0. 简介
在一些比较空旷,且没有参照的场地中,我们很难利用车道线或者稠密的激光点云地图来完成定位,而本文《Monocular Simultaneous Localization and Mapping using Ground Textures》仅使用向下朝向的单目相机拍摄的地面纹理图像,就能实现令人印象深刻的定位性能。这提供了一种可靠的导航方法,能抵抗特征稀疏环境和具有挑战性的光照条件。然而,这些定位方法需要一个现有的地图进行比较。本文的工作旨在通过引入一个完整的同时定位和地图构建(SLAM)系统来减轻对地图的需求。不需要现有地图,可以使设置时间最小化,并使系统更能适应不断变化的环境。这个SLAM系统采用了多种技术相结合来实现这一目标。首先识别图像关键点并将其投影到地面平面上。然后,利用这些关键点、视觉词袋和若干阈值参数来识别重叠图像和重访区域。接下来,系统使用鲁棒的M估计器来估计具有重叠图像和重访区域的机器人姿态之间的变换。这些优化估计组成了用于导航的地图。实验数据表明,这个系统在许多地面纹理上表现可靠,当然并非所有纹理都适用。还得根据自身的需求进行选择。目前这项工作的代码已经开源了,各位可以在Github上寻找
1. 主要贡献
在这里,我们考虑通过消除对先验地面纹理地图的需求,来扩展地面纹理定位方法。没有这个需求,操作员在初始设置时可以节省时间,因为在操作之前不需要创建完整的地图。这样可以探索以前未知的环境。此外,系统对于与先验地图不同的环境变化更具鲁棒性。通过引入一个完整的SLAM系统,可以实现这一功能。具体来说,这篇系统论文中的贡献如下:
- 这是第一个使用单目相机开发在线地面纹理SLAM系统。
- 在地面纹理领域的独特算法,当估计重叠图像之间的变换和识别环路闭合时,利用已知的地面纹理图像深度。
- 在最近的数据集上进行的实验结果显示,某些纹理具有厘米级的精度,跨变化纹理的性能优越,以及一致、准确的环路闭合识别。
2. 问题描述
在这里,我们考虑一台仅配备有向下朝向的、校准过的单目相机的地面机器人,该相机具有内在矩阵 K ∈ R 3 × 3 K∈\mathbb{R}^{3×3} K∈R3×3,并且相对于地面平面上机器人的原点具有已知的3D姿态。这个姿态可以表示为同构矩阵 T R C ∈ R 4 × 4 T_{RC}∈\mathbb{R}^{4×4} TRC∈R4×4,用于将以相机的参考系 C C C测量的数据转换为机器人的参考系 R R R。图1显示了一个示例设置。

图1:作者配置的一个向下朝向的相机设置。请注意,这并非用于收集本文中所考虑的实验数据的设置,但可以说明典型的设置。
机器人在平面地面上穿过几个姿态, x ⃗ t \vec{x}_t xt。这些姿态是在地面平面上定义的,作为从世界或地图框架 W W W测量的机器人的2D姿态:
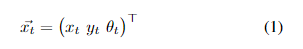
图1中可以表示为同构变换 T W x ⃗ t ∈ R 3 × 3 T_{W\vec{x}_t}∈\mathbb{R}^{3×3} TWxt∈R3×3。在这些姿态中,机器人以地面纹理无畸变图像的形式接收到观测值 Z t Z_t Zt。
目标是开发一种算法,仅使用观测值 Z 0 : t Z_{0:t} Z0:t,相机校准矩阵 K K K以及相机相对于机器人的姿态 T R C T_{RC} TRC,可靠地估算所有时刻 t t t的机器人姿态 x ⃗ t \vec{x}_t xt。
请注意,虽然里程计和惯性信息通常是可用的,但本系统特意探究了在没有额外传感器信息的情况下实现此目标的能力。实现这一目标需要一种能够估计连续图像之间的相对运动,并准确检测已重新访问的地形先前部分的方法。
3. 提出的方法
我们提出了一种执行SLAM的算法,分为三个步骤。图2显示了提出的方法的概述。首先,处理传入的图像。然后,使用连续的图像对来估计仅视觉的里程计。接着,利用环路闭合来纠正漂移。里程计和环路闭合步骤都使用从图像中识别的关键点及其相关描述符。此外,这两个步骤都使用投影到地面平面上的关键点和M估计器来估计图像对之间的变换,而M估计器是鲁棒的确定性模型。与局部视觉里程计不同,环路闭合检测使用三个度量来确定候选环路闭合是否有效。从每个步骤估算出的变换插入到表示地图的因子图中。算法的整个过程如下所述。
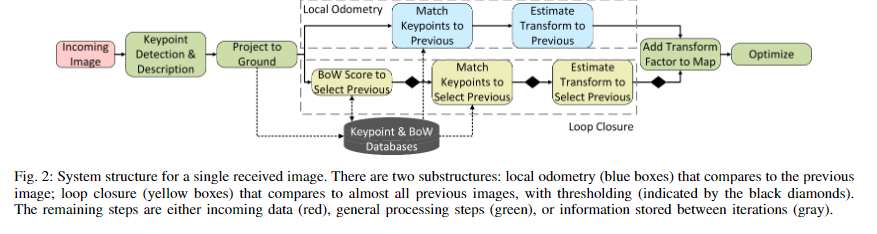
图2:接收到的单个图像的系统结构。有两个子结构:与先前图像进行比较的局部里程计(蓝色框);与几乎所有先前图像进行比较的环路闭合(黄色框),并进行阈值处理(由黑色菱形表示)。其余步骤是输入数据(红色)、通用处理步骤(绿色)或在迭代之间存储的信息(灰色)。
3.1 图像处理
当接收到图像时,首先使用ORB算法[7]对其进行处理以提取关键点及其相关描述。然后,将关键点从像素点转换为地面点。通过执行此转换,系统可以直接估计机器人在实际空间中的变换,而无需估计基本矩阵并进行转换。在大多数2D到3D投影场景中,这种转换仅在深度的比例因子上进行。然而,由于已知相机与地面平面之间的距离,可以明确地投影这些点。首先将点从像素值投影到以相机的参考系测量的米为单位,使用以下方程:
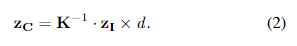
在这个方程中, d d d 是相机与地面平面之间的距离,由 T R C T_{RC} TRC得出, z I ∈ R 3 x N z_I ∈ \mathbb{R}^{3xN} zI∈R3xN 是以像素为单位的这个图像的关键点集合,用同构坐标表示如下:
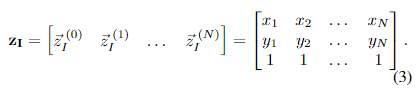
结果是一组3D向量,表示以米为单位从相机的参考系测量的点(在同构表示中的1变成 Z Z Z分量时,表示法有些滥用)。然后,这个值可以通过转换为3D同构表示和简单的变换投影到机器人的参考系中:
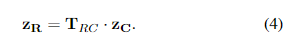
从这里开始,因为所有点和机器人的姿势都在地面平面上具有相同的 Z Z Z值(为0),所以舍弃了 Z Z Z分量。这将得到一组2D点的 z R z_R zR。投影完成后,原始的像素值关键点不再保留。保留投影后的关键点和描述符以供后续使用。
3.2 局部里程计
为了进行局部里程计测量,将投影后的关键点与前一图像的投影后关键点进行匹配。然后估计图像之间的变换。
关键点匹配:关键点匹配使用描述符在两个图像中识别相应的关键点。我们的实现使用了快速近似最近邻库(FLANN)方法[21]。对于当前图像中的每个关键点,基于FLANN的匹配算法使用关键点描述符在前一图像中找到两个描述符最相似的关键点。我们使用OpenCV的实现[22]。这种相似性用距离得分来衡量,得分越低表示相似性越高。如果两个得分相差一定百分比,那么这些关键点被认为是匹配的。换句话说,如果关键点比下一个最接近的匹配明显更相似,则它们匹配。这个比例测试是在[8]中引入的,并按照如下方式应用:
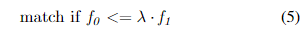
在上述不等式中, f 0 f_0 f0和 f 1 f_1 f1分别是最接近和次接近的距离得分, λ λ λ是匹配阈值,在我们的方法中通常设置在0.5到0.7之间,在文献中为0.7。
变换估计:匹配的投影关键点然后在M-估计因子图中使用GTSAM的表达式图特征[23]来估计它们之间的变换。这里描述的实验使用的是Huber,但也可以使用其他方法。这个因子图估计变换的X、Y和偏航分量, T x ⃗ j x ⃗ i T_{\vec{x}_j \vec{x}_i} Txjxi ,它表示机器人两个姿势之间的变换。估计的变换是最符合下面等式的那个。因为关键点是投影到地面平面上的,如第3章刚开始所述,这个估计完全在2D实空间中进行,提供了比传统的3D SLAM方法更高的效率。
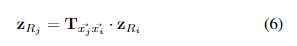
估计完成后,将变换及其相关协方差添加到机器人的SLAM因子图中,作为当前姿势与前一个姿势之间的因子。然后系统继续进行闭环识别步骤。
3.3 闭环检测
为了纠正漂移,系统必须正确识别以前访问过的地面纹理。所有以前访问过的姿势处的观测值都是可能的候选项。使用三个阈值标准:视觉词袋得分,关键点匹配数和协方差参数。
视觉词袋:第一个阈值参数是视觉词袋得分。使用[24]中描述的技术和库,构建一个先前图像描述符的数据库,随着新观测值的接收。为了防止在相邻观测值上出现冗余闭环,描述符在添加了足够数量的后续观测值后才添加到数据库中。换句话说,如果刚刚接收到的当前观测值是 Z n Z_n Zn,那么从 Z n − k Z_{n-k} Zn−k的描述符被添加到数据库中。
然后,用当前观测值的描述符查询数据库以找到匹配项。在这项工作中使用的设置下,数据库中每个先前观测值返回的得分范围为0到1,其中1为完美匹配。所有得分高于某个阈值的结果都被认为是候选闭环。