






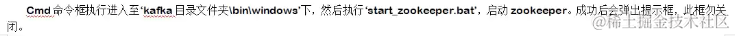





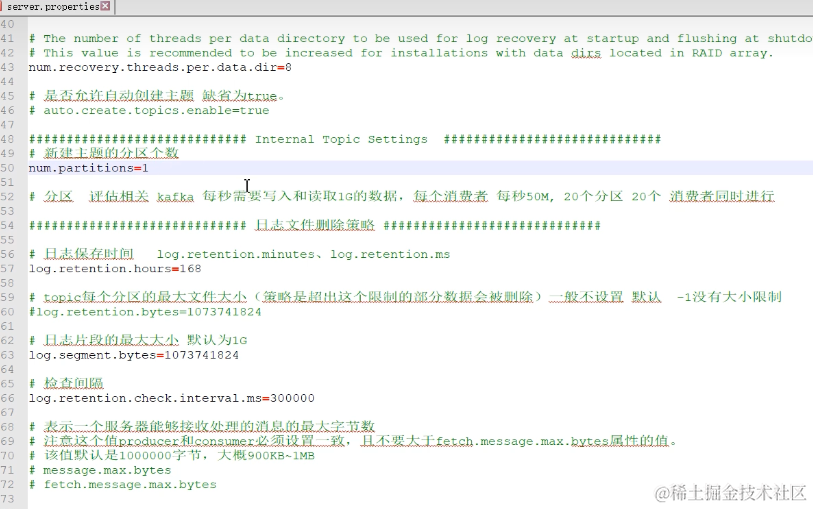
不能缩小





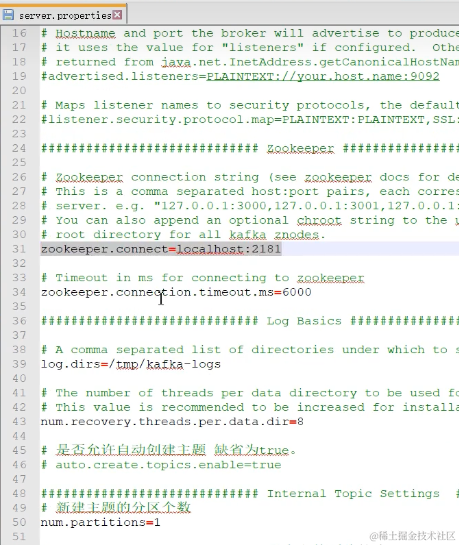

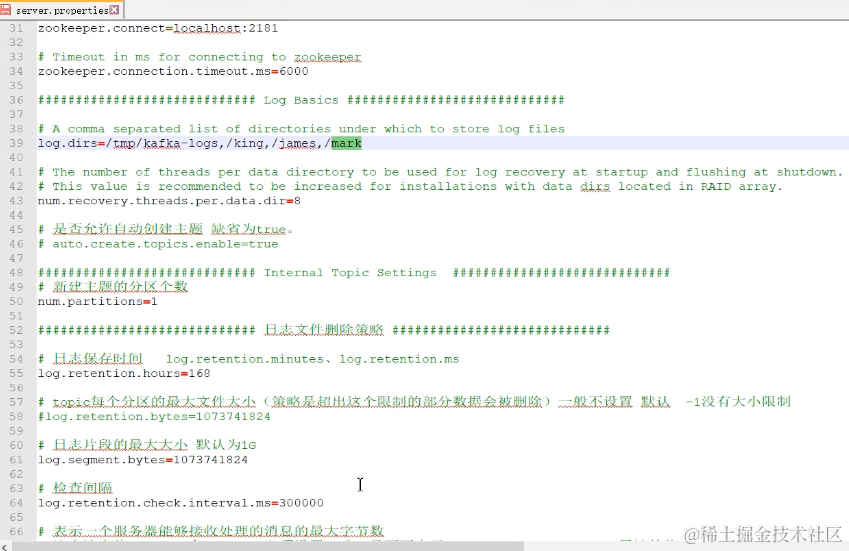

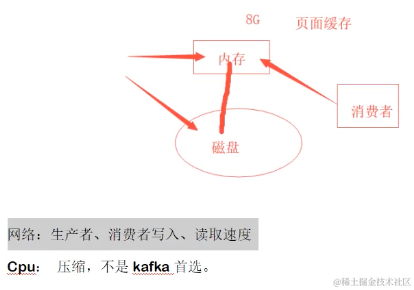
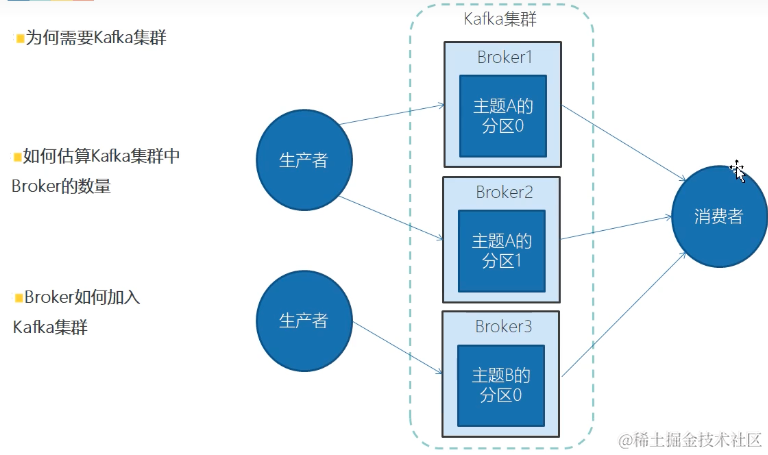
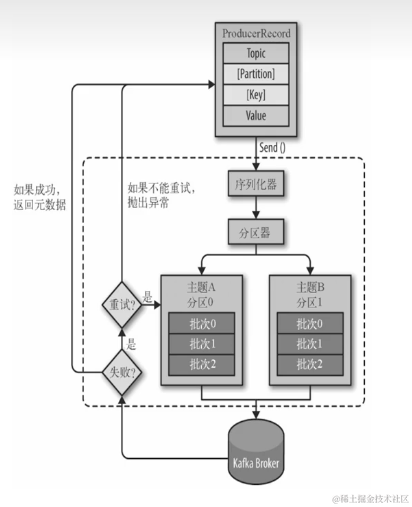
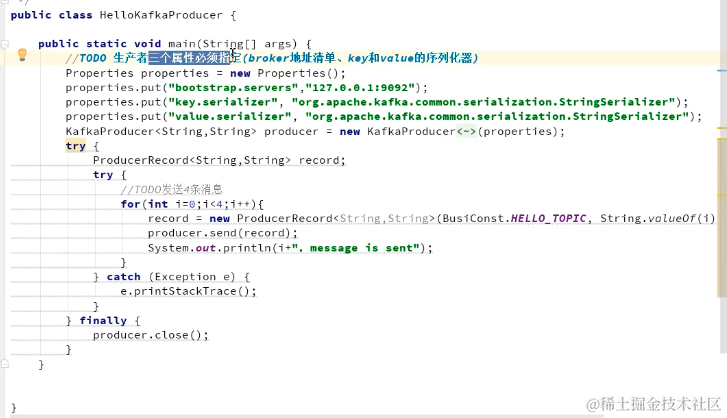
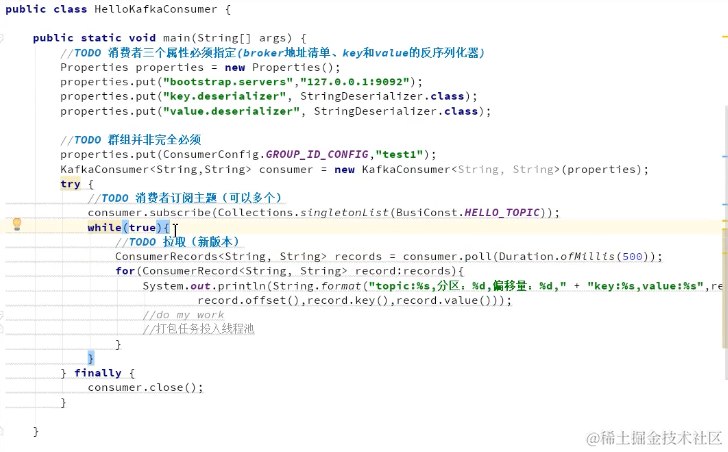
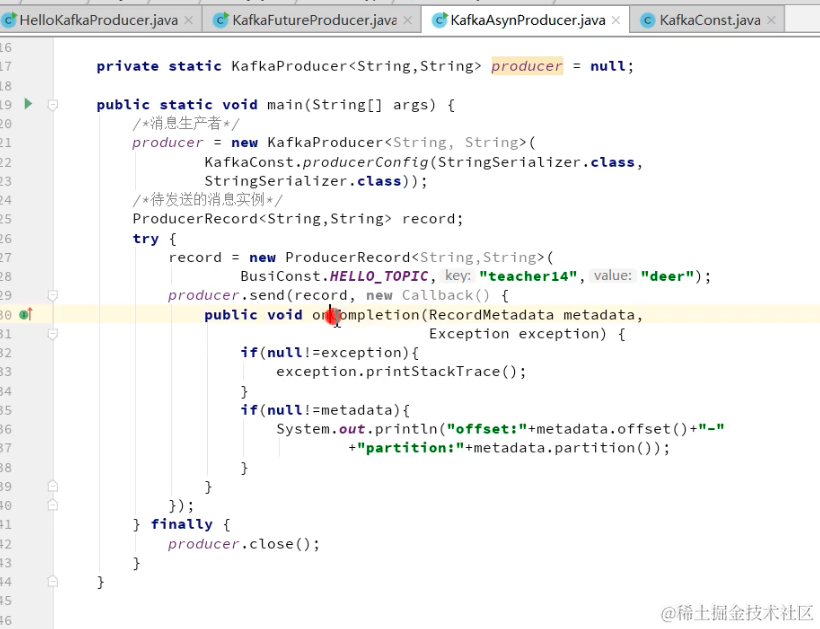



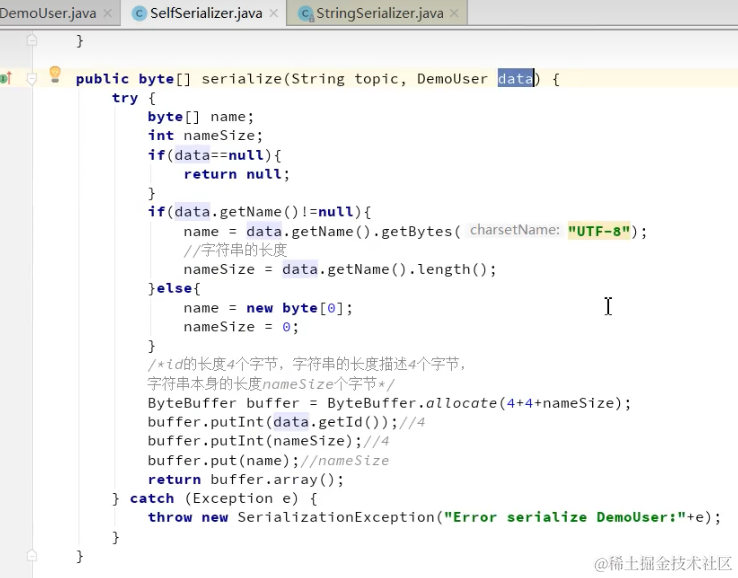
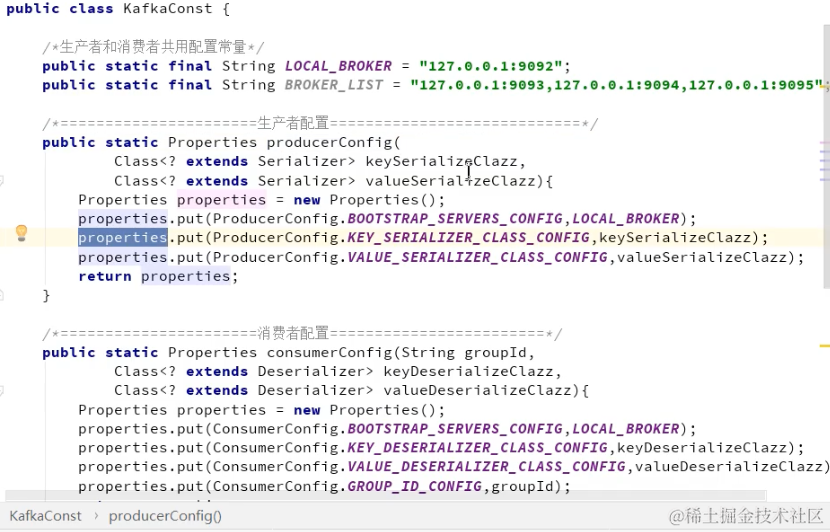
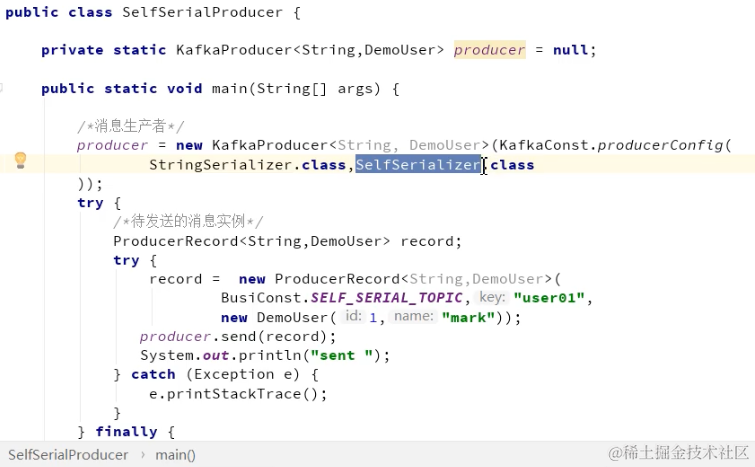
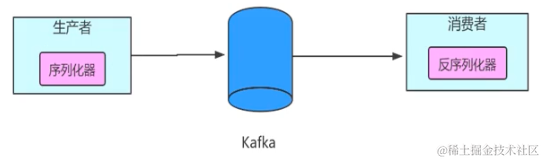
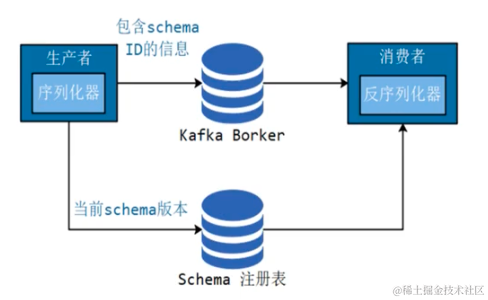
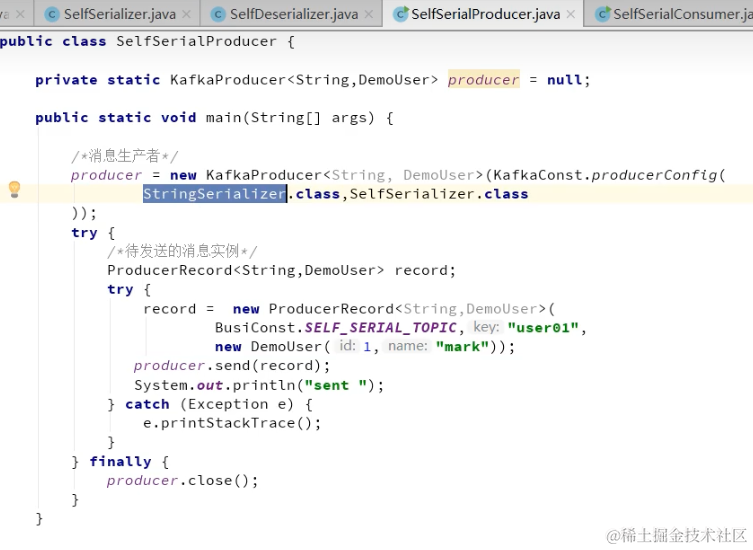

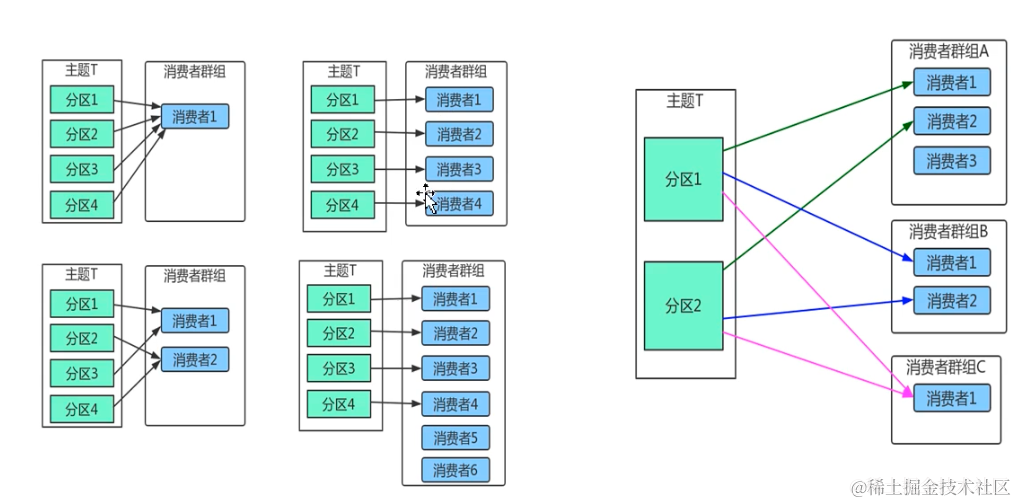

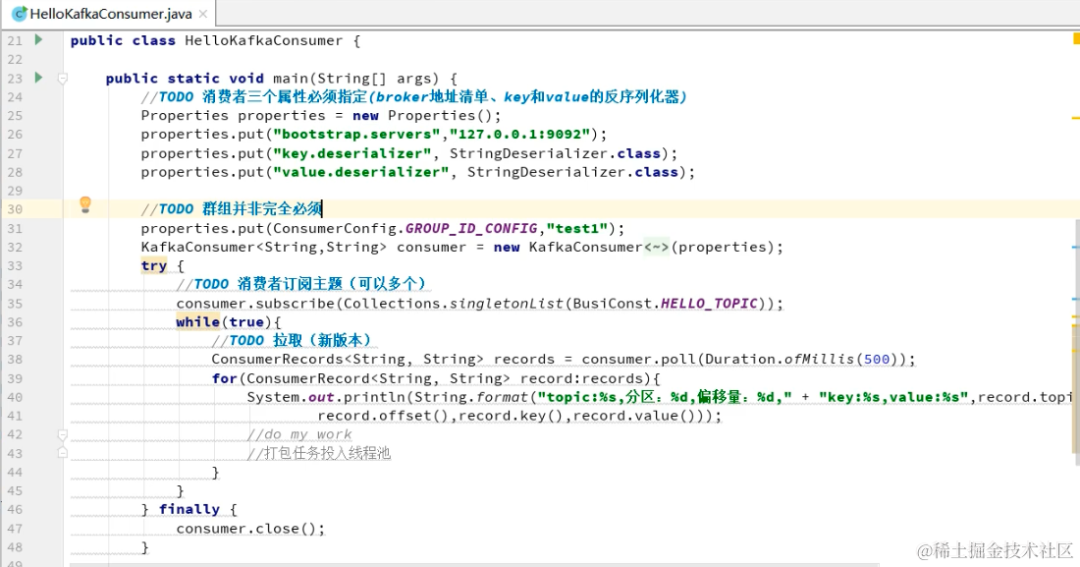
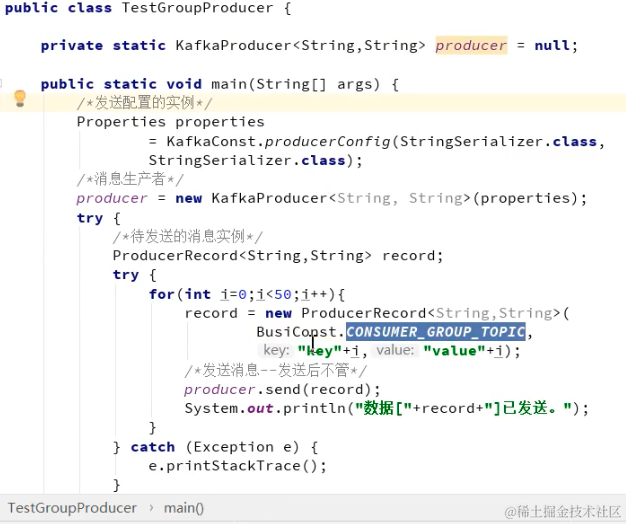


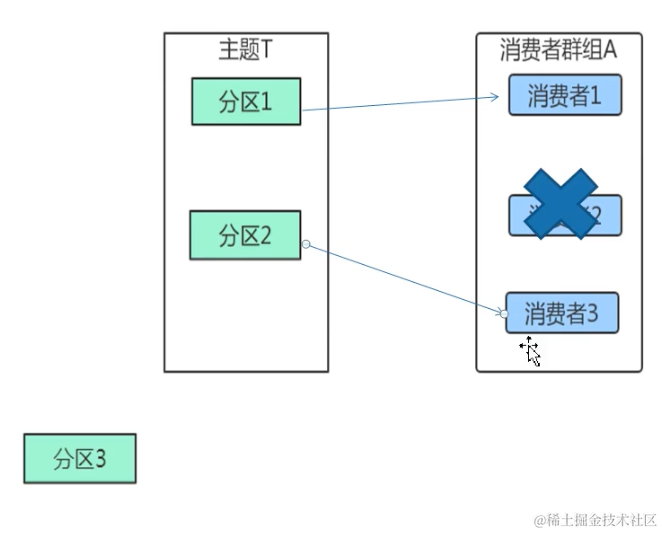
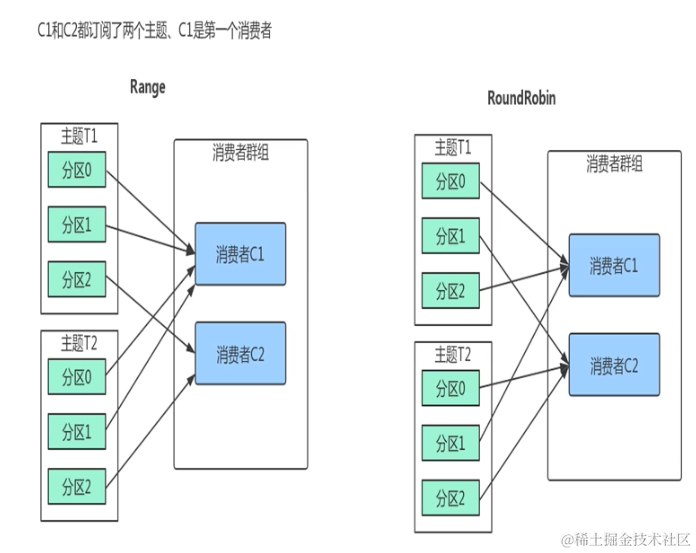

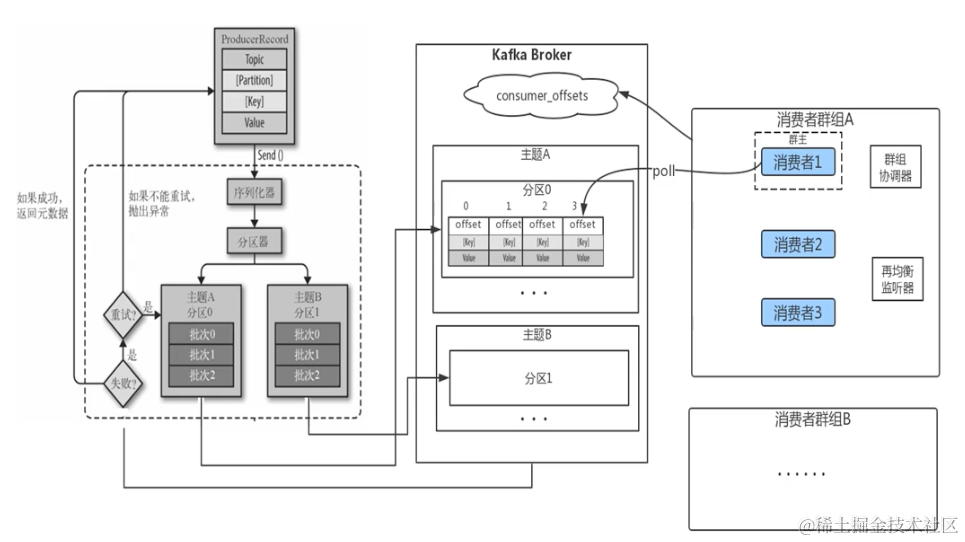

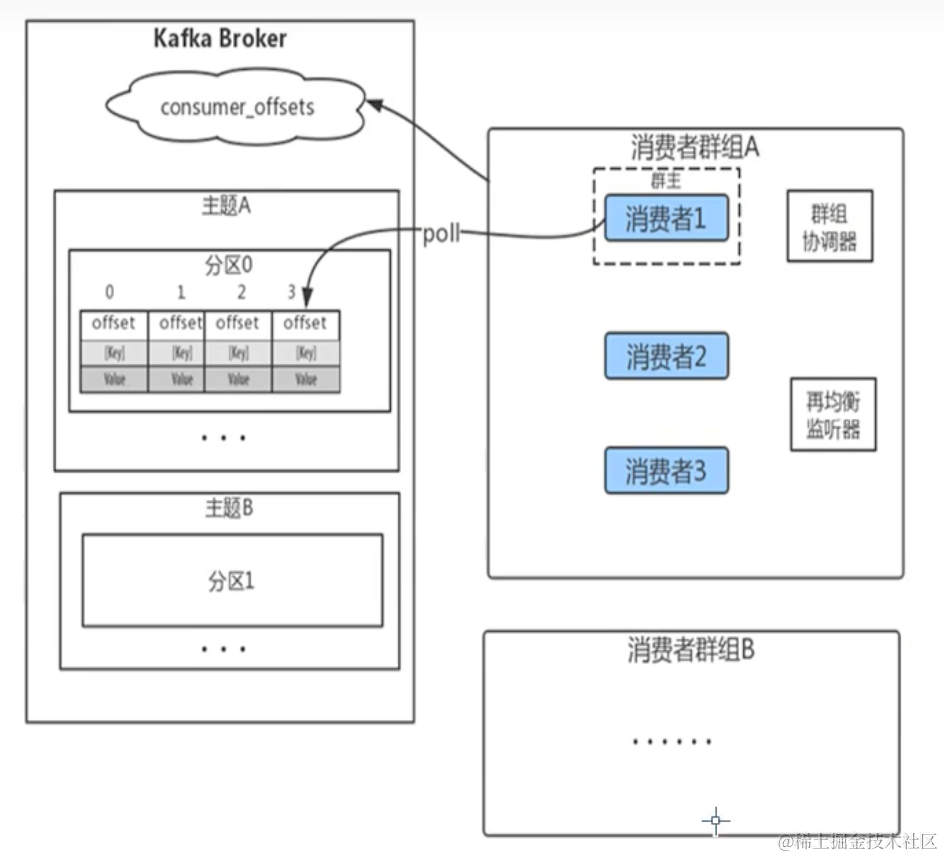
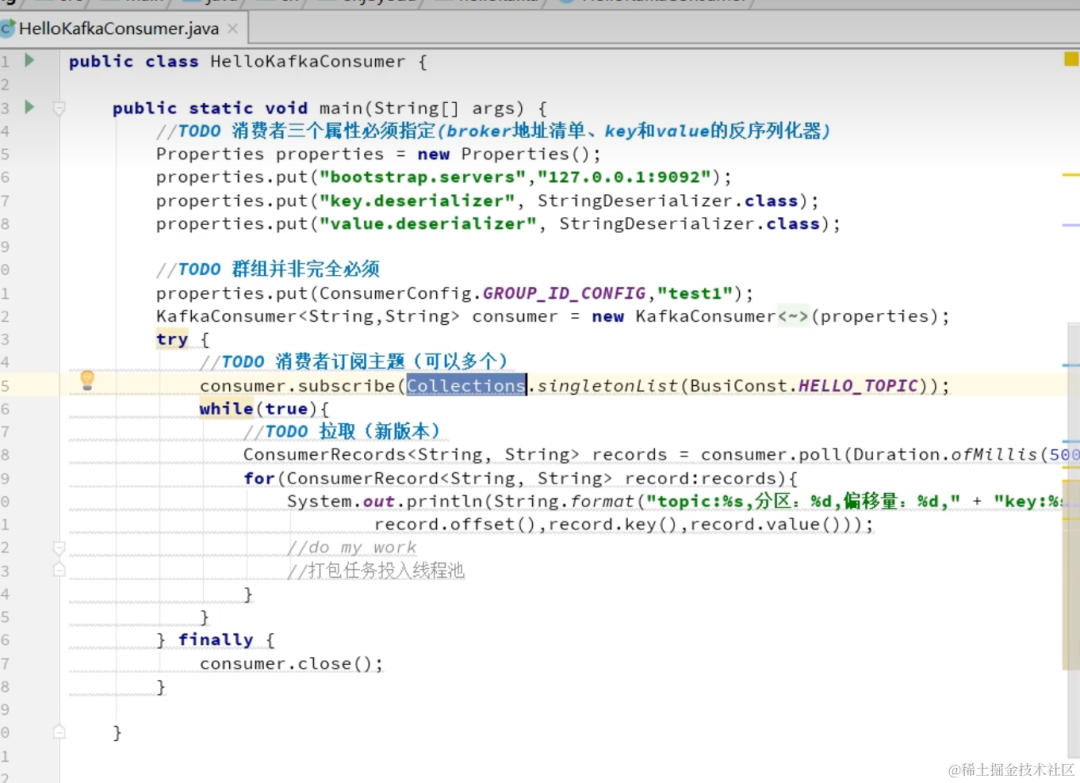
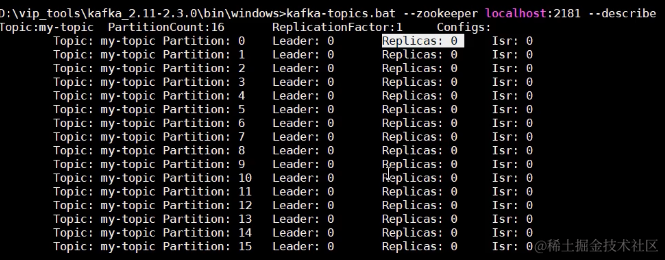
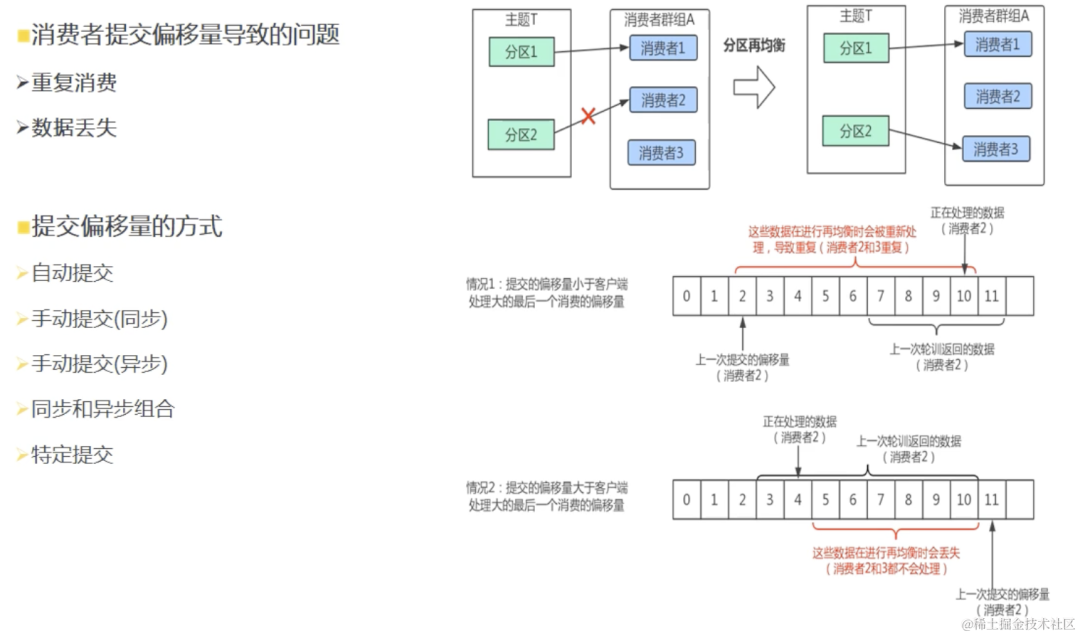
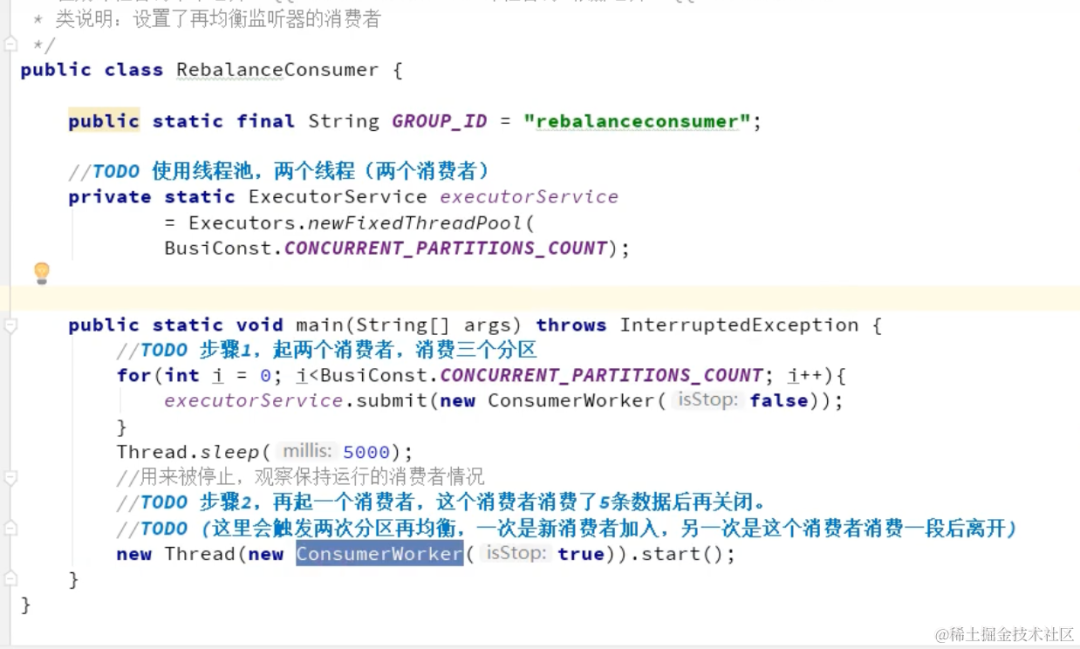
生产者多线程安全,消费者一个线程一个消费者

BigDecimal 是 Java 中的一个精确数字类,用于表示高精度的浮点数或整数,通常用于处理需要避免舍入误差的数值计算。它提供了高精度的算术运算,可用于处理非常大或非常小的数值,以及需要精确度的金融计算或科学计算。
下面是一些关于 BigDecimal 的要点:
高精度:
BigDecimal可以表示非常大或非常小的数值,而且不会丢失精度。这使它非常适合于金融计算和科学计算,这些领域对精确度要求很高。不会引起舍入误差: 与基本的浮点数类型(如
float和double)不同,BigDecimal不会引起舍入误差。它以字符串表示数值,因此可以精确地表示分数。支持各种运算:
BigDecimal类提供了各种算术运算,包括加法、减法、乘法、除法等。这些运算会在内部处理数值的精度,确保结果是准确的。不可变性:
BigDecimal对象是不可变的,这意味着一旦创建,它们的值不能更改。每次执行算术运算时,都会创建一个新的BigDecimal对象来存储结果。舍入模式: 在执行某些操作时,您可以指定舍入模式,以控制结果的舍入行为。常见的舍入模式包括四舍五入、向上舍入、向下舍入等。
import java.math.BigDecimal;
public class BigDecimalExample {
public static void main(String[] args) {
// 创建 BigDecimal 对象
BigDecimal num1 = new BigDecimal("10.5");
BigDecimal num2 = new BigDecimal("5.2");
// 加法运算
BigDecimal sum = num1.add(num2);
System.out.println("Sum: " + sum); // 输出:Sum: 15.7
// 减法运算
BigDecimal difference = num1.subtract(num2);
System.out.println("Difference: " + difference); // 输出:Difference: 5.3
// 乘法运算
BigDecimal product = num1.multiply(num2);
System.out.println("Product: " + product); // 输出:Product: 54.6
// 除法运算
BigDecimal quotient = num1.divide(num2, 2, BigDecimal.ROUND_HALF_UP);
System.out.println("Quotient: " + quotient); // 输出:Quotient: 2.02
}
}



pool:这是一个命名块(或称为子配置块),用于定义与连接池相关的配置参数。max-idle:这个参数表示连接池中允许的最大空闲连接数。在连接池中,如果某个连接长时间没有被使用,会被判定为空闲连接。这个参数限制了空闲连接的数量,以控制连接池的大小。min-idle:这个参数表示连接池中保持的最小空闲连接数。连接池通常会在初始化时创建一些连接,以确保在需要连接时能够快速获取,而不需要创建新的连接。这个参数就是用来配置这个最小数量的连接。max-active:这个参数表示连接池中允许的最大活动连接数。活动连接是当前正在被使用的连接,这个参数限制了同时被使用的连接的最大数量。如果达到这个数量,新的请求可能需要等待。max-wait:这个参数表示获取连接的最大等待时间(以毫秒为单位)。如果连接池中的活动连接数达到了max-active的限制,新的请求获取连接时可能需要等待。这个参数指定了最长等待时间,如果在这个时间内没有可用连接,则会抛出超时异常。
这些参数的值可以根据你的应用需求和系统性能来进行调整。不同的应用场景可能需要不同的连接池配置,以满足并发访问的要求并避免资源浪费。
hystrix:这是一个命名块(或子配置块),用于定义Hystrix的配置参数。command:这个参数指定了Hystrix命令的配置,可以根据需要配置多个命令。default:这是一个命令名称,表示默认的Hystrix命令配置。你可以在这个块中定义默认的命令配置,然后在具体的命令配置中覆盖它。execution:这个参数用于配置Hystrix命令的执行策略。isolation:这个参数用于配置命令的隔离策略,隔离策略决定了Hystrix命令的执行方式。在这里,thread表示使用线程隔离,即为每个Hystrix命令创建一个独立的线程池来执行。timeoutInMilliseconds:这个参数表示Hystrix命令的超时时间,以毫秒为单位。如果命令执行的时间超过了这个超时时间,Hystrix会认为命令执行失败并执行降级逻辑。
在上述配置中,Hystrix默认命令的隔离策略是线程隔离,并且超时时间为30,000毫秒(30秒)。这意味着每个Hystrix命令都会在自己的线程中执行,如果执行时间超过30秒,Hystrix会触发降级逻辑。
你可以根据具体的需求和应用场景来调整这些参数,以满足系统的性能和可用性要求。不同的命令可以具有不同的配置,以适应不同的操作和服务调用。
serialVersionUID 是 Java 中用于控制序列化版本的特殊字段。当你在 Java 中使用对象序列化(将对象转换为字节流以便存储或传输)时,每个序列化的类都会有一个 serialVersionUID。它的作用是在反序列化时确保类的版本匹配。
serialVersionUID 是 Java 中用于控制序列化版本的特殊字段。当你在 Java 中使用对象序列化(将对象转换为字节流以便存储或传输)时,每个序列化的类都会有一个 serialVersionUID。它的作用是在反序列化时确保类的版本匹配。
以下是关于 serialVersionUID 的一些要点:
serialVersionUID是一个长整数(64 位),它用于标识类的版本。当你序列化一个对象时,
serialVersionUID会被写入序列化数据中。在反序列化时,Java 会使用被序列化数据中的
serialVersionUID与类的当前版本的serialVersionUID进行比较。如果两者不匹配,就会导致反序列化失败,抛出InvalidClassException异常。如果类没有显式地定义
serialVersionUID,Java 会根据类的结构自动生成一个serialVersionUID。这意味着如果类的结构发生变化,serialVersionUID也会发生变化,可能导致反序列化失败。
通常,为了确保序列化和反序列化的兼容性,建议显式地定义 serialVersionUID,并在类的版本发生变化时手动更新它。这可以通过在类中添加以下声明来完成:
private static final long serialVersionUID = <自定义的版本号>;<自定义的版本号> 应该是一个常量长整数。如果你不希望手动管理 serialVersionUID,可以使用一些工具来自动生成它。
总之,serialVersionUID 是 Java 中用于控制序列化版本兼容性的机制,它确保了在类结构发生变化时反序列化操作的可靠性。
ObjectId 类看起来像是用于表示对象标识符的类。这个类实现了 Comparable<ObjectId> 接口,这意味着它可以被用于对象之间的比较。同时,它还实现了 java.io.Serializable 接口,表明对象可以被序列化和反序列化。
在 Java 中,java.io.Serializable 接口用于指示一个类的对象可以被序列化成字节流,以便在网络上传输、保存到文件或通过其他方式进行持久化。通过实现 Serializable 接口,你可以将对象转化为字节流,然后在需要的时候将其还原为对象。
在这个 ObjectId 类中,实现 Comparable<ObjectId> 接口可能是为了定义对象之间的自然排序顺序。这意味着你可以使用类似于排序算法的操作来比较和排序 ObjectId 对象。
MongoDB 驱动程序(Java Driver)的一部分,用于创建一个 ObjectId 对象。这个方法名为 createFromLegacyFormat,接受三个参数:
time:表示时间部分,以秒为单位。machine:表示机器或节点的标识。inc:表示递增值(Incremental Value)。
这个方法的主要作用是为了向后兼容旧版本的驱动程序,因为旧版本的驱动程序只需要这三个参数来创建 ObjectId,而新版本的 MongoDB 驱动程序需要更多的信息来创建符合规范的 ObjectId。
在文档中也有一些额外的说明:
这个方法主要面向那些编写自己的 BSON 解码器(BSON 是 MongoDB 中的二进制数据表示格式)的开发者,普通用户通常不需要使用它。
这个方法的存在不会破坏已经使用
ObjectId的应用程序,因为它仍然可以处理旧版本的ObjectId格式,并且可以在新旧版本之间进行互操作。
总之,这个方法的目的是为了平滑过渡,以确保不会中断使用旧版 ObjectId 的应用程序的正常运行,并为那些需要创建兼容旧版本格式的 ObjectId 的开发者提供了一种方式。
用于检查一个字符串是否符合 ObjectId 格式的方法。ObjectId 是 MongoDB 数据库中的一种数据类型,通常由一个24个字符的十六进制字符串组成。
该方法接受一个字符串作为参数,并返回一个布尔值,表示该字符串是否可能是一个有效的 ObjectId。以下是该方法的主要步骤:
首先,它检查输入字符串是否为 null,如果为 null,则直接返回 false。
接下来,它获取字符串的长度,如果长度不等于 24,则返回 false。因为 ObjectId 必须由24个字符组成。
然后,它遍历字符串的每个字符,检查每个字符是否是有效的 ObjectId 字符。有效的 ObjectId 字符包括数字 '0' 到 '9',小写字母 'a' 到 'f' 以及大写字母 'A' 到 'F'。如果字符串中包含了其他字符,就返回 false。
如果字符串通过了上述所有检查,那么它被认为是一个可能的有效 ObjectId,最后返回 true。
这个方法主要用于验证用户提供的字符串是否符合 ObjectId 的格式要求,以防止不合法的输入被插入到 MongoDB 数据库中。如果字符串通过了验证,那么它可以被用作 ObjectId。如果不通过验证,则应该拒绝该字符串作为 ObjectId。
构造函数被标记为 @Deprecated,意味着不建议继续使用它,可能存在一些问题或不推荐的用法。在新的代码中,建议使用其他方式来创建 ObjectId 实例,例如使用 ObjectId 类提供的静态方法。
被标记为 @Deprecated,表示该方法已经不推荐使用,并且在将来的版本中将会被移除。该方法名为 toStringBabble,它用于将 ObjectId 对象转换为一种称为 "babble" 格式的字符串表示。然而,这种格式已经被弃用,并且建议使用 toHexString 方法来获取十六进制格式的字符串表示。因此,开发者应该避免使用 toStringBabble 方法,而改用 toHexString 方法。
new TypeToken<List<Bean>>() {}.getType()使用了 @Data 注解,通常这个注解会自动生成常用的getter、setter、toString等方法。该类包含以下字段:
total(类型为Long):用于存储某种数据的总数或总量。retMapList(类型为List<Map<String, Object>>):这是一个包含Map对象的列表。每个Map对象代表一条数据记录,其中键为String类型,值为Object类型,用于存储数据的字段名和对应的值。
这个类通常用于表示从Elasticsearch或类似的数据存储系统中检索数据时的结果集,其中total字段可以表示匹配的总记录数,而retMapList字段则包含了每个记录的详细信息。
请注意,@Data 注解通常是Lombok库中的注解,它自动生成了一些常用的Java类方法,如toString、equals、hashCode等,以简化代码编写。如果您的项目中使用了Lombok库,那么这些方法将自动生成,否则您需要手动编写这些方法。
// 创建一个 IndexRequest 对象,用于插入文档
// 设置文档的唯一标识 ID
// 将对象 o 转换为 JSON 字符串,并设置为文档的内容
// 设置刷新策略,使用 IMMEDIATE,表示插入后立即刷新,使写入操作立即生效
// 使用 RestHighLevelClient 执行插入请求,返回 IndexResponse 对象
// 将 IndexRequest 添加到 BulkProcessor 中,以便批量执行插入请求
设置一致性级别为 ConsistencyLevel.ANY,以确保插入操作能够在任何节点上执行
举例来说,假设你有一个 Cassandra 表格,表示用户信息,包含字段如下:
id: 用户的唯一标识name: 用户的姓名email: 用户的电子邮件地址
如果你想要更新用户的姓名和电子邮件地址,同时需要提供用户的唯一标识(id)作为主键来定位要更新的用户记录,那么你可以使用如下的 Java 代码来构建更新操作:
Update update = QueryBuilder.update("my_keyspace", "user_info");
// 设置要更新的字段和值
update.with(QueryBuilder.set("name", "New Name"));
update.with(QueryBuilder.set("email", "[email protected]"));
// 添加主键条件
update.where(QueryBuilder.eq("id", "user123"));
// 设置一致性级别
update.setConsistencyLevel(ConsistencyLevel.ANY);PRIMARY KEY:这部分定义了表的主键。((userId, day), logTime, logId):这部分定义了主键的结构,它由多个部分组成,每个部分用逗号分隔。
userId和day是复合主键的第一个部分,它们被括在括号()中。logTime是复合主键的第二个部分,它位于第一个部分之后,由逗号,分隔。logId是复合主键的第三个部分,它位于第二个部分之后,由逗号,分隔。
这个复合主键的定义意味着以下几点:
主键由多个列组成,按照定义的顺序。
(userId, day)组成了复合主键的第一个部分,被用于分区键。这意味着数据将根据userId和day进行分区,并存储在Cassandra的不同分区中。logTime和logId组成了复合主键的第二和第三部分,用于在分区内排序和唯一标识行。这可以确保在同一分区内的数据按logTime和logId进行排序,同时保持唯一性。
PRIMARY KEY ((userId, day), logTime, logId) 这个定义的是Cassandra表的复合主键。让我为您解释它的含义并提供一个示例:
PRIMARY KEY:这部分定义了表的主键。((userId, day), logTime, logId):这部分定义了主键的结构,它由多个部分组成,每个部分用逗号分隔。
userId和day是复合主键的第一个部分,它们被括在括号()中。logTime是复合主键的第二个部分,它位于第一个部分之后,由逗号,分隔。logId是复合主键的第三个部分,它位于第二个部分之后,由逗号,分隔。
这个复合主键的定义意味着以下几点:
主键由多个列组成,按照定义的顺序。
(userId, day)组成了复合主键的第一个部分,被用于分区键。这意味着数据将根据userId和day进行分区,并存储在Cassandra的不同分区中。logTime和logId组成了复合主键的第二和第三部分,用于在分区内排序和唯一标识行。这可以确保在同一分区内的数据按logTime和logId进行排序,同时保持唯一性。
示例说明:
假设有以下日志数据:
userId | day | logTime | logId | info
-------+-----------+----------+-------+-----------
user1 | 20220101 | 08:00:00 | log1 | ...
user1 | 20220101 | 08:30:00 | log2 | ...
user2 | 20220102 | 09:00:00 | log3 | ...数据按照
(userId, day)部分进行分区。这意味着user1的所有数据都存储在一个分区中,user2的数据存储在另一个分区中。在每个分区内,数据按照
logTime进行排序。例如,user1分区内的数据按照logTime排序,log1在log2之前。logId用于确保在同一分区内的数据行是唯一的。这确保了每条日志都具有唯一的标识。
cassandraDao.insertByPkWheres 的方法,该方法的作用是向 Cassandra 数据库中插入数据。以下是对该行代码的注释和举例:
// 使用 cassandraDao 对象调用 insertByPkWheres 方法,将用户信息插入到 Cassandra 数据库
// 参数 session:数据库连接会话对象
// 参数 keyspace:数据库键空间名称
// 参数 tableNa:表名
// 参数 pkMap:主键映射,其中包含了 userId 作为主键字段名和用户信息中的用户 ID 值
// 参数 null:此处为 null,表示没有要添加的其他条件
// 参数 userInfo:要插入的用户信息对象
cassandraDao.insertByPkWheres(session, keyspace, tableNa, pkMap, null, userInfo);putAll 是 Java 中 Map 接口的一个方法,它用于将一个 Map 中的所有键值对映射添加到另一个 Map 中。具体来说,它接受一个 Map 参数,并将该参数中的所有键值对添加到当前的 Map 中,如果有重复的键,则新值会覆盖旧值。
例如,假设你有两个 Map 对象 map1 和 map2,你可以使用 putAll 方法将 map2 中的所有键值对添加到 map1 中,如下所示:
Map<String, Object> map1 = new HashMap<>();
map1.put("key1", "value1");
map1.put("key2", "value2");
Map<String, Object> map2 = new HashMap<>();
map2.put("key3", "value3");
map2.put("key4", "value4");
map1.putAll(map2);
System.out.println(map1);上述代码会输出:
{key1=value1, key2=value2, key3=value3, key4=value4}如你所见,map2 中的键值对已经成功添加到了 map1 中。
@JsonProperty 是 Jackson 库的注解,通常用于指定 Java 对象属性与 JSON 属性之间的映射关系。当 Java 类的字段名与 JSON 数据中的字段名不一致时,使用 @JsonProperty 注解可以指定它们之间的对应关系。
例如,如果您有一个 Java 类如下:
public class MyObject {
@JsonProperty("name")
private String objectName;
// Getter 和 Setter 方法
}在这个示例中,@JsonProperty("name") 注解指定了 objectName 字段与 JSON 数据中的 "name" 属性之间的映射关系。这意味着当将该 Java 对象转换为 JSON 数据时,将使用 "name" 作为字段名。
这个注解对于处理复杂的 JSON 数据结构或者需要在 Java 对象和 JSON 之间进行灵活映射的情况非常有用。它可以帮助确保在序列化和反序列化过程中正确地匹配字段名称。
@ApiModelProperty 是 Swagger 注解之一,它用于在生成 API 文档时对 API 接口的操作或模型的属性进行描述。这个注解通常用在 Java 类的字段、方法、方法参数等上,以提供额外的元数据,用于生成详细的 API 文档。
下面是一些常用的 @ApiModelProperty 注解的属性和其作用:
value:描述属性的简短说明,通常是该属性的用途或含义。name:属性的名称。dataType:属性的数据类型,可以是基本数据类型(如 int、long、String)或自定义的数据类型。example:属性的示例值,用于展示该属性的典型值。notes:属性的详细说明,可以包含更多的信息,如限制、特殊规则等。hidden:是否隐藏属性,如果设置为true,则该属性不会在生成的 API 文档中显示。
示例:
import io.swagger.annotations.ApiModelProperty;
public class User {
@ApiModelProperty(value = "用户ID", dataType = "Long", example = "12345")
private Long id;
@ApiModelProperty(value = "用户名", dataType = "String", example = "john_doe")
private String username;
@ApiModelProperty(value = "年龄", dataType = "int", example = "30")
private int age;
// 构造函数、Getter 和 Setter 方法等...
}上面的示例中,@ApiModelProperty 注解用于描述 User 类的属性,包括 id、username 和 age。这些描述信息可以帮助生成 API 文档时提供更多的上下文和信息,使 API 文档更加清晰和有用。在实际使用中,Swagger 会根据这些注解自动生成 API 文档,开发人员和 API 使用者可以根据文档了解如何正确地使用 API。
@SerializedName 是 Google Gson 库中的注解,用于指定 Java 类字段(或方法)与 JSON 数据中的键之间的映射关系。通常情况下,JSON 数据的键名与 Java 类的字段名是一致的,但有时候 JSON 数据的键名可能与 Java 类的字段名不匹配,或者希望在序列化和反序列化过程中使用不同的名称。这时可以使用 @SerializedName 注解来显式指定映射关系。
以下是 @SerializedName 注解的用法示例:
import com.google.gson.annotations.SerializedName;
public class Person {
@SerializedName("first_name")
private String firstName;
@SerializedName("last_name")
private String lastName;
// 构造函数、Getter 和 Setter 方法等...
}在上面的示例中,@SerializedName 注解用于将 Java 类中的 firstName 字段映射到 JSON 数据中的 first_name 键上,将 lastName 字段映射到 last_name 键上。这样,在序列化(将 Java 对象转换为 JSON 数据)和反序列化(将 JSON 数据转换为 Java 对象)时,Gson 库会根据这些注解来正确地映射字段与键。
使用 @SerializedName 注解可以解决 JSON 数据与 Java 类字段之间的不匹配问题,使数据的序列化和反序列化更加灵活和精确。
在这个 preHandle 方法中,拦截器记录了请求的 URL 和远程主机地址,并返回 true,表示请求可以继续处理。如果你想要在这个拦截器中执行其他的操作,例如权限检查、参数验证等,可以在这个方法内进行处理。如果需要拦截请求,可以返回 false。
这个方法是请求处理前的预处理操作,你可以根据具体需求来扩展它,以实现你的拦截逻辑。例如,在这里可以添加一些权限验证、日志记录、请求参数的验证等操作。
在 postHandle 方法中,你可以执行在请求处理之后、视图渲染之前的操作。通常,你可以在这里对模型和视图进行进一步的处理,或者添加一些通用的数据供视图渲染使用。
如果你的拦截器不需要在请求处理后执行额外的操作,可以将这个方法保留为空实现,就像你的代码示例中一样。如果需要在请求处理后执行特定的逻辑,你可以在这个方法中实现它。例如,你可以根据请求的结果进行一些日志记录或其他操作。
要注意,postHandle 方法会在请求处理后,但在视图渲染之前被调用,因此你可以在这里对响应进行进一步的处理,但不能修改视图的渲染结果。
使用 Elasticsearch 的 Java API 创建一个查询条件,该条件是一个精确匹配(match phrase)查询
使用 Elasticsearch 的 Java API 创建一个查询条件,该条件是一个术语查询(term query)。
使用了 ".keyword" 后缀来表示精确匹配,通常用于处理关键字类型的字段,以确保不进行分词处理或标记化处理。
使用 Elasticsearch 的 Java API 创建了一个查询条件,该条件是一个术语查询(term query)。术语查询是一种用于精确匹配的查询类型,要求字段的值必须与指定的值完全相等。
@Primary 注解:这是 Spring 框架的注解之一,它表示被注解的 bean 是首选的,当多个候选 bean 匹配一个注入点时,首选 bean 会被注入。
Set<Integer> 是一个用于存储整数的集合数据结构。在Java中,Set 是一个接口,用于表示不允许包含重复元素的集合。Integer 是Java中的整数对象类型,可以用来表示整数值。
以下是一些示例操作:
// 创建一个空的整数集合
Set<Integer> allONumSet = new HashSet<>();
// 向集合中添加整数
allONumSet.add(1);
allONumSet.add(2);
allONumSet.add(3);
// 检查整数是否存在于集合中
boolean containsOne = allONumSet.contains(1); // 返回 true
boolean containsFour = allONumSet.contains(4); // 返回 false
// 从集合中删除整数
allONumSet.remove(2);
// 获取集合的大小(包含的唯一整数数量)
int size = allONumSet.size(); // 返回 2,因为只剩下 1 和 3
// 迭代集合中的整数
for (Integer num : allONumSet) {
System.out.println(num);
}加群联系作者vx:xiaoda0423
仓库地址:https://github.com/webVueBlog/JavaGuideInterview