系列文章
《算法导论》学习(一)---- 插入排序和归并排序
《算法导论》学习(七)----堆排序和优先队列(C语言)
《算法导论》学习(八)----快速排序(C语言)
《算法导论》学习(九)----为什么比较排序算法时间复杂度的下界是确定的?
《算法学习》学习(十)----计数排序,基数排序,桶排序(C语言)
文章目录
前言
本文主要讲解顺序统计量,直接解决了从一组输入中找到第i小的元素的问题,给出了相应的C语言代码,同时该算法时间性能很突出,最坏情况是线性时间代价
一、顺序统计量
1.什么是顺序统计量?
(1)定义
在一个由 n 个元素组成的集合中,第 i 个顺序统计量是该集合中第 i 小的元素。 在一个由n个元素组成的集合中,第i个顺序统计量是该集合中第i小的元素。 在一个由n个元素组成的集合中,第i个顺序统计量是该集合中第i小的元素。
(2)例子
对于一个元素集合,我们可以用顺序统计量来定义最大值和最小值
1.最小值是第一个顺序统计量
2.最大值是第n个顺序统计量
2.如何得到顺序统计量?
得到第i个顺序统计量的算法本质上就是求第i小的元素
我们可以有两个方法:
1.将元素直接排好序,直接提取
2.直接求解第i小的元素
我们都知道,排序算法可以达到平均时间代价O(n);同时还有能达到 Θ ( n l g n ) \Theta(nlgn) Θ(nlgn)的排序算法。
而单纯的得到最大值和最小值的时间代价的上界也一定是 O ( n ) O(n) O(n)
这样看来,排序算法似乎已经在性能上很优了,那我们能否得到更优的解呢?
3.能不能有更快的程序可以得到顺序统计量?
我们可以尝试方案2:直接求解第i小的元素。
这个算法也被称作选择算法。它的核心与快速排序的核心相同,都会用到将数组分割成小于标准值和大于标准值的两部分的操作。这个操作本质上是维护一种局部有序,这个局部有序恰好也是顺序统计量所要求的:
顺序统计量可以看作一种局部有序,即只要求在i位置上的值大于i以前的所有值,以前的值是否有序不要求
二、最坏情况为线性时间的选择算法
1.C语言代码
#include<stdio.h>
#include<stdlib.h>
#include<time.h>
#define SIZE 10000
#define LIM 1000
void insertion_sort(int *x,int num)
{
int i=0;//循环变量初始化
int j=0;//循环变量初始化
int tempval;//中间暂存变量初始化,因涉及两数交换所需
/*
第一个循环是要遍历一遍数组
依次为每一个变量找到它合适的位置
这个合适的位置是一个局部的范围
范围是在这个变量之前的空间,包括这个变量
随着循环的进行,到最后
这个局部的范围就是所有变量
那么就完成排序
*/
for(i=1;i<num;i++)
{
j=i-1;//为位置指正赋值,目的是设置局部范围的界限
/*
第二个循环是找准第一个循环所确定变量的合适位置
循环的方向是从确定变量位置往前
循环条件包含了判断规则
满足循环就需要进行交换数据
不满足循环时,就是局部排序完成时
*/
while((x[j+1]<x[j])&&(j>=0))
{
tempval=x[j+1];//数据交换
x[j+1]=x[j];
x[j]=tempval;
j=j-1;//循环变量赋值,推动循环进行
}
}
}
//快速排序的分割函数
//该函数的目的是:
//1.随机选定一个中间标准值,该值是随机产生的
//2.然后将数组给定区间的所有元素进行“分类”
//3.将小于标准值的元素放到标准值的左边
//4.将大于标准值的元素放到标准值的右边
//5.最后是返回标准值所在的位置信息
int PARTITION_RAND(int *x,int left,int right,int std_val)
{
//定义两个循环变量
//1.i是永远指向小于标准值那组数据的最右端
//2.j永远指向未分类的元素
int i;
int j;
/*
//模拟随机抽样
int middle;
int delt,n=0;
delt=(right-left+1);
//若只有一个元素,那就直接返回它本身
if(delt==1)
{
return left;
}
middle=rand()%delt;
n=middle+left;
n=delt/2+right;
int std_val=x[n];//得到标准值
*/
int temp;//中间暂存变量
int num;
//初始化索引变量
i=left-1;
j=left;
//让索引变量进入循环
for(j=left;j<=right;j++)
{
//如果元素小于等于标准值,那么就将该元素与i指向的下一个位置的元素交换,
//如果元素大于标准值,那么就保留
//这两个操作就可以将元素以i为界分割出来“两类”
if(x[j]<=std_val)
{
i++;
temp=x[i];
x[i]=x[j];
x[j]=temp;
//为了标记中间值的位置
if(x[i]==std_val)
{
num=i;
}
}
}
//中间值可能并不在中间
//我们现在标记了中间值的位置
//同时i指向最右边的“小值”
//那么交换两个位置的元素,就可以完成分类
temp=x[i];
x[i]=std_val;
x[num]=temp;
//最后i就是中间值的位置
return i;
}
//返回第i_min小的值
//该算法先对整个数据进行分组,5个数一组,剩余的一组
//之后得到每组的中位数
//再得到每组的中位数中的中位数
//将最终的中位数传入快排的分割程序,得到该中位数在原数组中的确切位置
//若该中位数的位置是要求的,那么直接返回该值
//若是要求的位置,然后以该中位数为界,递归地分割原数组,进入下一轮寻找
int SELECT(int *a,int left,int right,int i_min,int size)
{
//如果数组的数量只有1个,那么返回它本身即可
if(size==1)
{
return a[left];
}
int group;//组数
int surplus;//分组后剩余数
//中位数是第k小值,即中位数的位置到数组的边界之间数的个数
int k=0;
//循环索引变量
int i=0;
int j=0;
//得到分组,以及分组后剩余数据的个数
surplus=size%5;
group=size/5;
//分组缓存
int temp[5];
//中位数的值
int m_v=0;
//中位数在数组中的位置
int m_n=0;
//组数和剩余数都大于等于1的情况
if(surplus>=1&&group>=1)
{
//申请缓存
int temp1[surplus];
int middle[group+1];
/*
找到中位数
*/
for(i=0;i<group;i++)
{
for(j=0;j<5;j++)
{
temp[j]=a[left+(5*i)+j];
}
insertion_sort(temp,5);
middle[i]=temp[2];
}
for(i=0;i<surplus;i++)
{
temp1[i]=a[left+group*5+i];
}
insertion_sort(temp1,surplus);
middle[group]=temp[surplus/2];
//给中位数数组再排序
insertion_sort(middle,group+1);
//给中位数赋值
m_v=middle[(group+1)/2];
}
//没有剩余数,组数大于等于1
else if(surplus==0&&group>=1)
{
int middle[group];
/*
找到中位数
*/
for(i=0;i<group;i++)
{
for(j=0;j<5;j++)
{
temp[j]=a[left+(i*5)+j];
}
insertion_sort(temp,5);
middle[i]=temp[2];
}
//给中位数数组再排序
insertion_sort(middle,group);
//给中位数赋值
m_v=middle[group/2];
}
//数组总数小于5,组数等于0
else if(surplus>=0&&group==0)
{
int temp1[surplus];
for(i=0;i<surplus;i++)
{
temp1[i]=a[left+i];
}
insertion_sort(temp1,surplus);
//给中位数赋值
m_v=temp1[surplus/2];
}
//发生错误
else
{
return -1;
}
//让中位数作为标准值传入,得到它再原数组中的位置
m_n=PARTITION_RAND(a,left,right,m_v);
//计算包含中位数之前的元素个数
k=m_n-left+1;
//调用依次SELECT就会打印一次,可以看出算法规模
printf("success\n");
//如果中位数的位置满足要求,那么就直接返回该值
if(i_min==k)
{
return a[m_n];
}
//如果小于,分割后调用
else if(i_min<k)
{
return SELECT(a,left,m_n-1,i_min,k-1);
}
//如果大于,分割后调用
//这里的i_min变成i_min-k,这样保持了递归的统一性
else if(i_min>k)
{
return SELECT(a,m_n+1,right,i_min-k,size-k);
}
//发生错误
else
{
return -1;
}
}
int main()
{
int a[SIZE];
int b=0;
int c=0;
srand((unsigned)time(NULL));
int i=0;
//得到随机数组
for(i=0;i<SIZE;i++)
{
a[i]=rand()%LIM;
}
b=rand()%SIZE;
//将随机数组打印出来
for(i=0;i<SIZE;i++)
{
printf("%5d",a[i]);
}
printf("\n");
//对数组进行桶排序
c=SELECT(a,0,SIZE-1,b,SIZE);
//对数组进行排序
//实际上不需要,这里用作验证
insertion_sort(a,SIZE);
//将排序后的新数组打印出来
printf("min_%dth data is %5d\n",b+1,c);
printf("correct data is %5d\n",a[b-1]);
return 0;
}
2.算法逻辑
(1)基本思想
1.首先我们的核心算法是利用快速排序操作的一部分-----”分类“操作。
(1)将某一个数作为标准值,然后返回这个数的下标num。
(2)然后我们拿num与要求的第i个顺序统计量的i作比较:
1.如果i=num,那么直接返回标准值
2.如果i<num,那么将数组的边界设置为left~num-1,进入递归
3.如果i>num,那么将数组的边界设置为num+1~right,进入递归
(3)当然递归调用到数组只有一个数的时候,直接返回它本身
2.关于标准值的选取策略:
我们的标准值选取不是随意的,而是用如下操作:
==首先将数据分组,每组5个,剩余的不足5个的元素自成一组;之后将每组的中位数找到,然后再将所有中位数的中位数找到,将该数作为标准值 ==
过程的描述如图:
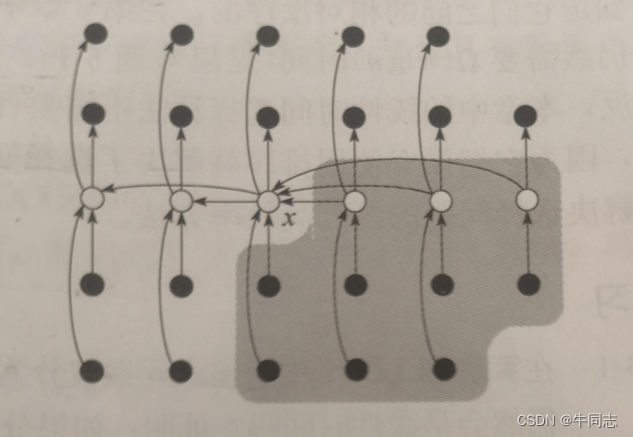
通过这个操作,我们可以发现:如果i>num时,那么我们只需要在阴影部分中寻找即可。
(2)算法特点
该算法的特点就是最坏的情况为线性时间代价;但是时间代价的常数项较大。
(3)算法时间性能分析
实际运行规模
算法的时间代价最坏情况也是线性的,这集中体现在递归调用次数少上面:
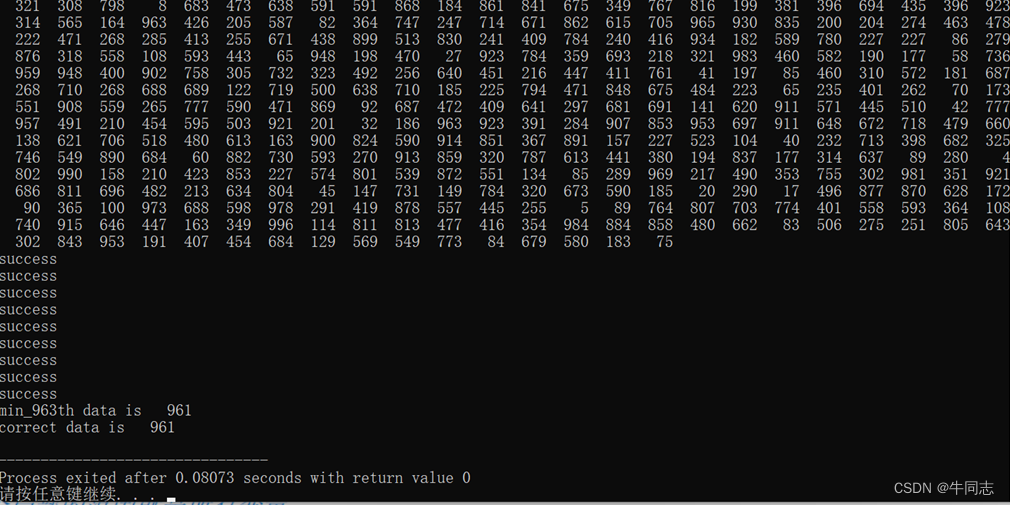
下面是算法的实际运行情况,每一个success代表递归调用一次
1.数量10000时:

2.数量1000时:
3.数量100时
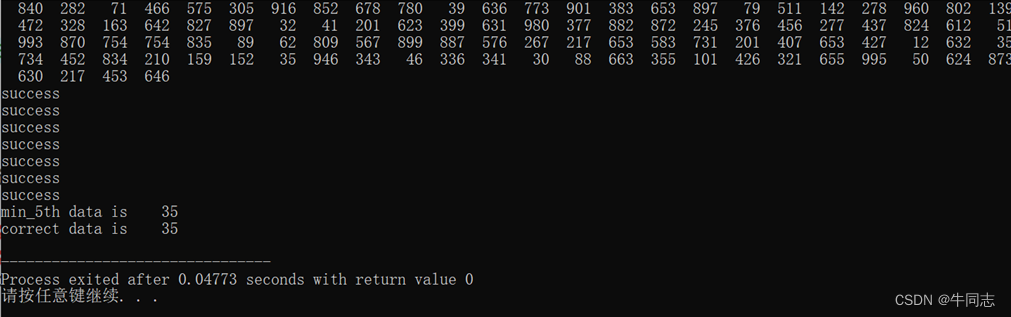
我们可以发现,随着输入规模10倍的扩大,递归调用次数并没有随之扩大10倍,说明一般情况下时间代价是小于线性时间的
总结
文章的不妥之处请各位读者包涵并且指正
本文参考了插入排序和快速排序的代码,下面给出文章链接:
《算法导论》学习(一)---- 插入排序和归并排序
《算法导论》学习(八)----快速排序(C语言)