AI: 开始学习AI--第一课 Machine Learning 。四,如何在Azure 建立分类模型(Classification多用疾病预测)。
机器学习的分类算法是什么?
- 分类技术预测的数据对象是离散值。根据一些数据来获得真假的比率,如癌症的良性,阴性。糖尿病等,本例子的数据是预测糖尿病,最后会输出一个预测图表。
继续使用之前创建的实验,这次通过一个关于糖尿病的分析,来介绍分类模型。
- 测试数据可以从这里下载:https://download.csdn.net/download/jason_dct/10410538
首先使用的是两个Excel 数据导入到数据集,如果不知道如何导入的话,可以参考之前的文章。
- 导入之后-Dataset diabetes.csv 和 doctores.csv 拖入到中间编辑面板里。
然后,使用Join data 控件把病人信息和相关医生连接成一个数据集。
- L 是左侧的数据集 diabetes,选择PatientID。
- R是右侧的数据集 doctores, 选择PatientID。
- 选择使用左外连接,把数据管理起来。然后运行。

- 运行成功之后,单击Join Data 空间,在下拉框里选择“visualize“ 来简单看一下数据分布情况。
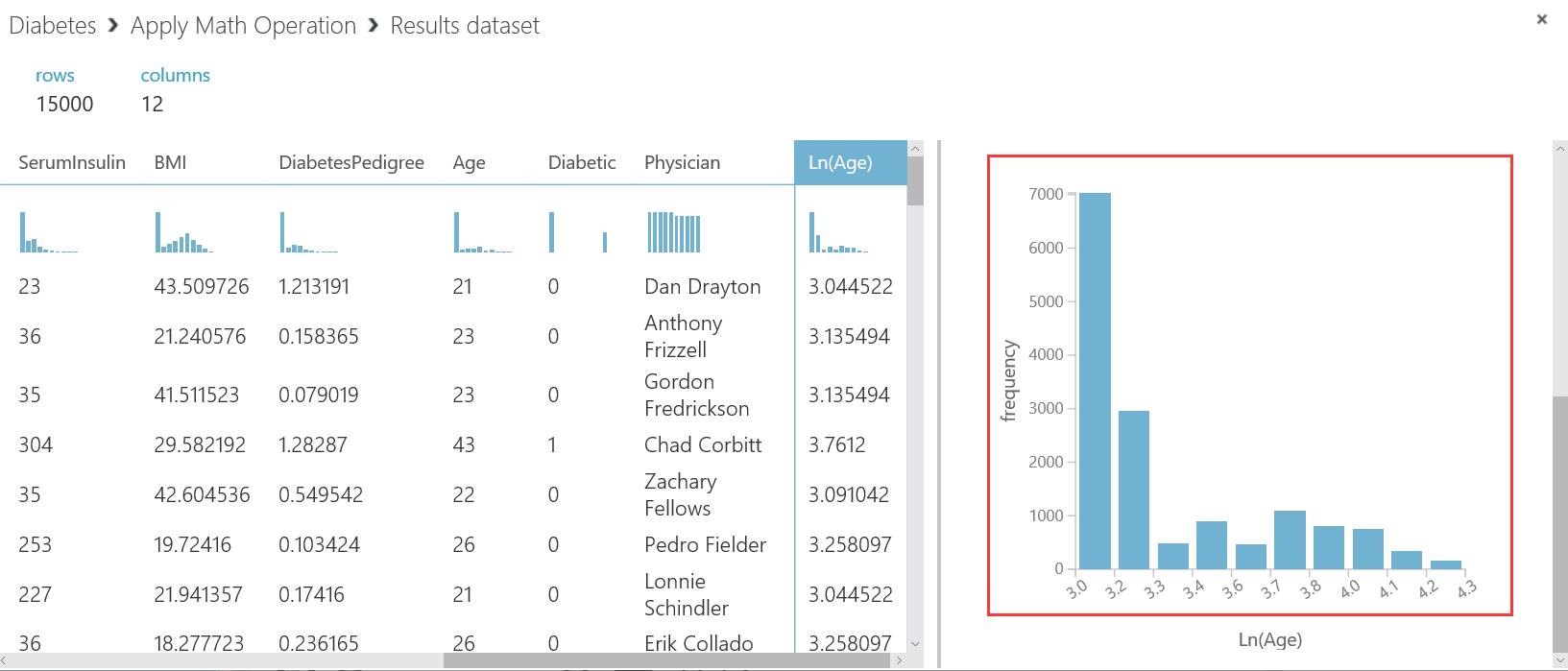
- 从age年龄,diabetes pedigree 家族病史 等。由这里数据来看,峰值和谷值差距太大。直方图,大多数聚集在年轻的数据里,这对预测产生了干扰,所以我们增加一个应用数学控件,里来处理。
- 增加一个Apply Math Operation,配置如下
- Category 选择“Basic”
- Basic Math Function 选择”Ln“
- Column set Column Names= Age
- Output mode 选择Append。
- OK 配置完成之后,在Apply Math Operation 单击 visualize 产看数据结果。有了很大提升,但是还需要改善。
- 增加两个Normalize Data
- 第一个是正常的数据,使用ZScore。
- 第二个Normalize Data 包含其他列,使用MinMax
- 这里注意;PatientID 和 physician,仅仅是病人编号和医生的姓名,不会影响到数据预测,也不会训练这些数据,所以不选。

下面继续使用回归的方式分割数据
- 这是一个监督模型,增加一个Split Data控件,按照30%和70%分割数据。30%的数据用训练,70%的数据直接用于。
- 这里增加一个Train Model 如果对Train model 不太熟悉的话,请参考这里:https://docs.microsoft.com/en-us/azure/machine-learning/studio-module-reference/train-model
- 在配置Train Model 之前,增加一个二级决策树(Two-Class Boosted Decision Tree)。
- Train Model,选择Column names:Diabetic
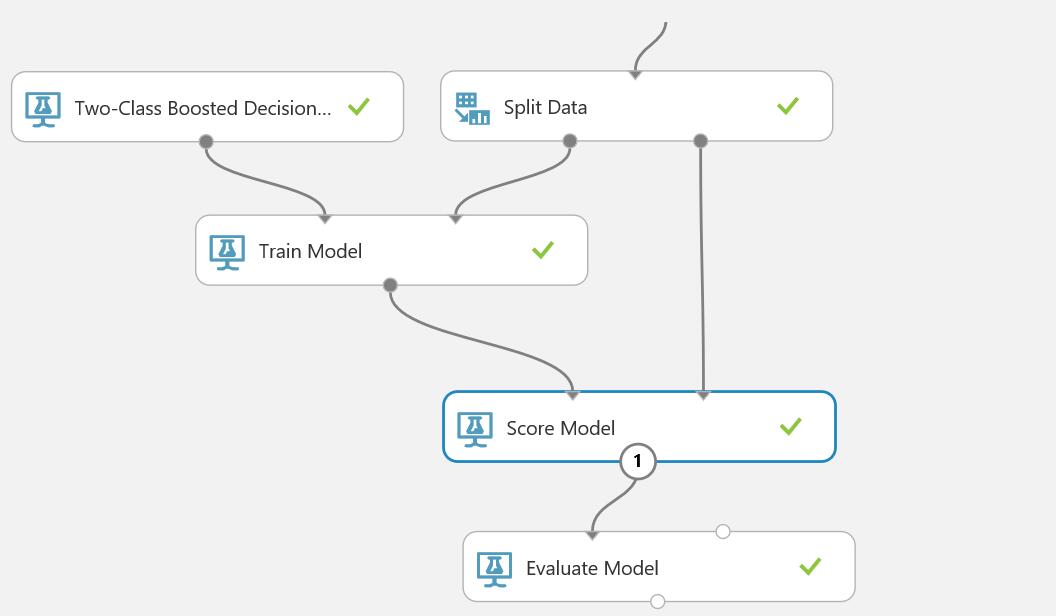
- 然后增加一个Score Model(评分模型)
- 最后增加一个Evaluate Model,增加完成如下。
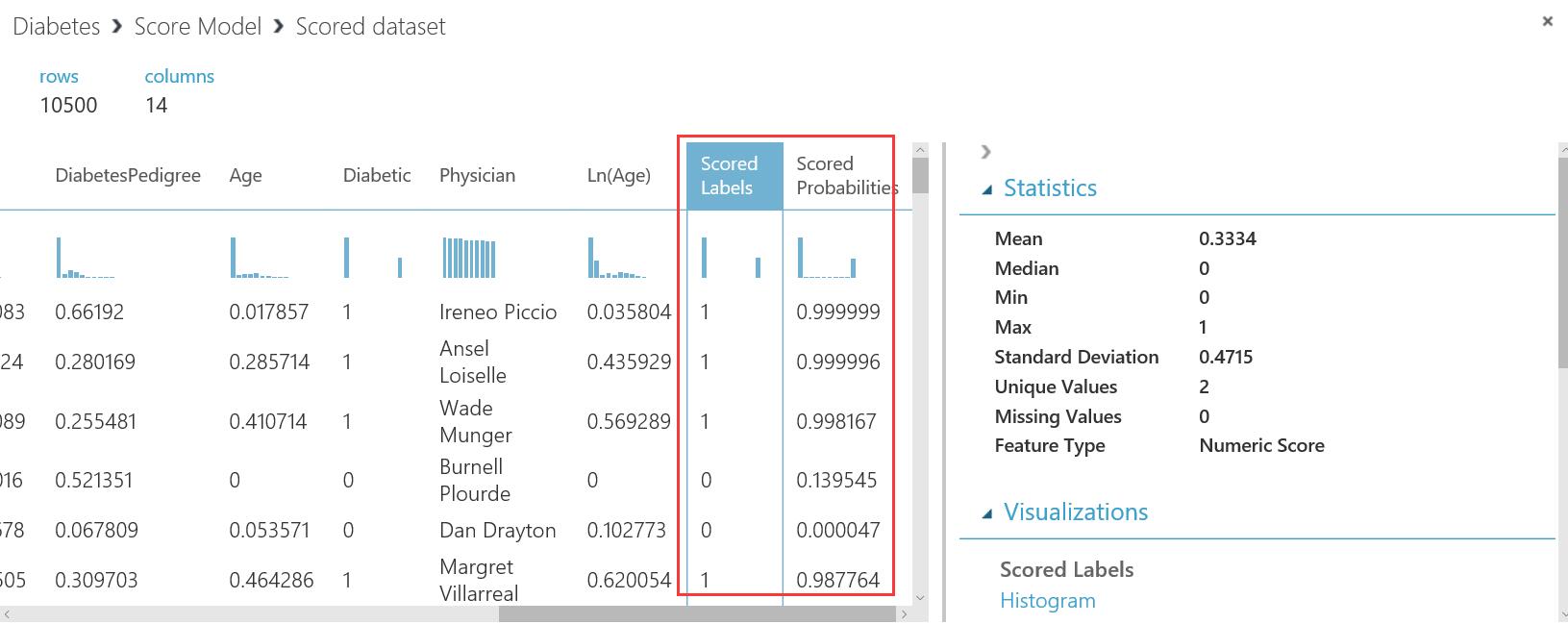
- 我们看一下Score Model 的输出,单击Score Model 中间的圆圈,在弹出的下拉框里选择”Visualize“
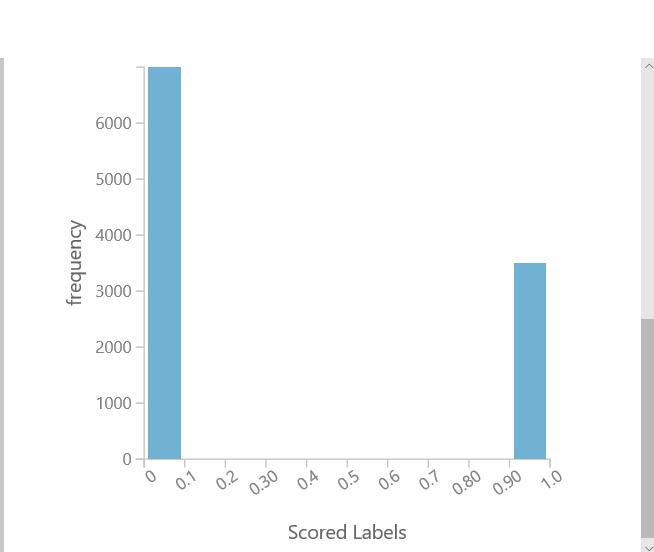
- 下图是糖尿病的阴性和阳性的预测输出结果。
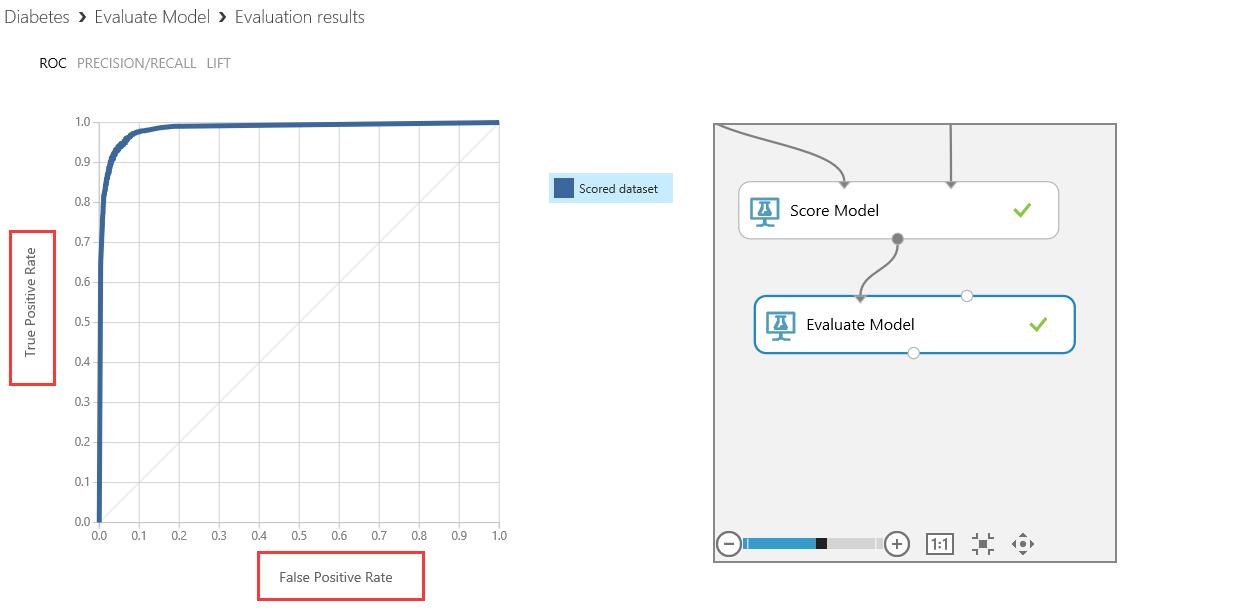
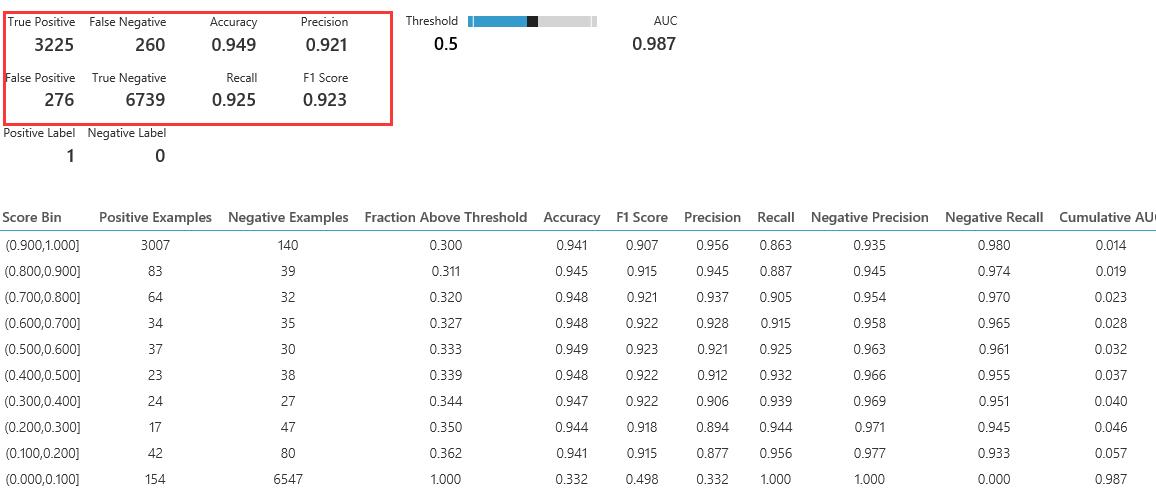
- 最后看一下Evaluate Model 最终输出结果:单击Evaluate Model ,在下拉框选择 Visulize。True Positive rate和False Positive rate 。
- 预测数据结果如下,从数据结果来看,预测结果正确率达到了90%以上,虽然不能到100%正确,但是已经无限接近了。