【人脸识别7】haar+CART+Adaboost+Cascade训练过程分析
人脸检测分类器可以总结为:
人脸检测分类器=haar-like (特征)+CART(弱)+ Adaboost(强) + Cascade(级联)
下面将从以下几个问题入手,各个击破:
1.什么是Haar特征?为什么使用feature而不是直接使用pixels?
2.什么是CART分类回归树?CART在本节的训练中有何作用?
3.什么是弱分类器?在本节中,具体是指什么?如何得到弱分类器(CART)?
4.强分类器是什么?如何训练得到(ADaboost)?结构如何?
5.Cascade是什么?有什么作用?
6.整个人脸检测分类器的组成?详述训练过程 haar+CART+adaboost+cascade?
一、带着问题来学习
1.什么是Haar特征?为什么使用feature而不是直接使用pixels?
Haar特征:
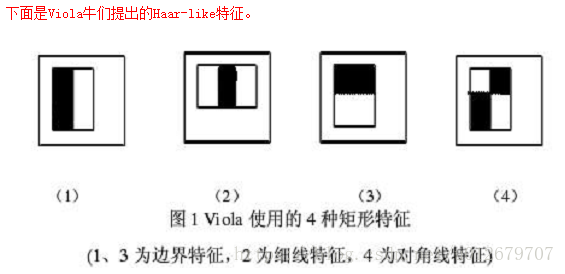
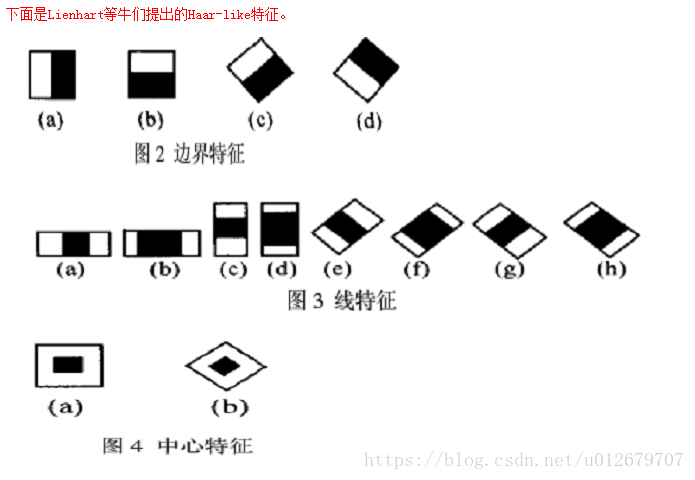
为什么使用feature而不是直接使用pixels?
我们的目标检测过程是根据简单特征的值对图像进行分类。使用特征而不是直接使用像素有很多动机。
(1)特征可以用来编码特定领域的知识,而这些知识是很难用有限数量的培训数据来学习的。
(2)对于这个系统使用特征,还有第二个关键的动机:基于特征的系统的运行速度比基于像素的系统要快得多。
在本分类器中,所涉及的haar特征具体参数如下:
typedef struct CvTHaarFeature
{
char desc[CV_HAAR_FEATURE_DESC_MAX];
int tilted;/*haar特征包括一个tilted标志,tilted = 0 是直立型特征; tilted =1 是45度特征
特征是2-3 个带权重的矩形,如果rect[2].weight != 0 则特征是3个矩形,否则是2 个矩形*/
struct
{
CvRect r; //矩形
float weight; //权值
} rect[CV_HAAR_FEATURE_MAX];
} CvTHaarFeature; //haar特征
typedef struct CvFastHaarFeature
{
int tilted;
struct
{
int p0, p1, p2, p3;
float weight;
} rect[CV_HAAR_FEATURE_MAX];
} CvFastHaarFeature;
typedef struct CvIntHaarFeatures
{
CvSize winsize;
int count;
CvTHaarFeature* feature;
CvFastHaarFeature* fastfeature;
} CvIntHaarFeatures;
2、什么是CART分类回归树?CART在本节的训练中有何作用?
本节中,所用的CART(分类回归树)是一种决策树学习算法。分类回归树(classification and regression tree,CART)模型由Breiman等人在1984年提出,是应用广泛的决策树学习方法。CART同样由特征选择、树的生成以及剪枝组成,既可以用于分类也可以用于回归。
CART的算法思想是:CART算法采用的是一种二分递归分割的技术,将当前样本分成两个子样本集,使得生成的非叶子节点都有两个分支。因此CART实际上是一棵二叉树。
特点:当CART是分类树的时候,采用GINI值作为分裂节点的依据,当CART作为回归树的时候,使用样本的最小方差作为分裂节点的依据
具体关于CART的介绍,可看:https://blog.csdn.net/gzj_1101/article/details/78355234
在本节中,我们主要使用CART分类功能。假设我们使用三个Haar-like特征f1,f2,f3来判断输入数据是否为人脸,可以建立如下决策树:(下图相当于是CART tree:较优弱分类器)
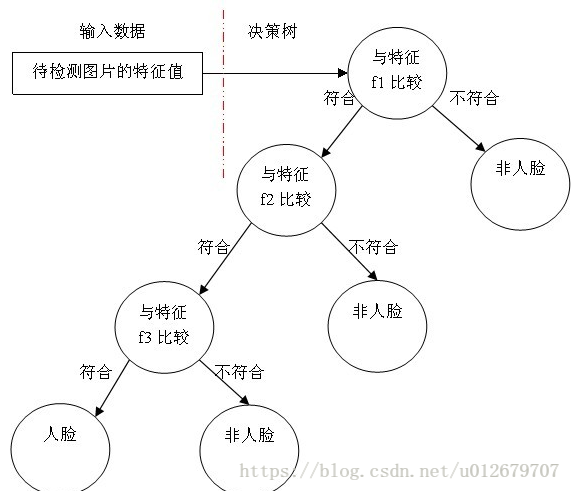
可以看出,在分类的应用中,CART每个非叶子节点都表示一种判断,每个路径代表一种判断的输出,每个叶子节点代表一种类别,并作为最终判断的结果。
CART在本节的训练中有何作用?
CART在本节的训练中,可以将最基本的弱分类器,通过训练,找到最优阈值,使之成为可用的较优弱分类器。(下面会有详细的CART训练过程)
3.什么是弱分类器?在本节中,具体是指什么?如何得到弱分类器?
弱分类器(弱学习算法),是一个学习算法对一组概念的识别比随机分类的正确率高一点,强分类器(强学习算法),就是指一个学习算法对一组概念的识别率很高。
弱分类器分为最基本弱分类器和最优弱分类器。最基本的弱分类器,只含有一个haar-like特征,在决策树CART结构中,它相当于只有一层,被称为“树桩”(stump),如下图所示。

由于单特征的分类器(只有一个树桩)太简陋了,可能并不比随机判断的效果好。所以,采用了CART的决策树形式,单节点的基本分类器通过训练可以优化为有更高的辨别力的分类器,即为弱分类器(CARTHaarClf),最终弱分类器形式一般为多节点形式,如下。
但本节所采用的是树桩型CART树。所以一个CART树,仅有一个树桩节点(单个特征),所以最终的弱分类器形式,如下图所示:
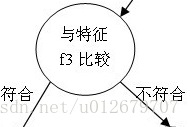
那一个最基本的弱分类器,如何成为一个较优的弱分类器呢?
最基本的弱分类器可能只是一个最基本的Haar-like特征,计算输入图像的Haar-like特征值,和最基本的弱分类器的阈值比较,以此来判断输入图像是不是人脸,然而这个弱分类器太简陋了,可能并不比随机判断的效果好。弱学习算法被设计成选择单个矩形特性,它可以最好地分离正样本和负样本的例子。对于每个特征,弱学习器决定了最优阈值分类函数,这样被错误分类的样本数最少。因此,一个弱分类器hj(x)包括一个图像的子窗口x、一个特征fj、一个阈值θj和一个指示不等号方向的极性pj(作用是控制不等式的方向,使得不等式都是<号,形式方便)组成,:
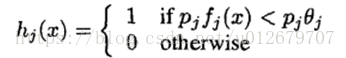
最重要的就是如何决定每个结点判断的输出,要比较输入图片的特征值和弱分类器中特征,一定需要一个阈值,当输入图片的特征值大于该阈值时才判定其为人脸。训练最优弱分类器的过程实际上就是在寻找合适的分类器阈值,使该分类器对所有样本的判读误差最低。
具体寻找最优阈值的过程:

弱分类器的具体参数,代码如下:
/*
* CART classifier
*/
typedef struct CvCARTHaarClassifier
{
CV_INT_HAAR_CLASSIFIER_FIELDS()
int count;
int* compidx;
CvTHaarFeature* feature;// 特征(指针相当于数组,表明可以有多层CART tree,但在本训练中,采用树桩结构,即一个CARTHaarClf,一个特征)
CvFastHaarFeature* fastfeature;
float* threshold;//阈值
int* left;//左叶子值
int* right;//右叶子值
float* val;//计算值
} CvCARTHaarClassifier;
4.强分类器是什么?如何训练得到?结构如何?
在任何图像子窗口中,haar-like的特征的总数非常大,远远大于像素的数量。为了确保快速分类,学习过程必须排除大部分可用的特征,并将重点放在一小部分关键特征上。在Tieu和Viola的工作的激励下,通过对AdaBoost程序的简单修改,特征选择被实现了:通过使用AdaBoost选择少量重要特征来构造强分类器,即通过组合弱分类器得到了强分类器。
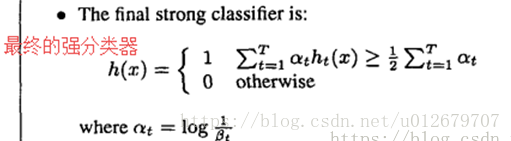
其中,弱分类器的分类误差越小(性能越好),在强分类器中所占的比重越大。即αt 越大。
如何训练得到强分类器?
每个弱分类器只能依赖于单个特征。因此,选择一个新的弱分类器的提升(boosting)过程的每个阶段,都可以被看作是一个特征选择过程。Adalboost提供了一种有效的学习算法和强大的边界泛化性能。Adalboos算法具体过程如下:

对于人脸检测的任务,AdaBoost选择的初始矩形特征是有意义且容易解释的。第一个特征选择似乎专注于眼睛比鼻子和脸颊更暗这一属性 (参见图4)。这个特征与检测子窗口相比相对较大,并且应该对脸的大小和位置不敏感。选择的第二个特征依赖于眼睛比鼻梁更暗的属性。
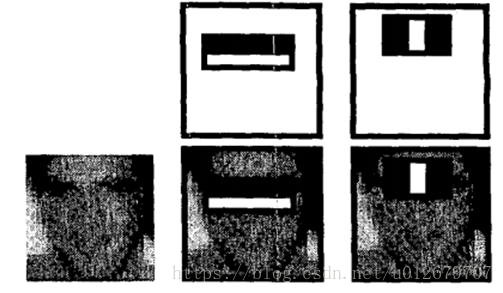
图4:AdaBoost选择的第一个和第二个特征。这两个特征显示在最上面一行,然后在底部的一个典型的训练面上覆盖。第一个特征是测量眼睛区域和上颊区域之间的强度差异。该特征利用观察到的观察结果,即眼睛区域通常比脸颊更暗。第二个特征是将眼睛区域的强度与鼻梁上的强度进行比较。
想看更详细的Adalboost的算法介绍,请戳:https://blog.csdn.net/u012679707/article/details/80369772
强分类器(stageHaarClf)的参数,见代码:
/* internal stage classifier */
typedef struct CvStageHaarClassifier
{
CV_INT_HAAR_CLASSIFIER_FIELDS()
int count;
float threshold;
CvIntHaarClassifier** classifier;
} CvStageHaarClassifier;
强分类器结构:

xml文件中的stageHaarClf:

5.Cascade是什么?有什么作用?整个人脸检测分类器的组成?
Cascade是什么?
检测过程的整体形式是一个退化的决策树,我们称之为“cascade”(级联分类器,见图5)。第一个分类器的结果如果为正(positive result),则将触发对第二个分类器的评估,它也被调整以达到很高的检测率。第二个分类器的正的结果触发第三个分类器,以此类推。任何时候的负结果(A negative)都会导致子窗口立即被拒绝。
级联的阶段是通过使用Adaboost训练分类器,然后调整阈值以减少errar rate来构建的。注意,默认的Adaboost阈值被设计为在训练数据上产生低错误率。一般来说,较低的阈值会产生更高的检测率和更高的假正率。
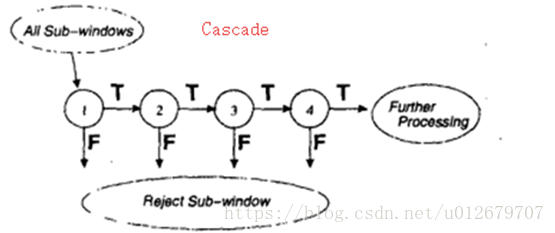
图5:检测级联的示意图。每个子窗口都应用了一系列分类器。最初的分类器消除了大量的负面例子,且只需很少的处理。随后的层消除了额外的负面例子,但需要额外的计算。经过几个阶段的处理后,子窗口的数量已经大大减少了。进一步的处理可以采取任何形式,例如附加级联阶段(如在我们的检测系统中)或使用另一种可选择的检测系统。
TreeCascadeClf结构:
HaarCascadeTree结构:
CascadeTree
{
Stage 0:
{
Tree 0:
Tree 1:
…
Tree T0:
}
Stage 1:
{
Tree 0:
Tree 1:
…
Tree T1:
}
……
Stage N:
……
}
想要了解人脸检测分类器的具体内容,打开cascade.xml文件,一看便知:

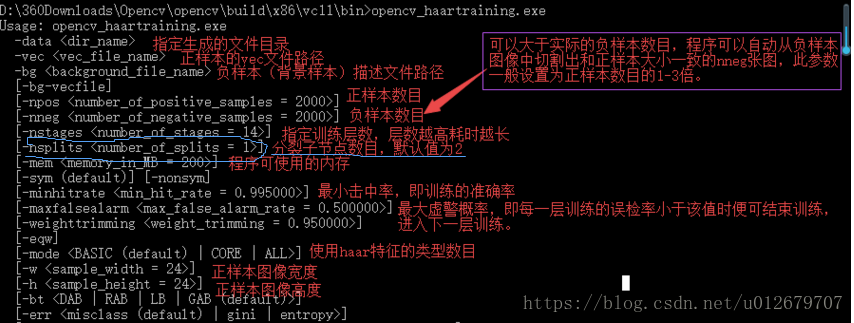
这是我自己训练的分类器,选择的是树桩型(stump),每棵CART树只有root node,没有叶子节点。所以一个CART弱分类器就是一个树桩stump,包含一个特征。若选择分裂节点不为1,则是多节点树,每个弱分类器将包含多个node,也就含有多个特征(每个cart tree node带有一个特征)。

具体设置可见【附录1】,训练haartraing时,参数分裂子节点设置成了1,则表明树高为1,即只有树桩;默认是2,则表明树高为2。
Cascade有什么作用?
在一个级联结构中,将更复杂的分类器组合在一起(强强联手),通过对图像中有”希望“的区域的关注,极大地提高了检测器的速度。第一个分类器的结果如果为正(positive result),则将触发对第二个分类器的评估,它也被调整阈值以达到很高的检测率。第二个分类器的正的结果触发第三个分类器,以此类推。任何时候的负结果(A negative)都会导致子窗口立即被拒绝。这就使得待检测区域急速缩小,提升了检测速度,节省了大量时间。
如何训练得到CascadeTree?
级联训练过程涉及两种类型的权衡(折衷)。在大多数情况下,具有更多特征的分类器将获得更高的检测率和更低的假阳性率。与此同时,具有更多特征的分类器需要更多的时间来计算。原则上,我们可以定义一个优化框架,其中:
i)分类器迭代阶数
ii)每个迭代阶段(stage)的特征数量
iii)每个阶段的阈值,为了最小化预期的被评估特性的数量而被改变。
不幸的是,找到这种最优的方法是一个非常困难的问题。
在实践中,一个非常简单的框架被用来产生一个高效的分类器。级联的每个阶段都降低了假正率,降低了检测率。选择一个目标,以减少误报和最大化减少检测量。具体的训练过程,包括弱分类的训练,和强分类的训练。
(1)每个阶段都通过添加特征feature(弱分类器)来训练,直到目标检测和假阳性率得到满足(这些率rate是通过在验证集中测试检测器来确定的)。
(2)在达到假阳性和检测率的总体目标之前,增加迭代数目(stage,强分类器)。直到满足条件,停止迭代。
具体训练过程如下:

/* internal cascade classifier */
typedef struct CvCascadeHaarClassifier
{
CV_INT_HAAR_CLASSIFIER_FIELDS()
int count;
CvIntHaarClassifier** classifier;
} CvCascadeHaarClassifier;
/* internal tree cascade classifier node */
typedef struct CvTreeCascadeNode
{
CvStageHaarClassifier* stage;
struct CvTreeCascadeNode* next;
struct CvTreeCascadeNode* child;
struct CvTreeCascadeNode* parent;
struct CvTreeCascadeNode* next_same_level;
struct CvTreeCascadeNode* child_eval;
int idx;
int leaf;
} CvTreeCascadeNode;
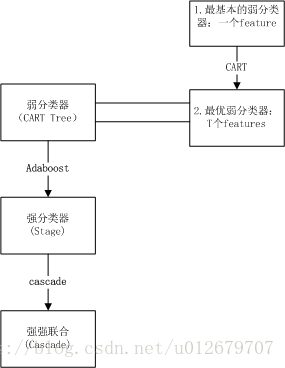
6.整个人脸检测分类器的组成?
人脸检测分类器可以总结为:
人脸检测分类器=haar-like (特征)+CART(弱)+ Adaboost(强) + Cascade(级联)
haar-like+CART+adaboost+Cascade 训练过程分析图:
整个训练过程源码简摘:
获取训练的样本数据(正和负)-----计算子窗口特征值----训练弱分类器----训练强分类器----训练级联分类器----输出训练好的人脸检测分类器
源码分析:
//创建TreeCasecadeClf
cvCreateTreeCascadeClassifier( dirname, vecname, bgname,
npos, nneg, nstages, mem,
nsplits,
minhitrate, maxfalsealarm, weightfraction,
mode, symmetric,
equalweights, width, height,
boosttype, stumperror,
maxtreesplits, minpos, bg_vecfile );
haar_features = icvCreateIntHaarFeatures( winsize, mode, symmetric );
training_data = icvCreateHaarTrainingData( winsize, npos + nneg );
//从vec正样本文件获取训练数据
poscount = icvGetHaarTrainingDataFromVec( training_data, 0, npos,
(CvIntHaarClassifier*) tcc, vecfilename, &consumed );
// consumed = consumed + thread_consumed_count(线程消耗数)
printf( "POS: %d %d %f\n", poscount, consumed, ((double) poscount)/consumed );
//从负样本文件获取训练数据
negcount = icvGetHaarTrainingDataFromBG( training_data, poscount, nneg,
(CvIntHaarClassifier*) tcc, &false_alarm, bg_vecfile ? bgfilename : NULL );
printf( "NEG: %d %g\n", negcount, false_alarm );
printf( "BACKGROUND PROCESSING TIME: %.2f\n", (proctime + TIME( 0 )) );
//Adaboost
/* precalculate feature values 预先计算特征值*/
icvPrecalculate( training_data, haar_features, numprecalculated );
printf( "Precalculation time: %.2f\n", (proctime + TIME( 0 )) );
/* train stage classifier using all positive samples 使用所有正样本训练强分类器TreeCascadeNode=stage*/
CV_CALL( single_cluster = icvCreateTreeCascadeNode() );
//训练每一强分类器stage中的弱分类器CartTree
single_cluster->stage = (CvStageHaarClassifier*) icvCreateCARTStageClassifier(
training_data, NULL, haar_features,
minhitrate, maxfalsealarm, symmetric,
weightfraction, numsplits, (CvBoostType) boosttype,
(CvStumpError) stumperror, 0 );
printf( "Stage training time: %.2f\n", (proctime + TIME( 0 )) );
---------------------------------------------- 附录 --------------------------------------------------------------
【附录1】训练haartraing时,参数分裂子节点设置成了1,则表明树高为1,即只有树桩;默认是2,则表明树高为2。
------------------------------------------- END -------------------------------------
参考:
(人脸检测过程分析 非常棒!) http://www.cnblogs.com/ello/archive/2012/04/28/2475419.html
(haar源码) https://blog.csdn.net/u011783201/article/details/52184093
(CART) https://blog.csdn.net/acdreamers/article/details/44664481