阅读时间:2023-10-28
1 介绍
年份:2015
作者:Quoc V. Le、Navdeep Jaitly、Geoffrey E. Hinton,谷歌团队
期刊:Computer Science
引用量:812
这篇论文的主题是关于使用修正线性单元(ReLU)组成的递归神经网络(RNN)的初始化及其与长短期记忆(LSTM)RNN的性能进行比较。论文开头提到了训练RNN的困难之处,如梯度消失和梯度爆炸,以及已有的优化技术和网络架构用于克服这些挑战。作者提出了一种更简单的方法,使用单位矩阵或其缩放版本对RNN进行初始化,成为IRNN。他们发现,这种初始化方法在各种基准测试中表现与标准的LSTM实现相当,包括具有长期时间结构的玩具问题、语言建模和语音识别。实验表明,使用单位矩阵初始化的具有ReLU的RNN在涉及长期依赖的任务上表现良好,并且可以达到与LSTM相近的结果。论文还探讨了在RNN中使用修正线性单元的方法,并将其与其他激活函数进行了比较。这项研究揭示了LSTM的成功因素,以及在RNN中使用ReLU的潜力。
通过一个小的标量对单位矩阵进行缩放是一种有效的机制来忘记长程影响。
创新点来源:【26】
本文的网络使用修正线性单元,而单位矩阵仅用于初始化。
2 创新点
- 文章提出了一种使用矩阵初始化的方法来初始化由修正线性单元 (ReLU) 组成的循环神经网络 (RNN)。这种方法简单且易于实现,能够解决RNN训练中的梯度消失和梯度爆炸问题。
- 通过在多个基准测试中进行实验证明,使用矩阵初始化的ReLU RNN在处理包含长期依赖关系的任务时表现良好,并且能够达到与标准实现的长短期记忆 (LSTM) RNN相当的结果。
- 讨论了在RNN中使用ReLU和其他激活函数的比较,并讨论了LSTM的成功因素和ReLU在RNN中的潜力。
3 算法
(1)使用正确定义的权重初始化,包括将递归权重矩阵初始化为恒等矩阵,偏置初始化为零。
(2)通过时间反向传播(backpropagation through time)来计算权重的误差导数。
(3)对于每个小的mini-batch序列,更新权重。
(4)使用Rectified Linear Units (ReLU)作为激活函数来构建RNN,初始化时将隐藏状态向量复制为上一个隐藏向量,然后加上当前输入的影响,并将所有负状态替换为零。
(5)当没有输入数据时,经过初始化为恒等矩阵的ReLU RNN(称为IRNN)的隐藏单元状态保持不变。
(6)利用反向传播通过时间将隐藏单元的误差导数传播回来时,只要没有额外的误差导数添加,它们保持不变。这与LSTM的行为相同,当它们的遗忘门设置为没有衰减时,可以很容易地学习非常长期的时间依赖性。
(7)对于表现出较少长期依赖的任务,通过将恒等矩阵进行小的标量缩放可以有效地忘记长期作用。这与LSTM的行为相同,当它们的遗忘门设置为记忆快速衰减时。
4 实验分析
基准模型:RNN和LSTM
基准数据集:加法、图像、语言模型、语音
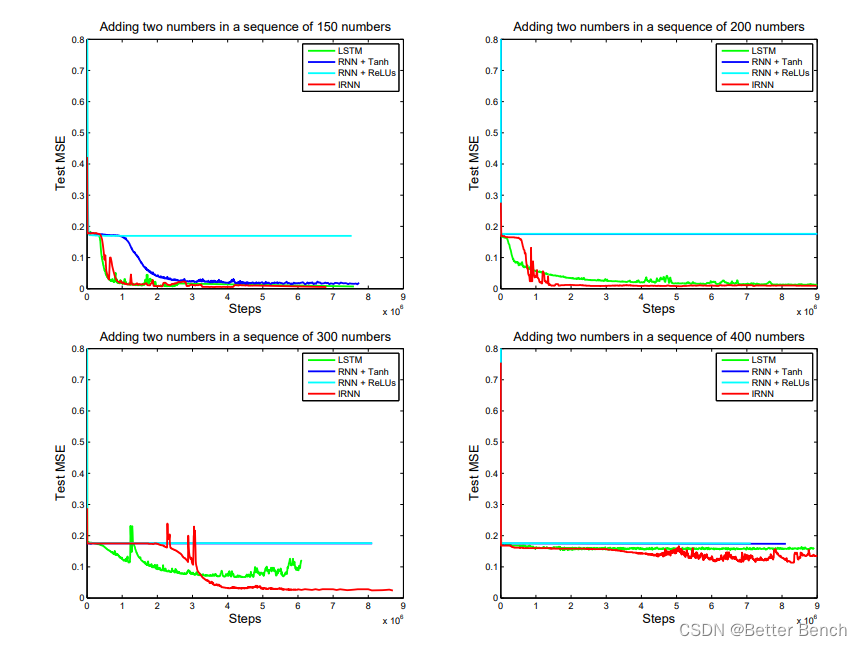
(1)加法
随着序列长度T的增加,问题变得更加困难,因为输出与相关输入之间的依赖关系变得更加遥远。
随着变化T的值,我们注意到当T约为150时,LSTMs和RNNs都开始遇到困难。,IRNNs的收敛性和LSTMs一样好。这是由于每个LSTM步骤比一个IRNN步骤更昂贵(至少4倍)。
(2)图像
使用标准的扫描线像素顺序,实验结果表明,RNN效果不佳,而IRNN实现了3%的测试错误率,比大多数现成的线性分类器要好。LSTM的表现一如既往的好。
(3)语言模型
这些结果表明IRNNs在这个大规模任务上的性能更接近LSTMs的性能,而不是RNNs的性能。
(4)语音
使用iRNN的性能远远优于使用tanh单元的RNN,并且与LSTM的性能相当。
5 思考
缺少代码,没有明白如何去实现,模型没有写清楚,都没有建立数学模型。
第一步的工作“权重初始化,包括将递归权重矩阵初始化为恒等矩阵,偏置初始化为零。”没明白怎么实现。