十分激动啊啊啊题目终于出来了!!官网6点就进去了结果直接卡死现在才拿到题目,我是打算A-E题全部做一遍。简单介绍一下我自己:博主专注建模四年,参与过大大小小数十来次数学建模,理解各类模型原理以及每种模型的建模流程和各类题目分析方法。参与过十余次数学建模大赛,三次美赛获得过二次M奖一次H奖,国赛二等奖。希望各位以后遇到建模比赛可以艾特一下我,我可以提供免费的思路和部分源码,以后的数模比赛只要我还有时间肯定会第一时间写出免费开源思路。博主紧跟各类数模比赛,每场数模竞赛博主都会将最新的思路和代码写进此专栏以及详细思路和完全代码且完全免费。希望有需求的小伙伴不要错过笔者精心打造的文章。
只希望!!!大家给我三连就满足了!!那么废话不多说现在开始做题
(更新源码版本)
赛题分析
E题很明显是一道数据分析挖掘题,涉及到时序预测模型和时序数据的处理。先分析每个题目。
题目一
问题 1 研究该水文站黄河水的含沙量与时间、水位、水流量的关系,并估算近 6 年该水 文站的年总水流量和年总排沙量。
思路
首先明白我们需要研究的对象是黄河水的含沙量,因变量为时间、水位、水流量。此题我们根据附件1的2016-2021年黄河水沙检测数据基本就可以处理。
解答
数据和时间维度直接拿原数据看起来比较难看明白,稍作处理:、
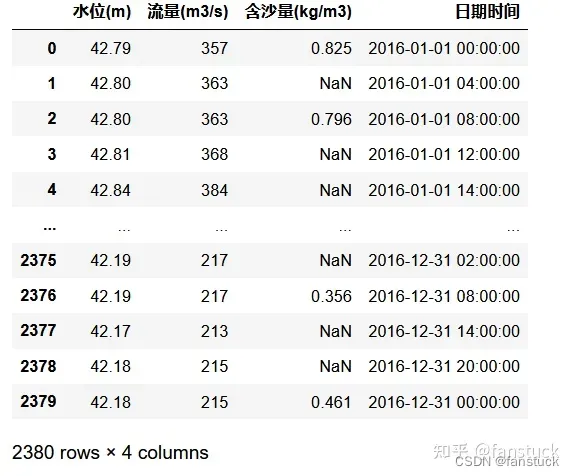
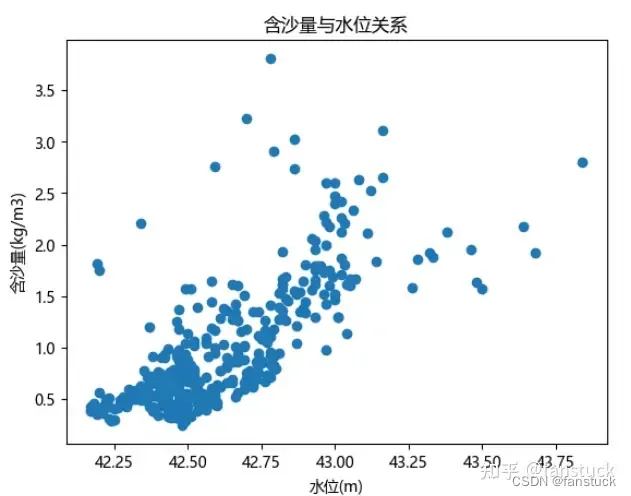
首先看水位和流量对含沙量的关系:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from pylab import mpl
from IPython.core.interactiveshell import InteractiveShell
InteractiveShell.ast_node_interactivity = "all"
plt.rcParams['font.sans-serif']=['Microsoft YaHei'] # 使用微软雅黑的字体
# 假设 df 是你的数据框
# 如果 df 是之前提供的数据,请将该数据转为数据框
# 绘制含沙量与水位的散点图
plt.scatter(df.iloc[:,0], df.iloc[:,2])
plt.xlabel('水位(m)')
plt.ylabel('含沙量(kg/m3)')
plt.title('含沙量与水位关系')
plt.show()
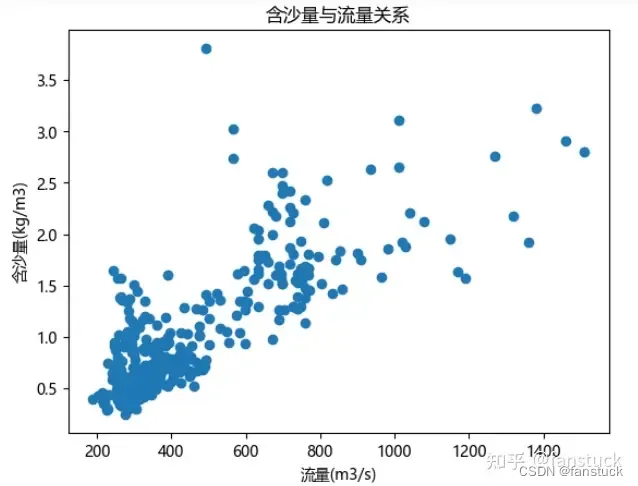
# 绘制含沙量与流量的散点图
plt.scatter(df.iloc[:,1], df.iloc[:,2])
plt.xlabel('流量(m3/s)')
plt.ylabel('含沙量(kg/m3)')
plt.title('含沙量与流量关系')
plt.show()
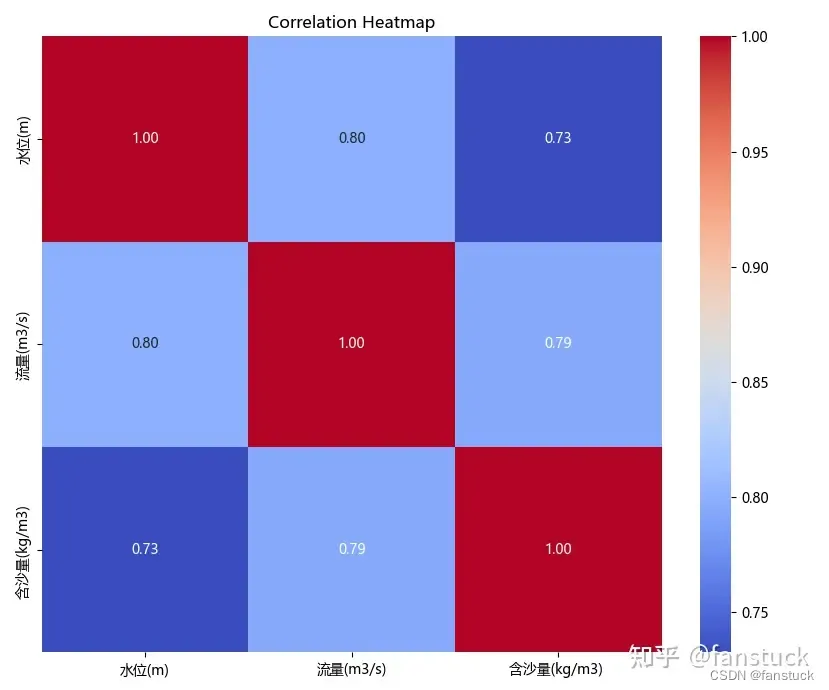
相关性矩阵:
# 计算所有列的相关系数
correlation_matrix = df.corr()
# 打印相关系数矩阵
print(correlation_matrix) 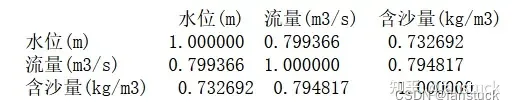
import pandas as pd
import matplotlib.pyplot as plt
# 假设 df 是你的数据框,日期时间为索引
# 如果不是,请将日期时间列设置为索引:df.set_index('日期时间', inplace=True)
df.set_index('日期时间', inplace=True)
# 将索引转为日期类型,并提取年月日
df.index = pd.to_datetime(df.index).date
# 提取含沙量存在的行
df_with_sediment = df.dropna(subset=['含沙量(kg/m3) '])
# 使用移动平均法平滑数据
rolling_mean = df_with_sediment.iloc[:,2].rolling(window=30).mean()
# 绘制原始数据和移动平均线
plt.figure(figsize=(10, 6))
plt.plot(df_with_sediment.index, df_with_sediment.iloc[:,2], label='原始数据')
plt.plot(df_with_sediment.index, rolling_mean, label='30天移动平均线', color='red')
plt.xlabel('日期时间')
plt.ylabel('含沙量(kg/m3)')
plt.title('含沙量长期趋势')
plt.legend()
plt.show()都是正相关且相关性挺高的,说明二者皆为正影响含沙量。那么再使用时间序列分析方法来识别含沙量的长期趋势:

先记录到这里后面整理一下!只希望大家给我三连就满足了,下一步开始计算6年含沙量预估。
# 将日期时间列设置为索引
df = df.set_index('日期时间')
# 1. 按年份分组
df['年份'] = df.index.year
# 2. 计算年总水流量和排沙量
annual_flow = df.groupby('年份')['流量(m3/s)'].sum()
annual_sediment = df.groupby('年份')['含沙量(kg/m3) '].sum()
# 3. 汇总结果
total_flow = annual_flow.sum()
total_sediment = annual_sediment.sum()
print(f'近 6 年总水流量为: {total_flow} m3/s')
print(f'近 6 年总排沙量为: {total_sediment} kg/m3')
(更新了源码版本)
下一次更新第二问简历时序预测模型,如果对此模型掌握不是很熟悉的同喜,推荐阅读本人专栏:
时序预测模型已经写了有八篇了,对于每个时序预测模型都有各自特点最优的使用场景,但是一般来说大部分时间序列数据都呈现出季节变化(Season)和循环波动(Cyclic)。对于在这些数据基础之上进行的建模一般最优是采用季节性时序预测。大家可以试读一下我的这篇文章
https://blog.csdn.net/master_hunter/category_10967944
那我们下次更新不见不散