清理 数据清洗 是否合理? 多维度验证 群 群组 转换 ET2离线工程师

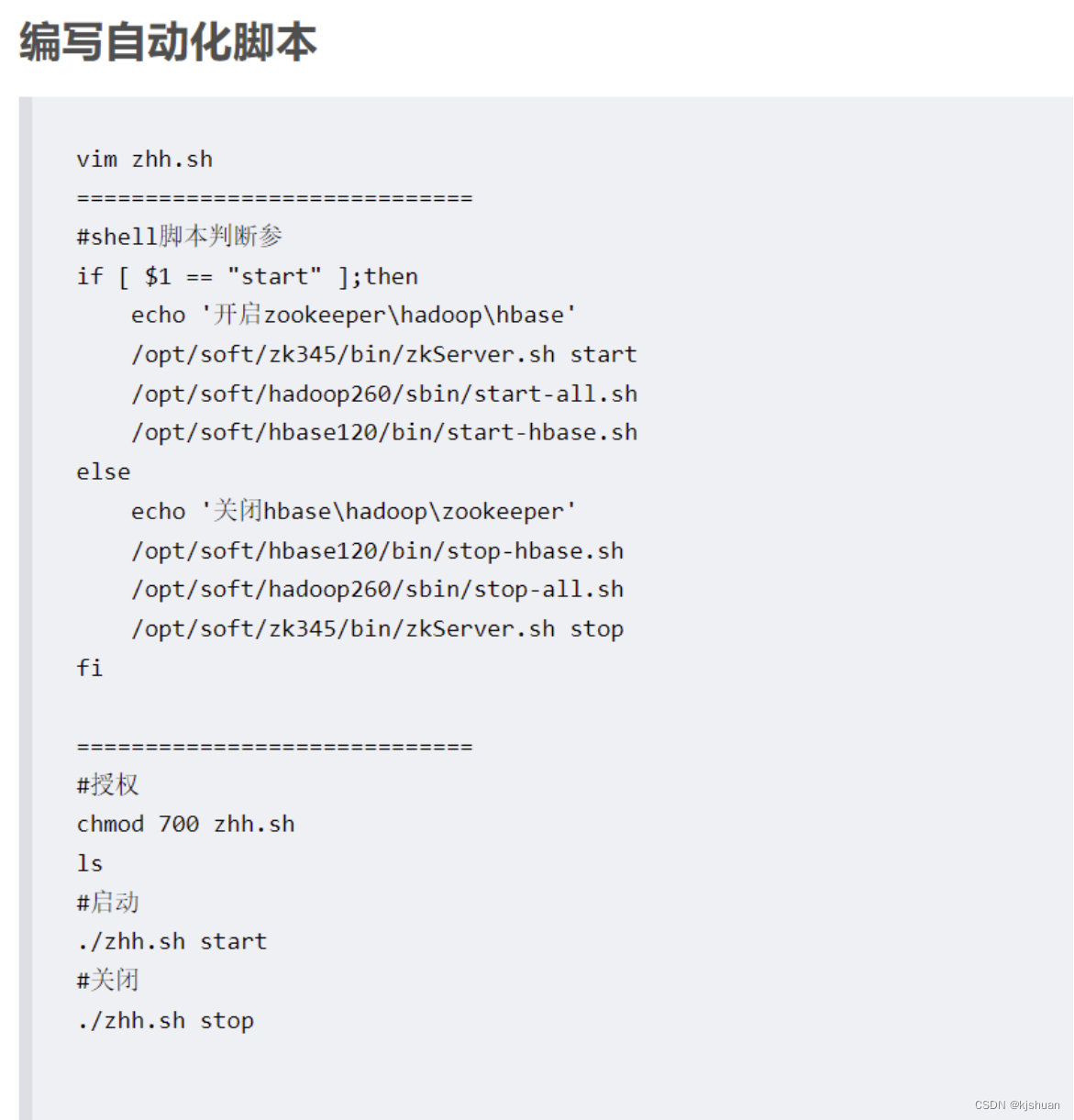
方法一 利用RandomAccessFile下载文件hash去重
public class App
{
public static void main( String[] args ) throws Exception {
//准备hash
HashMap<String, Integer> map = new HashMap<>();
//读文件
RandomAccessFile raf = new RandomAccessFile("D:\\bgdata\\bgdata01\\events.csv", "rw");
//跳过首行
raf.readLine();
//读一行行数据
String line="";
//循环读数据
while ((line=raf.readLine())!=null){
//读出的数据以逗号分割 取第一个
String eventid=line.split(",")[0];
//判断map是否包含 id
if (map.containsKey(eventid)){
map.put(eventid,map.get(eventid)+1);
//否则是第一次获取id 值设置为1
}else {
map.put(eventid,1);
}
}
//关闭流文件
raf.close();
//输出查看map大小 查看是否有重复
System.out.println(map.size()+"==============");
}
}

缺点:本次使用的文件数据300w 读取很慢 大概用了30分钟o(╥﹏╥)o
建议使用下面的方式
方法二 利用Mapreduce下载文件
2.1配置pom文件
<dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-client</artifactId> <version>2.6.0</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-mapreduce-client-core</artifactId> <version>2.6.0</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-hdfs</artifactId> <version>2.6.0</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-common</artifactId> <version>2.6.0</version> </dependency>
2.2配置 RcMapper类
public class RcMapper extends Mapper<LongWritable,Text ,Text, IntWritable> {
IntWritable one= new IntWritable(1);
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String eventid=value.toString().split(",")[0];
context.write(new Text(eventid),one);
}
}
2.3配置 RcReduce类
public class RcReduce extends Reducer<Text, IntWritable,Text,IntWritable>{
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int count=0;
for (IntWritable it : values) {
count+=1;
}
context.write(key,new IntWritable(count));
}
}
2.4配置RcCountDriver类
public class RcCountDriver {
public static void main(String[] args) throws Exception {
//实例化job对象
Job job = Job.getInstance(new Configuration());
//反射获取对象
job.setJarByClass(RcCountDriver.class);
//反射获取RcMapper对象
//设置对应的Text.class
job.setMapperClass(RcMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
//反射获取RcReduce对象
//设置对应的Text.class
job.setReducerClass(RcReduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//获取目标路径文件
FileInputFormat.addInputPath(job,new Path("file:///D:\\bgdata\\bgdata01\\events.csv"));
//标记下载文件地址
FileOutputFormat.setOutputPath(job,new Path("file:///d:/calres/cal01"));
/**
*Job运行是通过job.waitForCompletion(true),
* true表示将运行进度等信息及时输出给用户,
* false的话只是等待作业结束
*/
job.waitForCompletion(true);
}
}
点击测试即可!!
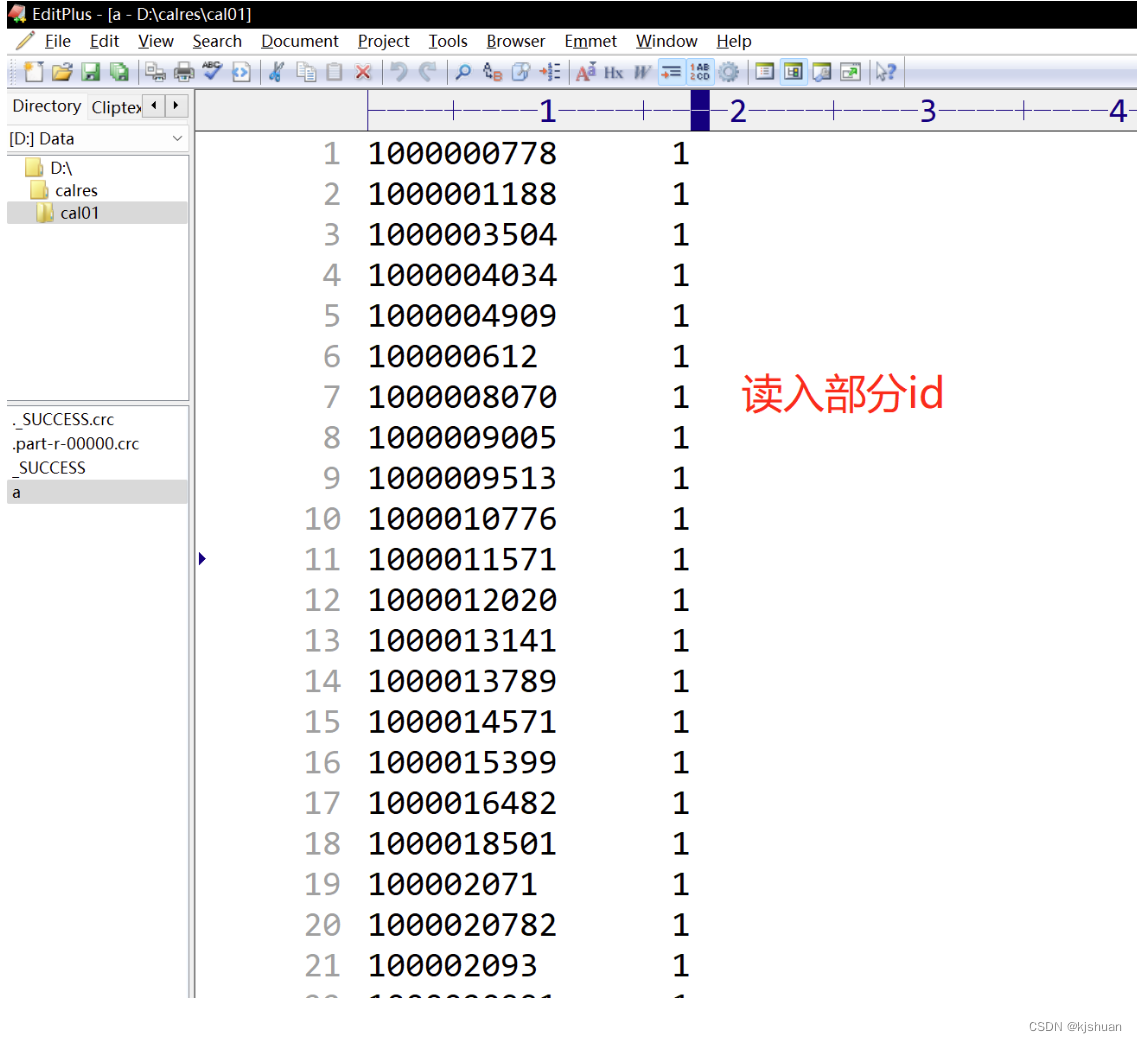
方法三. 利用Mapreduce去重
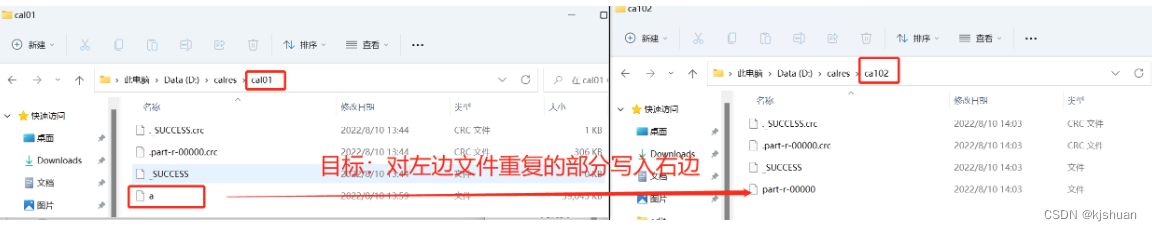
3.1配置CfMapper类
public class CfMapper extends Mapper<LongWritable, Text,Text, IntWritable> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//获取的值以空格分割
String[] infos = value.toString().split("\t");
//对第二个数据不是一的进行操作
if (!infos[1].equals("1")){
//获取第一个值,第二个不是1的值去空格
context.write(new Text(infos[0]),new IntWritable(Integer.parseInt(infos[1].trim())));
}
}
}
3.2配置CfCombiner类
public class CfCombiner extends Reducer<Text, IntWritable,Text,IntWritable> {
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
//配置k v键值对
context.write(key,values.iterator().next());
}
}
3.3配置CfCountDriver类
public class CfCountDriver {
public static void main(String[] args) throws Exception {
//实例化job对象
Job job = Job.getInstance(new Configuration());
//反射获取对象
job.setJarByClass(CfCountDriver.class);
//反射获取CfMapper对象
//设置对应的Text.class
job.setMapperClass(CfMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
//反射获取CfCombiner对象
//设置对应的Text.class
// job.setCombinerClass(CfCombiner.class);
job.setReducerClass(CfCombiner.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//获取目标路径文件
FileInputFormat.addInputPath(job,new Path("file:///d:/calres/cal01/a"));
//标记下载文件地址
FileOutputFormat.setOutputPath(job,new Path("file:///d:/calres/ca102/"));
/**
*Job运行是通过job.waitForCompletion(true),
* true表示将运行进度等信息及时输出给用户,
* false的话只是等待作业结束
*/
job.waitForCompletion(true);
}
}
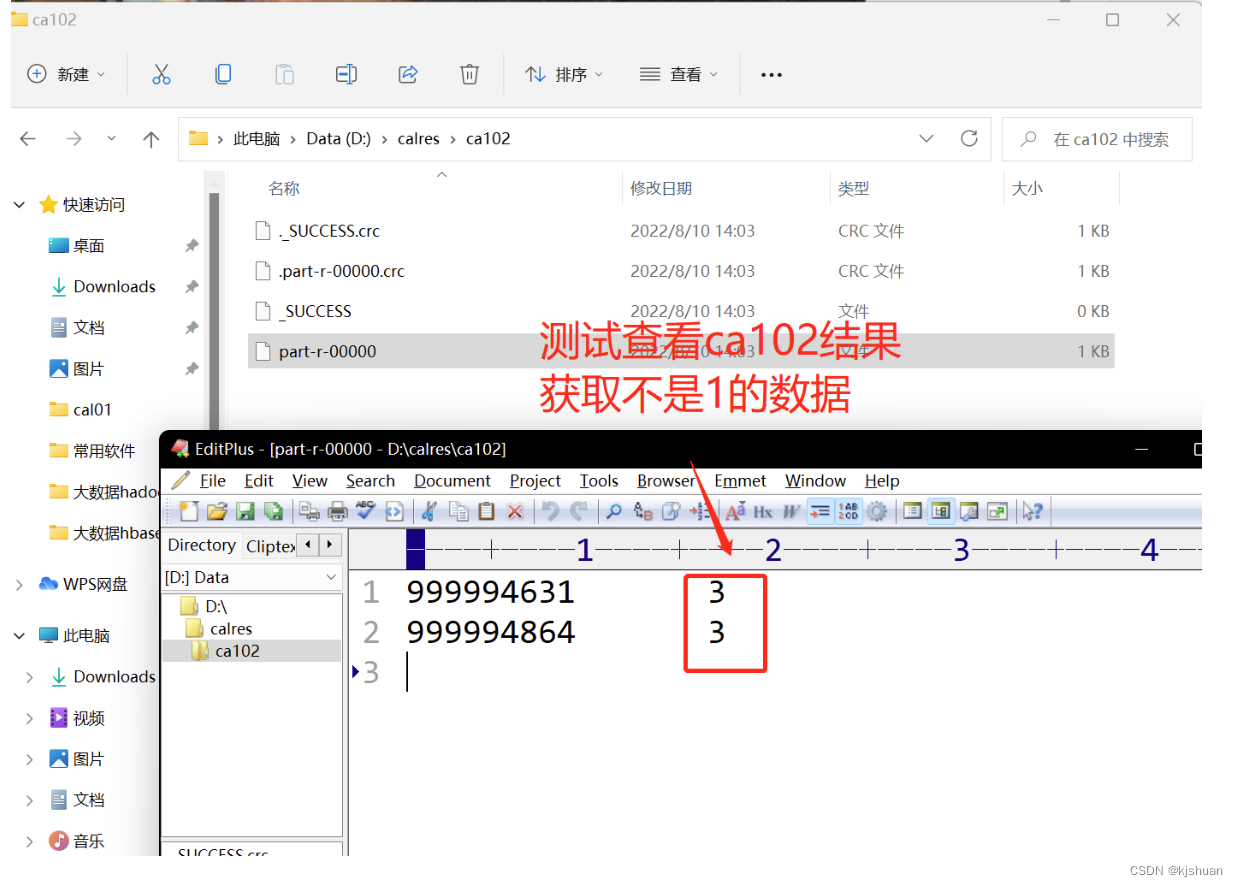
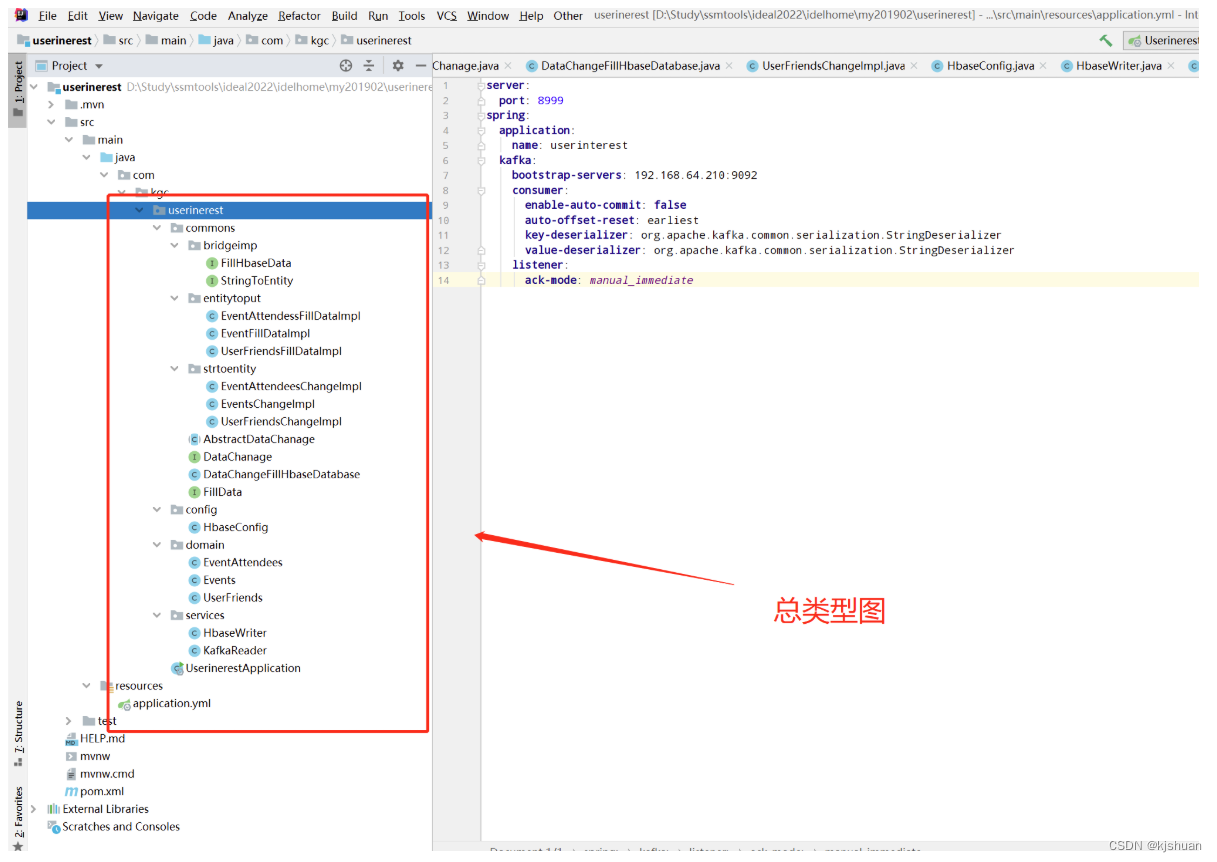
ideal配置kafka代码实现(优化:桥接模式)
1 导入 kafka pom文件
cannal 从数据库实时拉数据
2配置yml
手动提交 从开始读数据 序列化 监听
server: port: 8999 spring: application: name: userinterest kafka: bootstrap-servers: 192.168.64.210:9092 #acks=0:无论成功还是失败,只发送一次。无需确认 #acks=1:即只需要确认leader收到消息 #acks=all或-1:ISR + Leader都确定收到 consumer: #是否自动提交偏移量offset enable-auto-commit: false # earliest:无提交记录,从头开始消费 #latest:无提交记录,从最新的消息的下一条开始消费 auto-offset-reset: earliest #key的编解码方法 key-deserializer: org.apache.kafka.common.serialization.StringDeserializer #value的编解码方法 value-deserializer: org.apache.kafka.common.serialization.StringDeserializer # 配置监听器 listener: #当enable.auto.commit的值设置为false时,该值会生效;为true时不会生效 #manual_immediate:需要手动调用Acknowledgment.acknowledge()后立即提交 ack-mode: manual_immediate
3.配置桥接模式模板
3.1桥接模式接口类
public interface FillHbaseData<T> extends FillData<Put,T> {
List<Put> fillData(List<T> lis);
}
/**
* 根据用户的不同数据和传入的实体类模型进行数据格式转换接口
* @param <T>
*/
public interface StringToEntity<T> {
List<T> change(String line);
}
3.2桥接模式实现类
# EventAttendessFillDataImpl类 public class EventAttendessFillDataImpl implements FillHbaseData<EventAttendees> { @Override public List<Put> fillData(List<EventAttendees> lst) { List<Put> puts = new ArrayList<>(); lst.stream().forEach(ea->{ Put put = new Put((ea.getEventid() + ea.getUserid() + ea.getAnswer()).getBytes()); put.addColumn("base".getBytes(),"eventid".getBytes(),ea.getAnswer().getBytes()); put.addColumn("base".getBytes(),"userid".getBytes(),ea.getAnswer().getBytes()); put.addColumn("base".getBytes(),"answer".getBytes(),ea.getAnswer().getBytes()); puts.add(put); }); return puts; } } # EventFillDataImpl类 public class EventFillDataImpl implements FillHbaseData<Events> { @Override public List<Put> fillData(List<Events> lis) { List<Put> puts = new ArrayList<>(); lis.stream().forEach( event -> { Put put = new Put(event.getEventid().getBytes()); put.addColumn("base".getBytes(),"userid".getBytes(),event.getUserid().getBytes()); put.addColumn("base".getBytes(),"starttime".getBytes(),event.getStarttime().getBytes()); put.addColumn("base".getBytes(),"city".getBytes(),event.getCity().getBytes()); put.addColumn("base".getBytes(),"zip".getBytes(),event.getZip().getBytes()); put.addColumn("base".getBytes(),"state".getBytes(),event.getState().getBytes()); put.addColumn("base".getBytes(),"country".getBytes(),event.getCountry().getBytes()); put.addColumn("base".getBytes(),"lat".getBytes(),event.getLat().getBytes()); put.addColumn("base".getBytes(),"lng".getBytes(),event.getLng().getBytes()); puts.add(put); }); return puts; } } # UserFriendsFillDataImpl类 /** * 针对userfriends消息队列转换的List集合再转为List<Put> */ public class UserFriendsFillDataImpl implements FillHbaseData<UserFriends> { @Override public List<Put> fillData(List<UserFriends> lis) { List<Put> puts=new ArrayList<>(); lis.stream().forEach(userFriends -> { Put put = new Put((userFriends.getUserid()+"-"+userFriends.getFriendid()).getBytes());//行键 put.addColumn("base".getBytes(),"userid".getBytes(),userFriends.getUserid().getBytes()); put.addColumn("base".getBytes(),"friendid".getBytes(),userFriends.getFriendid().getBytes()); }); return null; } } # EventAttendeesChangeImpl类 public class EventAttendeesChangeImpl implements StringToEntity<EventAttendees> { /** * 数据进入为 eventid yes maybe invited no * ex:123,112233,34343,234234,45454,112233,23232,234234,3434343,34343 * 将数据格式转为 123 112233 yes ,123 34343 yes ,123 234234 maybe...... * @param line * @return */ @Override public List<EventAttendees> change(String line) { String[] infos = line.split(",", -1); List<EventAttendees> eas = new ArrayList<>(); //先计算所有回答yes的人 if (infos[1].trim().equals("")&&infos[1]!=null){ Arrays.asList(infos[1].split(" ")).stream().forEach( yes->{ EventAttendees ea = EventAttendees.builder() .eventid(infos[0]).userid(yes).answer("yes") .build(); eas.add(ea); }); } //先计算所有回答maybe的人 if (infos[2].trim().equals("")&&infos[2]!=null){ Arrays.asList(infos[2].split(" ")).stream().forEach( maybe->{ EventAttendees ea = EventAttendees.builder() .eventid(infos[0]).userid(maybe).answer("maybe") .build(); eas.add(ea); }); } //先计算所有回答invited的人 if (infos[3].trim().equals("")&&infos[3]!=null){ Arrays.asList(infos[3].split(" ")).stream().forEach( invited->{ EventAttendees ea = EventAttendees.builder() .eventid(infos[0]).userid(invited).answer("invited") .build(); eas.add(ea); }); } //先计算所有回答no的人 if (infos[4].trim().equals("")&&infos[4]!=null){ Arrays.asList(infos[4].split(" ")).stream().forEach( no->{ EventAttendees ea = EventAttendees.builder() .eventid(infos[0]).userid(no).answer("no") .build(); eas.add(ea); }); } return eas; } } # EventsChangeImpl类 public class EventsChangeImpl implements StringToEntity<Events> { @Override public List<Events> change(String line) { String[] infos = line.split(",", -1); List<Events> events=new ArrayList<>(); Events event = Events.builder().eventid(infos[0]).userid(infos[1]).starttime(infos[2]) .city(infos[3]).state(infos[4]).zip(infos[5]).country(infos[6]) .lat(infos[7]).lng(infos[8]).build(); events.add(event); return events; } } # UserFriendsChangeImpl类 /** * 将将123123, 123435 435455 345345 => 123123, 123435 123123,435455 123123, 345345 */ public class UserFriendsChangeImpl implements StringToEntity<UserFriends> { @Override public List<UserFriends> change(String line) { String[] infos = line.split(","); List<UserFriends> ufs = new ArrayList<>(); Arrays.asList((infos[1]).split(" ")).stream().forEach( fid->{ UserFriends uf = UserFriends.builder().userid(infos[0]).friendid(fid).build(); ufs.add(uf); } ); return ufs; } }
3.3桥接模式抽象类
/** *#3.3.1 AbstractDataChanage抽象类 * 桥梁模式中的抽象角色 */ public abstract class AbstractDataChanage<E,T> implements DataChanage<T> { protected FillData<E,T> fillData; protected StringToEntity<T> stringToEntity; public AbstractDataChanage(FillData<E, T> fillData, StringToEntity<T> stringToEntity) { this.fillData = fillData; this.stringToEntity = stringToEntity; } @Override public abstract List<T> change(String line); public abstract void fill(ConsumerRecord<String,String> record); } /** *#3.3.2 DataChanage接口 * 数据转换接口 kafka数据转为常用数据格式 * (如果有redis hbase oracle多个数据库 需要编写填充接口) * @param <T> */ public interface DataChanage<T> { List<T> change(String line); } #3.3.3 DataChangeFillHbaseDatabase类 public class DataChangeFillHbaseDatabase<T> extends AbstractDataChanage<Put,T> { public DataChangeFillHbaseDatabase( FillData<Put,T> fillData, StringToEntity<T> stringToEntity) { super(fillData,stringToEntity); } @Override public List<T> change(String line){ return stringToEntity.change(line); } @Override public void fill(ConsumerRecord<String,String> record){ //读取kafka获得的ConsumerRecord转字符串 List<Put> puts = fillData.fillData(change(record.value())); //将集合填充到对应的hbase数据库中 } } #3.3.4接口 FillData public interface FillData<T,E> { List<T> fillData(List<E> lst); }
3.4桥梁模式

抽象工厂 a工厂 abc3种产品 b工厂 abc3种产品
4.编写实体类
@Data
@AllArgsConstructor
@NoArgsConstructor
@Builder
public class EventAttendees {
private String eventid;
private String userid;
private String answer;
}
@Data
@AllArgsConstructor
@NoArgsConstructor
@Builder
public class Events {
private String eventid;
private String userid;
private String starttime;
private String city;
private String state;
private String zip;
private String country;
private String lat;
private String lng;
}
@Data
@AllArgsConstructor
@NoArgsConstructor
@Builder
public class UserFriends {
private String userid;
private String friendid;
}
5.编写配置类
@Configuration
public class HbaseConfig {
@Bean
public org.apache.hadoop.conf.Configuration hbaseConfiguration(){
org.apache.hadoop.conf.Configuration cfg= HBaseConfiguration.create();
cfg.set(HConstants.ZOOKEEPER_QUORUM,"192.168.64.210:2181");
return cfg;
}
@Bean
@Scope("prototype")
public Connection getConnection() {
Connection connection=null;
try {
connection = ConnectionFactory.createConnection(hbaseConfiguration());
} catch (IOException e) {
e.printStackTrace();
}
return connection;
}
@Bean
public Supplier<Connection> hbaseConSupplier(){
return ()->{
return getConnection();
};
}
}
5.1解决数据重复hbase
hbase 底层 kv k为行键 行键为 用户名+朋友 5.2 数据量太大?超过30w 几十个g 3000w数据大约几个g 分库分表 纵向分区10g hbase的功能 预分区功能 oracle分区 hash分区 范围分区 列表分区
5.2编写服务类
#5.2.1 /** * 接受转换后的List<Put>数据集合 填写到Hbase数据库 */ @Component public class HbaseWriter { @Resource private Connection hbaseConnection; public void write(List<Put> puts,String tableName){ try { Table table = hbaseConnection.getTable(TableName.valueOf(tableName)); table.put(puts); } catch (IOException e) { e.printStackTrace(); } } } #5.2.2 @Component public class KafkaReader { @KafkaListener(groupId = "cm",topics = {"events_raw"}) public void readEventToHbase(ConsumerRecord<String ,String > record, Acknowledgment ack){ AbstractDataChanage<Put,Events> eventsHandler = new DataChangeFillHbaseDatabase<Events>( new EventFillDataImpl(), new EventsChangeImpl() ); eventsHandler.fill(record); ack.acknowledge(); } @KafkaListener(groupId = "cm",topics = {"event_attendees_raw"}) public void readEventToHbase1(ConsumerRecord<String ,String > record, Acknowledgment ack){ AbstractDataChanage<Put,EventAttendees> eventsHandler = new DataChangeFillHbaseDatabase<EventAttendees>( new EventAttendessFillDataImpl(), new EventAttendeesChangeImpl() ); eventsHandler.fill(record); ack.acknowledge(); } @KafkaListener(groupId = "cm",topics = {"user_friends_raw"}) public void readEventToHbase2(ConsumerRecord<String ,String > record, Acknowledgment ack){ AbstractDataChanage<Put, UserFriends> eventsHandler = new DataChangeFillHbaseDatabase<UserFriends>( new UserFriendsFillDataImpl(), new UserFriendsChangeImpl() ); eventsHandler.fill(record); ack.acknowledge(); } }
6 hbase数据库创建列簇
#根据所需的区域数量和分割算法自动计算分割
create 'userfriends','base',{ NUMREGIONS => 3, SPLITALGO =>'HexStringSplit' }
======================================================================
NUMREGIONS说明:
hbase 默认 HFile 的大小为 10G(hbase.hregion.max.filesize=10737418240=10G)
源数据为 Hive:推荐分区数 ≈ HDFS大小 / 10G * 10 *1.2
HexStringSplit、UniformSplit、DecimalStringSplit说明:
UniformSplit(占用空间小,rowkey前缀完全随机•••••••):将可能的键的空间平均分割的聚合体。当键是近似一致的随机字节时(例如散列),建议使用这个。行是范围为 00 => FF 的原始字节值,用0右填充以保持相同的 memcmp()顺序。对于byte[]环境来说,这是一种自然的算法,可以节省空间,但是对于可读性来说,它并不一定是最简单的。
HexStringSplit(占用空间大,rowkey是十六进制的字符串作为前缀的•••••••):HexStringSplit 是一个典型的 RegionSplitter.SplitAlgorithm来选择 region 边界。HexStringSplit region 边界的格式是MD5校验和或任何其他均匀分布的十六进制值的ASCII表示形式。Row是十六进制编码的长值,其范围为“00000000”=>“FFFFFFFF”,并左填充0,以使其在字典上保持与二进制相同的顺序。由于这种分割算法使用十六进制字符串作为键,所以在 shell 中方便读写,但是占用更多的空间,而且可能不够直观。
DecimalStringSplit:rowkey是10进制数字字符串作为前缀的
======================================================================
create 'eventAttendees','base'
cat events.csv.COMPLETED |head -2
cd /opt/data/attendees
cat event_attendees_raw |head -2
create 'events' 'base'
6.1 hbase启动命令
#hbase启动 start-hbase.sh 或者开启脚本!!!!脚本如下 #浏览器地址 http://192.168.64.210:60010/master-status