深度学习论文: Gold-YOLO: Efficient Object Detector via Gather-and-Distribute Mechanism及其PyTorch实现
Gold-YOLO: Efficient Object Detector via Gather-and-Distribute Mechanism
PDF: https://arxiv.org/pdf/2309.11331.pdf
PyTorch代码: https://github.com/shanglianlm0525/CvPytorch
PyTorch代码: https://github.com/shanglianlm0525/PyTorch-Networks
1 概述
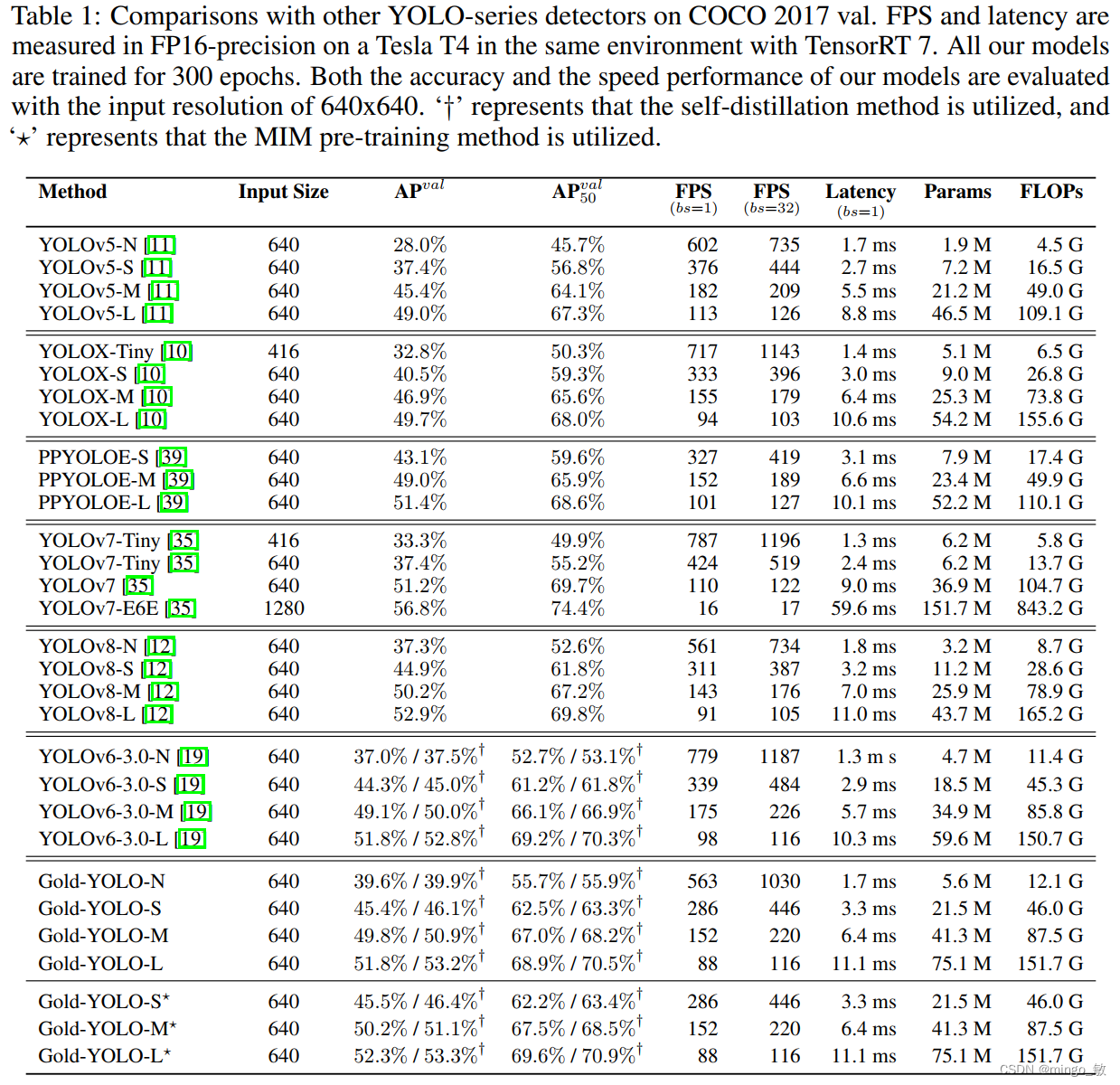
在过去的几年中,YOLO系列模型已经成为实时目标检测领域的领先方法。许多研究通过修改架构、增加数据和设计新的损失函数,将基线推向了更高的水平。然而以前的模型仍然存在信息融合问题,尽管特征金字塔网络(FPN)和路径聚合网络(PANet)已经在一定程度上缓解了这个问题。因此,本研究提出了一种先进的聚集和分发机制(GD机制),该机制通过卷积和自注意力操作实现。这种新设计的模型被称为Gold-YOLO,它提升了多尺度特征融合能力,在所有模型尺度上实现了延迟和准确性的理想平衡。此外,本文首次在YOLO系列中实现了MAE风格的预训练,使得YOLO系列模型能够从无监督预训练中受益。Gold-YOLO-N在COCO val2017数据集上实现了出色的39.9% AP,并在T4 GPU上实现了1030 FPS,超过了之前的SOTA模型YOLOv6-3.0-N,其FPS相似,但性能提升了2.4%。

2 Gold-YOLO

2-1 Preliminaries
YOLO系列的中间层结构采用了传统的FPN结构,其中包含多个分支用于多尺度特征融合。然而,它只充分融合来自相邻级别的特征,对于其他层次的信息只能间接地进行“递归”获取。

传统的FPN结构在信息传输过程中存在丢失大量信息的问题。这是因为层之间的信息交互仅限于中间层选择的信息,未被选择的信息在传输过程中被丢弃。这种情况导致某个Level的信息只能充分辅助相邻层,而对其他全局层的帮助较弱。因此,整体上信息融合的有效性可能受到限制。
为了避免在传输过程中丢失信息,本文采用了一种新颖的“聚集和分发”机制(GD),放弃了原始的递归方法。该机制使用一个统一的模块来收集和融合所有Level的信息,并将其分发到不同的Level。通过这种方式,作者不仅避免了传统FPN结构固有的信息丢失问题,还增强了中间层的部分信息融合能力,而且并没有显著增加延迟。
2-2 低阶聚合和分发分支 Low-stage gather-and-distribute branch
从主干网络中选择输出的B2、B3、B4、B5特征进行融合,以获取保留小目标信息的高分辨率特征。

低阶特征对齐模块 (Low-stage feature alignment module): 在低阶特征对齐模块(Low-FAM)中,采用平均池化(AvgPool)操作对输入特征进行下采样,以实现统一的大小。通过将特征调整为组中最小的特征大小 ( R B 4 = 1 / 4 R ) (R_{B4} = 1/4R) (RB4=1/4R),我们得到对齐后的特征 F a l i g n F_{align} Falign。低阶特征对齐技术确保了信息的高效聚合,同时通过变换器模块来最小化后续处理的计算复杂性。其中选择 R B 4 R_{B4} RB4 作为特征对齐的目标大小主要基于保留更多的低层信息的同时不会带来较大的计算延迟。
低阶信息融合模块(Low-stage information fusion module): 低阶信息融合模块(Low-IFM)设计包括多层重新参数化卷积块(RepBlock)和分裂操作。具体而言,RepBlock以 F a l i g n ( c h a n n e l = s u m ( C B 2 , C B 3 , C B 4 , C B 5 ) ) F_{align} (channel= sum(C_{B2},C_{B3},C_{B4},C_{B5})) Falign(channel=sum(CB2,CB3,CB4,CB5))作为输入,并生成 F f u s e ( c h a n n e l = C B 4 + C B 5 ) F_{fuse} (channel= C_{B4} + C_{B5}) Ffuse(channel=CB4+CB5)。其中中间通道是一个可调整的值(例如256),以适应不同的模型大小。由RepBlock生成的特征随后在通道维度上分裂为 F i n j P 3 Finj_P3 FinjP3和 F i n j P 4 Finj_P4 FinjP4,然后与不同级别的特征进行融合。

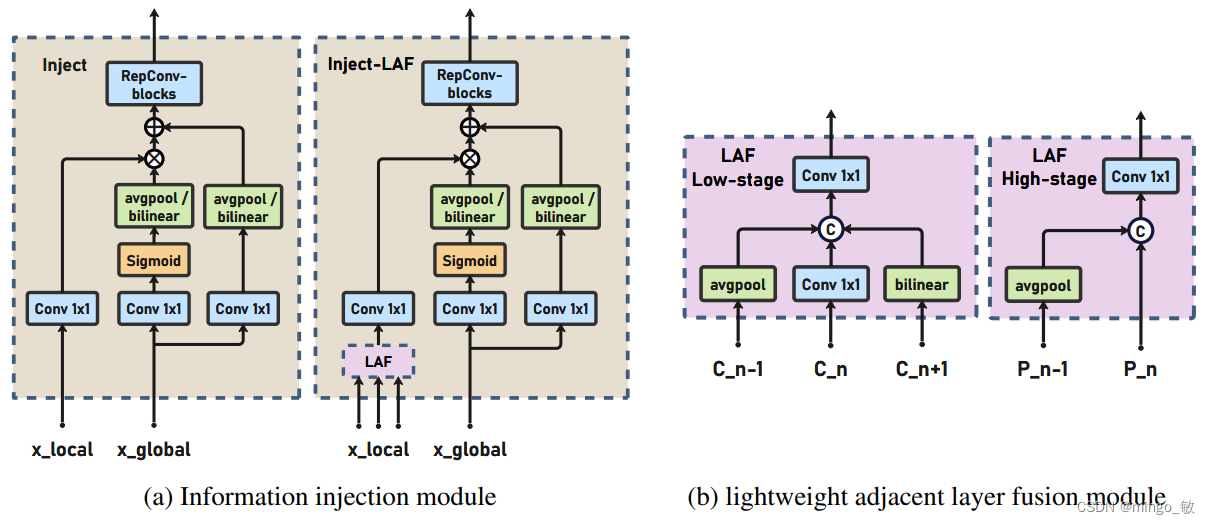
信息注入模块(Information injection module): 分别输入当前层的特征 F l o c a l F_{local} Flocal和由IFM生成全局注入信息 F i n j F_{inj} Finj。使用两个不同的Convs与 F i n j F_{inj} Finj进行计算,分别得到 F g l o b a l e m b e d F_{global_embed} Fglobalembed和 F a c t F_{act} Fact。而 F l o c a l e m b e d F_{local_embed} Flocalembed则是使用Conv对 F l o c a l F_{local} Flocal进行计算得到的。融合后的特征 F o u t F_{out} Fout通过注意力机制计算得到。由于 F l o c a l F_{local} Flocal和 F g l o b a l F_{global} Fglobal之间的尺寸差异,使用平均池化或双线性插值来根据 F i n j F_{inj} Finj的尺寸对 F g l o b a l e m b e d F_{global_embed} Fglobalembed和 F a c t F_{act} Fact进行缩放,以确保适当的对齐。在每次注意力融合的最后添加RepBlock来进一步提取和融合信息。
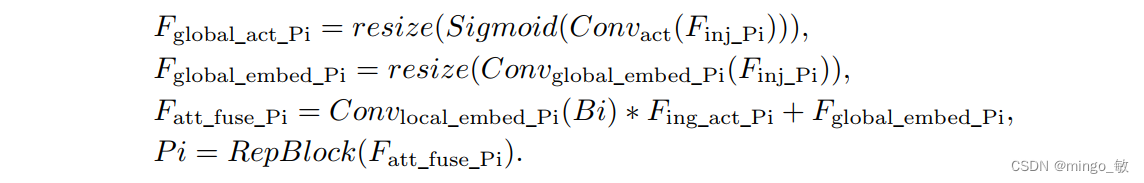
2-3 高阶聚合和分发分支 High-stage gather-and-distribute branch
高级全局特征对齐模块(High-GD)将由低级全局特征对齐模块(Low-GD)生成的特征{P3, P4, P5}进行融合。

高级特征对齐模块(High-stage feature alignment module): High-FAM由avgpool组成,用于将输入特征的维度减小到统一的尺寸。具体而言,当输入特征的尺寸为{
R P 3 R_{P3} RP3, R P 4 R_{P4} RP4, R P 5 R_{P 5} RP5}时,avgpool将特征尺寸减小到该特征组中最小的尺寸( R P 5 R_{P5} RP5 = 1/8R)。由于transformer模块提取了高层次的信息,池化操作有助于信息聚合,同时降低了transformer模块后续步骤的计算需求。
高级信息融合模块(High-stage information fusion module): 高级信息融合模块(High-IFM)包括transformer块和一个分割操作,该操作包括三个步骤:(1)使用transformer块将由High-FAM导出的 F a l i g n F_{align} Falign组合起来,得到 F f u s e F_{fuse} Ffuse。(2)通过Conv1×1操作将 F f u s e F_{fuse} Ffuse通道减少到sum( C P 4 C_{P4} CP4, C P 5 C_{P5} CP5)。 (3)通过分割操作,将 F f u s e F_{fuse} Ffuse沿通道维度分成 F i n j N 4 F_{inj_N4} FinjN4和 F i n j N 5 F_{inj_N5} FinjN5,然后用于与当前层级特征进行融合。
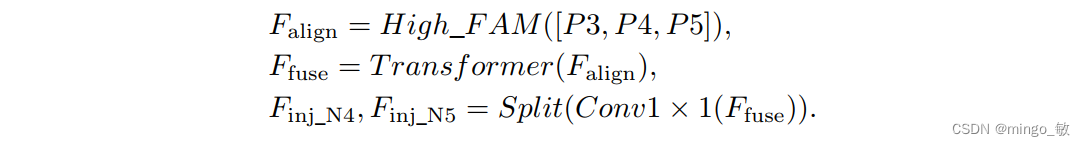
Transformer融合模块由多个堆叠的transformer组成,transformer块的数量为L。每个transformer块包括一个多头注意力块、一个前馈网络(FFN)和残差连接。采用与LeViT相同的设置来配置多头注意力块,使用16个通道作为键K和查询Q的头维度,32个通道作为值V的头维度。为了加速推理过程,将层归一化操作替换为批归一化,并将所有的GELU激活函数替换为ReLU。为了增强变换器块的局部连接,在两个1x1卷积层之间添加了一个深度卷积层。同时,将FFN的扩展因子设置为2,以在速度和计算成本之间取得平衡。
信息注入模块(Information injection module): 高级全局特征对齐模块(High-GD)中的信息注入模块与低级全局特征对齐模块(Low-GD)中的相同。在高级阶段,局部特征(Flocal)等于Pi,因此公式如下所示:
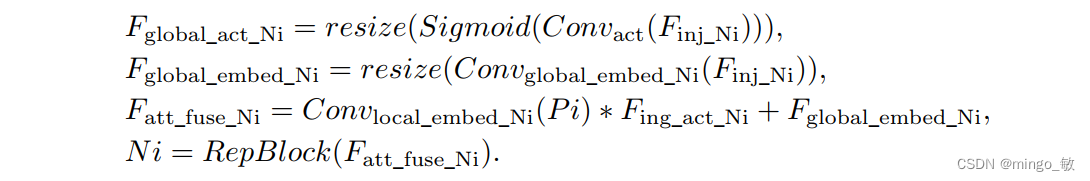
2-4 增强的跨层信息流动 Enhanced cross-layer information flow
为了进一步提升性能,从YOLOv6 中的PAFPN模块中得到启发,引入了Inject-LAF模块。该模块是注入模块的增强版,包括了一个轻量级相邻层融合(LAF)模块,该模块被添加到注入模块的输入位置。为了在速度和准确性之间取得平衡,设计了两个LAF模型:LAF低级模型和LAF高级模型,分别用于低级注入(合并相邻两层的特征)和高级注入(合并相邻一层的特征)。它们的结构如图5(b)所示。为了确保来自不同层级的特征图与目标大小对齐,在实现中的两个LAF模型仅使用了三个操作符:双线性插值(上采样过小的特征)、平均池化(下采样过大的特征)和1x1卷积(调整与目标通道不同的特征)。模型中的LAF模块与信息注入模块的结合有效地平衡了准确性和速度之间的关系。通过使用简化的操作,能够增加不同层级之间的信息流路径数量,从而提高性能而不显著增加延迟。
3 Experiment