A Video Key Frame Extraction Method Based on Multiview Fusion
摘要:
- 目前的实时监控中,存在大量的视频数据。传统的关键帧抽取方法需要消耗更多的资源和更长的时间。因此,进行关键帧抽取研究来减少大规模视频数据是很有必要的。为了解决以上的这些问题,作者提出了一种基于多视觉特征融合的关键帧抽取方法,该方法通过自动编码来进行视频压缩。通过将视频数据进行特征降维,降维后进行特征融合,最后采用动态规划和聚类算法来进行关键帧抽取。实验结果表明,这种方法具有更低的计算复杂度,同时互信息也更好。在一定程度上表明本文提出的方法更有效,为后续的视频研究提供了技术支撑。
1、引言
- 随着经济和生活的需要,监控设备也在不断增加。同时,视频的清晰度和分辨率也得了不断的提高,比如说:4k和8k及其百万级像素,高动态范围和位深度。基于此,大量的视频的视频数据将会产生,要想全量保存这些大规模的数据是不实际的,这将会消耗大量的内存。因此,是关键帧获取也就显示尤为重要。
- 在视频关键帧抽取中,这为实时视频监控和视频分割带来了巨大的挑战。在时间方面,收到监控设备的影响,需要进行实时视频流处理,基本每秒需要进行24到30帧。在资源消耗方面,关键帧抽取对于计算要求很高,每一帧的处理都需要算力。第二,其次,视频流的连续传输给网络流量增加了巨大的负担并且需要较高的网络带宽。
- 为了从海量的视频数据中抽取出关键信息,作者提出了一种关键帧抽取技术。目前在关键帧抽取研究中已经取得了一些成果。
- 为了能够有效解决已经存在的这些问题,作者提出了一种基于自动编码的关键帧抽取方法。首先使用使用全量数据来训练师模型,然后使用训练的模型来进行特征降维,并对降维后的数据进行多视觉特征融合。然后使用融合的特征来进行关键帧抽取。
- (1)从多视角来进行特征融合抽取的关键帧更为准确。
- (2)是从多个视频帧来抽取关键信息,因此能够能够有效减少冗余特征。
- (3)提出了一种新的损失函数来保证降维前后的特征的一致性。
- (4)采用低纬度特征来进行特征重组,能够提高关键帧抽取的速度。
剩下的文章的组织结构如下所示:第二部分介绍了自动编码的内容。第三部分介绍了多角度视频流降维。第四部分介绍了融合后的关键帧抽取和实验结果展示。第五部分就是结语。
2、自动编码相关概述
- 1986年,Rumelhart提出了自动编码并且应用其到高维度特征的处理中,并提出了一种改进后的神经网络模型。自编码是一种前馈非循环神经网络模型,同时是无监督的,能够从输入数据中学习到隐藏的特征。自编码在特征抽取中效果比较好,同时也是深度置信网络模型重要组成部分。在图像特征重组和机器翻译中应用比较广泛。自动编码被应用到关键帧抽取中,需要将特征降维后来学习隐藏特征。然后在隐层特征中抽取出关键帧。
2.1网络结构
- 自动编码的网络结构如图1所示。主要包括编码和解码层。
- 自动编码将输入特征x进行编码获取一个新的特征然后进行性特征重组和学习得到一个新的特征。
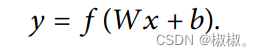
- 为了使得重构后的特征鱼输入x需要尽可能保持一致,基于此需要通过损失函数来对模型不断进行迭代训练来进行优化。
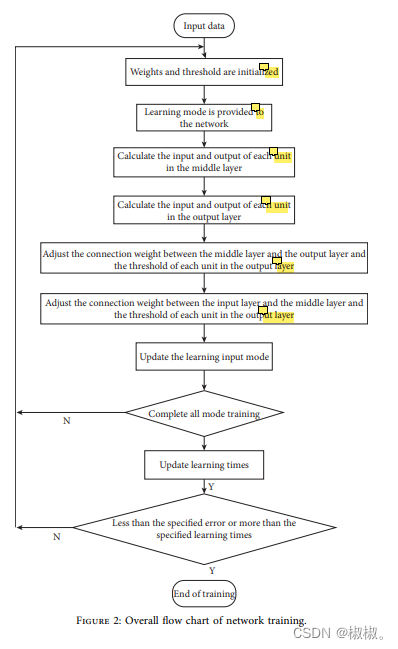
2.2网络训练
与深度前馈神经网络结构类似,自动编码模型训练的过程主要包括:参数初始化、前馈节点计算、误差权重计算。计算过程如图2所示。
3、视频流多视角特征降维模型
3.1数据获取及其预处理
- 实时的视频数据采集(采集的四川摄像头的实时数据)。
- 获取的视频总共4分钟,数据包括六千帧。将数据进行模型训练后,需要将数据进行更深层的处理。处理过程如下所示:
- 第一阶段:使用VIBe算法分割成包含目标的十个部分,然后将每部分分割成300个视频帧来作为训练数据。
- 第二阶段:将数据转换成RGB三通道数据,三通道数据能很好表达出三个矩阵,便于后续的计算。
- 第三阶段:将RGB数据进行标准化处理。
数据的归一化方法我们使用z-score方法,需要先进行z-score归一化,然后在进行归一化。
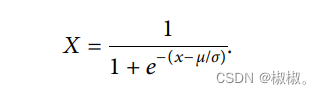
- 最后一阶段:将数据转换成模型需要的数据格式。
3.2模型结构设计
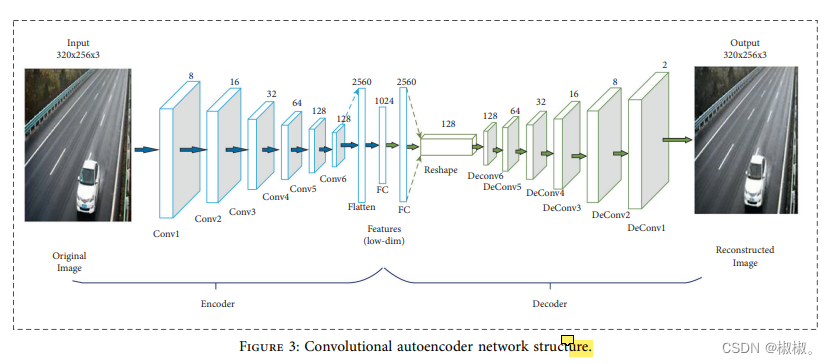
- 预处理之后,自动编码模型需要进行编码和解码处理。编码部分主要包括:输入层、6个卷积层、2个全连接层。卷积层如图3所示。卷积层1到6的参数分别为:8、16、32、64、128和128.所有的卷积层都使用3x3的滤波器。最后一个卷积层的输出作为全连接层的输入,输出得到2560个参数。全连接层的输出为1024个参数。
-解码主要包括:全连接层、重构层、6个卷积层。全连接层的节点为1280,6个反卷积的参数为:5、4、128,如图3所示。反卷积的计算参数为:128、64、32、16、8和2.卷积层和反卷积层使用的激活函数为非线性激活函数(RELU),如图3所示。
- 在模型中设置了特殊的损失函数,通过训练不断计算损失函数来进行模型优化。通过不断迭代训练持续性地减少真实值与预测值之间的误差。其中,average
absolute error损失函数作为损失函数的一部分。MAE的计算公式如下所示,其中y作为真实值的表示,h为模型预测值的表示。
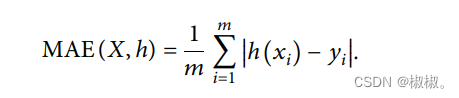
使用的损失函数为混合损失函数。具体公式如下所示。
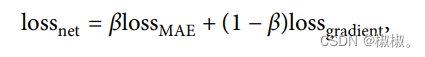
- 贝塔的值是随机的,会根据重构的结果在0-1之间进行不断赋值。损失值与视频的每帧梯度信息相关。该值主要是为了增强将为前后的数据重组的一致性,使得重构后的特征与原始数据的内容尽可能接近。公式6表示了该节点与其前后左右四个节点之间的不同,其中wij为编码后的重构特征。loss计算公式如7所示。
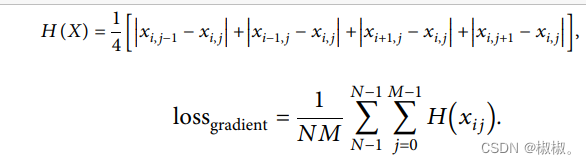
- 模型的优化算法采用:Adam,优化的步长为0.001,参数贝塔1值为0从0.8设置为0.99,学学习率初始化值为:0.001,批处理大小为128,每次处理数据5000.
- 根据训练数据对模型进行训练,模型的训练过程如下所示:
- 第一步,将训练数据输入到训练模型中,将模型参数初始化。
- 第二步,模型的参数前馈计算,损失函数的初始化计算,并使用优化函数对模型进行优化。
- 第四步,重复第二第三步骤,不断对模型进行迭代训练,不断计算损失函数减少真实值与预测值的误差。
4视频关键帧抽取及其多视角融合
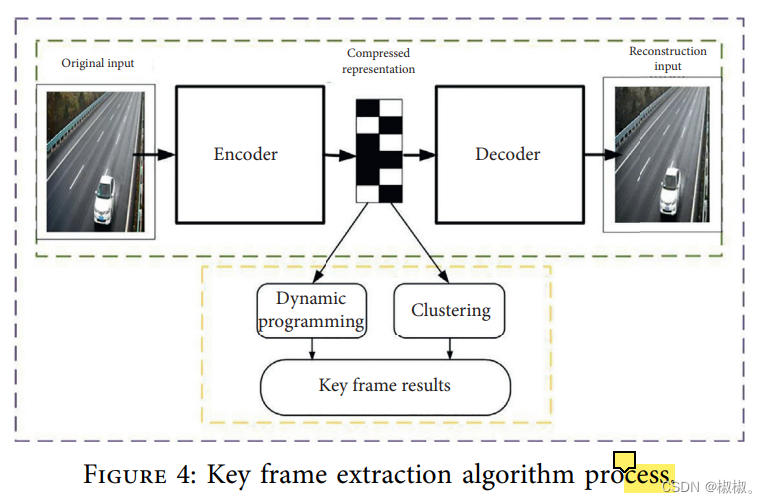
- 需要使用卷积编码来进行特征降维,并对降维后的特征来进行视频关键帧抽取。具体的实现过程如图4所示。首先需要将特征降维,然后对降维后的特征进行关键帧抽取。需要结合动态规划和聚类算法来进行关键帧抽取。
4.1视频帧特征重组
- 为了比较AE及其混合损失函数对于模型的影响,模型使用了两种损失函数来进行训练比较。选择了三种关键帧来进行抽取进而对损失函数进行比较,结果如图5所示。

- 通过比较重构前后的特征的变化,可以发现,使用混合损失函数对关键帧有比较好的影响。通过比较损失函数的平均误差,可以发现,混合损失函数的误差耕地,重构的特征效果更好,重构后的特征更接近原始特征。基于此,本文提出了混合损失函数来进行后续的特征处理。
- 如图6中,前部分44-49帧数据为白色轿车数据,后面928-933帧为红色轿车数据,然后2937-2942帧为多种车辆数据。我们将视频帧数据进行降维,将高纬度数据降到低维度数据,最终使用低维度数据来进行原始视频重构。视频帧数据重构前后结果如图6所示。

- 通过比较重构前后的结果可知,本文提出的模型能够很好地抽取出不同场景下的特征,同时降维后的特征能够很好地重构回原始视频特征。
- 我们重构了视频帧的单张车辆、卡车、多张汽车。从图6中可知能够使用低维度的特征来表示高纬度特征,模型具有更好的泛化能力,因此使用降维后特征来进行关键帧抽取。
4.2视频关键帧抽取
- 本文提出了多视图关键帧特征融合,通过将图像中的三通道进行降维,然后在该维度上进行特征融合。将三通道进行拼接将特征进行融合,然后使用动态规划和聚类方法来进行表示。
- 使用的编程语言为python,所有的数据都是在相同的设备上进行训练的。
- 使用动态规划来进行关键帧抽取,其中比较关键的一步是:计算第一步与最后一步的最短距离。采用了多种方法来计算距离:MI、ED和MD。
- 为了验证算法的有效性,将数据降维与不降维的效果进行了比较,并结合动态规划和聚类算法来进行关键帧抽取来验证算法的有效性。实验结果如表1所示。

- 通过以上的这些处理,视频的存储减少了71.43%,视频维度减少了98.13%。降维后的数据在计算资源和时间消耗上都得到了大幅度的优化。
- MI中距离计算为动态规划,ED中的距离计算为欧几里得距离,MD的距离计算为马氏距离。AE+MI采用自动编码plusMI、Kmeans聚类算法和AE+Kmeans方法。
- 表2展示了使用AE和不使用AE的效果之差。那个使用AE的方法会有更好的互信息,在关键信息提取中消耗的时间更少,提取的关键信息都是均匀分布的。结果表明。使用自编的方式来进行关键信息抽取能够有更高的准确率和更好的表示。

- 从表2和图8中所示,AE+Kmeans方法得到的互信息更好,与只使用Kmeans方法的相比较,同时降维后的数据能够得到更多的又表示意义的结果同时消耗更少的时间。

- 通过以上的经验结果表明,自编码动态规划方法基于互信息进行关键帧抽取自编码plus聚类在关键帧抽取中效果更好。抽取出的关键帧能够重新表示视频特征的变化,抽取的特征均匀分布。与直接动态规划方法相比较,本文提出的方法提高了关键帧抽取的准确率,节约了消耗的时间。
5、结论
- 本文提出了一种针对视频流的基于多视角特征融合的关键帧抽取方法。首先,将视频流数据用于训练自动编码网络。其次,采用网络模型来特征降维,将高纬度数据转化成低维度特征,其次将低维度数据从多视角进行融合。最后,动态规划和聚类算法从融合后的低维数据中来进行关键帧抽取。以上的这些处理过程都是基于自动编码后的低维度数据的,能够有效降低计算时间和资源消耗。与已经存在的方法相比较,本文提出的方法抽取的关键帧更为准确,能够有效解决大规模视频的关键帧抽取。
- 然后,本文提出的方法也需要将输入数据处理成一个特殊的大小。因此,依然需要思考一个更加简单和更快捷的方法来进行关键帧抽取,一不限制视频流输入数据大小的方式。