一、LiteOS同步实验(实现生产者-消费者问题)
效果如下图:
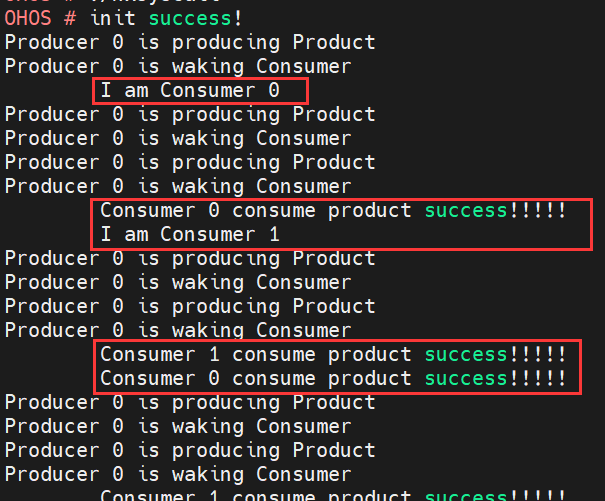
给大家解释一下上述效果:在左侧(顶格)的是生产者(Producer);在右侧(空格)的是消费者(Consumer)。生产者有1个,代号为“0”;消费者有2个,代号分别为“0”和“1”。
生产者首先生产出一个产品,输出“is producing Product”。然后唤醒消费者来消费,输出“is waking Consumer”。
消费者生成时会报告自己的信息,比如“I am Consumer 0”代表它是0号消费者。如果有东西可以消费,它会输出“Consumer 代号 consume product success!!!!”代表消费成功。
程序实现的效果是:生产者不断生产“产品”,然后消费者“0”和“1”不断进行消费,如此循环往复。
一、代码剖析
代码逻辑如下,很清晰:
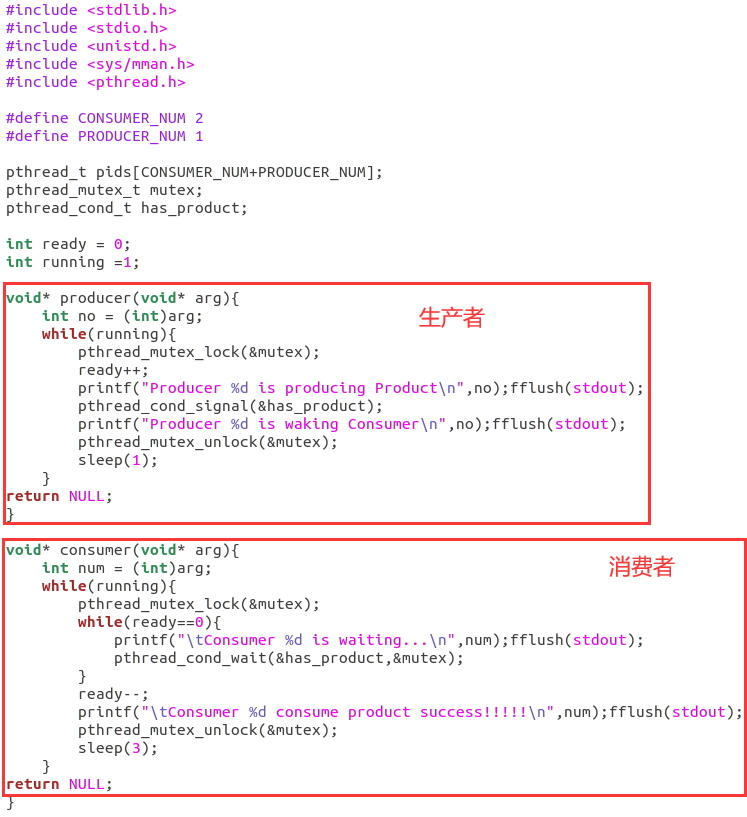

入口函数代码逻辑:
从HxSyscall进入,调用pthread_mutex_init初始化互斥锁mutex(是一个pthread_mutex_t结构体),调用pthread_cond_init初始化条件变量has_product(是一个pthread_cond_t结构体)。
紧接着定义了一个thread_ids数组,该数组用于存储生产者和消费者的编号。

然后先调用pthread_create函数生成生产者,在这里解释一下4个传入参数各自的含义:
第1个参数是一个指向pthread_t类型变量的指针,用于存储新创建的线程,简言之就是新创建的线程会存放在该变量里。
第2个参数是一个指向pthread_attr_t类型变量的指针,用于指定新线程的属性,这里是NULL,说明用的是默认属性。
第3个参数:是一个指向函数的指针,该函数就是新线程的入口点。可以这么理解:这里传入什么函数名就去调用哪个函数。比如在这里我们将生产者producer的函数名传入,就会去执行producer函数。
第4个参数:一个指向void类型的指针,用于传递给新线程入口点函数的参数。可以这么理解:这里传入的值就是要调用函数的参数,比如我们调用producer函数需要传入了一个参数arg,这里的这第4个参数就是这个参数arg。
大家需要注意一点:如果需要在线程执行时输出语句printf(),一定要在printf()后加上fflush(stdout);这条语句,因为当我们使用printf等输出函数打印文本时,并不会立即将其发送到屏幕上,而是先存储在输出缓冲区中,而fflush(stdout)这条语句可以刷新输出缓冲区,将缓冲区内容输出到屏幕上。
最后说一下pthread_join函数的是用于阻塞调用线程,直到指定的线程结束执行,实现线程的同步,确保调用线程等待指定线程的完成。在入口函数中执行该操作,会等待所有线程都执行完之后再继续执行。简而言之就是要避免:某些线程还在运行,却意外销毁了该些线程所需的资源,导致出错的情况发生。

补充:
1.互斥锁(Mutex)的作用是保护共享资源,确保同一时间只有一个线程可以访问共享资源。
2.条件变量(Condition Variable)的作用是实现线程间的协调和通信。条件变量允许一个线程等待某个条件的发生,并在条件满足时被唤醒。
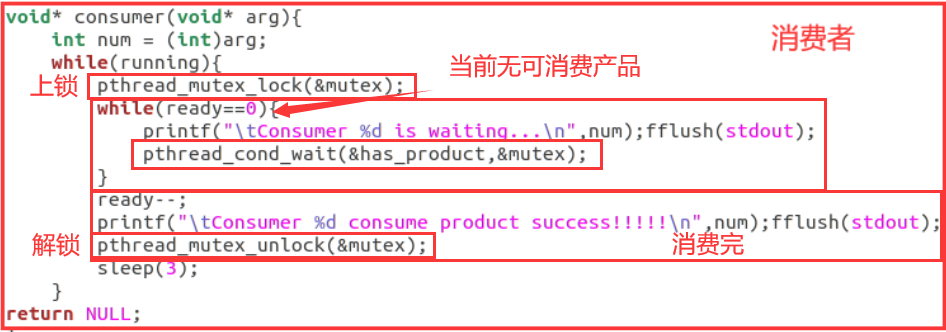
消费者函数逻辑:
用pthread_mutex_lock来上互斥锁,pthread_mutex_unlock来解除互斥锁,在此不过多赘述。
当ready==0时说明此时消费者生产的东西都被消费完了,或者还没来得及生产,因此用while循环来忙等待。
pthread_cond_wait函数的作用是使线程等待某个条件的发生,一旦条件满足(收到信号),线程将被唤醒并继续执行。在这里等待的是has_product变量。
当ready>0时,令ready-1表示消费掉1个产品,然后休眠3秒
生产者函数逻辑:
用pthread_mutex_lock来上互斥锁,pthread_mutex_unlock来解除互斥锁,在此不过多赘述。
pthread_cond_signal用于向线程发送信号,告诉它们条件已经满足,你可以执行啦!与消费者中的pthread_cond_wait函数相呼应。

二、可运行代码
代码如下可直接复制:
#include <stdlib.h>
#include <stdio.h>
#include <unistd.h>
#include <sys/mman.h>
#include <pthread.h>
#define CONSUMER_NUM 2
#define PRODUCER_NUM 1
pthread_t pids[CONSUMER_NUM+PRODUCER_NUM];
int ready = 0;
int running =1;
pthread_mutex_t mutex;
pthread_cond_t has_product;
void* producer(void* arg){
int no = (int)arg;
while(running){
pthread_mutex_lock(&mutex);
ready++;
printf("Producer %d is producing Product\n",no);fflush(stdout);
pthread_cond_signal(&has_product);
printf("Producer %d is waking Consumer\n",no);fflush(stdout);
pthread_mutex_unlock(&mutex);
sleep(1);
}
return NULL;
}
void* consumer(void* arg){
int num = (int)arg;
while(running){
pthread_mutex_lock(&mutex);
while(ready==0){
printf("\tConsumer %d is waiting...\n",num);fflush(stdout);
pthread_cond_wait(&has_product,&mutex);
}
ready--;
printf("\tConsumer %d consume product success!!!!!\n",num);fflush(stdout);
pthread_mutex_unlock(&mutex);
sleep(3);
}
return NULL;
}
void HxSyscall(int num){
pthread_mutex_init(&mutex,NULL);
pthread_cond_init(&has_product,NULL);
printf("init success!\n");
int i;
int thread_ids[CONSUMER_NUM + PRODUCER_NUM];
for(i=0; i<PRODUCER_NUM; i++){
thread_ids[i] = i;
pthread_create(&pids[i], NULL, producer, (void*)i);
}
for(i=0; i<CONSUMER_NUM; i++){
printf("\tI am Consumer %d \n",i);fflush(stdout);
sleep(2);
thread_ids[PRODUCER_NUM + i] = i;
pthread_create(&pids[PRODUCER_NUM + i], NULL, consumer, (void*)i);
}
for(i=0; i<PRODUCER_NUM + CONSUMER_NUM; i++){
pthread_join(pids[i], NULL);
}
pthread_mutex_destroy(&mutex);
pthread_cond_destroy(&has_product);
return;
}大家只需要按照project1的方式,将上述代码放入home/openharmony/kernel/liteos_a/syscall下的hx_syscall.c文件夹下(这里为了方便基础较薄弱的同学操作,所以我们仍旧采用勖哥在pro1中的函数命名),接下来大家只需要按照pro1的方法进行编译烧录即可运行。
效果如下:
生成了1个生产者,2个消费者,生产者不断生产,消费者不断消费,实现了生产者-消费者功能。
【如果觉得有帮助记得点赞+收藏⭐】
三、源码展示
如有需要的同学可以自取,在此不过多赘述分析了,按照使用顺序排列:
pthread_mutex_lock(&mutex);
pthread_mutex_destroy(&mutex);
pthread_mutex_unlock(&mutex);
pthread_mutex_init(&mutex,NULL);
pthread_cond_signal(&has_product);
pthread_cond_wait(&has_product,&mutex);
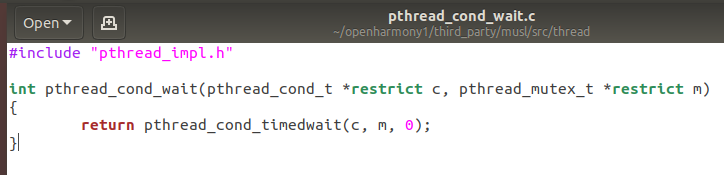
pthread_cond_init(&has_product,NULL);
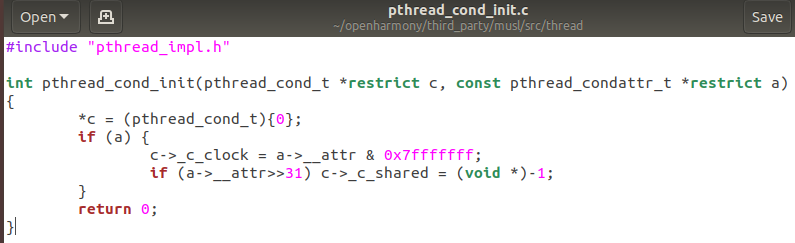
pthread_cond_destroy(&has_product);
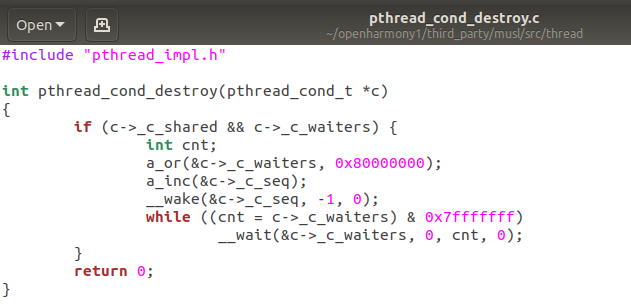
pthread_join(pids[i],NULL);
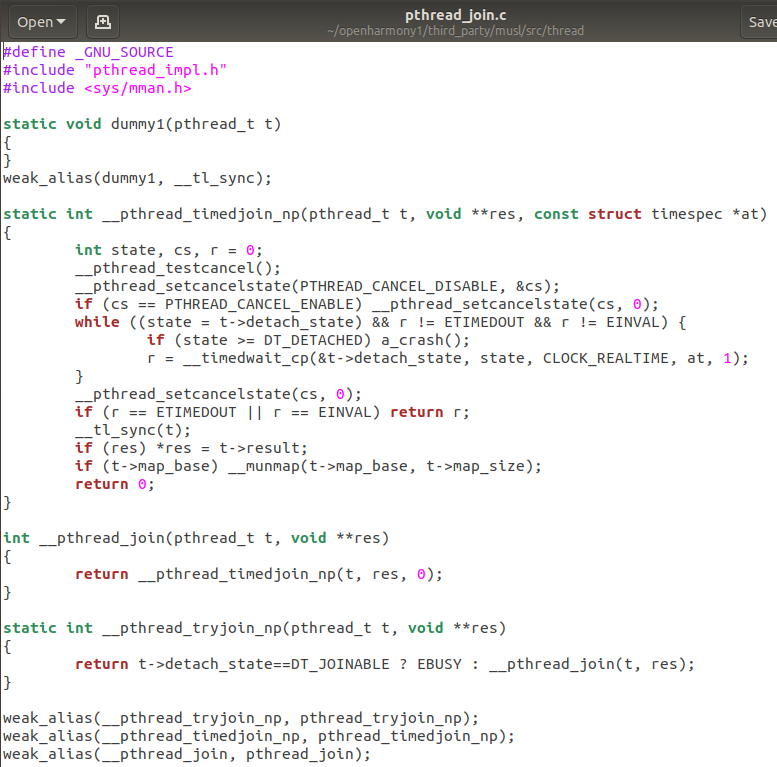
pthread_create(&pids[i],NULL,producer,(void*)i);
#define _GNU_SOURCE
#include "pthread_impl.h"
#include "stdio_impl.h"
#include "libc.h"
#include "lock.h"
#include <sys/mman.h>
#include <string.h>
#include <stddef.h>
static void dummy_0()
{
}
weak_alias(dummy_0, __acquire_ptc);
weak_alias(dummy_0, __release_ptc);
weak_alias(dummy_0, __pthread_tsd_run_dtors);
weak_alias(dummy_0, __do_orphaned_stdio_locks);
weak_alias(dummy_0, __dl_thread_cleanup);
static int tl_lock_count;
static int tl_lock_waiters;
void __tl_lock(void)
{
int tid = __pthread_self()->tid;
int val = __thread_list_lock;
if (val == tid) {
tl_lock_count++;
return;
}
while ((val = a_cas(&__thread_list_lock, 0, tid)))
__wait(&__thread_list_lock, &tl_lock_waiters, val, 0);
}
void __tl_unlock(void)
{
if (tl_lock_count) {
tl_lock_count--;
return;
}
a_store(&__thread_list_lock, 0);
if (tl_lock_waiters) __wake(&__thread_list_lock, 1, 0);
}
void __tl_sync(pthread_t td)
{
a_barrier();
int val = __thread_list_lock;
if (!val) return;
__wait(&__thread_list_lock, &tl_lock_waiters, val, 0);
if (tl_lock_waiters) __wake(&__thread_list_lock, 1, 0);
}
_Noreturn void __pthread_exit(void *result)
{
pthread_t self = __pthread_self();
sigset_t set;
self->canceldisable = 1;
self->cancelasync = 0;
self->result = result;
while (self->cancelbuf) {
void (*f)(void *) = self->cancelbuf->__f;
void *x = self->cancelbuf->__x;
self->cancelbuf = self->cancelbuf->__next;
f(x);
}
__pthread_tsd_run_dtors();
/* Access to target the exiting thread with syscalls that use
* its kernel tid is controlled by killlock. For detached threads,
* any use past this point would have undefined behavior, but for
* joinable threads it's a valid usage that must be handled. */
LOCK(self->killlock);
/* The thread list lock must be AS-safe, and thus requires
* application signals to be blocked before it can be taken. */
__block_app_sigs(&set);
__tl_lock();
/* If this is the only thread in the list, don't proceed with
* termination of the thread, but restore the previous lock and
* signal state to prepare for exit to call atexit handlers. */
if (self->next == self) {
__tl_unlock();
__restore_sigs(&set);
UNLOCK(self->killlock);
exit(0);
}
/* At this point we are committed to thread termination. Unlink
* the thread from the list. This change will not be visible
* until the lock is released, which only happens after SYS_exit
* has been called, via the exit futex address pointing at the lock. */
libc.threads_minus_1--;
self->next->prev = self->prev;
self->prev->next = self->next;
self->prev = self->next = self;
/* Process robust list in userspace to handle non-pshared mutexes
* and the detached thread case where the robust list head will
* be invalid when the kernel would process it. */
#if 0
__vm_lock();
volatile void *volatile *rp;
while ((rp=self->robust_list.head) && rp != &self->robust_list.head) {
pthread_mutex_t *m = (void *)((char *)rp
- offsetof(pthread_mutex_t, _m_next));
int waiters = m->_m_waiters;
int priv = (m->_m_type & 128) ^ 128;
self->robust_list.pending = rp;
self->robust_list.head = *rp;
int cont = a_swap(&m->_m_lock, 0x40000000);
self->robust_list.pending = 0;
if (cont < 0 || waiters)
__wake(&m->_m_lock, 1, priv);
}
__vm_unlock();
#endif
__do_orphaned_stdio_locks();
__dl_thread_cleanup();
/* This atomic potentially competes with a concurrent pthread_detach
* call; the loser is responsible for freeing thread resources. */
int state = a_cas(&self->detach_state, DT_JOINABLE, DT_EXITING);
#if 0
if (state==DT_DETACHED && self->map_base) {
/* Robust list will no longer be valid, and was already
* processed above, so unregister it with the kernel. */
if (self->robust_list.off)
__syscall(SYS_set_robust_list, 0, 3*sizeof(long));
/* Since __unmapself bypasses the normal munmap code path,
* explicitly wait for vmlock holders first. */
__vm_wait();
/* The following call unmaps the thread's stack mapping
* and then exits without touching the stack. */
__unmapself(self->map_base, self->map_size);
}
/* Wake any joiner. */
__wake(&self->detach_state, 1, 1);
#endif
/* After the kernel thread exits, its tid may be reused. Clear it
* to prevent inadvertent use and inform functions that would use
* it that it's no longer available. */
if (self->detach_state == DT_DETACHED) {
/* Detached threads must block even implementation-internal
* signals, since they will not have a stack in their last
* moments of existence. */
__block_all_sigs(&set);
self->tid = 0;
}
__tl_unlock();
UNLOCK(self->killlock);
for (;;) __syscall(SYS_exit, 0);
}
void __do_cleanup_push(struct __ptcb *cb)
{
struct pthread *self = __pthread_self();
cb->__next = self->cancelbuf;
self->cancelbuf = cb;
}
void __do_cleanup_pop(struct __ptcb *cb)
{
__pthread_self()->cancelbuf = cb->__next;
}
struct start_args {
void *(*start_func)(void *);
void *start_arg;
volatile int control;
unsigned long sig_mask[_NSIG/8/sizeof(long)];
};
static int start(void *p)
{
struct start_args *args = (struct start_args *)p;
__syscall(SYS_rt_sigprocmask, SIG_SETMASK, &args->sig_mask, 0, _NSIG/8);
__pthread_exit(args->start_func(args->start_arg));
return 0;
}
static int start_c11(void *p)
{
struct start_args *args = (struct start_args *)p;
int (*start)(void*) = (int(*)(void*)) args->start_func;
__pthread_exit((void *)(uintptr_t)start(args->start_arg));
return 0;
}
#define ROUND(x) (((x)+PAGE_SIZE-1)&-PAGE_SIZE)
/* pthread_key_create.c overrides this */
static volatile size_t dummy = 0;
weak_alias(dummy, __pthread_tsd_size);
static void *dummy_tsd[1] = { 0 };
weak_alias(dummy_tsd, __pthread_tsd_main);
int __pthread_init_and_check_attr(const pthread_attr_t *restrict attrp, pthread_attr_t *attr)
{
int policy = 0;
struct sched_param param = { 0 };
int c11 = (attrp == __ATTRP_C11_THREAD);
int ret;
if (attrp && !c11) memcpy(attr, attrp, sizeof(pthread_attr_t));
if (!attrp || c11) {
pthread_attr_init(attr);
}
if (!attr->_a_sched) {
ret = pthread_getschedparam(pthread_self(), &policy, ¶m);
if (ret) return ret;
attr->_a_policy = policy;
attr->_a_prio = param.sched_priority;
}
if (attr->_a_policy != SCHED_RR && attr->_a_policy != SCHED_FIFO) {
return EINVAL;
}
if (attr->_a_prio < 0 || attr->_a_prio > PTHREAD_PRIORITY_LOWEST) {
return EINVAL;
}
return 0;
}
int __pthread_create(pthread_t *restrict res, const pthread_attr_t *restrict attrp, void *(*entry)(void *), void *restrict arg)
{
int ret, c11 = (attrp == __ATTRP_C11_THREAD);
size_t size, guard;
struct pthread *self, *new;
unsigned char *map = 0, *stack = 0, *tsd = 0, *stack_limit;
unsigned flags = CLONE_VM | CLONE_FS | CLONE_FILES | CLONE_SIGHAND
| CLONE_THREAD | CLONE_SYSVSEM | CLONE_SETTLS
| CLONE_PARENT_SETTID | CLONE_CHILD_CLEARTID | CLONE_DETACHED;
pthread_attr_t attr = { 0 };
sigset_t set;
if (!libc.can_do_threads) return ENOSYS;
if (!entry) return EINVAL;
self = __pthread_self();
__acquire_ptc();
ret = __pthread_init_and_check_attr(attrp, &attr);
if (ret) {
__release_ptc();
return ret;
}
if (attr._a_stackaddr) {
size_t need = libc.tls_size + __pthread_tsd_size;
size = attr._a_stacksize;
stack = (void *)(attr._a_stackaddr & -16);
stack_limit = (void *)(attr._a_stackaddr - size);
/* Use application-provided stack for TLS only when
* it does not take more than ~12% or 2k of the
* application's stack space. */
if (need < size/8 && need < 2048) {
tsd = stack - __pthread_tsd_size;
stack = tsd - libc.tls_size;
memset(stack, 0, need);
} else {
size = ROUND(need);
}
guard = 0;
} else {
guard = ROUND(attr._a_guardsize);
size = guard + ROUND(attr._a_stacksize
+ libc.tls_size + __pthread_tsd_size);
}
if (!tsd) {
if (guard) {
map = __mmap(0, size, PROT_READ|PROT_WRITE|PROT_NONE, MAP_PRIVATE|MAP_ANON, -1, 0);
if (map == MAP_FAILED) goto fail;
if (__mprotect(map+guard, size-guard, PROT_READ|PROT_WRITE)
&& errno != ENOSYS) {
__munmap(map, size);
goto fail;
}
} else {
map = __mmap(0, size, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANON, -1, 0);
if (map == MAP_FAILED) goto fail;
}
tsd = map + size - __pthread_tsd_size;
if (!stack) {
stack = tsd - libc.tls_size;
stack_limit = map + guard;
}
}
new = __copy_tls(tsd - libc.tls_size);
new->map_base = map;
new->map_size = size;
new->stack = stack;
new->stack_size = stack - stack_limit;
new->guard_size = guard;
new->self = new;
new->tsd = (void *)tsd;
new->locale = &libc.global_locale;
if (attr._a_detach) {
new->detach_state = DT_DETACHED;
} else {
new->detach_state = DT_JOINABLE;
}
new->robust_list.head = &new->robust_list.head;
new->CANARY = self->CANARY;
new->sysinfo = self->sysinfo;
/* Setup argument structure for the new thread on its stack.
* It's safe to access from the caller only until the thread
* list is unlocked. */
stack -= (uintptr_t)stack % sizeof(uintptr_t);
stack -= sizeof(struct start_args);
struct start_args *args = (void *)stack;
args->start_func = entry;
args->start_arg = arg;
args->control = attr._a_sched ? 1 : 0;
/* Application signals (but not the synccall signal) must be
* blocked before the thread list lock can be taken, to ensure
* that the lock is AS-safe. */
__block_app_sigs(&set);
/* Ensure SIGCANCEL is unblocked in new thread. This requires
* working with a copy of the set so we can restore the
* original mask in the calling thread. */
memcpy(&args->sig_mask, &set, sizeof args->sig_mask);
args->sig_mask[(SIGCANCEL-1)/8/sizeof(long)] &=
~(1UL<<((SIGCANCEL-1)%(8*sizeof(long))));
__tl_lock();
libc.threads_minus_1++;
ret = __thread_clone((c11 ? start_c11 : start), flags, new, stack);
/* All clone failures translate to EAGAIN. If explicit scheduling
* was requested, attempt it before unlocking the thread list so
* that the failed thread is never exposed and so that we can
* clean up all transient resource usage before returning. */
if (ret < 0) {
ret = -EAGAIN;
} else {
new->next = self->next;
new->prev = self;
new->next->prev = new;
new->prev->next = new;
*res = new;
__tl_unlock();
__restore_sigs(&set);
__release_ptc();
ret = __syscall(SYS_sched_setscheduler,
new->tid, attr._a_policy, attr._a_prio, MUSL_TYPE_THREAD);
}
if (ret < 0) {
libc.threads_minus_1--;
__tl_unlock();
__restore_sigs(&set);
__release_ptc();
if (map) __munmap(map, size);
return -ret;
}
return 0;
fail:
__release_ptc();
return EAGAIN;
}
weak_alias(__pthread_exit, pthread_exit);
weak_alias(__pthread_create, pthread_create);二、改进LiteOS中物理内存分配算法
一、实验要求
优化TLSF算法,将Best-fit策略优化为Good-fit策略,进一步降低时间复杂度至O(1)。
优化思路:
1.初始化时预先为每个索引中的内存块挂上若干空闲块,在实际分配时避免分割(split)操作,加速分配过程;
2.定位到比当前所需空间更大一级的内存块进行空闲块分配,避免因遍历链表寻找合适大小的空闲块所导致的时间浪费。
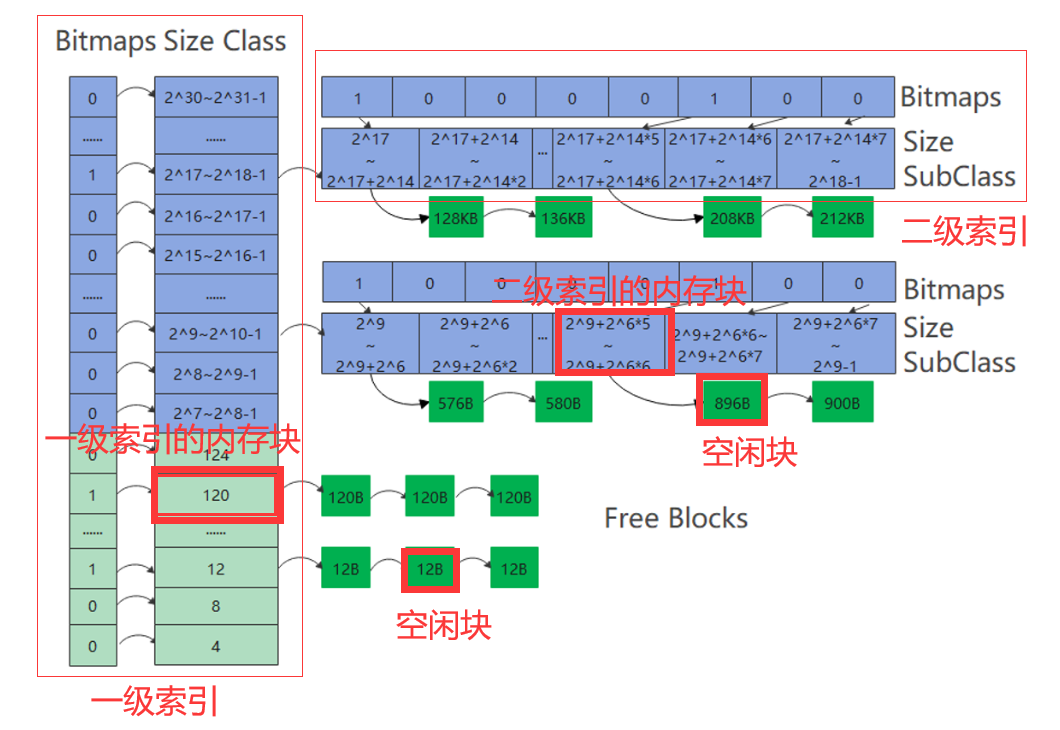
为了严谨起见,先规范一下术语(注意概念的大小:索引>内存块>空闲块。绿色是小桶,紫色是大桶):
二、实验准备
第1步:下载带有TLSF算法的源码
在这里下载OpenHarmony 1.1.0 LTS,实测内部含有内存两级分割策略算法(TLSF算法)的代码实现,repo地址如下:
repo init -u https://gitee.com/openharmony/manifest.git -b refs/tags/OpenHarmony_release_v1.1.0 --no-repo-verify
原本的想法是要编写一个程序来验证新内存分配算法的正确性,但由于补丁只能打1.0版本,而这个是1.1版本,抱有侥幸心理试试补丁能不能打1.x版本,于是下载了这个版本,事实证明补丁依旧不能打上..
在openharmony/kernel/liteos_a/kernel/base/mem下有一个tlsf文件夹,这个文件夹里存储的正是tlsf算法的实现:
进入到tlsf文件夹下的los_memory.c文件中。
第2步:查看结构体
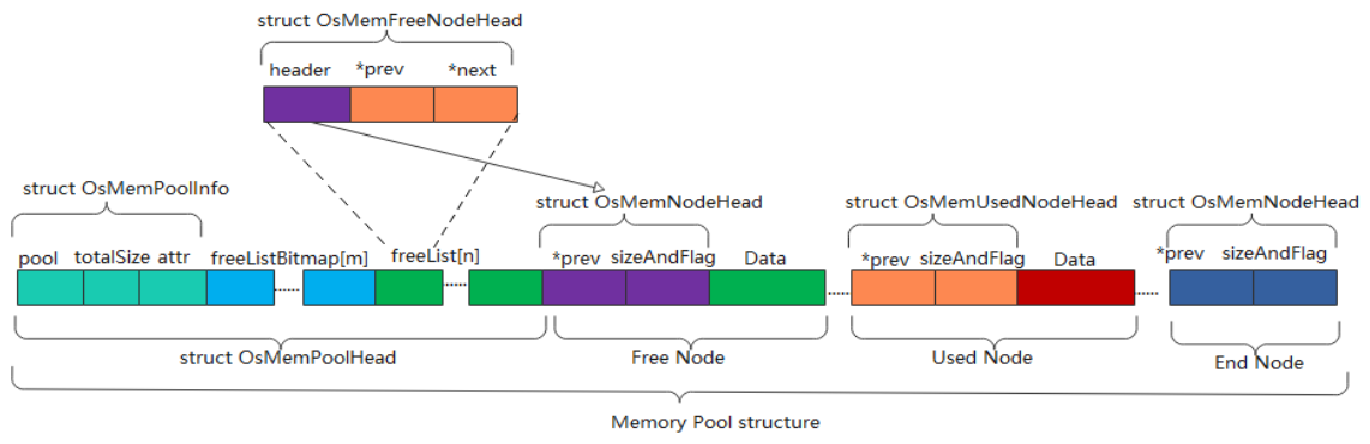
图中的结构体如下:
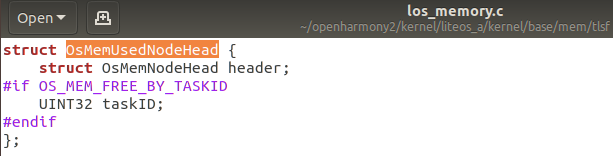
OsMemPoolInfo
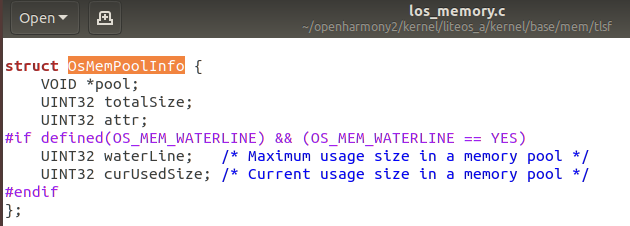
OsMemFreeNodeHead
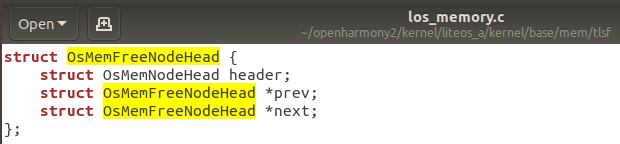
OsMemNodeHead
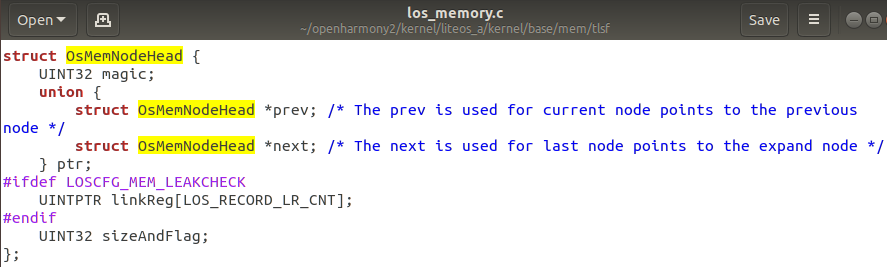
OsMemUsedNodeHead
第3步:检查常用宏
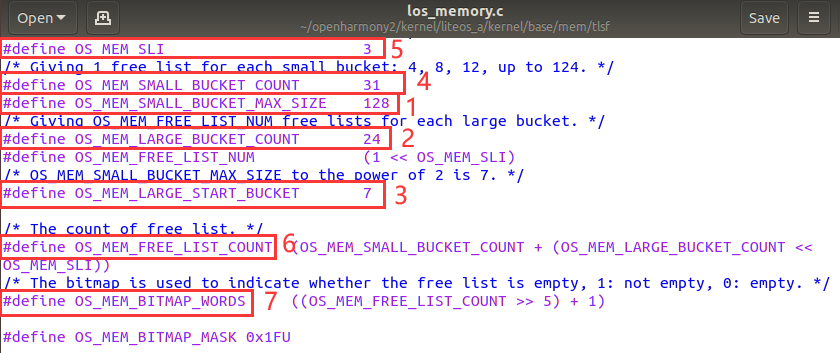
宏的含义可参考ppt。
第4步:理解TLSF算法
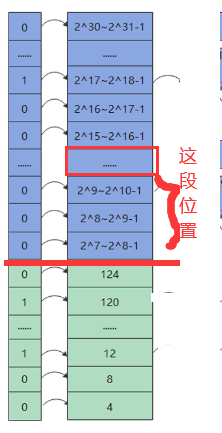
TLSF算法采用的是两级索引。右边的是第一级索引,将空间按2的指数大小(,
,
...)进行分块。其内部的内存块是否空闲用位图(一维数组)进行标识,1表示块内有剩余空间,0表示块内已经被挤得满满的。

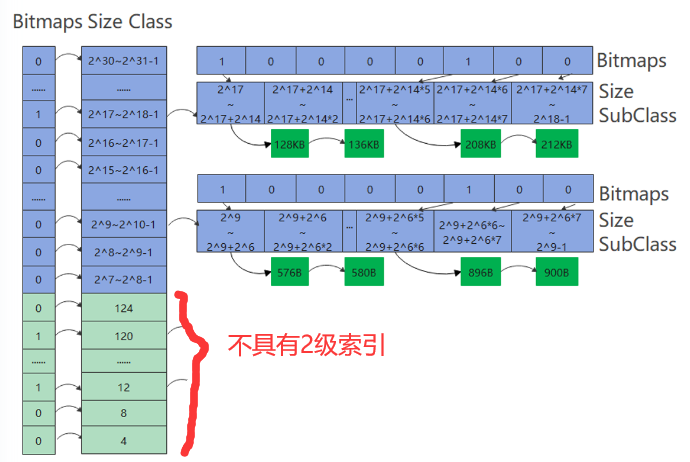
中间的是第二级索引,二级索引在一级索引分块的基础上,进一步进行分块,如图中将一级索引中的每块进一步分成了8块(例如32-63这段被分为了32-35,36-39,40-43,44-47,48-51,52-55,56-59,60-63,每块长度是4)。用位图(二维数组)标识是否存在空闲内存块。有空闲的块标记为1,没有空闲的块标记为0。
左边的是空闲块,空闲块的大小是一个确定的值,该值要在二级索引的区间范围之内。
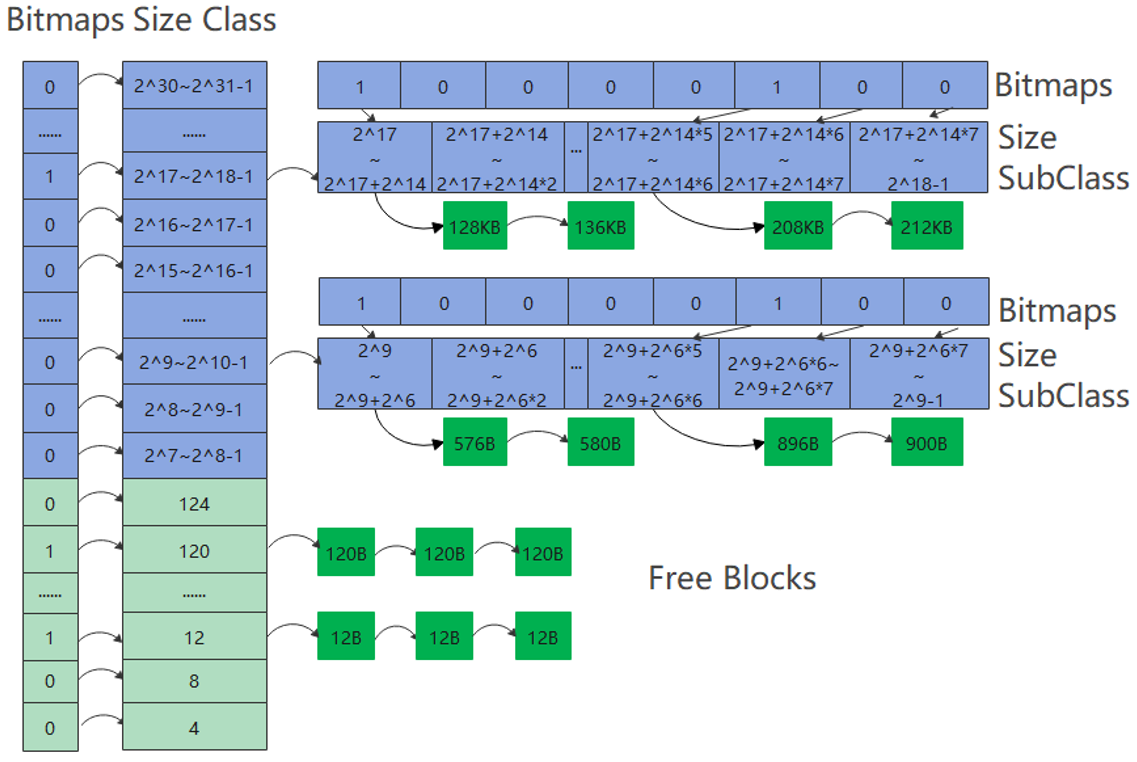
上图告诉我们鸿蒙系统将内存块大小分为两个部分:~
和
~
。
在4~127区间上是小桶申请,可以这么理解:在4~127区间上有31个桶(4,8,12,...,124),每个桶的大小代表了所能挂的空闲块的大小(比如12代表只能挂12B大小的空闲块,120代表只能挂120B大小的空闲块),没有二级索引。
大于127的是大桶申请,可以这么理解一共有24个大桶(~
,
~
,... ,
~
),这里的大桶代表了一级索引;然后每个大桶里又有8个小桶,这里的小桶代表2级索引;然后每个小桶里又可以挂若干个空闲块。
三、改进TLSF算法
事先说明:
1. 修改不保证完全正确,如有疏漏,望请指正。
2. 所修改的函数都在openharmony/kernel/liteos_a/kernel/base/mem/tlsf下的los_memory.c文件中。
3.所修改的源码是OpenHarmony 1.1.0 LTS版本,其它版本可能会有所差异。
1.定位到比当前所需空间更大一级的内存块
修改对象:OsMemFreeListIndexGet函数
改进思路:在当前内存块位置的基础上+1,指向下一块内存块的位置,需要考虑的是+1后从小桶变成大桶的情况,所以当size<124时归属于小桶,当size>=124时归属于大桶。
修改如下:

首先复制OsMemFreeListIndexGet这个函数,粘贴到原函数下面,改名为NewOsMemFreeListIndexGet,然后就不再变动NewOsMemFreeListIndexGet这个函数。
fl的值表示的是在一级索引中的位置,OS_MEM_SMALL_BUCKET_MAX_SIZE是一个宏其值为128,如果size<124,就让fl+1,相当于索引指向当前桶的上一级桶。
如果size>=124此时考虑临界状态,当size为124时再上一级桶时(+4后)会进入到大桶的范围(因为小桶的最大上界为127),所以此时会返回newFl。
newFl会进入到OsMemSlGet函数,这个函数的作用是返回某个值在二级索引中的位置(详见第四部分),所以sl的值代表了size在二级索引中的位置。
此时我们让sl+1,就相当于指向了下一个位置的二级索引,最后这里return的这一长串数很巧妙(同样详见第2部分)。
为什么要这么修改呢?原因:因为OsMemFreeListIndexGet这个函数的作用是返回要插入空闲块的内存块位置,我们为了在一般情况下默认定位到比当前所需空间更大一级的内存块进行空闲块插入,所以对OsMemFreeListIndexGet这个函数进行修改。
在特殊情况下,比如初始化时预先为每个索引挂上若干空闲块,要求12B就是为大小为12的内存块预先挂上空闲块,因此设定仍按准确的大小定位。
2.初始化时预先为每个内存块挂上若干空闲块
修改对象:OsMemPoolInit函数、OsMemFreeNodeAdd函数
修改思路:在初始化内存池的时候,同时为内存块挂上空闲块。人为给出要预先为哪些索引上的内存块挂上空闲块,空闲块的大小用sizeArray给出,然后为OsMemNodeHead结构体的变量freeNode赋值进行初始化,存储逻辑上用双向链表进行连接,索引逻辑上通过NewOsMemFreeNodeAdd函数将特定大小的空闲块挂载到索引的内存块上。
修改如下:
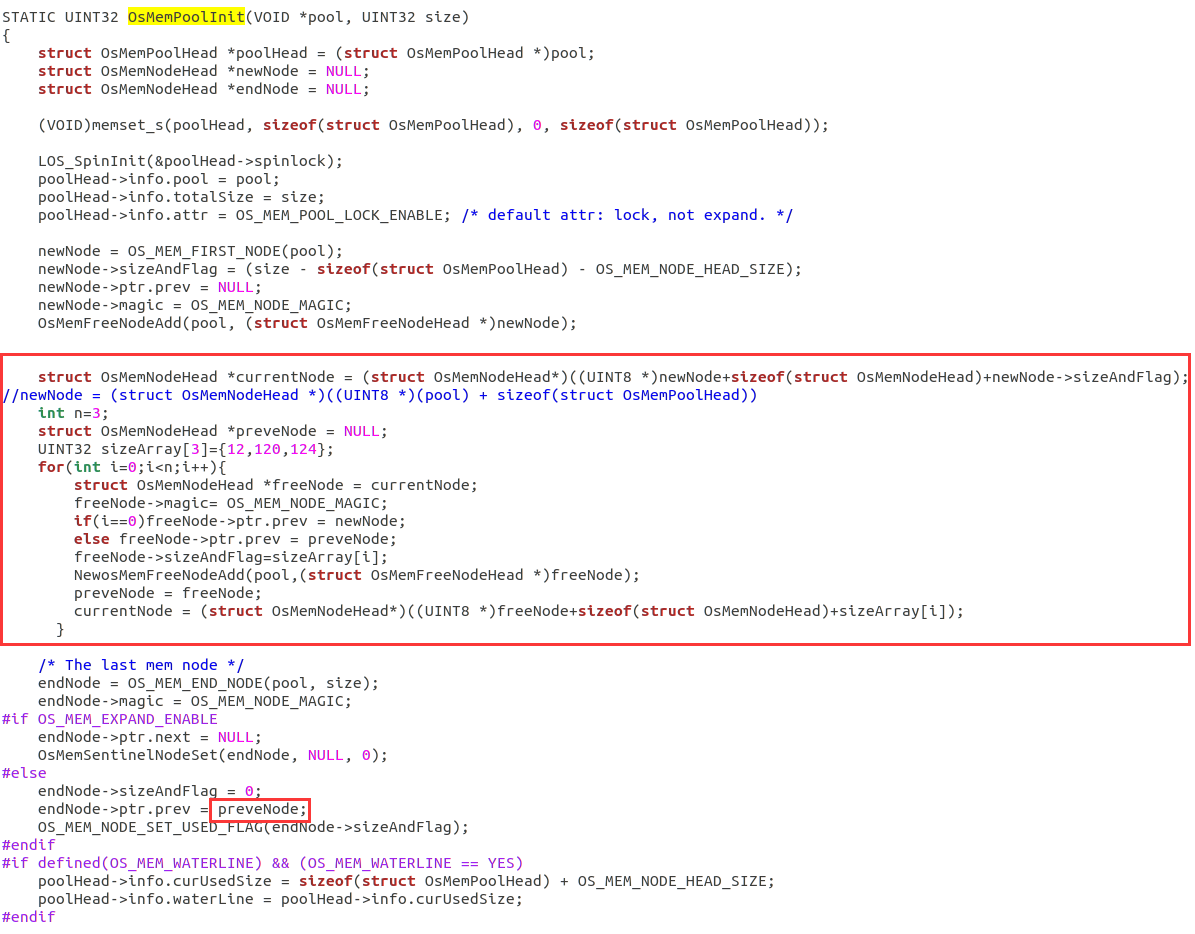
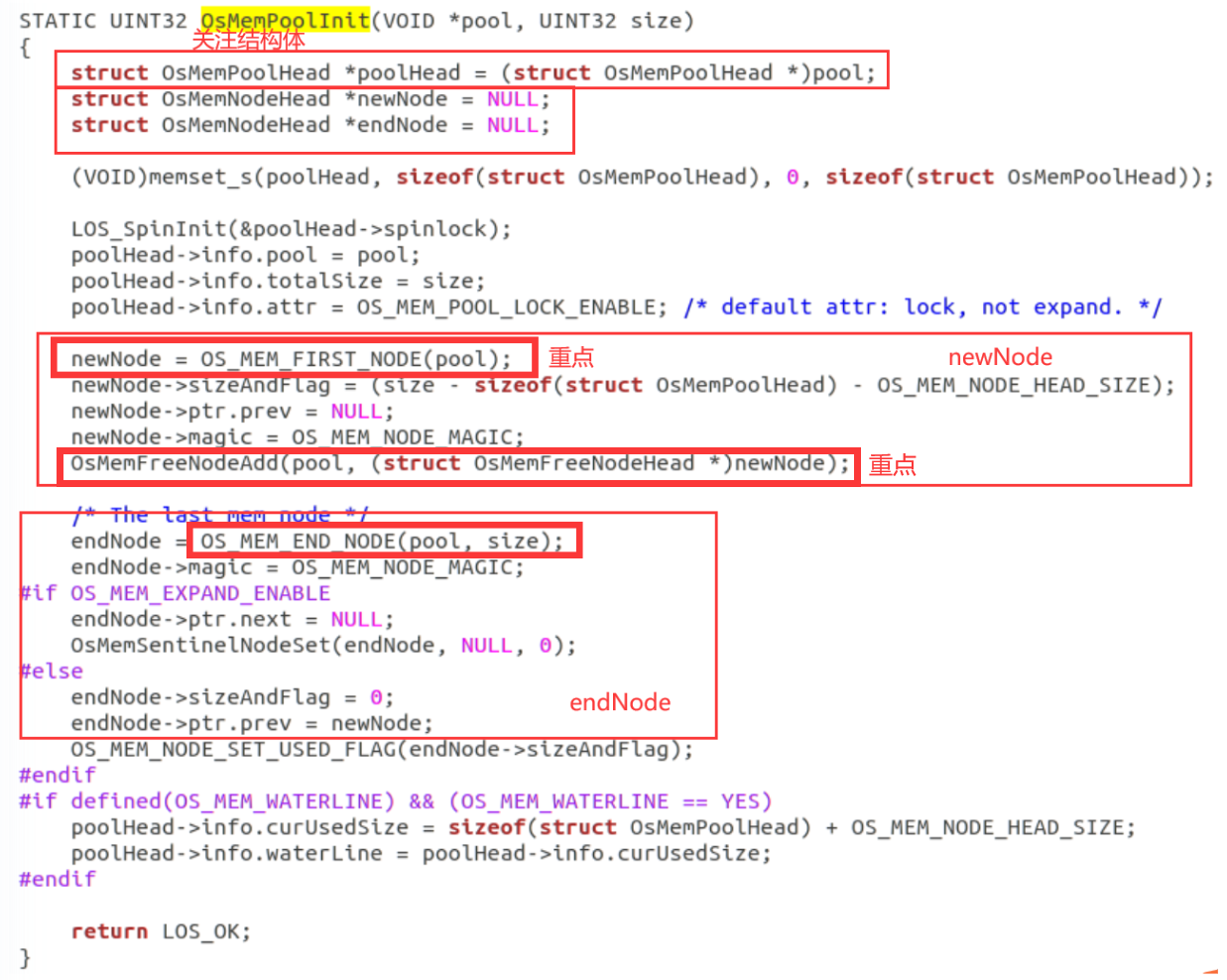
OsMemPoolInit这个函数是用于初始化内存池的,可以在该函数中预先挂上空闲块。
首先我定义了一个名为currentNode的OsMemNodeHead结构体指针,指向的是初始节点(newNode)的末尾,即后续空闲的线性空间的开头,用于顺序存储新的结构体和空闲块。
preveNode的作用是要记录前驱节点,方便后续双向链表的构建。
然后我定义了n和sizeArray这里是用于指定想要在哪个内存块上挂空闲块(比如12代表想要在大小为的内存块上挂大小为12B的空闲块),可以根据自己的需要将空闲块挂到其它内存块上,只需修改sizeArray数组内的值即可。
在for循环里主要就是给freeNode结构体内的参数赋值,freeNode指向的是前一个节点的末尾地址,即未被占用的线性空间开头的位置。
如果i==0,前驱节点要指向newNode,如果i>0此时preveNode的作用就凸显出来,freeNode(当前节点)的前驱就指向preveNode(前一个节点)。
然后调用NewOsMemFreeNodeAdd函数,这个函数主要是将结构体插入到索引的内存块当中。
preveNode = freeNode 用于前移preveNode指针指向的节点,使preveNode永远指向当前节点的前一个节点,
最后一行是令currentNode指向后续空闲空间的起始位置,方便添加新的结构体。

在OsMemPoolInit函数中调用到NewOsMemFreeNodeAdd这个函数,这个函数原名是OsMemFreeNodeAdd,只需在前面加上New即可,然后这里就和本节1中修改的NewOsMemFreeListIndexGet函数联系在一起。
四、源码解析+修改逻辑分析
1.定位到比当前所需空间更大一级的索引
首先我们分析一下OsMemFlGet这个函数,调用逻辑是:OsMemFlGet->OsMemLog2->OsMemFLS->
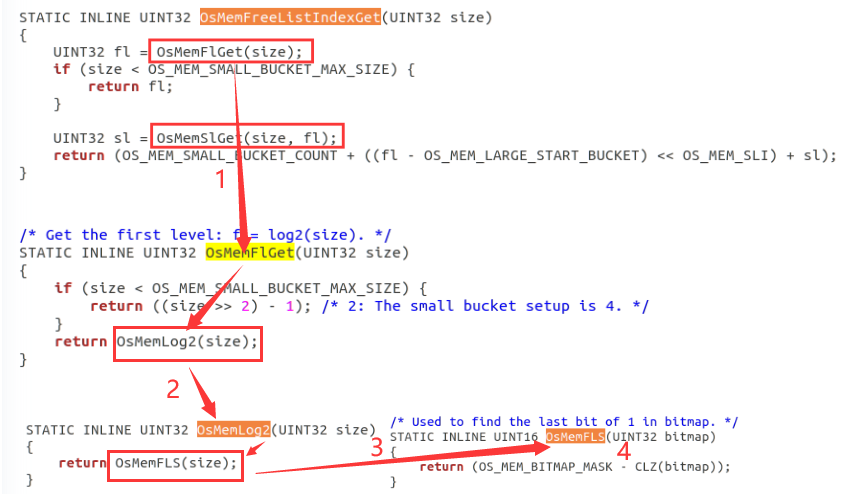
我们直接看OsMemFLS函数,OS_MEM_BITMAP_MASK是一个宏定义,代表数31(0到31共计32位,因为操作系统是32位的)。
CLZ是“Count Leading Zeros”的缩写,用于统计二进制数前导0的个数(比如一个32位的数0000010100...,前导0有5个)。
OS_MEM_BITMAP_MASK-CLZ(bitmap)是计算第1个“1”所在的位置(比如上面举例的32位数0000010100...,前导0有5个,用31-5得到的就是该数最高位的“1”所在的位置是26),这个的用处就是去定位这个数是在哪一个一级索引里(比如上面那个数最后会被放在2^26~2^27-1这个一级索引里),参考下面的图来理解:

接下来我们看OsMemSlGet函数,OS_MEM_SLI是一个宏定义值为3,OS_MEM_FREE_LIST_NUM是1<<3,即值为8。
size << OS_MEM_SLI是将size扩大8倍,(size << OS_MEM_SLI)>>fl是将乘8后的size再除以2^fl倍,这个的目的是得到二级索引的值,不至于移除低位导致精度缺失(比如对于数111000000,fl即一级索引是8,如果不乘8,此时将该数右移8位结果为1,明显不对,而乘8后右移8位结果为1110,十进制为14,此时减8,结果为6,表明该数在一级索引中是2^9~2^10-1,在二级索引中排在第6个块中)。
![]()
最后解释一下return的这段代码的含义,我首先各处各个变量代表的含义:OS_MEM_SMALL_BUCKET_COUNT=31,代表小桶一共被分为31个区间。OS_MEM_LARGE_START_BUCKET=7,2^7=128即大桶开始的位置。sl返回的是2级索引的值。fl是1级索引的值。
然后我们看表达式:fl - OS_MEM_LARGE_START_BUCKET,表达式的含义是:size所处的一级索引位置减去大桶开始的位置,如下图1:
fl - OS_MEM_LARGE_START_BUCKET) << OS_MEM_SLI,是将上图中那部分一级索引的个数乘以8,为什么要乘以8?因为每个一级索引(大桶)对应有8个二级索引块,所以是计算出二级索引块的个数。
OS_MEM_SMALL_BUCKET_COUNT + ((fl - OS_MEM_LARGE_START_BUCKET) << OS_MEM_SLI),意思是在前面二级索引块数的基础上,再加上一级索引块的数量(因为<128的一级索引属于小桶范畴不具备二级索引,如上图2,所以直接加上即可)。
OS_MEM_SMALL_BUCKET_COUNT + ((fl - OS_MEM_LARGE_START_BUCKET) << OS_MEM_SLI) + sl就是把所有的小桶+大桶的二级索引块全部加上,然后加上sl自身这个块的偏移量,就能够定位到要在哪个大桶的二级索引块上加入空闲块。
2.初始化时预先为每个索引挂上若干空闲块
首先看osmempoolinit的函数,主要要关注poolHead,newNode,endNode的结构体,这个大家自己看了。
然后要注意newNode = OS_MEM_FIRST_NODE(pool)和endNode=OS_MEM_END_NODE(pool,size)这两个函数对应的是一段计算公式,计算的是起始地址和结束地址,endNode标记的是末尾结点。
再然后要关注OsMemFreeNodeAdd这个函数,只有理清了这个函数才能真正理解是如何为每个桶挂上空闲块的。
1.分析OsMemPoolHead和OsMemNodeHead结构体
poolHead -> OsMemPoolHead
newNode、endNode -> OsMemNodeHead
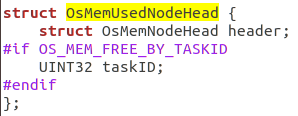
OsMemPoolHead包含了OsMemPoolInfo结构体,其中freeList表示索引列表:
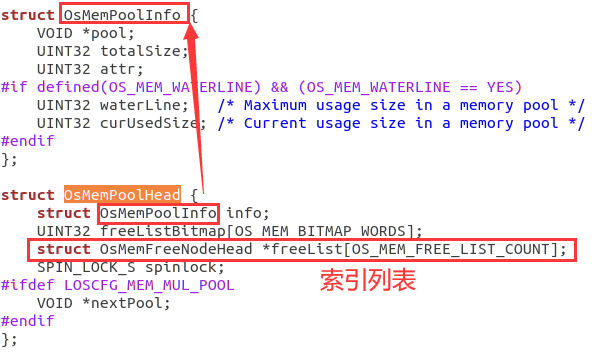
OS_MEM_FREE_LIST_COUNT=小桶(31个)+ 大桶(24个)x 8 = 223个
![]()
从这里可以看出对于小桶<128,是给每个一级索引分配一个链表,对于大桶,是给每个二级索引分配一个链表,链表可以在后续挂载空闲块。
OsMemFreeNodeHead包含了OsMemNodeHead结构体:
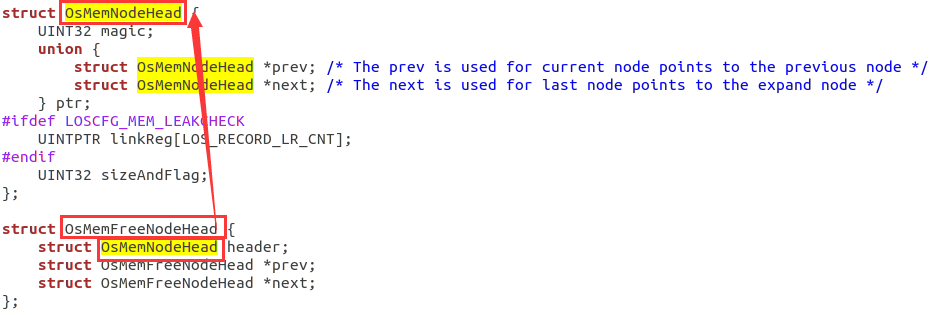
2.OS_MEM_FIRST_NODE(pool)和OS_MEM_END_NODE(pool,size)
OS_MEM_FIRST_NODE是一段宏定义,用于指明第1个结点的起始位置。pool是内存池的起始位置,sizeof(struct OsMemPoolHead)是内存池的头的长度,第1个结点从内存池头后开始。
![]()
OS_MEM_FIRST_NODE是一段宏定义,用于指明最后1个结点的起始位置。因为size代表的是整个内存池的大小,OS_MEM_NODE_HEAD_SIZE相当于就是endNode本身的结构体(OsMemNodeHead)大小,所以整个式子的含义就是指向刚好容纳最后一个节点的起始位置。
![]()
![]()
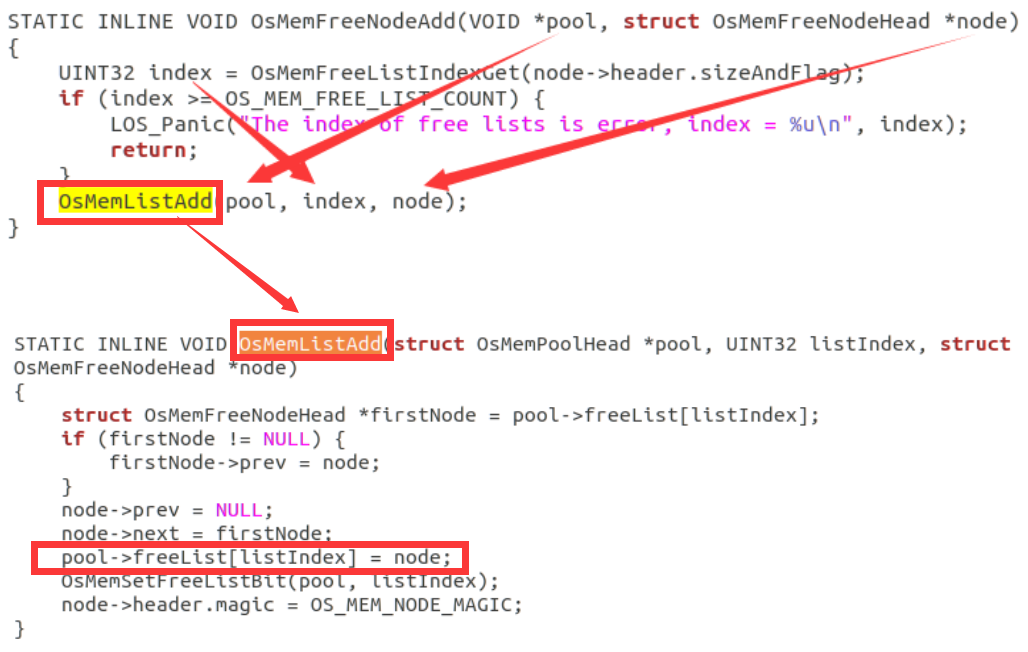
3.OsMemFreeNodeAdd函数
OsMemFreeNodeAdd函数的作用是将空闲块挂载到对应索引的内存块上。
首先进入到OsMemFreeNodeAdd函数后会调用OsMemFreeListIndexGet函数,这就是我们前面的函数,用于返回对应索引的内存块位置。
然后会调用OsMemListAdd函数,freeList就是内存池pool中的索引,然后会根据listIndex的值,将空闲块挂在到该索引上。
【到此为止,源码分析就结束了,如果觉得有帮助记得点赞+收藏吧】
下面补充内存池知识点:
OsMemPoolInit函数用来初始化一个内存池。
内存池(Memory Pool)是一个用于管理内存分配的系统,它预先分配一块大的内存区域,并将其划分为小块以供程序使用。这样做的好处包括减少内存碎片、提高内存分配效率和简化内存管理。
一二级索存在于内存池中,是内存池中的数据结构,它们用于快速定位和管理内存块。
在一个系统中会有多个内存池(比如用户空间和内核空间的内存池)。操作系统的内存不仅由内存池构成还包括页表、段表等,内存池只适用特定场景。空闲块是由内存池中的索引结构组织。