这两天,英特尔发布了广受期待的酷睿Ultra CPU。代号为Meteor Lake(以下简称MTL)的新CPU带来了许多个第一次,技术创新可以说是全方位和这几年最多的一次,非常值得期待。
尤其对从业人员和技术爱好者来说,了解这些新功能,可以帮助大家从中一窥未来x86技术发展的趋势,值得大书特书。为此,本着将这些新功能说好说透的原则,我来带大家详细了解一下酷睿Ultra(MTL)新亮点背后的知识:
- MTL的Intel 4制程,将晶体管密度提高了一倍,怎么算出来的?
- MTL采用现在流行的Chiplet封装形式,有哪些Tile(Die)?是如何划分的,为什么这么分?
- MTL 3D封装是怎么组织的?
- MTL采用三级混合内核架构,它背后的运行机制是怎样的?
- MTL第一次在芯片内部集成NPU,形成三级AI加速引擎,它们各自适用于哪种场景?有什么好处?
制程升级:Intel 4工艺
如果说对Intel目前来讲,什么东西最重要,那一定是制程、制程、制程(重要的事说三遍)了。
Intel这两年加紧了制程追赶的步伐,承诺四年五个节点的目标。
今年来到了承上启下的Intel 4工艺节点,用它来制造酷睿Ultra处理器:

为了在2024年实现制程反超,Intel计划分成两步走:先在仍然采用FinFET的基础上,引入EUV光源;再在下一代中引入RibbonFET和PowerVia(原计划这一步也是分两代,后来决定一代同时引入,落地在Intel 20A工艺节点上)。
作为引入EUV光源的第一代制程,Intel 4工艺需要为未来Intel 3(预计服务器Granite Rapids将采用这个工艺)打前站,更要为之后的新晶体管工艺奠定基础,可谓身负重要使命。
Intel 4工艺目前为止,成功地完成了探路先锋的角色,无论从晶体管密度、良率、制造成本等方面都表现出色,为下一代工艺打下了良好的基石。
在晶体管密度方面,Intel宣布DIE的面积相比Intel 7有一倍的缩减(0.5x),也可以理解为晶体管密度增加了一倍。它是怎么计算出来的?我们先来看晶体管制程的关键指标:
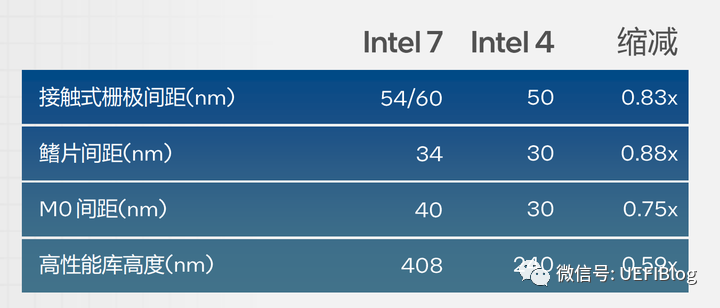
可能有些同学对中文的部分不是很熟悉,也为了后文方便,这里需要特别说明一下:
- 接触式栅极间距:Contacted Gate Pitch,以下统称CGP。
- 鳍片间距:Fin Pitch,以下简称FP。
- M0间距:M0 Pitch,也就是Minimal Metal Pitch,以下简称MMP。
如果我们单看这些数据,没有一个缩减了一倍(0.5x),也没有一个到个位数的nm级别,那所谓等效某厂4nm和缩减一倍从何而来呢?
这就牵扯出一段公案:xnm工艺名称的演进和混淆了。
而关于它本专栏多有讨论,这里不再展开。
为了避免口水战,Intel的Mark Bohr在14nm时候提出了计算半导体工艺水平的公式:
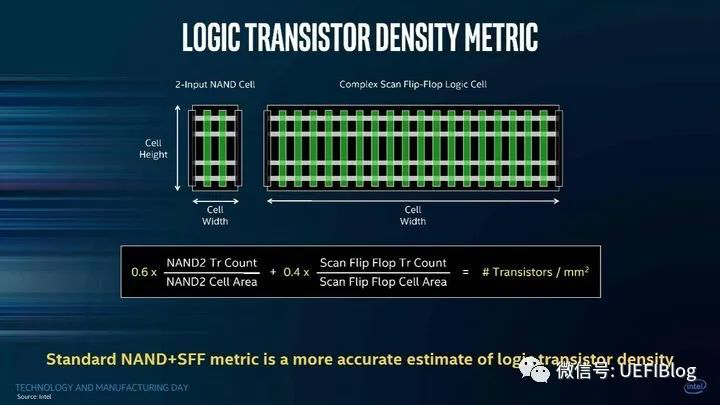
即应该用一个标准NAND2单元和一个标准Scan Flip-Flop(SFF)单元的加权密度来衡量整体密度。
这有些道理,因为如果单纯计算Fin Pitch不能反应多Fin的单元库密度和降低单元宽度(Cell Width)的努力(如减少Dummy Gate);
而CPP和MMP的乘积的方式,无法反应单元高度(Cell Height)的降低的诸多努力(如COAG,Contact Over Active Gate)。毕竟单位面积能放多少个单元才是最准确的密度。
这里Cell Height可能有些朋友误认为是Cell在立体空间长宽高中的高,实际上这两个参数是平面的,可以认为Cell Width是x轴,而Cell Height是y轴,通常意义的高是z轴,关于它的部分我们后面会讲。
Intel 4的制程带来的正是x轴和y轴的缩减:
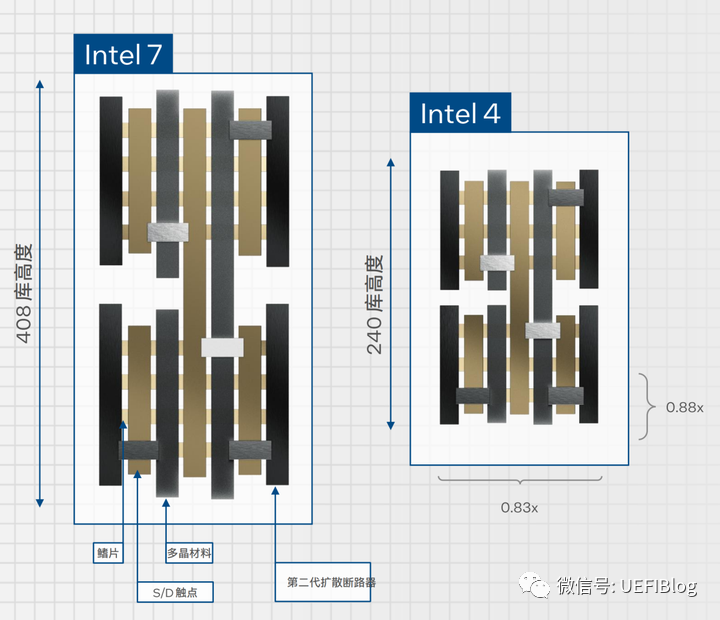
很多朋友可能看不太懂这个图,我来解释一下。所谓单元库,是指芯片无非是一个个单元构成。
而一个个单元,则是几个Fin与Gate的组合,为了减少本底功耗,一般都是由上下端接地和电源,中间加翻转和各种组合,组成各种标准门电路。
图中就是一个标准的背靠背的单元。各种单元的仓库就是单元库。那么何为高性能单元库?
这是因为在性能和功耗限制下,单元的Fin的个数等参数对不同性能有不同的最优配置,于是形成各种单元库,如HD(高密度,short libraries,2Fins)、HP(高性能,mid-height libraries,3Fins)和UHP(超高性能,tall libraries,4Fins)【1】。
图中Intel 7工艺部分,是一个4 Fin的超高性能库标准单元(Intel资料显示是HP,疑似应为UHP),它的高度是408nm;Intel 4工艺,超高性能库标准单元变成3Fin,Fin Pitch也缩减了0.88x,高240nm。整体Cell y轴缩短了0.59,x轴因为CGP缩小而缩短了0.83。所以算下来:
0.59 x 0.83 = 0.4897
约等于0.5x,整个单元缩减了一倍。这下应该比较清楚了。注意图中没有画出Dummy Gate和Dummy Fin。
单元密度增加,也让每个Die里面单位空间可以放入更多的Cell,也就是晶体管密度增加了,可以进一步提高性能。
除了晶体层密度增加之外,铜连接层也有不少变化:

首先是M0到M4的材质变了。这导致M0 Pitch直接从40nm减少成为30nm。
这里要科普一下这个图中的右边部分,有人问芯片是不是像电路板有很多层?回答是“是也不是”。
晶体管层其实只有一层,上面密密麻麻有很多金属导线层(MTL有17层),现在晶体管层越来越小,太多的单元要互联,导致金属导线层部分越来越复杂,它才是占据芯片z轴绝大部分空间的主体。
金属导线层越往上越大,最上面一层再植球,接着翻过来屁股冲上。
晶体管层从最下面变到在最上面,接触散热材料(它也是发热最多的部分),再经过一些其他处理,就变成了我们看到的Die了。
当然这个结构在PowerVia之后会有所改变,我们将在Intel 20A制程介绍中关注。
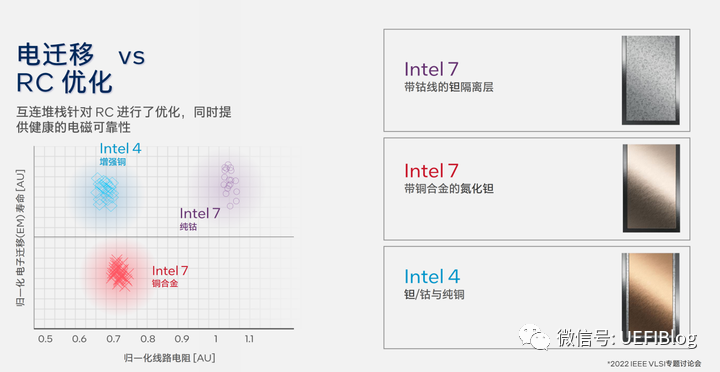
金属导线层金属的选择,尤其是下面几层金属的选择非常重要。
最早金属是铝,后来换成电阻更小的铜。但因为M0到M4,线宽非常窄(因为下面FP非常小),铜在太窄的情况下电子迁移会越来越严重,影响晶体管寿命。
前期还可以通过在铜周围掺杂别的物质来减缓(barrier 和 liner)。
后来不得不换成了金属钴,但钴的电阻又比铜大,增加功耗。
Intel 4在M0到M4这5层中采用了新的增强型的铜的金属工艺,来取得了性能和寿命的重新平衡。
另外采用EUV之后,多重曝光的需要减少了很多,直接减少了掩模的个数,相比Intel 7少了20%的掩膜,工艺步骤更是少了5%:
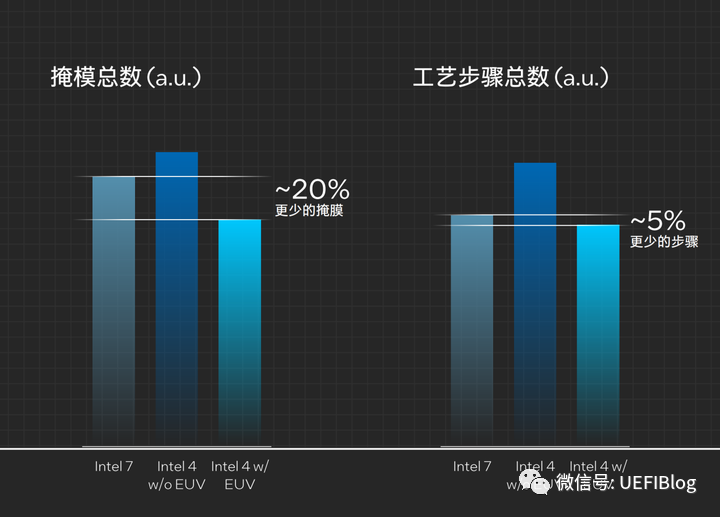
采用EUV的Intel 4工艺,现在良率非常好了。
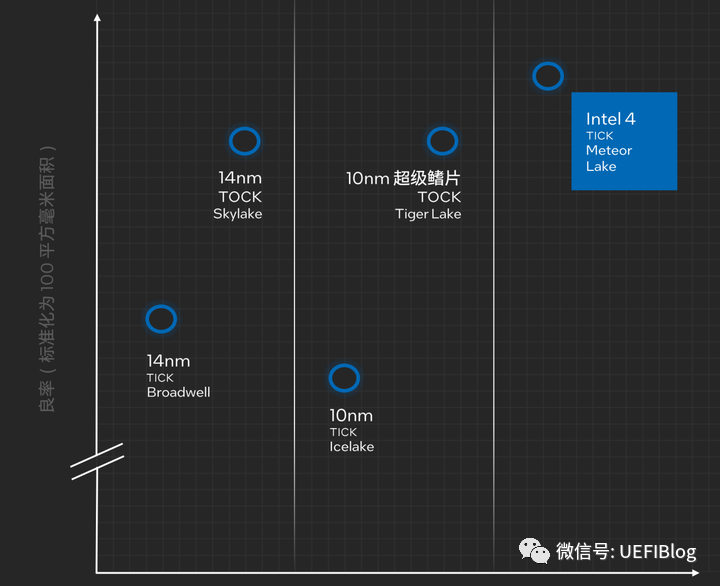
消费品市场的CPU的良率,第一代的Intel 4就超过14纳米或者是10纳米优化版(14nm+或者10nm+)的良率水平了:
Chiplet和3D封装
继服务器CPU之后,Intel也在消费品CPU中引入了Chiplet封装形式。
但和服务器SPR Chiplet采用几乎完全相同的几个Die,然后用EMIB将其拼装在一起不同,这次Intel对芯片内部的各种IP进行了完全的重组,分成各个专用的Tile(就是Die啦),之后用Foveros将其组合在一起。我们先来看Foveros。
EMIB实际上是一种2.5D的封装,本专栏多次做过介绍。也介绍过曾经应用在Lakefield CPU上的Foveros封装,它本质上是一种POP的3D封装形式。
MTL这次引入了一个Base Tile作为基座,再在其上用Foveros将各个Die堆叠到上面:
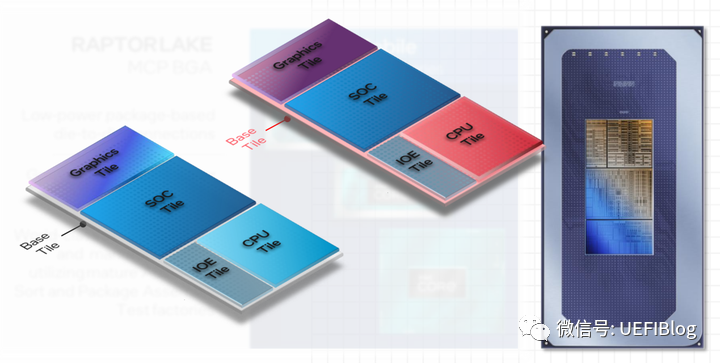
从单一大芯片,到Chiplet的小型化拼接,是现在风头正劲的趋势,MTL的这次改革,相当于化整为零,减少了每个Die的尺寸,从而增加了良品率和产出更多Die(因为边缘废品减少)。
更可以解耦各个Die的制程,甚至生产厂家也可以不同。
CPU Tile和GPU Tile一般用最高制程,IOE Tile和SOC Tile,则可以采用更加便宜的低制程。这些Tile也都可以混合生产,换用别家第三方代工,如台积电。
英特尔CPU的生产过程也作出了改变。
Intel从自家工厂或者第三方代工厂把这些Tile(如Graphic Tile由台积电代工)生产出来,pass检测后,直接把它们用Foveros封装在未切割的布满Base Tile的晶圆上面:
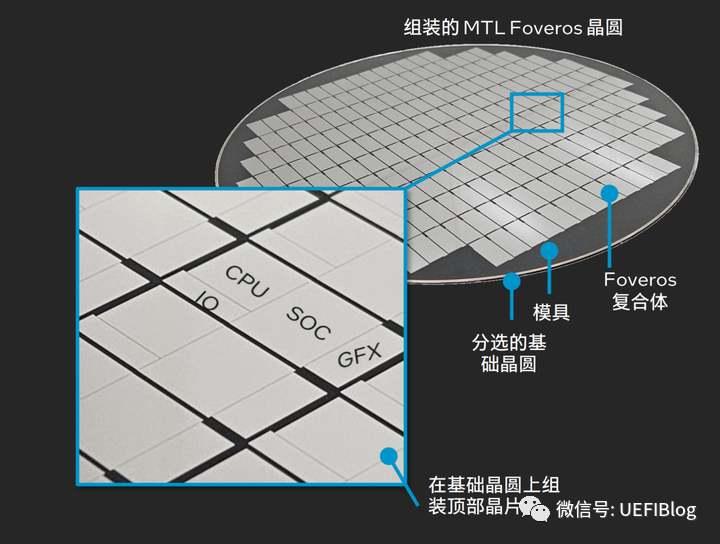
之后再进行切割、检测和封装。这点类似现在的硅中介封装。
那么拆解的原则是什么呢?
Intel把原来的一个大芯片,拆解成4个小芯片:
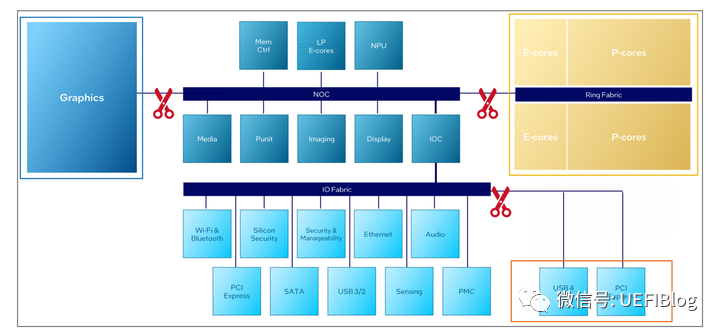
Tile拆解的原则示意图 来源:Intel
三把小剪刀将整个带核显的原CPU+原PCH重新分割成4块:计算密集型的一块叫做CPU Tile;
核显GPU一块叫做Graphic Tile;
原来CPU Uncore和南桥大部分功能变成了SOC Tile;
一部分高速外部总线(PCIe Gen5和USB 4/TBT)变成了IOE Tile。
CPU Tile集合了性能核(P-Core)和能效核(E-Core),这点完全符合大众预期。
IOE Tile集中了高速外部总线,也没有什么特殊之处。有意思的是Graphic Tile和SOC Tile。
Graphic Tile将上一代独显大部分功能和高性能特性搬到了核显中,大大提高了核显的游戏和图像计算密集型应用的体验,属于常规操作。
更有意思的是,在之前的设计中,核显一般内置了各种视频流解码器和Display Engine,这次将这两个部分给移出来到SOC Tile中,为什么这么做呢?当然是为了省电了。
我们一般做笔电BenchMark时候有一必作项是电池续航测试,基本会测“现代办公”和“视频播放”这两种。
现在这两项都不需要Graphic Tile参与了,可以直接关掉(Power Gate),更夸张的是,如果负载不重,甚至CPU Tile也可以关闭!
那控制流是谁来处理的呢?
这就不得不介绍另一个x86界的新创新:三级内核和SOC Tile中内置的低功耗能效核(LP E-Core)构成的低功耗岛了。
三级混合内核架构
Intel在12代酷睿(ADL)中引入性能核和能效核这种大小核的混合内核架构,取得非常不错的效果。
这一次Intel更进一步,除了升级性能核(P-Core,Redwood Cove)和能效核(E-Core,Crestmont)这种常规操作之外,更是在PC CPU中第一次引入了大中小这种三级混合内核架构,这个新引入的“更小”核就是整合在SOC Tile中的两个低功耗能效核LP E-Core,Intel称之为3D高性能混合架构:
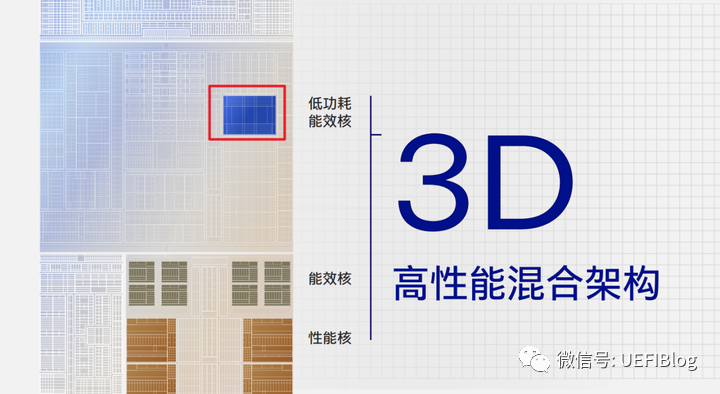
这两个新增的LP E-Core不像以前做带外处理的小核心,它们和真正的CPU内核一样,是可见和可用(可以被发现和调度的)。
如图中,我们看到4个P-Core(算上HT,是8个Thread),8个E-Core(4个一组)和2个LP E-Core。
这样在Windows的任务管理器中,我们就可以看到:8+8+2=18个Thread了。
尽管三级混合内核架构并不是第一次出场(某些ARM SOC中已经可以看到),但确实是在PC中第一次得到应用。
三级内核,每种都有自己最佳能耗比区间:
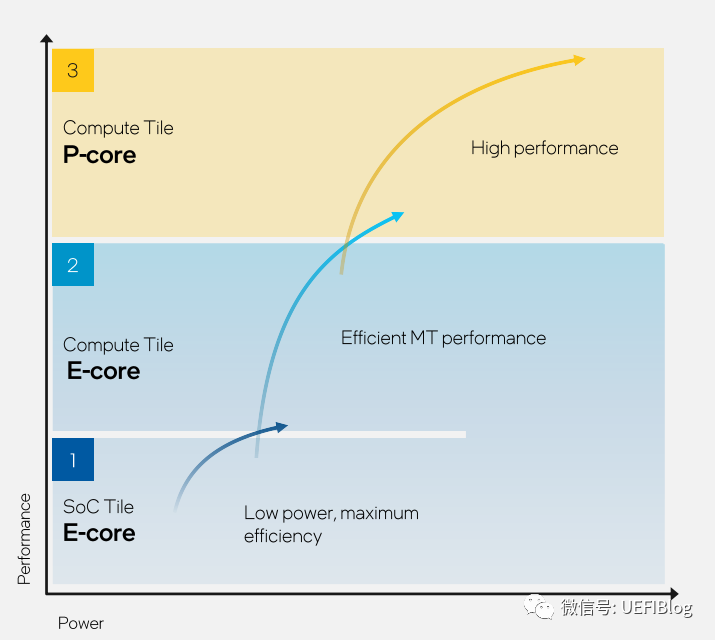
总的来说,LP E-Core在低负载时能耗比最好;E-Core在中负载时能耗比最好;P-Core在重载时能耗比最好。
要让它们物尽其用,真正在合适的时机用上合适的内核,这就离不来优化的调度器了。
为了配合新的三级混合内核架构,Intel和微软合作又一次升级了硬件线程调度器(所以要配合最新的Windows 2023H2)。
Intel Thread Director实际上并不直接调度线程,而是为操作系统的线程调度器提供Hint,实时更新一张Hint表。
通过将指令集合在三种内核的执行效率把它们分成四个Class,之后为每个内核进行推荐打分,给Windows线程调度器参考:
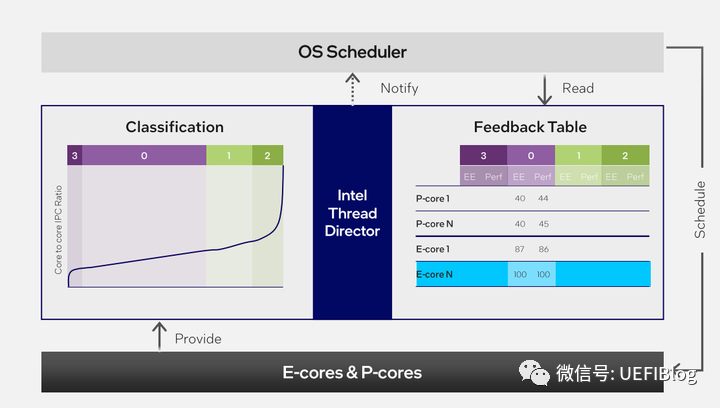
之后由操作系统调度器结合现实情况(如是前台还是后台,性能场景还是效能场景等),进行实时调度。
注意Hint Table的打分值是实时的,而且会根据当时的Power,甚至是否刚执行了某些高功耗指令而动态改变,可以做到精准推荐。
在12代酷睿引入两级混合内核之初,网上发起了各种论战,对这种改变究竟是好是坏,议论纷纷,莫衷一是。
经过12代和13代两代酷睿的现实检验,目前的主流观点对混合架构还是持有肯定态度。
这一次又引入一级,我可以脑补出下一次大论战的样子。
实践是检验真理的唯一标准,是骡子是马拉出来溜溜,我们尽可以让子弹再飞一会。
有的朋友可能会问,为什么新的LP E-Core不被整合在CPU Tile,而被放在SOC Tile中呢?这就是酷睿Ultra的另一个创新点:低功耗岛:

SOC Tile作为一个低功耗岛,实际上集合了常见低功耗应用场景所要用到的控制流和数据流的所有要素。
在典型“视频播放”应用场景中,LP E-Core足以应付控制流,而从传统核显迁移进来的视频解码器和Display Engine可以让数据流顺畅显示在屏幕上。
从而,CPU Tile和Graphic Tile,甚至IOE Tile都可以关闭!
只留下低功耗的SOC Tile孤独地服务各位。
相信笔电的电池续航BenchMark数值可以大幅提高,小伙伴们再也不要到处找电源插座了。
我们注意到AI单元NPU也在低功耗岛中,这是为什么呢?
NPU与AI加速
在这个AI的时代,Intel第一次在芯片中集成了AI专用的NPU,它和核显GPU、CPU,也形成了三级AI加速:

GPU、NPU和CPU都可以承接AI算力,侧重点不同。CPU AI算力能耗比最不划算,但响应快;GPU算力强大,能耗比还可以;NPU算力中等,能耗比最好。下面是一个比较典型的生成式AI Stable Diffusion的例子:
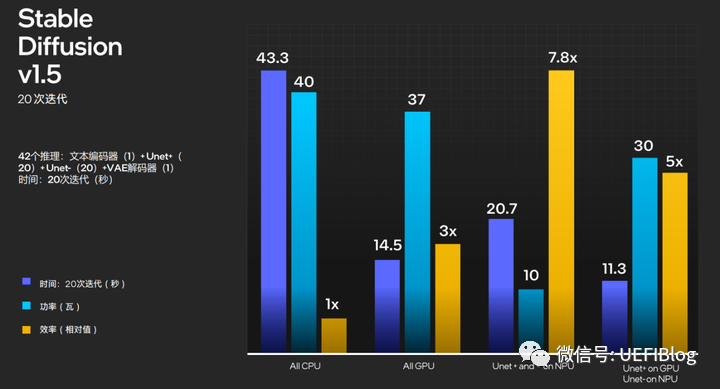
三级混合内核调度靠Thread Director,三级AI引擎调度其实可以使用OpenVINO。它一套接口可以支持三种AI引擎,十分方便。
NPU引入CPU中,一些推理的AI运算完全可以在PC上运行,效率相比CPU提升非常巨大。可以做一些非常Cool的应用,相应速度和隐私性也提高很多。需要说明的是,不久之前AMD上市的Phoenix笔电CPU也带有AI芯片(XNDA),酷睿Ultra的NPU性能要强很多,而且内置在芯片中,而不是外置的形式。
回到上一个问题,NPU为什么在低功耗岛里面?
疫情时代,大家都开过视频会议。
现在视频会议花头越来越多,背景虚化等都是常规操作,还有自动跟踪眼球、智能分区,甚至PS一个眼球等等高级功能。
这些都离不开AI运算,尽管现在都可以用内核推理完成,但效率很低,功耗较高。
现在NPU+LP E-Core完全可以完成控制流、数据流和AI运算的闭环,SOC Tile就可以完成视频会议了,功耗应该会非常低。
结论
因为篇幅的原因,酷睿Ultra还有大量的新功能没有覆盖到。
如增强的IO,大大加强的Graphic引擎的细节等等。
Intel酷睿Ultra一次带来很多重大变革:跨代的制程更新、模块化重构、Chiplet Foveros封装、三级混合内核架构、芯片整合NPU和其他诸多新功能,可谓Intel 40年来PC处理器最大的变革,非常值得期待。预计12月上市,等我拿到量产成品(QS)CPU会为大家做详细测评,敬请期待。
参考资料
2023-09-22