基于VC+++BP神经网络+车牌识别的车牌定位和识别系统设计与实现(毕业论文+程序源码)
大家好,今天给大家介绍基于VC+++BP神经网络+车牌识别的车牌定位和识别系统设计与实现,文章末尾附有本毕业设计的论文和源码下载地址哦。需要下载开题报告PPT模板及论文答辩PPT模板等的小伙伴,可以进入我的博客主页查看左侧最下面栏目中的自助下载方法哦
文章目录:
1、项目简介
- 车牌识别是现代智能交通系统中的重要组成部分之一,应用十分广泛。
本文对车牌识别系统中的车牌定位,车牌字符分割和车牌字符识别这三个主要技术进行了研究。
本文针对复杂环境下的车牌定位,提出了基于颜色的BP神经网络的定位算法,通过车牌底色库(蓝底)训练网络,使之具备区分蓝色与非蓝色能力,从而实现车牌的定位。车牌字符分割采用改进的垂直投影算法,可以较好、较快地分割出车牌字符的位置。最后字符识别部分仍然采用基于BP神经网络算法,通过建立字符库,训练网络使之具有区分34个不同字符的能力,最终实现车牌字符的识别。
2、资源详情
项目难度:中等难度
适用场景:相关题目的毕业设计
配套论文字数:11925个字24页
包含内容:全套源码+配整论文
开题报告、论文答辩、课题报告等ppt模板推荐下载方式:
3、关键词
BP神经网络、车牌定位、车牌识别、图像投影、字符分割4、毕设简介
提示:以下为毕业论文的简略介绍,项目完整源码及完整毕业论文下载地址见文末。
第一章 引言
1.1车牌识别的研究意义
车牌识别(Vehicle License Plate Recognition ,VLPR)是借助计算机通过运用数字图像处理、计算机视觉、模式识别等技术对路面来往车辆进行自动识别,获取其牌照信息的系统。车牌识别属于计算机视觉、模式识别等领域。
随着现在化交通发展的要求,智能交通将是未来交通系统的发展趋势。而车牌识别是智能交通系统中一个非常关键而重要的部分。
一、车牌识别在高速公路中的应用
高速公路作为公路交通的一个重要组成部分,是为了提高汽车运输的运输能力、速度和安全性方面而专门为汽车交通服务的基础设施。利用各种高新技术,特别是电子信息技术来提高管理效率、交通效率和安全的智能交通已成为当前交通管理发展的主要方向。据调查,在高速公路上已经出现了80%的小车都超速,大量的超速行为给高速公路行车安全带来了极大的隐患。霸占超车道的“蜗牛车,车德差,无视交通法规,不仅极大浪费道路资源,还给道路交通安全埋下安全隐患。这样的“霸道车”问题确实严重,存在很大的安全隐患。据有关数据统计表明,70%以上的高速公路交通事故都是由超速及占道引起的。如何做好高速公路超速及占道管理及处罚,对执法部门来说,取证难却成了执法中最头疼的难题。然而,许多高速公路 应用系统是因为不具备自动识别汽车的“唯一身份证”———牌照号的功能,从而为贪污、舞弊行为留下了可乘之机。汽车牌照自动识别器是近年来逐渐成熟的新型公路机电产品,它的出现,填补了一个采集基础交通信息的空白,为深化高速公路运营管理、提高运营效率提供了可靠依据。所以,在路边或龙门架上安装超速及占道监测设备,实时采集车辆图像及车牌信息并实时进行报警提醒,通过主机管理可以实现在出口自动报警,管理人员即可当场根据车牌信息当场处理,而对其产生强大的威慑力量,促使其自觉减少超速及占道现象,降低高速行车风险,产生极大的社会效益。
二、车牌识别在车辆出入管理中的应用
将车牌识别设备安装于出入口,记录车辆的牌照号码、出入时间,并与自动门、栏杆机的控制设备结合,实现车辆的自动管理。应用于停车场可以实现自动计时收费,也可以自动计算可用车位数量并给出提示,实现停车收费自动管理节省人力、提高效率。应用于智能小区可以自动判别驶入车辆是否属于本小区,对非内部车辆实现自动计时收费。在一些单位这种应用还可以同车辆调度系统相结合,自动地、客观地记录本单位车辆的出车情况。
三、其他应用
如黑名单监视,公安机关可以通过对特定的嫌疑车辆进行监视代替传统的人工监视;
一些机关的自动放行,对属于本单位的车辆进行识别。
此外,还有牌照的自动登记,停车场 的自动计时收费等等。
良好的车牌识别系统应用于交通系统后,可以使交通更加顺畅,提高效率,节省大量的人力物力。此外车牌识别属于模式识别领域,它的研究有利于推动计算机视觉的发展。
1.2车牌识别系统现状
车牌识别技术自上个世纪80年代以来,人们就对它进行了广泛的研究,目前国内外已经有众多的算法,一些实用的VLPR技术也开始用于车流监控、出入控制、电子收费、移动稽查等场合。然而,无论是VLPR算法还是VLPR产品几乎都存在一定的局限性,都需要适应新的要求而不断完善,如现有系统几乎都无法有效解决复杂背景下的多车牌图像分割定位与有效识别的技术障碍,另外也很难适应全天候复杂环境及高速度的要求。
车牌字符识别实际上是依附在车牌上的印刷体文字的识别,能否正确识别不仅是文字识别技术的问题,还是考虑其载体——车牌区域的影响。车牌字符识别技术是文字识别技术与车牌图像自身因素协调兼顾的综合性技术。由于摄像机的性能、车牌的整洁度、光照条件、拍摄时的倾斜角度及车辆运动等因素的影响使牌照中的字符可能出现比较严重的模糊、歪斜、缺损或污迹干扰,这些都给字符识别带来了难度。
目前的车牌识别方法主要是针对车辆自动缓停收费、停车场管理等场合,所监视的区域一般只有单一车辆,背景也比较简单。而如今的许多实际应用场合,监视区域比较复杂,现有的方法无法直接应用。比如在移动交警稽查、高速公路的监视与监控、城市交通要道的监视与监控,所监控的区域一般会同时出现多辆汽车,背景也比较复杂,有广告牌、树木、建筑物、斑马线以及各种背景文字等。所以本课题针对这种情况创新性的提出了一种复杂背景下多车牌定位分割与识别方法,并考虑了彩色分割与ColorLP算法,这也是当前车牌图像识别的发展趋势。
当然,车牌识别系统的具体应用发展也很迅猛,从原来的停车静止拍摄场景应用,如收费站、停车场等,发展到移动公路车辆稽查、违章自动报警、超载闯红灯等实时监控场合应用,增加神经网络自适应识别学习训练功能,对于系统响应的速度、网络化、智能化、识别成功率等实用化要求也越来越高。随着上述核心技术的研究发展,应用领域和功能等也获得大幅提高。但车牌识别的实用化研究仍然有很长的路要走。
目前,车内市场上有成熟产品投入使用的公司也很多。
如:北京文通车牌识别系统,深圳海川车牌识别,深圳信路通等等。
据市场调查机构 IMS发布的报告,车牌自动识别技术在美国市场一直呈现增长态势,经历08经济危机后,美国的大规模车辆识别项目又重新启动。
目前,车牌识别主要有以下几种识别方法:模板匹配法、特征统计匹配法和神经网络识别法。模板匹配法对规整字符的识别率比较高,但在字符变形等情况下,识别能力有限;特征统计
匹配法在实际应用中,当字符出现断裂、部分缺失时,识别效果不理想; 神经网络识别能有效识别解析度较高和图像比较清晰的车牌,具有强大的分类能力,容错性,鲁棒性和非线性映射能力,汽车牌照中的字符识别很多都是采用神经网络来实现,其中BP 神经网络作为神经网络的精华,是迄今为止,应用最为广泛的网络算法。
1.3车牌识别系统研究内容
本文车牌字符识别技术主要包括三部分内容:车牌定位、字符分割及字符识别。
车牌通过摄像机等电子设备,变成一幅图像后,如何在这幅图像中准确找到车牌,是整个车牌自动识别系统的关键。目前的车牌都有一定特点,如车牌底色、形状等都有国家标准,可以根据这些标准,加上图像处理中对颜色、形状(车牌主要是长方形)的处理方法,准确定位车牌位置。
车牌底色由于光照的影响,实际拍摄下来的车牌,其颜色与国家标准相比,会有些失真,通过建立车牌颜色库,利用BP神经网络,对失真的车牌底色作训练,使系统对车牌失真有更好的适应能力,从而更准确地定位车牌位置。
车牌定位后,要对车牌进行一些预处理,如去除噪声,边缘细化等。然后对车牌字符进行切分处理。本文字符切分处理采用基于投影特征值的方法,对于数字及字符,由于它们都属于连体字,因此只需在字符或数字之间找到一条无边的空白区(窄的区域),即可实现数字及字符之间的切分处理。
将车牌字符切分之后,最后是字符和数字的识别。车牌字符和数字是由国家制定的标准字符,本文采用基于BP神经网络算法,通过建立字符库,训练网络使之具有区分34个不同字符的能力,最终实现车牌字符的识别。
1.4章节安排
本论文共分为5章。
第一章引言主要介绍了车牌自动识别系统的研究意义,研究现状,研究内容。简要地介绍了车牌识别的一些常用方法,然后概述本论文的排版结构(即章节安排)。
第二章基于颜色BP神经网络 车牌定位,分别介绍了彩色图像BMP格式文件的图像显示方法,RGB色彩空间到CR CB色彩空间的转换,然后介绍BP神经网络的基本原理,最后介绍运用基于CR CB色彩空间的BP神经网络车牌定位的方法。
第三章,车牌字符定位与分割。首先介绍图像投影技术,然后介绍基于图像投影技术的车牌分割技术,最后介绍基于图像掠影技术车牌字符分割的实现方法。
第四章,基于颜色与BP神经网络的车牌系统。首先,介绍车牌字符库的建立,然后介绍基于BP神经网络字符识别,最后介绍基于这种技术的实现。
第五章,即最后一章为结论。把以上提出的种种方案编程实现后,由数张车牌图像作为结果,粗略感知这种 方法的可行性与否,并说明一些简单的意义,最后对指导老师表示感谢。
第二章 基于颜色和BP神经网络的车牌定位
2.1彩色图像的显示
彩色图像在视觉上较灰度图像更接近实物。车牌识别系统中,车牌的获取一般通过视频流来得到。然后把得到的含车牌的帧转换成彩色图像。常见的彩色图像格式主要有以下几种:
Jpeg,jpg,png,bmp。每种彩色图像的格式在各个领域上都有自己的优势与劣势。但是,在windows上,要显示成像让别人能看到,就要先转换成BMP格式(例如,打开jpg图像的时候,系统内部把每个像素还原了,这个处理类似bmp格式)。
在本论文中,我选取24位真彩图bmp格式作为原始车辆图像格式(即所有的待识别的原始车辆图像格式均为统一标准的640*480 bmp格式),其他彩色的图像不作研究,并且图像的格式问题与本论文的车牌定位,字符分割、字符识别等核心算法部分无关。
对任意的彩色图像,我们主要关心的几个元素有以下:图像的大小尺寸,图像各个像素的大小,图像的头信息等。
对于一个bmp格式的彩色图像也不例外,我们最关心的也是图像的大小尺寸(即长和宽或高度和宽度),每个像素的RGB大小。假如我们知道这些关键值之后,如(图像的高度大小是hImage,宽度大小是wImage,图像的像素每个RGB大小依次保存在数组Image[]中),那么这幅彩色图像的显示将变得十分简单,我们只要在相应的位置,显示出相应的像素即可。
所幸,BMP格式文件结构并不复杂。
典型的BMP图像文件由四部分组成:
1:位图头文件数据结构,它包含BMP图像文件的类型、显示内容等信息。
2:位图信息数据结构,它包含有BMP图像的宽、高、压缩方法,以及定义颜色等信息;
3:调色板这个部分是可选的,有些位图需要调色板,有些位图,比如真彩色图(24位的BMP)就不需要调色板;
4:位图数据,这部分的内容根据BMP位图使用的位数不同而不同,在24位图中直接使用RGB,而其他的小于24位的使用调色板中颜色索引值。
所以,通过读取BMP图像文件的各个部分,完全可以得到想要的数据。
在实验过程中,取得BMP图像的数据后在相应的位置把对应的像素RGB显示出来即可。下图是一BMP格式车牌的图像显示后截图。

2.2 RGB到Cr Cb色彩空间的转换
RGB色彩空间根据实际使用设备系统能力的不同,有各种不同的实现方法。截至2006年,最常用的是24-位实现方法,也就是红绿蓝每个通道有8位或者256色级。基于这样的24-位RGB 模型的色彩空间可以表现 256×256×256 ≈ 1670万色。一些实现方法采用每原色16位,能在相同范围内实现更高更精确的色彩密度。这在宽域色彩空间中尤其重要,因为大部分通常使用的颜色排列的相对更紧密。
在RGB色彩空间中,三个颜色的重要程度相同,所以需要使用相同的分辨率进行存储,最多使用RGB565这样的形式减少量化的精度,但是3个颜色需要按照相同的分辨率进行存储,数据量还是很大的。所以,利用人眼睛对亮度比对颜色更加敏感,将图像的亮度信息和颜色信息分离,并使用不同的分辨率进行存储,这样可以在对主观感觉影响很小的前提下,更加有效的存储图像数据。
YCbCr色彩空间和它的变形(有时被称为YUV)是最常用的有效的表示彩色图像的方法。Y是图像的亮度(luminance/luma)分量,使用以下公式计算,为R,G,B分量的加权平均值: Y = kr R + kgG + kbB 其中k是权重因数。
上面的公式计算出了亮度信息,还有颜色信息,使用色差(color difference/chrominance或chroma)来表示,其中每个色差分量为R,G,B值和亮度Y的差值: Cb = B -Y
Cr = R -Y
Cg = G- Y
其中,Cb+Cr+Cg是一个常数(其实是一个关于Y的表达式),所以,只需要其中两个数值结合Y值就能够计算出原来的RGB值。所以,我们仅保存亮度和蓝色、红色的色差值,这就是(Y,Cb,Cr)。
相比RGB色彩空间,YCbCr色彩空间有一个显著的优点。Y的存储可以采用和原来画面一样的分辨率,但是Cb,Cr的存储可以使用更低的分辨率。这样可以占用更少的数据量,并且在图像质量上没有明显的下降。所以,将色彩信息以低于量度信息的分辨率来保存是一个简单有效的图像压缩方法。
在本论文中,为了以较小数据尽量得到较全面的像素信息,我对RGB图像作了色彩空间的转换,并且只保留YCbCr色彩空间中的红色及蓝色分量。具体做法如下。
Cr= 128-37.797R/255-74.203G/255+112B/255;
Cb= 128+112R/255-93.768G/255-18.214B/255;
2.3 BP神经网络原理
BP(Back Propagation)网络是1986年由Rumelhart和McCelland为首的科学家小组提出,是一种按误差逆传播算法训练的多层前馈网络,是目前应用最广泛的神经网络模型之一。BP网络能学习和存贮大量的输入-输出模式映射关系,而无需事前揭示描述这种映射关系的数学方程。
一个神经网络的结构示意图如下所示。
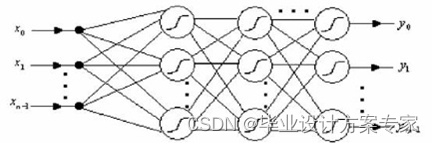
BP神经网络模型拓扑结构包括输入层(input)、隐层(hide layer)和输出层(output layer)。输入层神经元的个数由样本属性的维度决定,输出层神经元的个数由样本分类个数决定。隐藏层的层数和每层的神经元个数由用户指定。每一层包含若干个神经元,每个神经元包含一个而阈值 ,用来改变神经元的活性。网络中的弧线 表示前一层神经元和后一层神经元之间的权值。每个神经元都有输入和输出。输入层的输入和输出都是训练样本的属性值。
对于隐藏层和输出层的输入 其中, 是由上一层的单元i到单元j的连接的权; 是上一层的单元i的输出;而 是单元j的阈值。
神经网络中神经元的输出是经由赋活函数计算得到的。该函数用符号表现单元代表的神经元活性。赋活函数一般使用simoid函数(或者logistic函数)。神经元的输出为:
除此之外,神经网络中有一个学习率(l)的概念,通常取0和1之间的值,并有助于找到全局最小。如果学习率太小,学习将进行得很慢。如果学习率太大,可能出现在不适当的解之间摆动。
算法基本流程就是:

1、初始化网络权值和神经元的阈值(最简单的办法就是随机初始化)
2、前向传播:按照公式一层一层的计算隐层神经元和输出层神经元的输入和输出。
3、后向传播:根据公式修正权值和阈值
直到满足终止条件。
2、关于终止条件,可以有多种形式:
§ 前一周期所有的 都太小,小于某个指定的阈值。
§ 前一周期未正确分类的样本百分比小于某个阈值。
§ 超过预先指定的周期数。
§ 神经网络的输出值和实际输出值的均方误差小于某一阈值。
一般地,最后一种终止条件的准确率更高一些。
在实际使用BP神经网络的过程中,还会有一些实际的问题:
1、 样本处理。对于输出,如果只有两类那么输出为0和1,只有当 趋于正负无穷大的时候才会输出0,1。因此条件可适当放宽,输出>0.9时就认为是1,输出<0.1时认为是0。对于输入,样本也需要做归一化处理。
2、 网络结构的选择。主要是指隐藏层层数和神经元数决定了网络规模,网络规模和性能学习效果密切相关。规模大,计算量大,而且可能导致过度拟合;但是规模小,也可能导致欠拟合。
3、 初始权值、阈值的选择,初始值对学习结果是有影响的,选择一个合适初始值也非常重要。
4、 增量学习和批量学习。上面的算法和数学推导都是基于批量学习的,批量学习适用于离线学习,学习效果稳定性好;增量学习使用于在线学习,它对输入样本的噪声是比较敏感的,不适合剧烈变化的输入模式。
5、 对于激励函数和误差函数也有其他的选择。
总的来说BP算法的可选项比较多,针对特定的训练数据往往有比较大的优化空间。
2.4 基于Cr Cb的BP神经网络车牌定位

图为车牌底色部分样本
建立车牌底色库,在本论文中仅对蓝底白字车牌进行研究。对于这些车牌样本,将其从RGB色彩空间转换为得到其Cr Cb红色及蓝色分量。对车牌样本每个像素,均可得到其CR CB。而我们关心的只是两种像素,即蓝色非蓝色像素。对于蓝色的像素,在转换为CR CB 后其对应的BP神经网络映射关系为输出为1.非蓝色的像素,在转换为CR CB后相对应的BP映射为输出为0.由于BP神经网络要求输入值0到1.所以CR CB还需作简单的处理,把它转为符合要求的输入。
到此,用于进行车牌定位的BP神经网络模型有了输入层及输出层。即,输入层含两个神经结点(某像素的CR CB分量),输出层仅一个神经结点(对应逻辑关系为这个像素在视觉上是否为蓝色)。中间层设计为仅含4结点的一层。
设计好BP神经网络模型后,将车牌的底色投入训练,在网络收敛后可用(实际在论文完成的过程中,并没有出现收敛,而是达到训练次数后停止训练,这个次数2552555是在实验过程中测试后决定的,不一定最优)。这时的神经网络可以认为是已具备区分蓝色及非蓝色的能力了(对于训练得到的宝贵权值保存到一个文件CharBpNet.txt中,以便在恢复网络时直接读取而节省大量的训练时间)。然后对任意的一张含车牌的图像每个像素,将它投入网络动作,如果网络认为是蓝色的(结点输出为范围在0.8—1.0间的),那么将此像素映射成255,如果网络认为非蓝色的(结点输出范围在0—0.8间),那么将此像素映射成0.这样我们可以得到除了一张二值图像(由上述映射过来)外,还可以将车牌从复杂的自然图像分离开来(当然这是从十分理想的角度出发的,实际上当车辆颜色也是蓝色的时候是无法分离的)。

左图为原始的自然车辆图像,右图是经BP神经网络动作后得到的二值图像。
从以上两图中,可以看到一幅自然图像经处理后分离得到其里面的车牌了。而车牌定位好后字符的大体位置也就定下来了。
第三章 车牌字符定位与分割
3.1 图像投影技术
图像投影技术一般分为水平投影和垂直投影。所谓投影就是对图像的某种特征的统计,然后以直方图形式反映其特征强度。一般是对二值图像而用的,水平方向的投影就是每行的非零像素值的个数,在这里就是1或者255,垂直投影就是每列图像数据中非零像素值的个数。
图像的投影技术主要应用在物体的检测,人脸检测,车牌定位,字符分割等方面。能过对其二值图像的水平或垂直或水平加垂直的投影可以有效地分离其特征,得到想要的数据。
通常投影后的数据特征,我们采用直方图来反映。
所谓直方图,即柱状图或称质量分布图。是一种统计报告图,由一系列高度不等的纵向条纹或线段表示数据分布的情况。直方图有一般有以下几种:稳定型,孤岛型,双峰型,折齿型,陡壁型,平顶型等。
3.2 基于图像投影技术的车牌分割
由于车牌字符在车牌上,所以这部分可以认为是对字符的粗定位或车牌的精确定位。在设计上算法上可以这样做。对二值图像分别作水平和垂直方向的投影,得到其直方图分布,然后分别在波峰的地方作直线,这样水平方向和垂直方向共计四条直线,它们相交形成一矩形,这个矩形就是车牌的大概位置了。
将要进行水平和垂直投影的二值图像如下图:

对于要进行车牌定位的一幅二值图像,理想的水平或垂直投影后,期待的直方图应该是两边低,中间突然高的形状。
下面分别介绍水平 ,垂直方向的投影技术。

按行累加每个像素点的灰度值做投影,横坐标为灰度累加的和,纵坐标为图像的行数,即可确定车牌区域上下边缘。左上图 给出了灰度投影图其投影值整体分布情况。如左上图 所示,车牌区域的下边缘为: 第一个从下往上投影最大波峰值对应的行号; 同样车牌区域上边缘为:从上往下出现的第一个投影波峰值为最大的行号。因此汽车牌照区域是两个行
号之间的位置。水平分析算法如下:
- 从下向上逐行扫描图像,记下每行中灰度值为 255 的像素点的个数;
- 找到第一个灰度值为 255 的像素点的个数大于 某个阈值的行(并且紧挨着的若干行都满足个数大于某阈值),记录下行号,即为车辆牌照最下边缘;
- 然后继续扫描,找到第一个灰度值为 255 的像素点的个数小于 阈值 的行(并且紧挨着的若干行都满足个数大于某阈值),记录下行号,即为车辆牌照的最上边缘;
- 这时不再继续扫描,根据记录的两个行号,对原始图像进行裁剪;
- 得到裁剪后的图像,即为水平方向定位的牌照图像区域。
其垂直投影算法也类似。
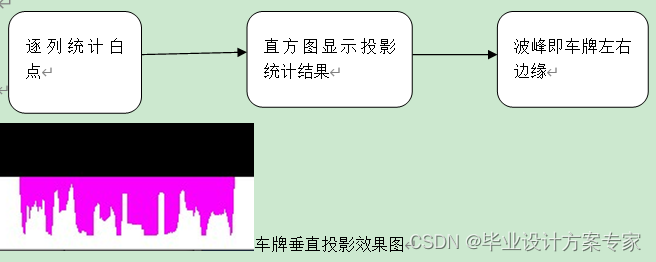
按列累加每个像素点的灰度值做投影,横坐标为灰度累加的和,纵坐标为图像的行数,即可确定车牌区域左右边缘。上图 给出了灰度投影图其投影值整体分布情况。如上图 所示,车牌区域的右边缘为: 第一个从右往左投影最大波峰值对应的行号; 同样车牌区域左边缘为:从左往右出现的第一个投影波峰值为最大的行号。因此汽车牌照区域是两个行
号之间的位置。垂直分析算法如下:
- 从左向右逐列扫描图像,记下每行中灰度值为 255 的像素点的个数;
- 找到第一个灰度值为 255 的像素点的个数大于 某个阈值的行(并且紧挨着的若干列都满足个数大于某阈值),记录下行号,即为车辆牌照最右边缘;
- 然后继续扫描,找到第一个灰度值为 255 的像素点的个数小于 阈值 的行(并且紧挨着的若干列都满足个数大于某阈值),记录下行号,即为车辆牌照的最左边缘;
- 这时不再继续扫描,根据记录的两个列号,对原始图像进行裁剪;
- 得到裁剪后的图像,即为垂直方向定位的牌照图像区域。
分别投影后效果如下图:

值得一提的是并不是所有的自然车辆图像经BP神经网络动作后都那么完美的,这也是为什么在求车牌各个边缘的时候设定一个阈值(并且紧挨着的若干行都满足个数大于某阈值)的原因。如下图

经过对车牌 的二值图像的水平和垂直投影后,我们已经得到了车牌的精确位置,也即字符的所在区域。至此,我们可以把注意力从原始的二值图像集中到二值图像中的车牌局部区域来(即如何从车牌中分割出 每个字符)。
字符粗略位置确定后可对车牌字符进行切分处理。
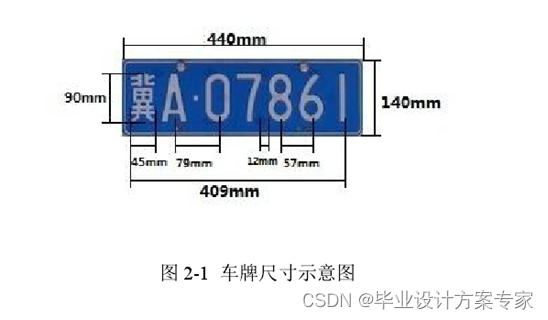
车牌的字符均有一定要标准,见下图。
除要可用比例的方法来分割外,本文采用一种适应性更好的基于投影的分割技术。
字符切分处理采用基于投影特征值的方法,对于数字及字符,由于它们都属于连体字,因此只需在字符或数字之间找到一条无边的空白区(窄的区域),即可实现数字及字符之间的切分处理(当然这也是出于理想情况的)

显然要在上图中分割出字符,只需在车牌内(白色矩形)对字符作像素为255的垂直投影。具体方法如下:

按列累加每个像素点的灰度值做投影,横坐标为灰度累加的和,纵坐标为图像的列数,即可确定字符区域左右边缘。
垂直分析算法如下:
- 从左向右逐列扫描图像,记下每列中灰度值为0的像素点的个数;
- 找到第一个灰度值为 0 的像素点的个数大于 某个阈值的列(并且紧挨着的若干列都满足个数大于某阈值),记录下列号,即为一个字符最左边缘;
- 然后继续扫描,找到第一个灰度值为 0 的像素点的个数小于 阈值 的列(并且紧挨着的若干列都满足个数大于某阈值),记录下列号,即为一字符照的最右边缘;
- 这时继续扫描,依次记录的两个列号,对原始图像进行裁剪;
- 得到裁剪后的图像,即为垂直方向定位的字符区域。
然后将得到 的各个字符,这时只要将每个字符的区域坐标保存好即可。

效果如上图
第四章 基于颜色与BP神经网络的车牌识别系统
4.1 车牌字符库的建立
字符库的建立是为字符的识别作准备的,字符库要求每个字符按一定标准保存,如保存格式一致,大小规格相同,每个字符的数目相同等等。在论文中,只对数字及字母作研究,对汉字不作研究,所以共计34个不同各类的字符。数字0和字母o,数字1和i为均认为是同一字符。每个字符用程序获取10个不尽相同的字符。字符库的建立是为了训练BP神经网络的样本。
4.1.1图像的缩放技术
在计算机图像处理中,图像缩放是指对数字图像的大小进行调整的过程。图像缩放是一种非平凡的过程,需要在处理效率以及结果的平滑度和清晰度上做一个权衡。当一个图像的大小增加之后,组成图像的像素的可见度将会变得更高,从而使得图像表现得“软”。相反地,缩小一个图像将会增强它的平滑度和清晰度。
图像缩放的算法主要有近邻插值和双线性插值。
在本论文研究中,我采用近邻插值方法将每个字符都归一化到6*12的统一规格中去。
所谓的最近邻插值,通俗理解就是将每一个原像素原封不动地复制映射到扩展后对应四个像素中。效果见下图。
归一化前的各字符。
归一化后各字符依次是
4.1.2字符的保存
首先给字符编号,0—9分别编号为00—09。A—Z分别编号为10–33
在本论文中,字符的保存格式为.raw原始图像数据文件。命名依次为000.raw 到339.raw。
即不超过340的三位数加格式名.raw。前两位数代表这个字符的编号,第三位数n代表这字符是第n张字符。如某字符某名为089.raw即意味着这字符代表数字8,它在库中是第9张了(从第0张开始计数)。又如330.raw代表着这字符为字母Z,它是第0张.
为了使字符库的字符和待识别的字符尽量保持一致性,字符的建立是通过程序的方法获得的。具体做法如下:
- 分割车牌中的每个字符。
- 将各个字符逐一归一化到6*12统一标准
- 将归一化的字符按一定的标准命名保存即可。
最后得到了340张不同的共34种的格式为.raw的文件。用程序显示这些字符库如下图。

4.2 基于BP神经网络的字符识别
建立字符库后,设计识别字符的BP神经网络。
首先设计输入层及输出层。字符库中每个标本,均是612的标准二值图像。对字符的特征,我采用像素法。即某个字符的像素是255时,神经结点输入为0.9,像素值是0时,神经结点输入为0.1.这样输入层就有612共72个结点。输出层采用了34结点,如当导师信号为A编号10时,就在第10个结点设为0.9.其他均为0.1.(用0.1 0.9代替0和1已被许多学者证明是更精确)。
到此,用于进行车牌定位的BP神经网络模型有了输入层及输出层。即,输入层含72个神经结点(对应字符的每个像素),输出层34个神经结点(对应逻辑关系为属于编号第N个字符)。中间层设计为仅含50结点的一层(这个是实验过程中得出的一经验值,不保证最优)
设计好BP神经网络模型后,将车牌的字符投入训练,在网络收敛后可用(实际在论文完成的过程中,并没有出现收敛,而是达到训练次数后停止训练,这个次数10000*72是在实验过程中测试后决定的,同样不保证最优)。这时的神经网络可以认为是已具备区分34个不同字符的能力了(对于训练得到的宝贵权值保存到一个文件CharBpNet.txt中,以便在恢复网络时直接读取而节省大量的训练时间)。然后对任意的一个从车牌分割得到的字符进行归一化之理后,依次假设其分别是编号0到33.并且求出每个编号对应的误差,最后在34个不同的误差中找出最小的那个编号,找到的编号即对应的字符了。如:某分割的字符投入动作后得到的最小误差编号为10,那么 认为这个字符为A。
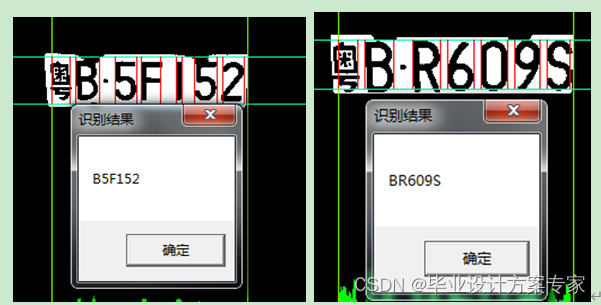
把从车牌分割下来的字符全部投入动作后得到的字符串即车牌的号码了。效果如下图:
第五章 结论
本论文《基于颜色和BP神经网络的车牌定位和识别系统》基本完成了,实验也达到预期的期望。
车牌定位方面,由于采用基于颜色定位方法,要求要定位的车牌图像质量较清晰,车牌底色为蓝色或和标准蓝色相差不大,这时BP网络能非常有效地区分蓝色与非蓝色,从而定位。但也常有无法定位的情况,当车身也是蓝色时,BP网络必定无法把车牌从图像中分离出来。
字符分割方面,采用基于垂直投影特征值的方法,能有效地分割字符。但也有分割错误的情况。如在车牌定位不够精确或定位出来的车牌有噪点时,无法在字符或数字之间找到一条无边的空白区(窄的区域),此时往往会分割错误(一字符可能分为多个,噪点也可能认为是字符)。
字符识别方面,在本论文中,实验过程发现当车牌定位和字符分割均能得到较好结果时大多数情况下均能有效地识别。但是字符分割错误(或不精确)或要识别噪点较多或字符倾斜较严重时往往会出现错识甚至拒识。比如B有可能错误为8,B错识为R等等。
参考资料
[1] 百度百科 车牌识别系统 http://baike.baidu.com/view/6256962.htm;
[2] 博BP神经网络学习 http://blog.csdn.net/sealyao/article/details/6538361
[3] 数字图像处理教程/常青编著.—上海:华东理工大学出版社,2009;
[4] 计算机视觉与模式识别[专著]/郑南宁著.—北京:国防工业出版社,1998;
[5] 精通Visual C++数字图像处理技术与工程案例/王占全,徐慧编著.—北京
[6] 妙趣横生的算法:C语言实现/杨峰编著.—北京
[7] 神经网络控制与MATLAB仿真=Neural networks control and MATLAB simulation/张泽旭编著.—哈尔滨
[8] 混合神经网络技术/田雨波编著.—北京
[9] 神经网络权值直接确定法=Weights direct determination of neural networks/张雨浓,杨逸文,李巍著
[10] 基于计算智能的产品概念设计及应用/薄瑞峰著.—北京
[11] 人工智能导论/王万良编著.—3版.—北京
[12] 图像情感语义分析技术/陈俊杰[等]著.—北京
致 谢
省略
5、资源下载
本项目源码及完整论文如下,有需要的朋友可以点击进行下载。如果链接失效可点击下方卡片扫码自助下载。
| 序号 | 毕业设计全套资源(点击下载) |
|---|---|
| 本项目源码 | 基于VC+++BP神经网络+车牌识别的车牌定位和识别系统设计与实现(源码+文档)_VC++_BP_车牌定位和识别系统.zip |