论文原文:Staleness-aware Async-SGD for Distributed Deep Learning
ABS
使用异步 S G D SGD SGD的时候,如何控制超参数是一个重要的问题(例如如何根据训练的进行而调整学习率),超参数的设置对于异步 S G D SGD SGD有着很重要的影响。
本文提出了异步 S G D SGD SGD的一种变体,该方法能够根据梯度延迟而调整学习率。并且对于该算法的收敛性做了理论保证。
1 INTRO
通常采用的分布式机器学习方法有 S S G D SSGD SSGD(同步随机梯度下降)和 A S G D ASGD ASGD(异步随机梯度下降)。
对于 S S G D SSGD SSGD来说,每一轮所有工作结点必须等待最慢的工作结点完成计算后才能开始下一轮的计算,这极大程度上影响了训练速度。
而对于 A S G D ASGD ASGD来说,可以不用等待所有工作结点完成本轮计算,而是没有一个工作结点完成计算,该工作结点更新后可以直接进行下一轮的计算,这导致了新的问题:梯度过期,即结点正在计算的参数可能落后于当前的最新的参数。这种影响是巨大的,当训练轮数固定, A S G D ASGD ASGD的训练效果要比 S S G D SSGD SSGD差得多。
作者发现 A S G D ASGD ASGD的收敛程度会极大的收到超参数(例如学习率和批量大小)和分布式系统的实现方式(例如同步协议,结点的个数)的影响,而目前缺少关于设置超参数来改善 A S G D ASGD ASGD的效果的研究。
于是本文的作者决定提出一种能够自动调节学习率的 A S G D ASGD ASGD这样好能够使 A S G D ASGD ASGD免收梯度过期的困扰。在该方法中,会记录梯度过期,同时将学习率除以梯度过期的程度以获得新的学习率。并且证明了该方法的收敛速率与 S S G D SSGD SSGD一样。
之前一些相关工作通过指数级别的学习率减少能够在结点数量较少的分布式系统上有着不错的效果,但是在大型的分布式系统的时候,学习率会随着训练的进行变成一个特别小(接近于 0 0 0)的数字,这会导致整个系统的收敛速度过慢。
2 System Architecture
这一部分会描述整个算法的设计,这里给出了两种算法的架构:
- n − s o f t s y n c p r o t o c o l n-softsync\ protocol n−softsync protocol:能够感知一部分的梯度过期并且通过软同步防止发生过多的过期;
- h a r d s y n c p r o t o c o l hardsync\ protocol hardsync protocol:也就是 S S G D SSGD SSGD,作为 B a s e l i n e Baseline Baseline进行对比。
2.1 Architecture Overview
一些参数的说明:
- λ \lambda λ:工作结点的个数;
- μ \mu μ:每个节点的批量大小;
- α \alpha α:学习率;
- E p o c h Epoch Epoch:迭代版本;
- T i m e s t a m p Timestamp Timestamp:时间戳,每一次参数更新时间戳会增加。每一次的梯度会记录当前的时间戳。
- τ i , l \tau_{i,l} τi,l:工作结点 l l l的梯度过期程度。如果一个工作结点在 i i i时刻发送了 j j j时刻的梯度,这意味着当前发送的梯度是过期的,那么 τ i , l = i − j \tau_{i,l}=i-j τi,l=i−j。
每个工作结点会依次执行下面的操作:
- g e t M i n i b a t c h getMinibatch getMinibatch:获取本轮用于计算的批量。
- p u l l W e i g h t s pullWeights pullWeights:从参数服务器获取权重。
- c a l c G r a d i e n t calcGradient calcGradient:根据权重计算当前批量的梯度。
- p u s h G r a d i e n t pushGradient pushGradient:将计算后的梯度发送给参数服务器。
参数服务器会执行的操作如下:
- s u m G r a d i e n t sumGradient sumGradient:对收到的梯度进行聚合。
- a p p l y U p d a t e applyUpdate applyUpdate:用聚合后的梯度更新参数。
2.2 Synchronization Protocols
h a r d s y n c p r o t o c o l hardsync\ protocol hardsync protocol:在每轮更新的时候,参数服务器会在收到所有结点发送的梯度后,才会执行 s u m G r a d i e n t sumGradient sumGradient操作,之后进行 a p p l y U p d a t e applyUpdate applyUpdate只有当这两个操作完成后,工作结点才能够通过 p u l l W e i g h t s pullWeights pullWeights获取新一轮的参数,这意味着工作结点必须等待最慢的工作结点完成任务。虽然该方法速度比较慢,但是训练的精度却非常高。
n − s o f t s y n c p r o t o c l n-softsync\ protocl n−softsync protocl:该方法中参数服务器只需要在收到至少 c = [ λ n ] c=[\frac{\lambda}{n}] c=[nλ]个梯度后就可以进行这 c c c个结点的梯度聚合操作,之后进行参数更新,此时完成的节点就可以获取新的参数继续训练(其中 n n n是一个超参数,如果 n = λ n=\lambda n=λ这就和之前提出的 A S G D ASGD ASGD是类似的,本文的方法更新的学习率是动态变化的)。更新的公式如下图:
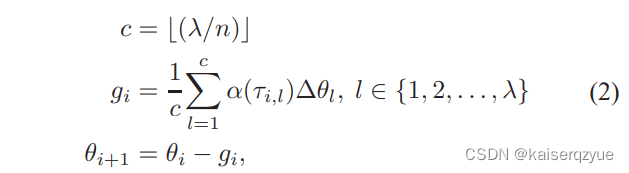
其中学习率会根据过期程度进行计算。
2.3 Implementation Details
本文的方法依然采取了一些同步机制,例如 p u l l W e i g h t s pullWeights pullWeights只有在 p u s h G r a d i e n t pushGradient pushGradient完成后才能够获取参数,这样能够保证模型的参数因为并发而出现不一致问题。
在实现中一个计算机可能存在多个工作结点。没有使用模型并行。
2.4 Staleness Analysis
对于 h a r d s y n c p r o t o c o l hardsync\ protocol hardsync protocol服务器必须受到所有结点的梯度后才会进行更新,所以不会发生过期的情况,也就是说 τ = 0 \tau=0 τ=0。
而对于不同取值 n n n发生的过期程度不同,作者对于 λ = 30 \lambda=30 λ=30不同的 n n n进行了 τ \tau τ的计算,结果如 F i g u r e 1 Figure\ 1 Figure 1所示:
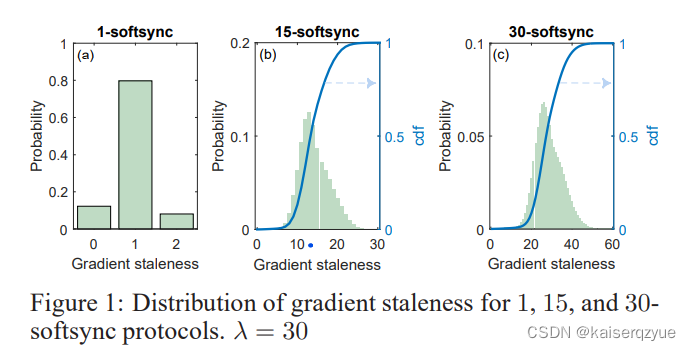
上述的结果让我费解的是当 n = 1 n=1 n=1的时候,这意味着参数服务器只有收到至少 30 30 30个梯度的时候才会进行参数的更新,也就是说这个时候理应和 S S G D SSGD SSGD产生相同的行为,也就是 τ = 0 \tau=0 τ=0会成立,但是实验结果表明并不是这样,所以我猜测这里收到的 30 30 30个梯度可能存在来自同一个结点的两次梯度,但是根据 2.3 2.3 2.3中的描述来看, p u l l W e i g h t s pullWeights pullWeights在 p u s h G r a d i e n t pushGradient pushGradient完成后才能执行,这似乎有点冲突了。
通过实验作者发现对于 n − s o f t s y n c p r o t o c l n-softsync\ protocl n−softsync protocl其中的 τ \tau τ大多数都等于 n n n。有了这个直观认识,就可以通过控制 n n n来控制能够容忍的过期程度。
时刻 i i i,结点 l l l的学习率由如下公式决定:
α i , l = α 0 τ i , l i f τ i , l > 0 α i , l = α 0 i f τ i , l = 0 \alpha_{i,l}=\frac{\alpha_0}{\tau_{i,l}}\quad if\ \tau_{i,l} > 0\\ \alpha_{i,l}=\alpha_0\quad if\ \tau_{i,l} = 0\\ αi,l=τi,lα0if τi,l>0αi,l=α0if τi,l=0
3 Theoretical Analysis
这一部分证明了收敛性,但是限于本人能力有限,没太看懂(主要是不太想看)。
4 Experimental Results
4.1 Hardware and Benchmark Datasets
这一部分介绍了使用的设备和数据集的细节。可以在原文中查看。
4.2 Runtime Evaluation
F i g u r e 2 Figure\ 2 Figure 2展示了不同的节点数量下,没收到一个梯度就进行更新的方法在两个数据集上带来的速度提升:
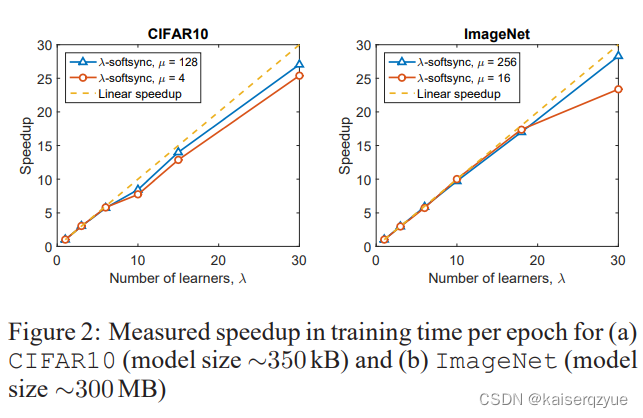
可以看到图表表明本文提出的方法提供了近似线性的加速(在结点个数增多的情况下)。
4.3 Model Accuracy Evaluation
F i g u r e 3 Figure\ 3 Figure 3展示了在数据集上 C I F A R 10 CIFAR10 CIFAR10上的训练误差和测试精度结果:(上面两张图使用的是固定学习率,而下面两张图则是会动态的更新学习率)

F i g u r e 4 Figure\ 4 Figure 4展示了在 I m a g e N e t ImageNet ImageNet上的结果:
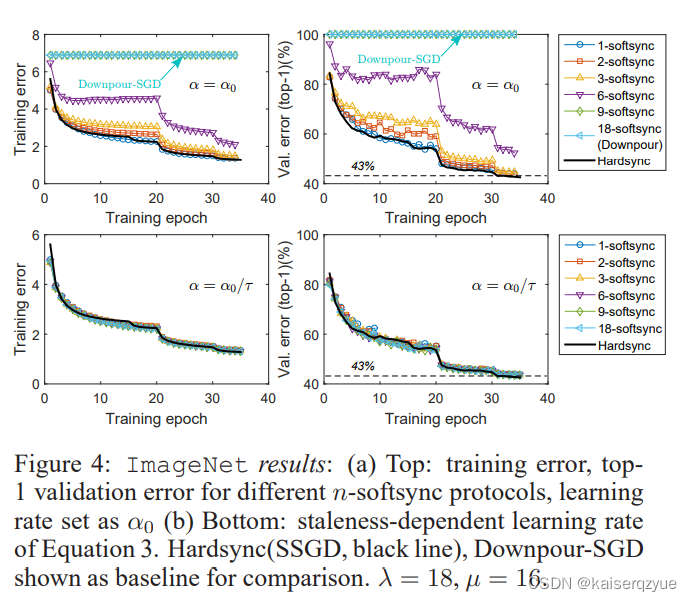
从图片的对比可以看到,当根据过期程度进行动态的更新学习率的时候, n − s o f t s y n c n-softsync n−softsync与 S S G D SSGD SSGD的贴合较好。
5 Conclusion
本文的贡献:
- 证明了 A S G D ASGD ASGD可以与 S G D SGD SGD拥有相同的收敛速度;
- 在一些数据集上量化了梯度过期的程度。同时实验中使用了最大为 30 30 30个的工作结点,算是比较大的分布式系统的尝试。