to_depth和Conv直接融合在一起
在yolov7-main-biyebase/models中新建一个名为SPDConv.py的文件,将以下代码复制进去
import torch.nn as nn
import torch
from models.common import Conv
class SPDConv(nn.Module):
# Changing the dimension of the Tensor
def __init__(self, inc=64, outc=128, dimension=1):
super(SPDConv, self).__init__()
self.d = dimension
self.conv = Conv(4*inc, outc, 3, 1, None, 1, nn.LeakyReLU(0.1))
def forward(self, x):
return self.conv(torch.cat([x[..., ::2, ::2], x[..., 1::2, ::2], x[..., ::2, 1::2], x[..., 1::2, 1::2]], self.d))
if __name__ == '__main__':
input = torch.randn(1, 128, 8, 8)
spdconv = SPDConv(128)
output = spdconv(input)
print(output.shape)
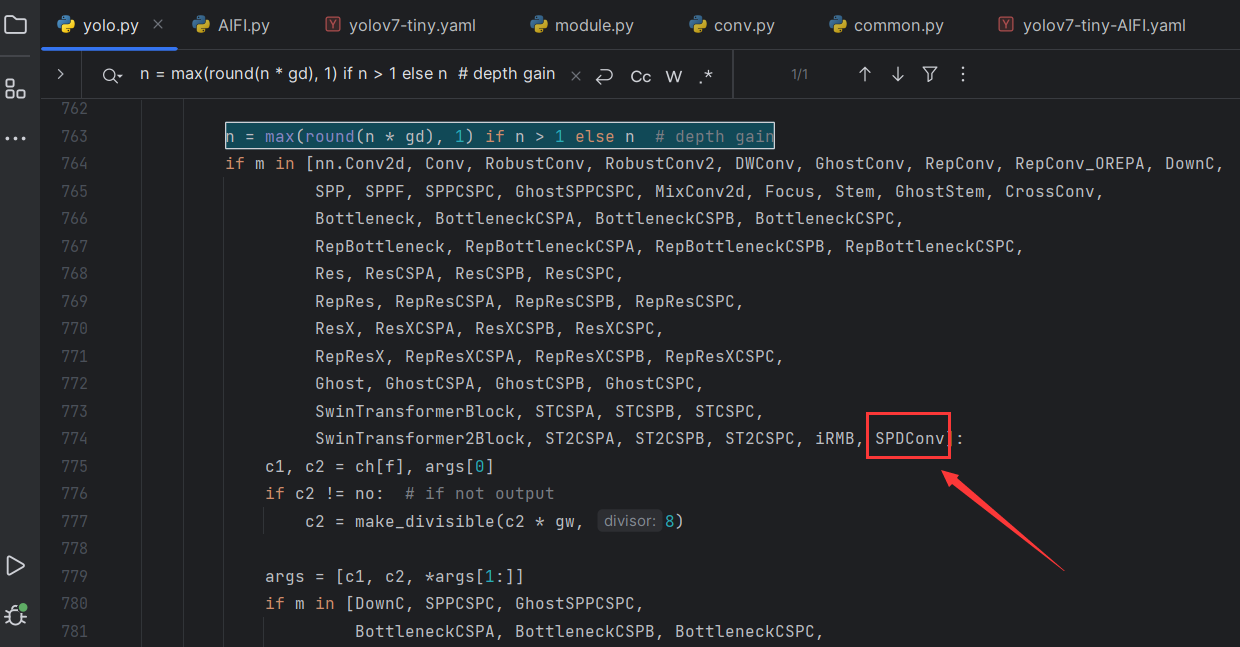
3.3.2 在yolo.py中修改
- 导入包
from models.SPDConv import SPDConv
- 搜索
n = max(round(n * gd), 1) if n > 1 else n # depth gain,然后在下图位置添加SPDConv
3.3.3 网络结构:YOLOv7-tiny-SPDConv.yaml
# parameters
nc: 80 # number of classes
depth_multiple: 1.0 # model depth multiple
width_multiple: 1.0 # layer channel multiple
# anchors
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# yolov7-tiny backbone
backbone:
# [from, number, module, args] c2, k=1, s=1, p=None, g=1, act=True
[[-1, 1, SPDConv, [32]], # 0-P1/2
[-1, 1, SPDConv, [64]], # 1-P2/4
[-1, 1, Conv, [32, 1, 1, None, 1, nn.LeakyReLU(0.1)]], # ---------------ELAN Backbone-1
[-2, 1, Conv, [32, 1, 1, None, 1, nn.LeakyReLU(0.1)]],
[-1, 1, Conv, [32, 3, 1, None, 1, nn.LeakyReLU(0.1)]],
[-1, 1, Conv, [32, 3, 1, None, 1, nn.LeakyReLU(0.1)]],
[[-1, -2, -3, -4], 1, Concat, [1]],
[-1, 1, Conv, [64, 1, 1, None, 1, nn.LeakyReLU(0.1)]], # 7 ------------ELAN Backbone-1 end
[-1, 1, MP, []], # 8-P3/8
[-1, 1, Conv, [64, 1, 1, None, 1, nn.LeakyReLU(0.1)]], # ---------------ELAN Backbone-2
[-2, 1, Conv, [64, 1, 1, None, 1, nn.LeakyReLU(0.1)]],
[-1, 1, Conv, [64, 3, 1, None, 1, nn.LeakyReLU(0.1)]],
[-1, 1, Conv, [64, 3, 1, None, 1, nn.LeakyReLU(0.1)]],
[[-1, -2, -3, -4], 1, Concat, [1]],
[-1, 1, Conv, [128, 1, 1, None, 1, nn.LeakyReLU(0.1)]], # 14 ----------ELAN Backbone-2 end
[-1, 1, MP, []], # 15-P4/16
[-1, 1, Conv, [128, 1, 1, None, 1, nn.LeakyReLU(0.1)]], # --------------ELAN Backbone-3
[-2, 1, Conv, [128, 1, 1, None, 1, nn.LeakyReLU(0.1)]],
[-1, 1, Conv, [128, 3, 1, None, 1, nn.LeakyReLU(0.1)]],
[-1, 1, Conv, [128, 3, 1, None, 1, nn.LeakyReLU(0.1)]],
[[-1, -2, -3, -4], 1, Concat, [1]],
[-1, 1, Conv, [256, 1, 1, None, 1, nn.LeakyReLU(0.1)]], # 21 ----------ELAN Backbone-3 end
[-1, 1, MP, []], # 22-P5/32
[-1, 1, Conv, [256, 1, 1, None, 1, nn.LeakyReLU(0.1)]], # --------------ELAN Backbone-4
[-2, 1, Conv, [256, 1, 1, None, 1, nn.LeakyReLU(0.1)]],
[-1, 1, Conv, [256, 3, 1, None, 1, nn.LeakyReLU(0.1)]],
[-1, 1, Conv, [256, 3, 1, None, 1, nn.LeakyReLU(0.1)]],
[[-1, -2, -3, -4], 1, Concat, [1]],
[-1, 1, Conv, [512, 1, 1, None, 1, nn.LeakyReLU(0.1)]], # 28 ----------ELAN Backbone-4 end
]
# yolov7-tiny head
head:
[[-1, 1, Conv, [256, 1, 1, None, 1, nn.LeakyReLU(0.1)]], # ---------------------SPP
[-2, 1, Conv, [256, 1, 1, None, 1, nn.LeakyReLU(0.1)]],
[-1, 1, SP, [5]],
[-2, 1, SP, [9]],
[-3, 1, SP, [13]],
[[-1, -2, -3, -4], 1, Concat, [1]],
[-1, 1, Conv, [256, 1, 1, None, 1, nn.LeakyReLU(0.1)]],
[[-1, -7], 1, Concat, [1]],
[-1, 1, Conv, [256, 1, 1, None, 1, nn.LeakyReLU(0.1)]], # 37 -----------------SPP end
[-1, 1, Conv, [128, 1, 1, None, 1, nn.LeakyReLU(0.1)]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[21, 1, Conv, [128, 1, 1, None, 1, nn.LeakyReLU(0.1)]], # route backbone P4
[[-1, -2], 1, Concat, [1]],
[-1, 1, Conv, [64, 1, 1, None, 1, nn.LeakyReLU(0.1)]], # ----------------------ELAN FPN
[-2, 1, Conv, [64, 1, 1, None, 1, nn.LeakyReLU(0.1)]],
[-1, 1, Conv, [64, 3, 1, None, 1, nn.LeakyReLU(0.1)]],
[-1, 1, Conv, [64, 3, 1, None, 1, nn.LeakyReLU(0.1)]],
[[-1, -2, -3, -4], 1, Concat, [1]],
[-1, 1, Conv, [128, 1, 1, None, 1, nn.LeakyReLU(0.1)]], # 47 -----------------ELAN FPN end
[-1, 1, Conv, [64, 1, 1, None, 1, nn.LeakyReLU(0.1)]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[14, 1, Conv, [64, 1, 1, None, 1, nn.LeakyReLU(0.1)]], # route backbone P3
[[-1, -2], 1, Concat, [1]], # ---------------------------FPN end---------------
[-1, 1, Conv, [32, 1, 1, None, 1, nn.LeakyReLU(0.1)]], # ---------------------ELAN PAN-1
[-2, 1, Conv, [32, 1, 1, None, 1, nn.LeakyReLU(0.1)]],
[-1, 1, Conv, [32, 3, 1, None, 1, nn.LeakyReLU(0.1)]],
[-1, 1, Conv, [32, 3, 1, None, 1, nn.LeakyReLU(0.1)]],
[[-1, -2, -3, -4], 1, Concat, [1]],
[-1, 1, Conv, [64, 1, 1, None, 1, nn.LeakyReLU(0.1)]], # 57 -----------------ELAN PAN-1 end
[-1, 1, SPDConv, [128]],
[[-1, 47], 1, Concat, [1]],
[-1, 1, Conv, [64, 1, 1, None, 1, nn.LeakyReLU(0.1)]], # ---------------------ELAN PAN-2
[-2, 1, Conv, [64, 1, 1, None, 1, nn.LeakyReLU(0.1)]],
[-1, 1, Conv, [64, 3, 1, None, 1, nn.LeakyReLU(0.1)]],
[-1, 1, Conv, [64, 3, 1, None, 1, nn.LeakyReLU(0.1)]],
[[-1, -2, -3, -4], 1, Concat, [1]],
[-1, 1, Conv, [128, 1, 1, None, 1, nn.LeakyReLU(0.1)]], # 65 -----------------ELAN PAN-2 end
[-1, 1, SPDConv, [256]],
[[-1, 37], 1, Concat, [1]],
[-1, 1, Conv, [128, 1, 1, None, 1, nn.LeakyReLU(0.1)]], # ---------------------ELAN PAN-3
[-2, 1, Conv, [128, 1, 1, None, 1, nn.LeakyReLU(0.1)]],
[-1, 1, Conv, [128, 3, 1, None, 1, nn.LeakyReLU(0.1)]],
[-1, 1, Conv, [128, 3, 1, None, 1, nn.LeakyReLU(0.1)]],
[[-1, -2, -3, -4], 1, Concat, [1]],
[-1, 1, Conv, [256, 1, 1, None, 1, nn.LeakyReLU(0.1)]], # 73 -----------------ELAN PAN-3 end
[57, 1, Conv, [128, 3, 1, None, 1, nn.LeakyReLU(0.1)]],
[65, 1, Conv, [256, 3, 1, None, 1, nn.LeakyReLU(0.1)]],
[73, 1, Conv, [512, 3, 1, None, 1, nn.LeakyReLU(0.1)]],
[[74,75,76], 1, IDetect, [nc, anchors]], # Detect(P3, P4, P5)
]
| 参数量/M | 计算量/GFLOPs | |
|---|---|---|
| YOLOv7-tiny | 6.23 | 13.9 |
| YOLOv7-tiny-SPDConv | 7.39(+1.16) | 18.6(+4.7) |
4 一些疑问
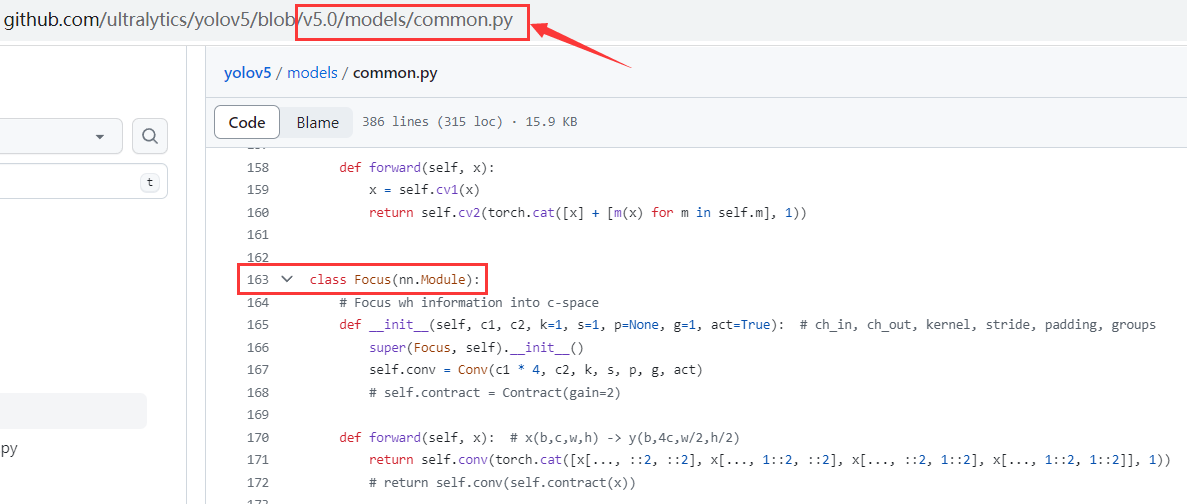
4.1 整体思想,跟YOLOv5 v5.0版本里的Focus一摸一样哇
- 采用的同样的cat拼接内容
- 并且顺序也是spd->Conv
4.2 为什么论文和代码不一致?
论文里面:先spd,再Conv(可见本文的1 摘要)
代码里面:先Conv,再spd(可见本文的3.2 SPDConv源码中是怎么使用spd的呢?)