如何降低模型成本?
近年来,模型参数爆炸到数量巨大(PaLM 为 540 B)。有人提出的问题是这个参数数量是否必要。
根据 OpenAI 的说法,随着模型的增长,性能也会提高。此外,还出现了突现属性(除非在一定规模内才能观察到的属性)。
这种观点受到了以下事实的挑战:实际上更多的数据,因此扩展受到最佳训练模型所需的令牌数量的限制。此外,甚至这些新兴属性也可能不存在。
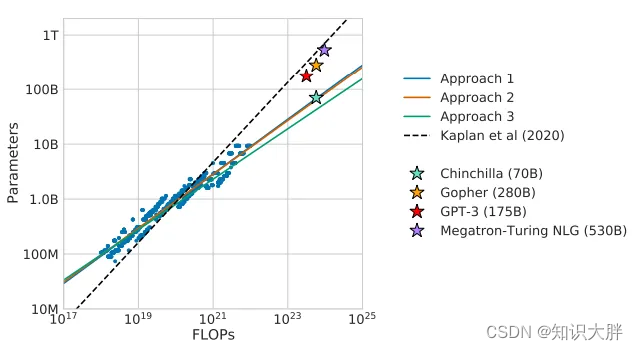
其次,这些专有模型不能被科学界自由分析或使用。因此,首先是BLOOM,然后是META 的 LLaMA,社区已转向使用开源模型。LLaMA还表明,对数据的更多关注使得较小的模型能够与较大的模型竞争。
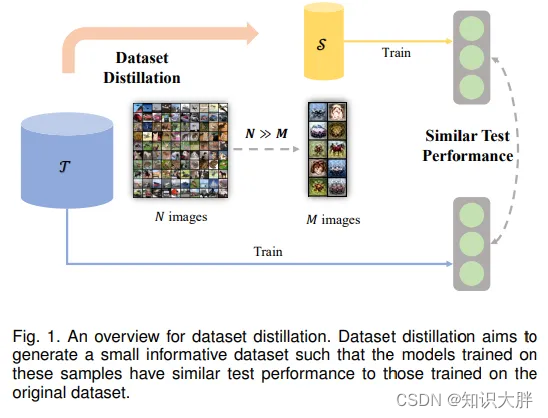
然而,另一方面,小模型不能像大模型一样具有泛化能力。然而,这导致人们寻找降低这些模型成本的技术,例如知识蒸馏(教师模型教授学生模型)。后来的方法试图通过提取数据集(从大型训练数据集开始,到较小但同时有效的数据集)来进一步降低成本。
降低计算成本的另一个想法是混合专家,其中网络的各个部分根据输入被激活。例如,在开关变压器中,为每个示例(以及不同的令牌)选择不同的参数集。