1、问题出现
在APP客户端输入搜索文章的关键字时,不小心输入来了一个 emoji 表情符号,提示出错了,在后台查询错误日志信息,提示查询出现了2条相同的记录:
Caused by: org.hibernate.NonUniqueResultException: query did not return a unique result: 22、业务逻辑
数据库有个 tb_search_statistic 表格用来记录用户的搜索记录。每次客户端发起搜索,后台业务先查询下之前是否已经存在该「关键字」的搜索记录,如果没有就插入一条新数据,如果已经存在就对其搜索次数增加 1; 在执行查询操作时,因为返回了两条记录所以报错了。
3、在Nacat for MySQL 进行问题重现

果然,出现了两条记录,是不是很奇怪,明明两个表情符号是完全不同的。其实这条查询语句里面有个字符 “=” ,这个等号和 MySQL 的字符集和字符序有关系。
MySQL 里存储的数据,只要是字符类型的字段,都会对应一个字符集(字符集合+编码)和字符序(字符的排序和比较),每个字符集对应一个或多个字符序,且对应一个默认的字符序,在数据表里新建字段时,这个字符集和字符序就确定下来了,如果不专门指定,就继承自表格的字符集和字符序(继承关系:服务器 <- 数据库 <- 表 <- 字段)。
在 Navicat 客户端看下表格的字符集和字符序:

可以发现,表格的字符集是 utf8mb4, 字符序是默认的 utf8mb4_general_ci。因为 keyword 字段没有专门指定,就继承了与表格相同的字符集和字符序。
问题的关键就出在这里:utf8mb4_general_ci 无法精确区分不同的 emoji 表情符号,所以导致查询结果出现多条记录。刚才提到一个字符序可以对应多个字符序。下面是 utf8mb4 对应的的两个字符序的比较:
- utf8mb4_bin:将字符串每个字符用二进制数据编译存储,区分大小写,而且可以存二进制的内容。
- utf8mb4_general_ci:ci 即 case insensitive,不区分大小写。没有实现 Unicode 排序规则,在遇到某些特殊语言或者字符集,排序结果可能不一致。但是,在绝大多数情况下,这些特殊字符的顺序并不需要那么精确。
4、解决方案
方案一:将字段的字符序修改为 utf8mb4_bin.
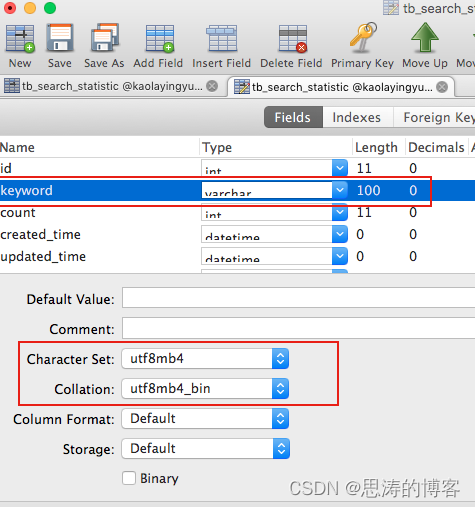
修改后,再次执行查询语句,结果就正好是我们期望的这条数据了:

方案二:在where查询字段添加 binary 关键字,BINARY 不是函数,是类型转换运算符,它用来强制它后面的字符串为一个二进制字符串。

以上出现了一些关于字符集和字符序的术语,其实 MySQL 的一些莫名其妙的错误包括“乱码”都和它们密切相关。 所以有必要对它们有清晰的了解,如果感兴趣,可以参考笔者另外一篇文章: