前置知识:
ref:https://www.osgeo.cn/pillow/reference/ImageFile.html
ref:https://blog.csdn.net/weixin_67510296/article/details/125207042
1.多线程初体验
主线程的id和进程的id是一个
查看进程pid下有多少个线程
ps -T -p pid
(base) D:\code\python_project\python_coroutine>C:/ProgramData/Anaconda3/python.exe d:/code/python_project/python_coroutine/01demo.py
threading.active_count=1
i am producer cnt=1 thread_id1 = 15984 thread_id2 = 15984
threading.active_count=2
i am consumer cnt=0 thread_id1 = 12828 thread_id2 = 12828
threading.active_count=3
i am producer cnt=1 thread_id1 = 15984 thread_id2 = 15984
i am consumer cnt=0 thread_id1 = 12828 thread_id2 = 12828
i am producer cnt=1 thread_id1 = 15984 thread_id2 = 15984
import threading
import time
cnt = 0
def producer():
global cnt
while True:
cnt += 1
print("i am producer cnt={} thread_id1 = {} thread_id2 = {}".format(cnt,threading.get_ident(), threading.get_native_id()))
time.sleep(1)
pass
def consumer():
global cnt
while True:
if cnt <= 0:
continue
cnt -= 1
print("i am consumer cnt={} thread_id1 = {} thread_id2 = {}".format(cnt,threading.get_ident(), threading.get_native_id()))
time.sleep(1)
if __name__ == "__main__":
print("threading.active_count={}".format(threading.active_count()))
t1 = threading.Thread(target=producer)
t2 = threading.Thread(target=consumer)
t1.start()
print("threading.active_count={}".format(threading.active_count()))
t2.start()
print("threading.active_count={}".format(threading.active_count()))
查看当前程序的活跃线程数量
threading.active_count()
2.单线程下载器
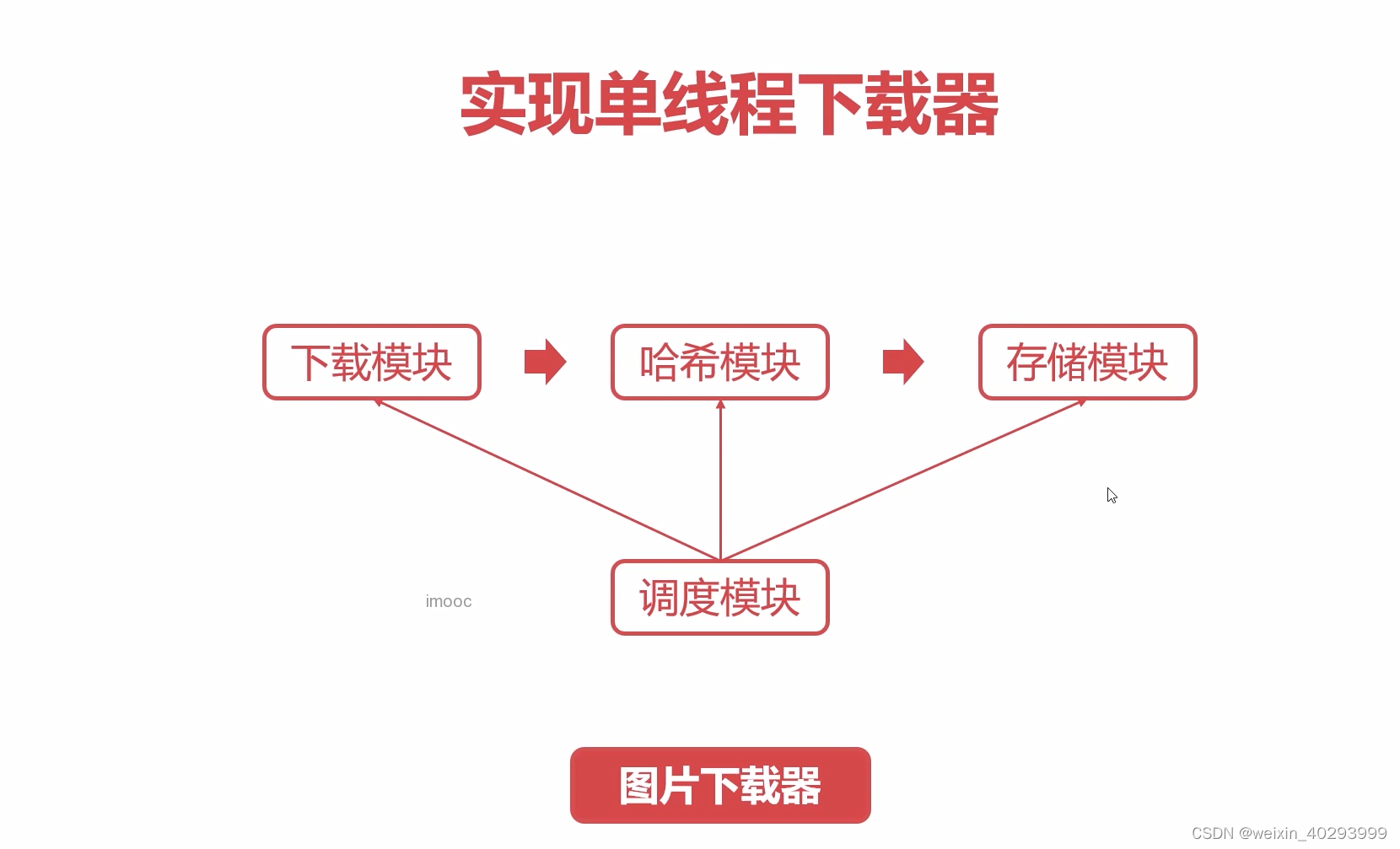
下载模块:从网络上下载图片 I/O密集型
哈希模块:cpu密集
存储模块:I/O密集
单线程的是串行的,先下载,再哈希计算重命名,再存储,都是在主线程完成。
实际上三个功能应该并行起来:主线程负责调度,三个线程分别实现下载,哈希和存储。
2.1 目录结构
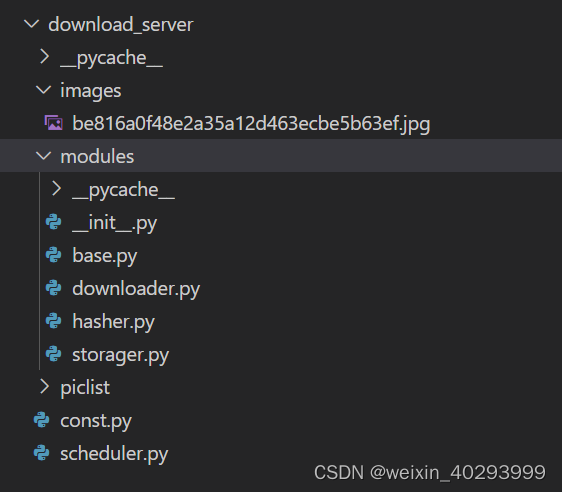
modules 下的三个文件是对三个功能的实现,base是定义的抽象方法
const.py 是枚举类。
scheduler.py 是总调度方法
在写 base.py 和 其子类的时候,发现子类可以重载父类的方法,也就是参数可以不相同。
另外,base中定义的方法,需要raise 异常,以防 base 类中控制的总实现发现运行中,子类因为拼写错误而没有运行。
2.2 单线程下载器
在实现单线程下载器的时候,顺便完成了整个框架的搭建,可以方便的改成多线程下载器
import os
import sys
sys.path.append(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))
from const import CaclType
class BaseModule():
"""
抽象模块
"""
def __init__(self) -> None:
self.calc_type = CaclType.SingleThread
def set_calc_type(self, type_):
self.calc_type = type_
def _process(self):
raise NotImplementedError
def _process_singlethread(self):
raise NotImplementedError
def process(self, list_):
if self.calc_type == CaclType.SingleThread:
return self._process_singlethread(list_)
else:
pass
```
Downloader 下载器实现
```python
import os
import sys
import requests
from PIL import ImageFile
import numpy as np
sys.path.append(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))
from .base import BaseModule
from const import CaclType
class Downloader(BaseModule):
"""下载模块
"""
def __init__(self) -> None:
super().__init__()
def _process(self,url):
print("download url:" + url)
response = requests.get(url)
content = response.content
# 直接从网络上面抓取的数据,没有经过任何解码,所以是一个 bytes类型,其实在硬盘上和在网络上传输的字符串都是 bytes类型,
parser = ImageFile.Parser()
parser.feed(content)
img = parser.close()
# img.save("./a.jpg")
# 修改成numpy的格式
img = np.array(img)
return img
def _process_singlethread(self,list_):
response_list = []
for url in list_:
img = self._process(url)
response_list.append(img)
return response_list
def process(self, list_):
if self.calc_type == CaclType.SingleThread:
return self._process_singlethread(list_)
else:
pass
if __name__ == "__main__":
dl = Downloader()
list_ = ["https://nimg.ws.126.net/?url=http%3A%2F%2Fdingyue.ws.126.net%2F2023%2F0907%2Fb90e12c7j00s0lqz0000lc000ku00dpm.jpg&thumbnail=660x2147483647&quality=80&type=jpg"]
aa = dl.process(list_)
print(aa)
哈希实现:
···python
import os
import sys
from scipy import signal
import requests
from PIL import ImageFile,Image
import numpy as np
import hashlib
sys.path.append(os.path.dirname(os.path.dirname(os.path.abspath(file))))
from .base import BaseModule
class Hasher(BaseModule):
“”"
哈希模块
“”"
def init(self) -> None:
super().init()
def _process(self,item):
# 卷积
conv = [[[0.1],[0.05],[0.1]]]
img = signal.convolve(item,conv)
img = Image.fromarray(img.astype("uint8")).convert("RGB")
# 哈希
md5 = hashlib.md5(str(img).encode("utf-8")).hexdigest()
return md5
def _process_singlethread(self,list_):
md5_list = []
for img in list_:
md5 = self._process(img)
md5_list.append(md5)
return md5_list
···
存储实现
···python
import os
import sys
from scipy import signal
import requests
from PIL import ImageFile,Image
import numpy as np
import hashlib
sys.path.append(os.path.dirname(os.path.dirname(os.path.abspath(file))))
from .base import BaseModule
class Storager(BaseModule):
def init(self) -> None:
super().init()
def _process(self,item):
content,path = item
print("save path:{}".format(path))
content = Image.fromarray(content.astype('uint8')).convert("RGB")
content.save(path)
def _process_singlethread(self,list_):
# item = (content, path)
for item in list_:
self._process(item)
···
总调度实现
import os
from modules.downloader import Downloader
from modules.hasher import Hasher
from modules.storager import Storager
class Scheduler:
"""调度模块
"""
def __init__(self) -> None:
self.downloader = Downloader()
self.hasher = Hasher()
self.storager = Storager()
def _wrap_path(self, md5):
filename = '{}.jpg'.format(md5)
STORAGE_PATH = os.path.join(os.path.dirname(os.path.abspath(__file__)), 'images')
path = os.path.join(STORAGE_PATH, filename)
return path
def process(self):
# 1.加载图片url列表
url_list = ["https://nimg.ws.126.net/?url=http%3A%2F%2Fdingyue.ws.126.net%2F2023%2F0907%2Fb90e12c7j00s0lqz0000lc000ku00dpm.jpg&thumbnail=660x2147483647&quality=80&type=jpg"]
# 2. 调度下载模块
content_list = self.downloader.process(url_list)
# 3. 调度hash模块
md5_list = self.hasher.process(content_list)
# 4. 调度存储模块
item_list = []
for content, md5 in zip(content_list, md5_list):
save_path = self._wrap_path(md5)
item = (content,save_path)
item_list.append(item)
self.storager.process(item_list)
if __name__ == "__main__":
scheduler = Scheduler()
scheduler.process()
···
枚举实现:
```python
from enum import Enum
class CaclType(Enum):
SingleThread = 0
MultiThread = 1
MultiProcess = 2
PyCoroutine = 3
if __name__ == "__main__":
print(CaclType.SingleThread.value==0)
10 张图片的耗时:{‘network_time’: [0.913635], ‘cpu_time’: [1.68479], ‘disk_time’: [0.14452]}
-------------------------------------------------------------- 至此,一个单线程的下载器已经完成------
2.3 多线程下载器
{‘network_time’: [0.920507], ‘cpu_time’: [1.766117], ‘disk_time’: [0.146528]}
{‘network_time’: [0.450087], ‘cpu_time’: [1.698905], ‘disk_time’: [0.089213]}
多线程用线程池的方式实现,2个线程,一共url是7-10个,具体忘了
下载:
def _process_multithread(self,list_):
response_list = []
task_list = []
for url in list_:
task = tp.submit(self._process,(url))
task_list.append(task)
for task in task_list:
img = task.result()
response_list.append(img)
return response_list
哈希:
def _process_multithread(self,list_):
task_list = []
md5_list = []
for img in list_:
task = tp.submit(self._process,(img))
task_list.append(task)
for task in task_list:
md5 = task.result()
md5_list.append(md5)
return md5_list
存储:
def _process_multithread(self,list_):
task_list = []
for item in list_:
task = tp.submit(self._process,(item))
task_list.append(task)
for task in task_list:
task.result()
# 这里仍然需要等待完成的结果,否则计算时间会提前
三者的形式是相同的,都是submit发送task,然后 result等待收结果。
观察可得,下载和存储多线程有效果,而hash多线程没啥效果,甚至会变慢(因为上下文切换的原因),是因为python的多线程是伪多线程,因为GIL的存在,但对i/o操作还是可以加速的。
那么python 为啥不去掉GIL呢,而在操作内存的地方,追加锁,这样会增加和释放很多个锁,有人做过实验,会减慢单线程的操作,使得它的性能下降50%。

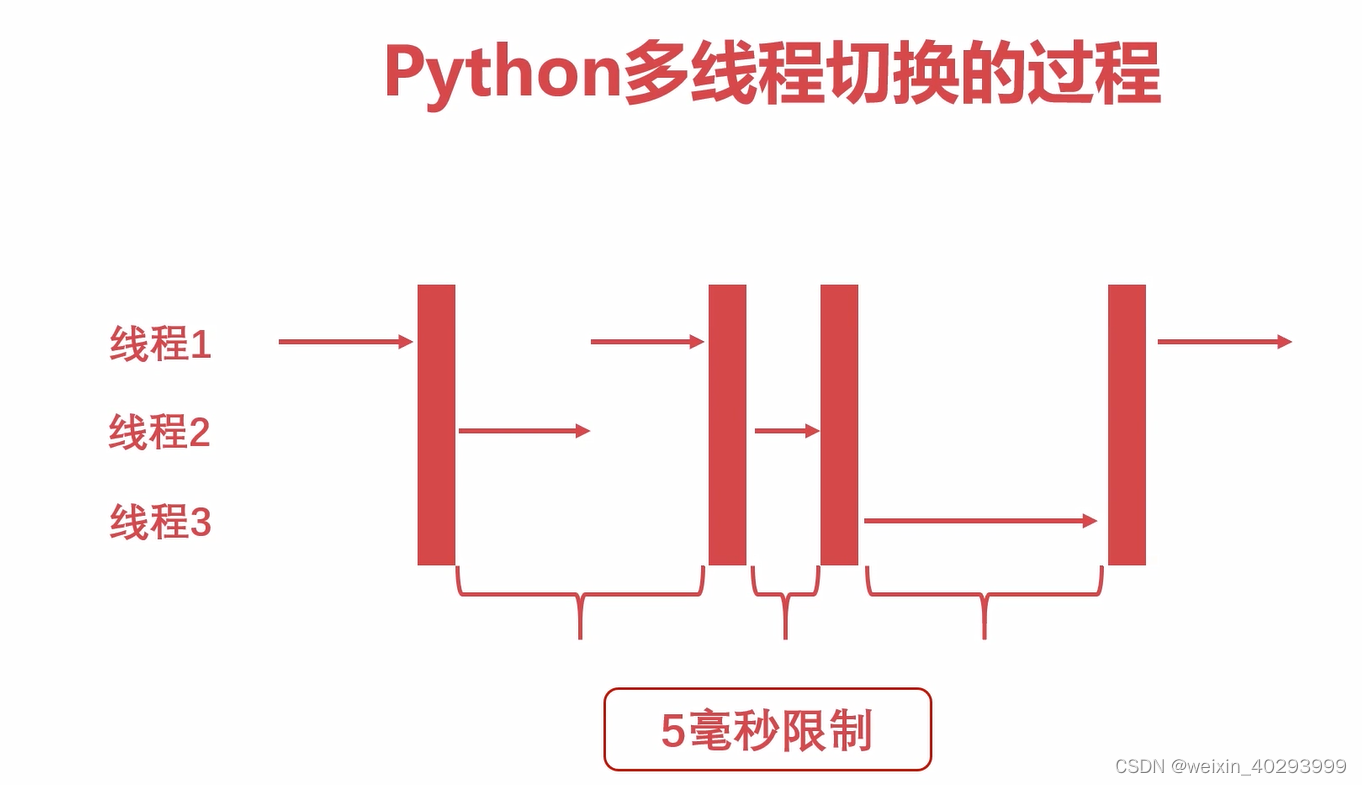
后来在python3.x的时候 python的GIL做过优化,python解释器讲python代码解释成字节码片段,100个ticks讲进行一次检查,若没有切换,则强制切换。这样有个不好的地方,字节码片段的执行并不是等时长的,有的字节码耗时长,有的耗时短。

后来变成了,5毫秒强制切换,和遇到i/o也切换。
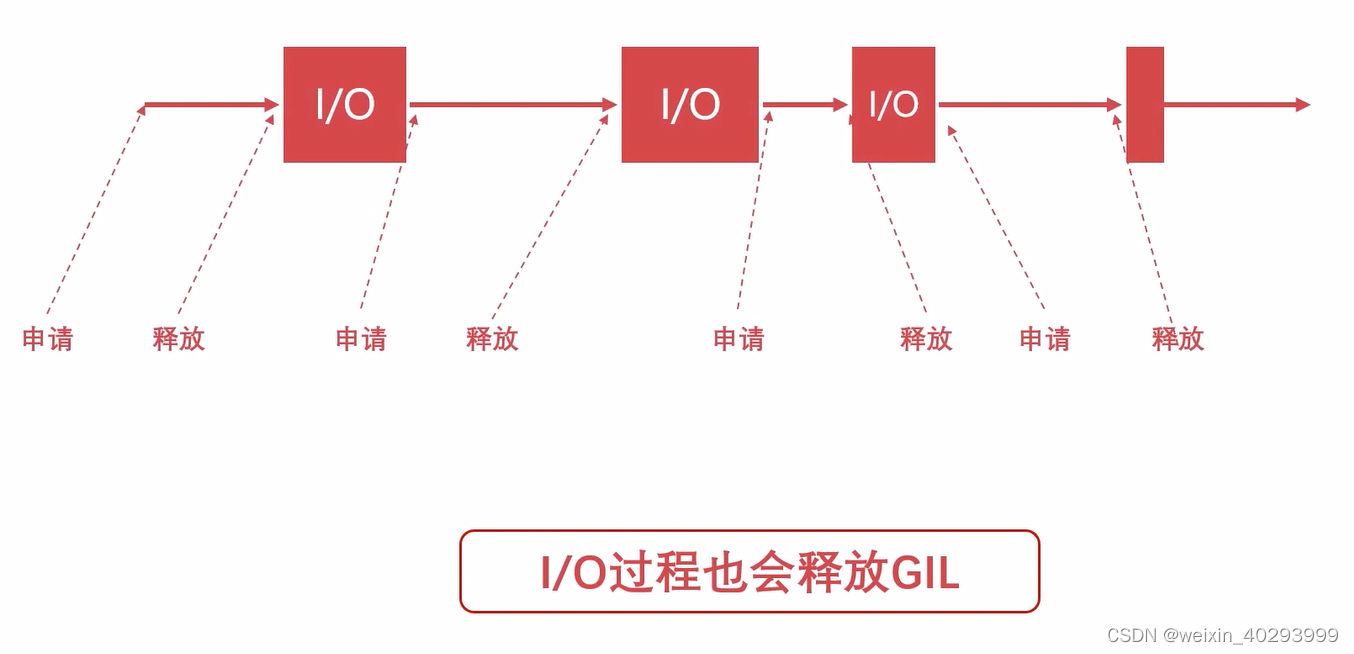
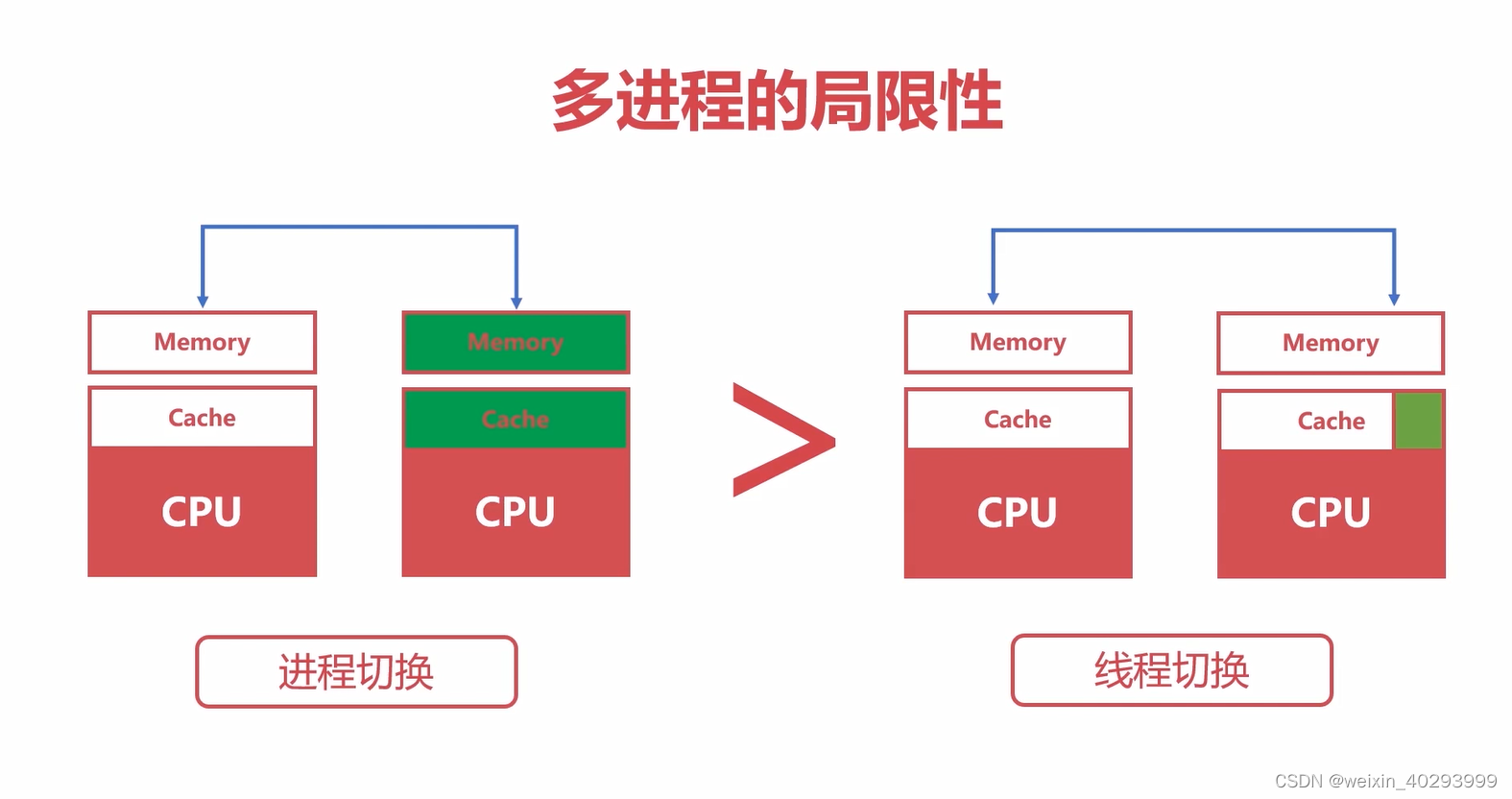
3.多进程
进程池和线程池的用法几乎完全一样。
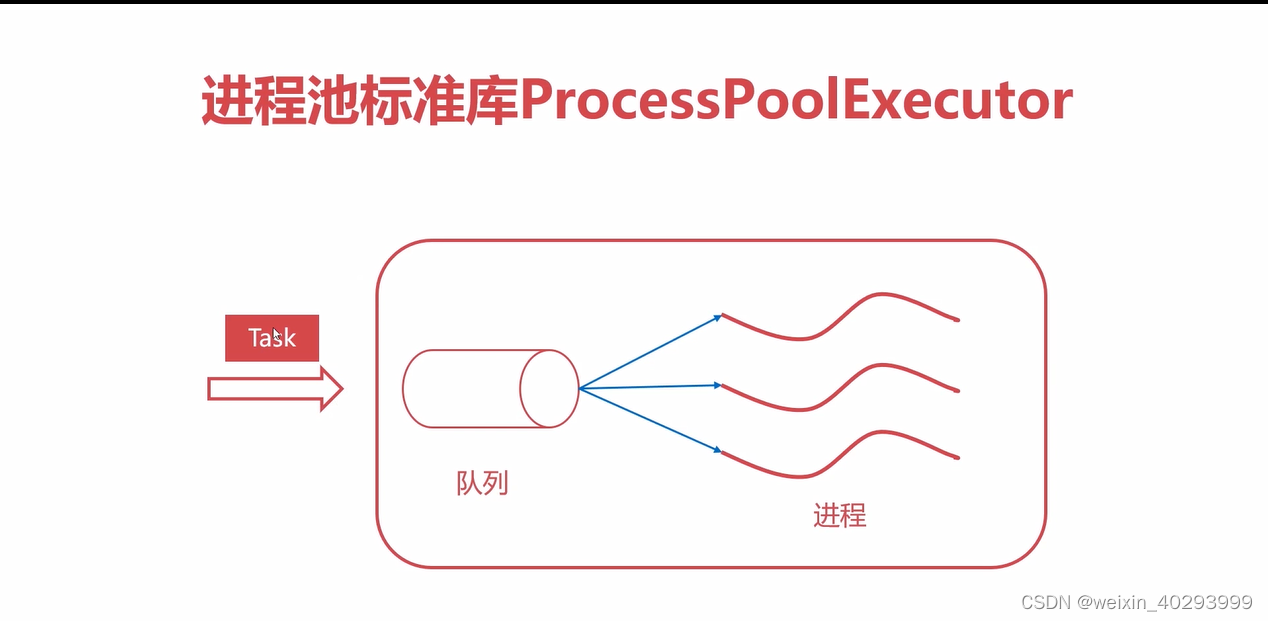
线程和进程都是将job抽象成了task任务,进程/线程池维护在了一个队列里面,由ThreadPoolExecutor/ProcessPoolExecutor维护。
不同的是,进程间的数据是相互隔离的,而线程池的全局数据是共享的,而进程间的数据需要同步,是用共享内存的方式实现的,有几种数据结构,queue,map等等好几个。
量化分析结果

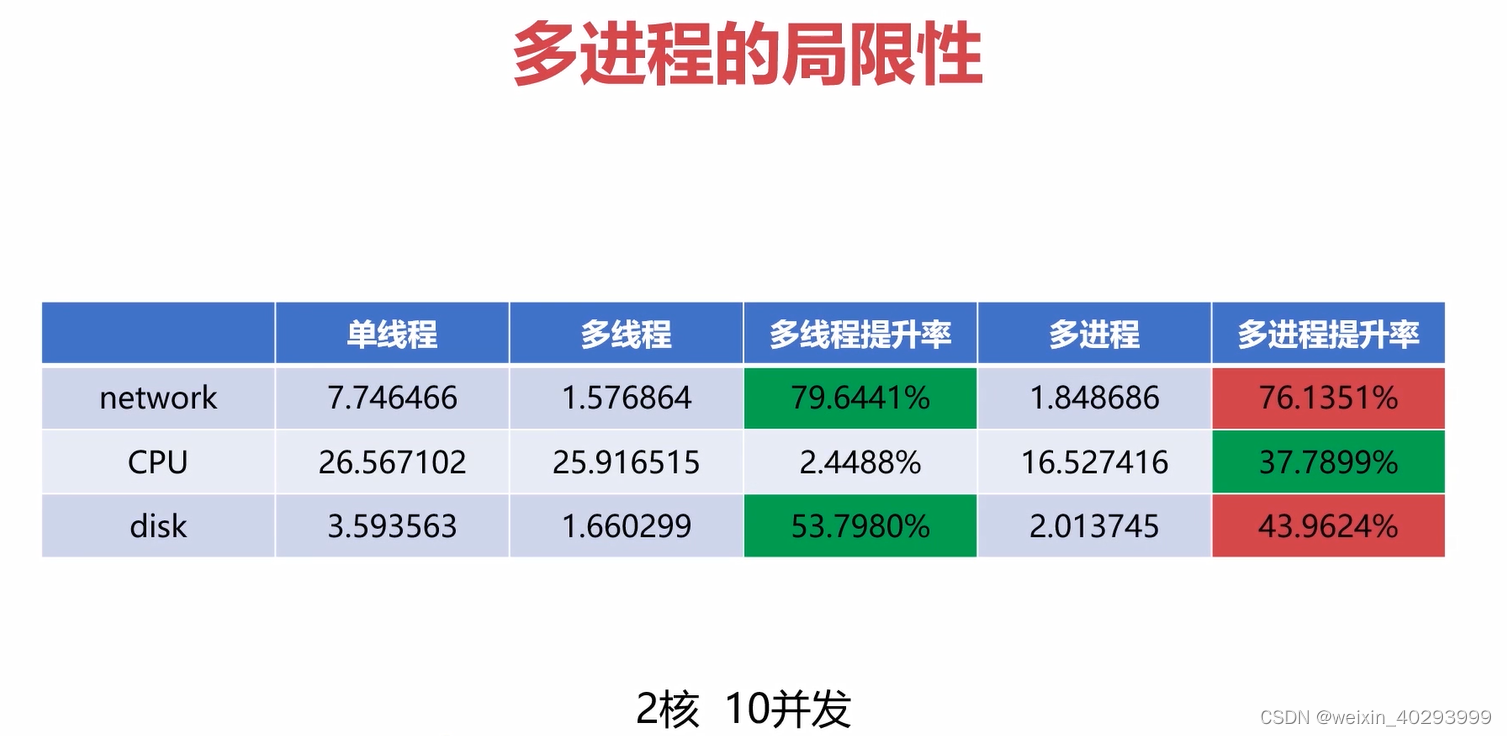

造成这个差异的原因是因为管理上下文的成本!那么抛出下面的问题?
进程的上下文切换会比线程的上下文切换差多少???
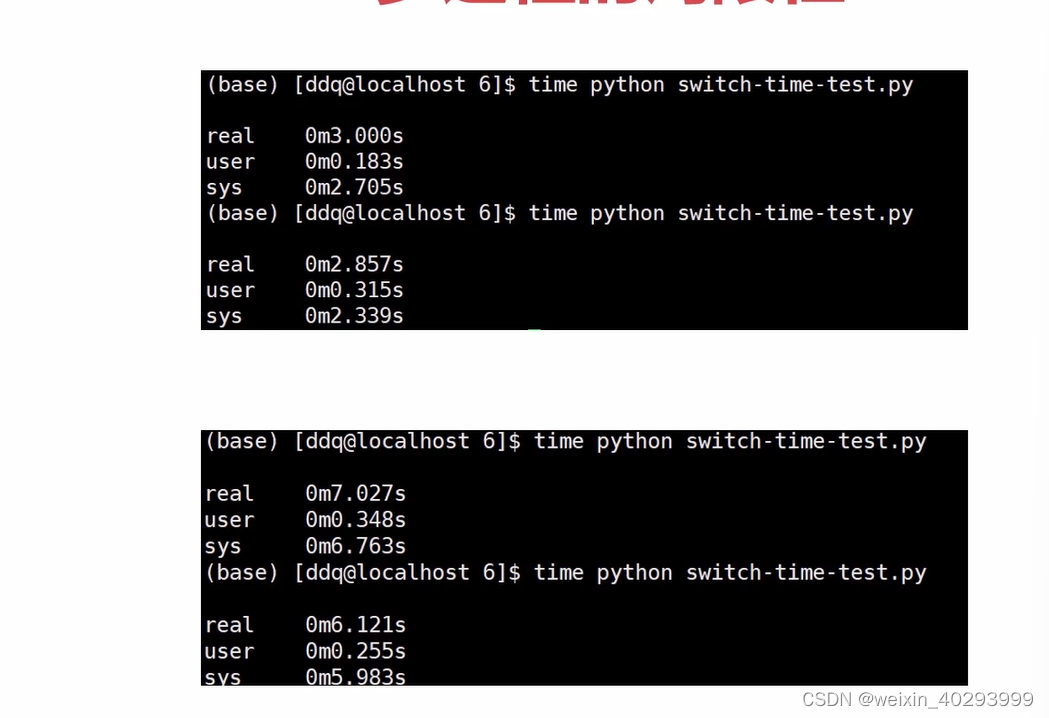
上下文切换的命令:
sar -w 1 1000
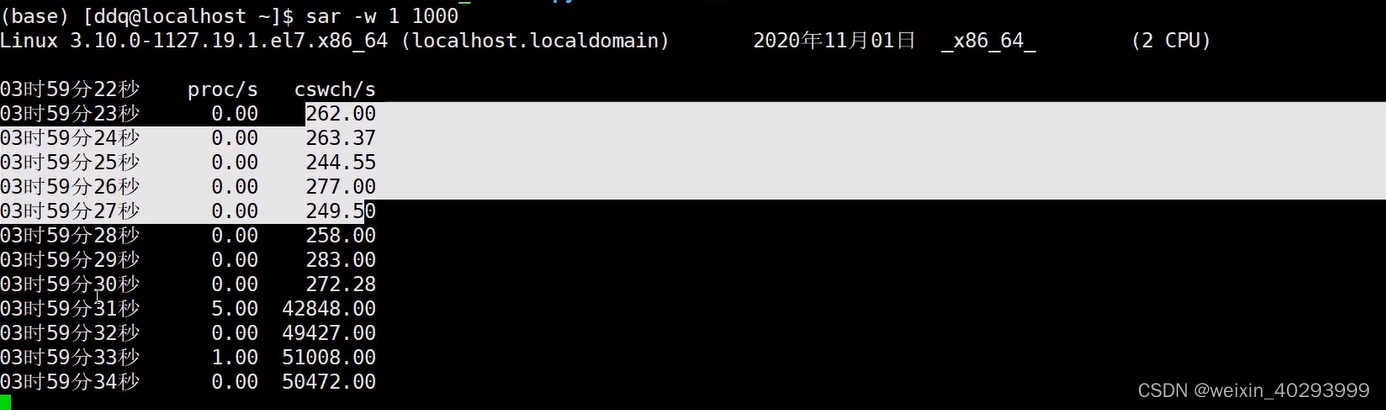
在2个多线程和2个多进程的比较,多进程的切换,是多线程切换的2~3倍,而且线程和进程的数量越多,拉开的差距越大
cpu核数、并发数和性能的关系
如何在环境中配置最合理的进程数量,才能达到最好的并发,来指导我们调优。
统筹方法
就是数学方法,就是小学的华罗庚数学家的那个…甘特图,或者前置项。。。。步骤间和任务内的并行关系。
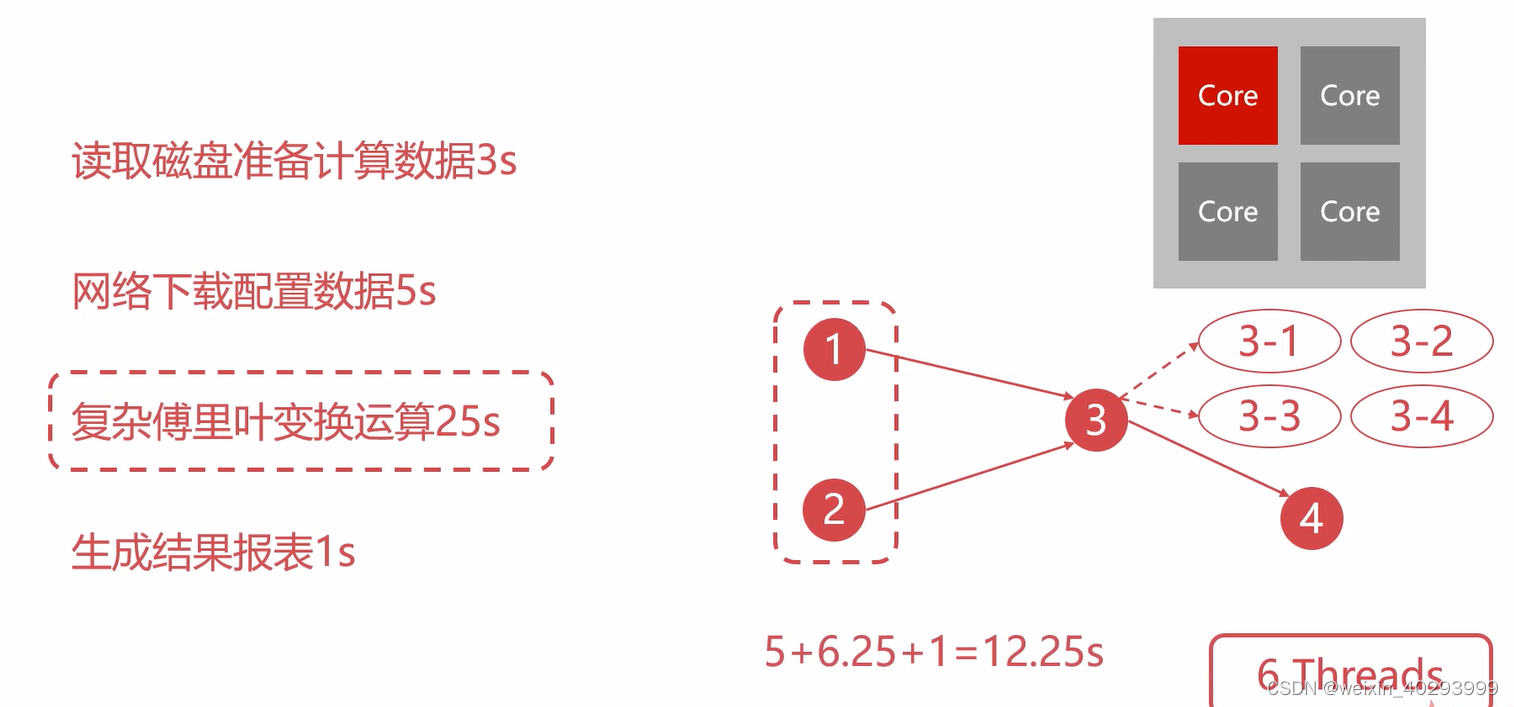
但是步骤3拆分的进程/线程越多越好么? 答案当然是否定的,但是有误量化的标准呢?
用阿姆达尔定律,代表理论的最大加速比
阿姆达尔定律
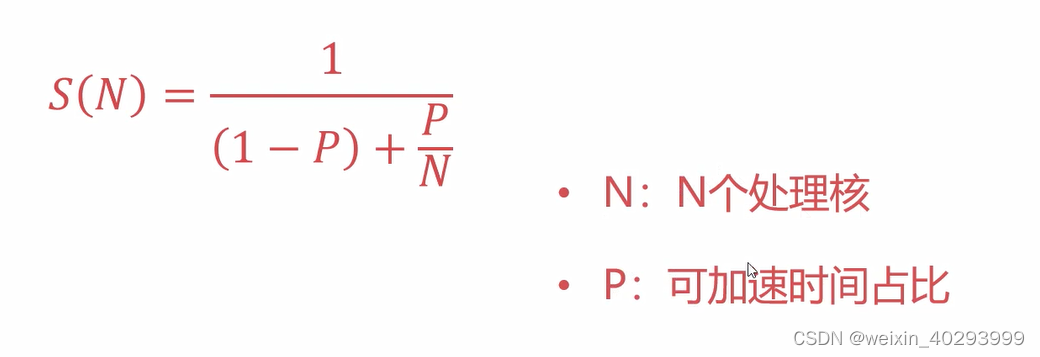
上面的例子,
N = 4
P = 25 /31 = 0.8065,
代入到阿姆达尔定律
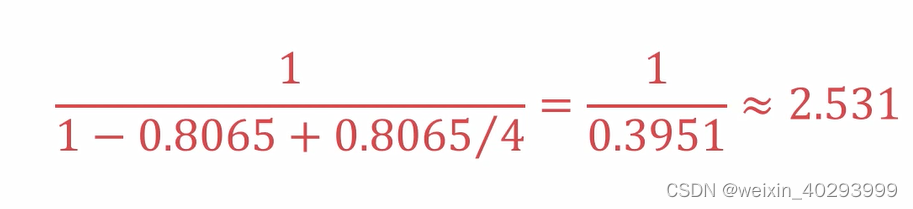
实际计算的结果,用N=4
31/12.25 X100% = 253.06%
假定 P=0.8065 提升N, 是否永远有效?答案不是的。
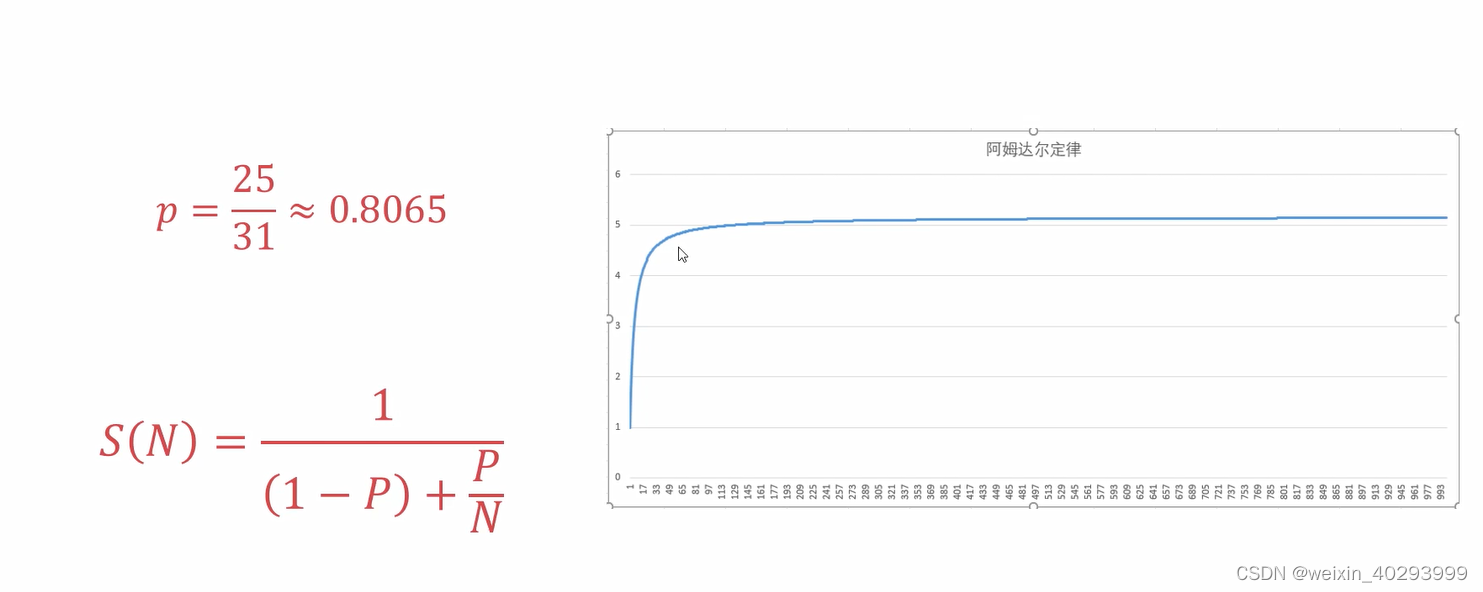
总结
至此已完成了单线程和多线程的下载器改造,并分析了python的多线程为啥是伪多线程,适合在什么场景使用。
这是慕课的一个系列课程,之前断断续续学习过一遍,那时候没咋用过python,用python两年后再看,还是收获很大!
还有协程的知识参加我的另一篇文章: https://mp.csdn.net/mp_blog/creation/success/130478060