目录
1、 Attention Augmented Convolutional Networks(ICCV 2019)
2、 Stand-Alone Self-Attention in Vision Models(NIPS 2019)
3、CMT: Convolutional Neural Networks Meet Vision Transformers(CVPR 2022,CMT)
4、Conformer: Convolution-augmented Transformer for Speech Recognition(2020,Conformer)
1、 End-to-End Object Detection with Transformers(ECCV 2020,DERT)
2、 Generative Pretraining from Pixels(ICML 2020)
3、 AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE(ICLR 2021,VIT)
1、Transformer in Transformer(NIPS 2021)
3、 Tokens-to-Token ViT: Training Vision Transformers from Scratch on ImageNet(ICCV 2021,T2T-VIT)
4、 Swin Transformer: Hierarchical Vision Transformer using Shifted Windows(ICCV 2021 最佳论文奖)
5、A Time Series is Worth 64 Words: Long-term Forecasting with Transformers(ICLR 2023)
五、基于MLP的TiDE模型,未使用注意力机制、CNN和RNN
一、CV中的Transformer介绍
随着Transformer在NLP领域主流地位的确立,越来越多的工作开始尝试将Transformer应用到CV领域中。CV Transformer的发展主要经历了以下3个阶段;首先是在CNN中引入Attention机制解决CNN模型结构只能提取local信息缺乏考虑全局信息能力的问题;接下来,相关研究逐渐开始朝着使用完全的Transformer模型替代CNN,解决图像领域问题;目前Transformer解决CV问题已经初见成效,更多的工作开始研究对CV Transformer细节的优化,包括对于高分辨率图像如何提升运行效率、如何更好的将图像转换成序列以保持图像的结构信息、如何进行运行效率和效果的平衡等。通过汇总近几年Transformer相关论文、介绍Attention机制在计算机视觉领域的应用,从ViT到Swin Transformer,完整了解CV Transformer的发展过程。
二、Attention机制增强CNN
前言:
卷积神经网络(CNN)在大量计算机视觉应用中取得了极大成功,尤其是图像分类。卷积层的设计需要通过受限的感受野来确保局部性(locality),以及通过权重共享来确保平移等效性(translation equivariance)。研究表明,这两种属性是设计图像处理模型时关键的归纳偏置。但是,卷积核固有的局部性使它无法得到图像中的全局语境;而为了更好地识别图像中的对象,全局语境必不可少。
归纳偏置:其实就是一种先验知识,一种提前做好的假设。归纳偏置可以理解为,从现实生活中观察到的现象中归纳出一定的规则 (heuristics),然后对模型做一定的约束,从而可以起到 “模型选择” 的作用,类似贝叶斯学习中的 “先验”。例如,深度神经网络就偏好性地认为,层次化处理信息有更好效果;卷积神经网络认为信息具有空间局部性 (Locality),可用滑动卷积共享权重的方式降低参数空间;循环神经网络则将时序信息考虑进来,强调顺序重要性。
自注意力(self-attention)机制是获取长程交互性方面的一项近期进展,但主要还只是用在序列建模和生成式建模任务上。自注意机制背后的关键思路是求取隐藏单元计算出的值的加权平均。不同于池化或卷积算子,用在加权平均运算中的权重是通过隐藏单元之间的相似度函数动态地得到的。由此,输入信号之间的交互就取决于信号本身,而不是由它们的相对位置预先确定。尤其值得提及的是,这使得自注意机制能在不增多参数的前提下获取长距离交互性。
自注意力(self-attention)机制:简单理解注意力机制 - 知乎 (zhihu.com)
《Attention is All You Need》浅读(简介+代码) - 科学空间|Scientific Spaces (kexue.fm)
1、 Attention Augmented Convolutional Networks(ICCV 2019)
CNN的模型结构特点是对局部信息汇聚建模,其劣势在于难以对长周期进行建模。而Attention模型有较强的的长周期建模能力,因此Attention Augmented Convolutional Networks(ICCV 2019)提出使用Attention来弥补CNN在超长周期建模的不足。这篇论文研究了将自注意(用作卷积的替代)用于判别式视觉任务的问题。研究者开发了一种全新的二维相对自注意机制,能够在纳入相对位置信息的同时维持平移等效性,这使得其非常适用于图像。研究表明,这种自注意方案非常有竞争力,足以完全替代卷积。尽管如此,对照实验表明,将自注意与卷积两者结合起来得到的结果最佳。因此,完全摈弃卷积思想是不妥的,而应该使用这种自注意机制来增强卷积。其实现方式是将卷积特征图(强制局部性)连接到自注意特征图(能够建模更长程的依赖)。该方法将输入的图像[H, W, F]转换成二维度[H*W, F]作为Attention部分输入,Attention模型采用了multi-head attention的形式。下图展示了这种注意增强方法在图像分类任务上的改进效果。
为了弥补Transformer对于空间位置信息提取能力的缺失,本文借助了Self-Attention with Relative Position Representations(2018)的思路,在宽度和高度两个维度分别使用了相对位置编码增强Attention能力。最后,作者用Attention部分得到的信息和CNN部分得到的信息拼接到一起,共同进行后续任务,形成了二者的优势互补。
相对位置嵌入Relative positional embeddings:
这里简单介绍一下相对位置编码,它是一种替代Transformer中position embedding的方式,对于任意两个位置的元素i和,会将二者的相对位置embedding加入到计算attention的过程中。如果i和j距离为n,就用距离为n对应的一个可学习的embedding表示,同时设定某个阈值,如果i和j的距离超过k,就都用距离k对应的embedding表示。下面的公式左侧代表i和j的相对位置embedding aij怎么用在多头attention中,右侧表明了两个元素相对位置embedding的计算方法。通过引入relative position embedding,在attention模型中也可以实现平移不变性(因为平移后相对位置不变)
注意力增强卷积Attention Augmented Convolution:
多个先前提出的关于图像的注意力机制表明卷积算子受其局部性和对全局上下文缺乏理解的限制。这些方法通过重新校准卷积特征映射来捕获远程依赖性。特别是,Squeeze-and-Excitation(SE)和GatherExcite(GE)执行通道重新加权,而BAM和CBAM 独立地重新加权通道和空间位置。
与这些方法相反,我们 1)使用注意力机制共同关注空间和特征子空间(每个head对应一个特征子空间)和 2)引入额外的特征映射(feature maps)而不是细化精炼它们。下图总结了我们提出的增强卷积。
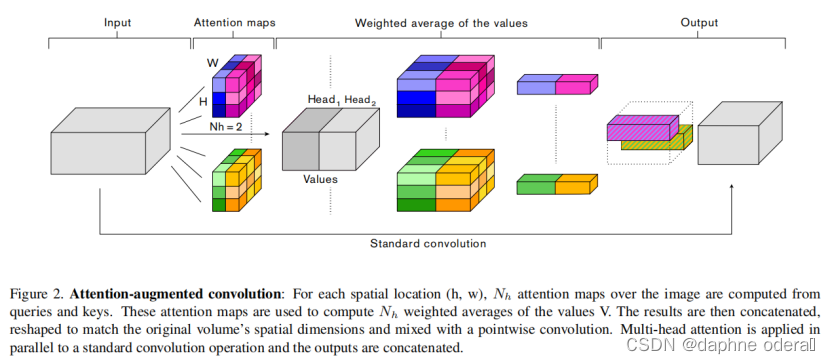
论文标题:Attention Augmented Convolutional Networks(ICCV 2019)
arXiv:https://arxiv.org/abs/1904.09925
github:https://github.com/leaderj1001/Attention-Augmented-Conv2d
笔记推荐:
论文标题:Self-Attention with Relative Position Representations(2018)
2、 Stand-Alone Self-Attention in Vision Models(NIPS 2019)
Stand-Alone Self-Attention in Vision Models(NIPS 2019)进一步提出完全使用Attention+相对位置embedding代替ResNet中的卷积模块,实现了全Attention的图像模型。与之前工作的差异是,本文提出使用local attention的方式,即类似于卷积,每个像素只和其周围几个像素点进行attention运算,降低了计算开销。图像中实现local attention的模型结构如下图所示。
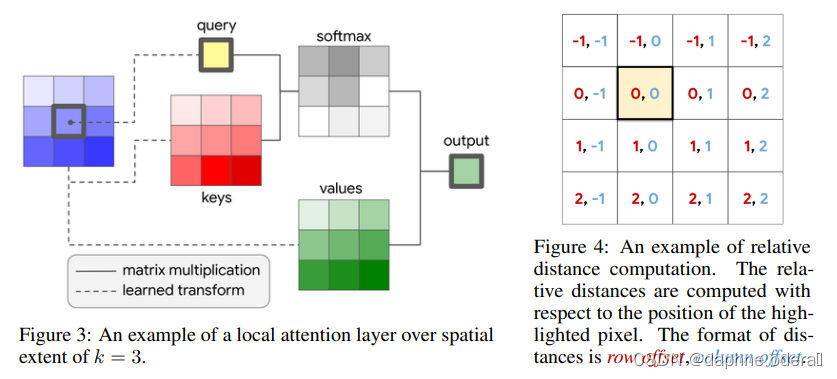
论文标题:Stand-Alone Self-Attention in Vision Models(NIPS 2019)
arXiv:https://arxiv.org/abs/1906.05909
github: https://github.com/leaderj1001/Stand-Alone-Self-Attention
3、CMT: Convolutional Neural Networks Meet Vision Transformers(CVPR 2022,CMT)
近年来,Transformer在视觉领域吸引了越来越多的关注,随之也自然的产生了一个疑问:到底CNN和Transformer哪个更好?CMT: Convolutional Neural Networks Meet Vision Transformers(CVPR 2022,CMT)华为诺亚实验室的研究员认为强强联手最好,提出一种新型视觉网络架构CMT,通过简单的结合传统卷积和Transformer,获得的网络性能优于谷歌提出的EfficientNet,ViT和MSRA的Swin Transformer。论文以多层次的Transformer为基础,在网络的层与层之间插入传统卷积,旨在通过卷积+全局注意力的方式层次化提取图像局部和全局特征。简单有效的结合证明在目前的视觉领域,使用传统卷积是提升模型性能的最快方法。在ImageNet图像识别任务,CMT-Small在相似计算量情况下Top-1正确率达83.5%,远高于Swin的81.3%和EfficientNet的82.9%。 整体架构如下图所示:
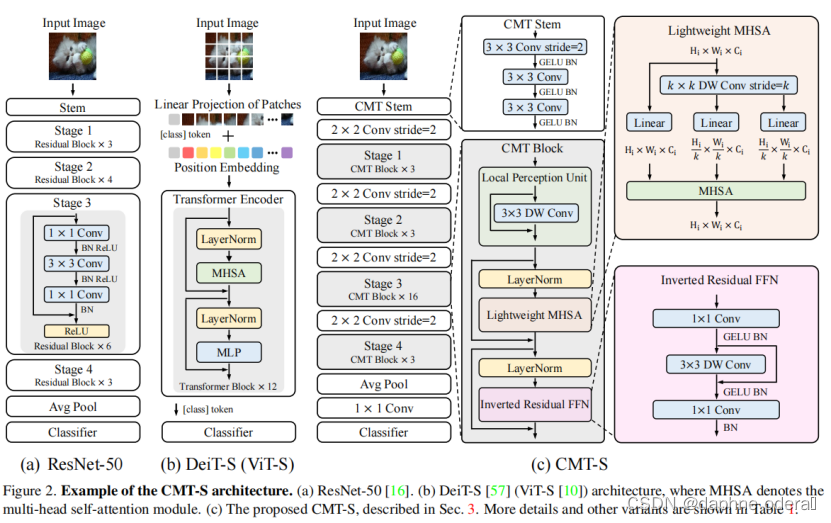
模型主要包括3个模块:
CMT stem(减小图片大小,提取本地信息)用于解决in-patch信息的建模问题,减小图片大小,提取细粒度特征和局部信息。首先是一个stride为2的 3×3 卷积,输出通道数为32,用于减小图片大小,然后是两个stride为1的 3×3 卷积以获得更好的局部信息提取。
Conv Stride(用来减少feature map,增大channel)卷积+layer norm,缩小中间特征的尺寸(分辨率下采样2倍),并将其投影到更大的维度(维度放大2倍),以产生层次化表示。
CMT block(捕获全局和局部关系)有助于在中间特征中同时捕捉局部和全局结构信息,提高网络的表示能力,包括局部感知单元,轻量多头自注意力和反向残差前馈网络。
论文标题:CMT: Convolutional Neural Networks Meet Vision Transformers(CVPR 2022,CMT)华为诺亚方舟实验室
arXiv:https://arxiv.org/abs/2107.06263
论文链接:CMT: Convolutional Neural Networks Meet Vision Transformers
4、Conformer: Convolution-augmented Transformer for Speech Recognition(2020,Conformer)
基于transformer和卷积神经网络cnn的模型在ASR上已经达到了较好的效果,都要优于RNN的效果。Transformer能够捕获长序列的依赖和基于内容的全局交互信息,CNN则能够有效利用局部特征。因此Conformer: Convolution-augmented Transformer for Speech Recognition(2020,Conformer)将transformer和cnn结合起来,对音频序列进行局部和全局依赖都进行建模,针对语音识别问题提出了卷积增强的transformer模型,称为conformer,模型性能比transformer和cnn都要好,成为了新的sota(当年)。
本文提出了一种新的self-attention和cnn结合起来的方式,在两方面都实现了最佳的效果:self-attention学习全局交互,cnn学习基于相对位置偏移的局部相关性,并将二者以sandwiched的方式结合起来,夹到一对前馈神经网络模块之间,模型结构如下图所示。提出的模型称为conformer,由两个macaron style(即feed-forward在两端,中间是multi-head self attention和convolution)的feed-forward的残差结构和multi-head self attention、convolution连接组成,后面跟着layernorm层进行归一化。

论文标题:Conformer: Convolution-augmented Transformer for Speech Recognition(2020,Conformer)
三、Transformer完全替代CNN
1、 End-to-End Object Detection with Transformers(ECCV 2020,DERT)
End-to-End Object Detection with Transformers(ECCV 2020,DERT)提出DERT模型,引入Transformer做目标检测任务。本文提出set prediction的方法解决目标检测任务,通过让模型预测N个元素(每个元素表示是否有目标,有目标的话预测目标的类别和位置),其中N大于图像中真正包含的目标,让这预测出来的N个结果和ground truth做一个匹配计算loss。这部分的细节感兴趣的同学可以阅读原文,我们下面主要介绍DERT的模型结构。DERT的目标是输入N个预测结果来和ground truth做匹配,采用了CNN+Transformer Encoder+Transformer Decoder的模型架构。输入图像维度为[3, W, H],首先利用CNN提取feature map,得到[C, W', H']的高阶表示。然后利用1*1的卷积将第一维进行压缩后,组成可以输入到Transformer模型中的2维序列数据,同时引入每个区块的position embedding和feature map对应进行拼接后输入到Encoder中,输入到Transformer Encoder中的维度为[d, W'*H']。Transformer Encoder的输出会进入到Decoder中,Decoder的输入也为可训练的N个position embedding,对应预测N个目标检测结果。最终N的输出分别进行FFN进行最终结果预测。DERT的模型结构如下图。
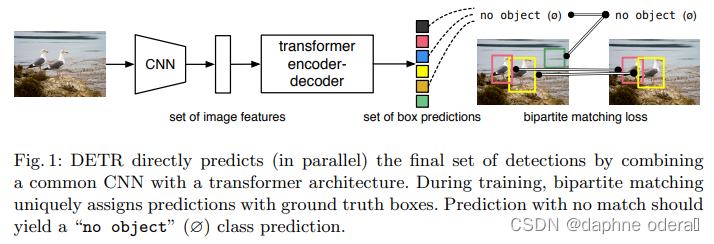
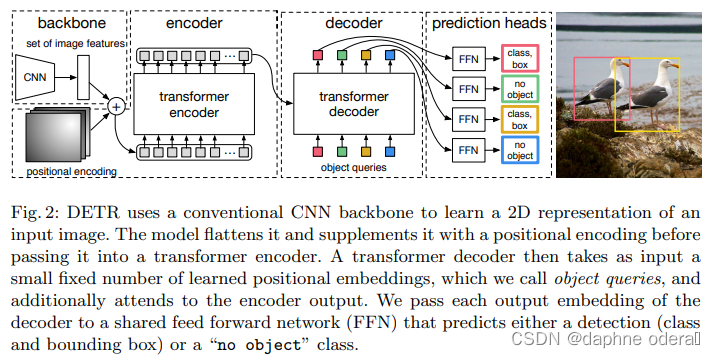
论文标题:End-to-End Object Detection with Transformers(ECCV 2020,DERT)
2、 Generative Pretraining from Pixels(ICML 2020)
Generative Pretraining from Pixels(ICML 2020)提出使用GPT在大规模图像样本上进行无监督预训练,生成图像表示用于下游任务。这篇工作采用的方法和GPT在NLP中的应用相似,对图像进行预处理,转换成生成分辨率较低的,然后转换成一维序列,输入到GPT模型中。文中尝试了Autoregressive(单向预测下一个像素点)以及Bert(mask掉部分像素点用上下文信息预测)两种预训练优化目标。使用这种方法预训练得到的图像表示,经过finetune后,在ImageNet上取得了72%的准确率。
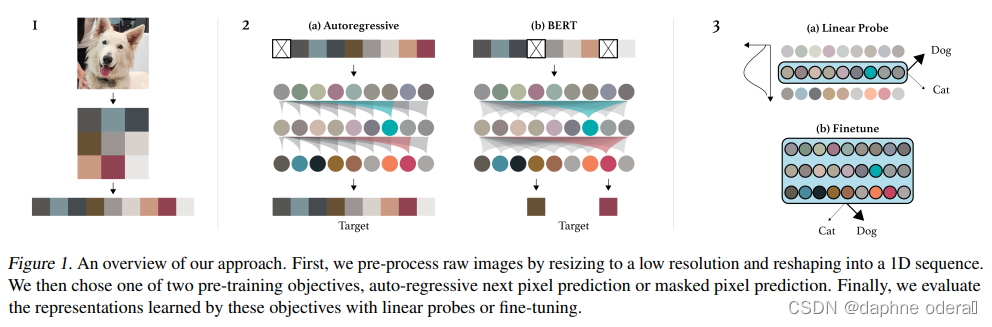
步骤:1、通过k-means将RGB值分成512个簇。然后每个像素被分配到最近的簇中心。2、降低图片分辨率,然后reshape为1D的输入。3、选择autoregressive或者BERT目标函数进行无监督训练。4、最后测试结果。
作者直接利用GPT-2 的模型结构,忽略图像的二维结构信息,直接将图像转化为一维序列作为输入,通过这这种方式地无监督生成式训练,GPT-2 在图像上也能学到很好的表达,预训练得到的模型在后续任务上不弱于甚至超过有监督学习得到的模型。
论文标题:Generative Pretraining from Pixels(ICML 2020)
论文链接:https://cdn.openai.com/papers/Generative_Pretraining_from_Pixels_V2.pdf
开源代码:https://link.zhihu.com/?target=https%3A//github.com/openai/image-gpt
3、 AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE(ICLR 2021,VIT)
AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE(ICLR 2021,VIT)提出了VIT模型,完全复用了NLP中Transformer的模型结构解决图像问题。VIT的具体做法是将图像处理成类似NLP中输入token序列的形式,输入到基础的Transformer中,实现图像领域的Transformer使用。具体做法为,将图像划分成多个patch,假设原来图像的维度是[W, H, C](宽度*高度*channel),那么经过转换后的图像维度为[N, P*P*C],其中P代表将图像的分成了多少个块,P对应的就是图像转换成的序列的长度。接下来每个patch会使用一个NN网络映射成一个固定维度,输入到后续的Transformer Encoder中。此外,position embedding也使用的是一维的。为了进行图像分类,类似于Bert,在序列起始位置添加了一个用于分类的标识token。文中也提到,使用Transfomer解决图像问题的主要问题在于缺少图像相关的inductive bias,CNN中的平移不变性、二维空间的临近关系等,在Transformer中都无法引入。但是文中通过实验验证,如果在大量充足的数据上进行预训练,VIT仍然能取得不错的效果。同时文中也提到,如果训练数据不充足,VIT的效果会大打折扣。
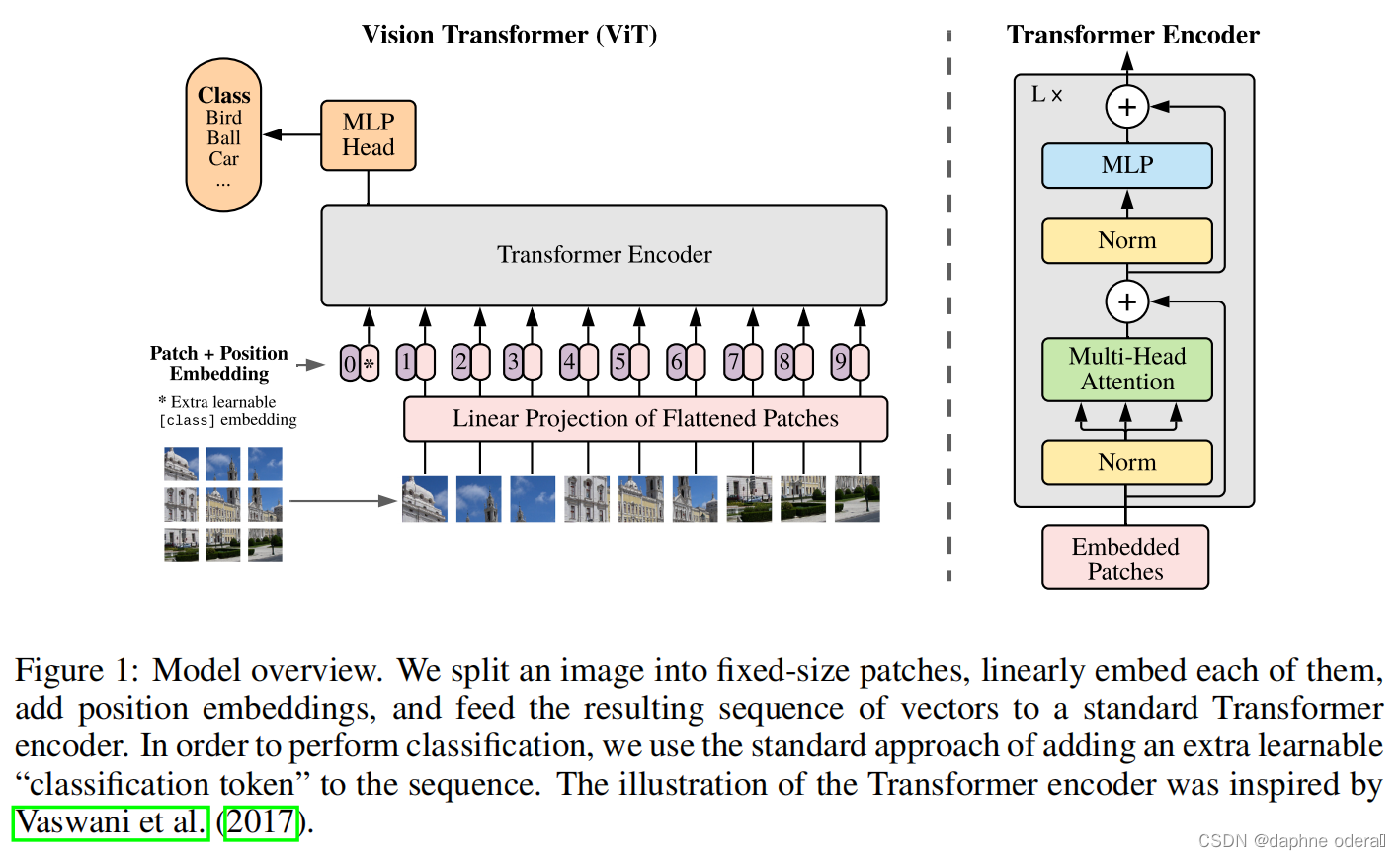
论文标题:An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale(ICLR 2021,VIT)
现如今,Vit衍生的模型百花齐放,层出不穷,即使是谷歌推出新一代MLP模型,其识别准确率已反超Transformer架构, 而通过Vit框架思路迭代的新模型至今会被例如CVPR会议收录,仍是很多视觉领域人员的研究重点,所以更多关于Vit模型内容请看官移步到以下文章(知乎的文章质量真的蛮高,内容也值得深思):
Vision Transformer , 通用 Vision Backbone 超详细解读 (原理分析+代码解读) (目录) - 知乎 (zhihu.com)
四、CV Transformer的效率和效果优化阶段
1、Transformer in Transformer(NIPS 2021)
在VIT的基础上,出现了一系列从效率、效果等角度的改进方法。Transformer in Transformer(NIPS 2021)提出了TNT模型。该方法的核心思路是,将原来VIT中的patch再进一步细分成sub-patch,将每个patch看成是一个sentence,而patch的进一步细分得到的元素看成是word。首先使用一个Inner Transformer对一个patch内的sub-patch进行表示生成。然后融合patch和sub-patch的信息,使用Outer Transformer在patch粒度进行表示生成。这种方式比较类似于NLP中的word-level和char-level信息的组合,它的本质思路是,将图像分成patch粒度太粗了,由于一个数据集中图像的多样性,如果将patch分解成粒度更细的sub-patch,就能在数据中发现更多相似的sub-patch组,提升模型在数据上的学习能力和泛化性。
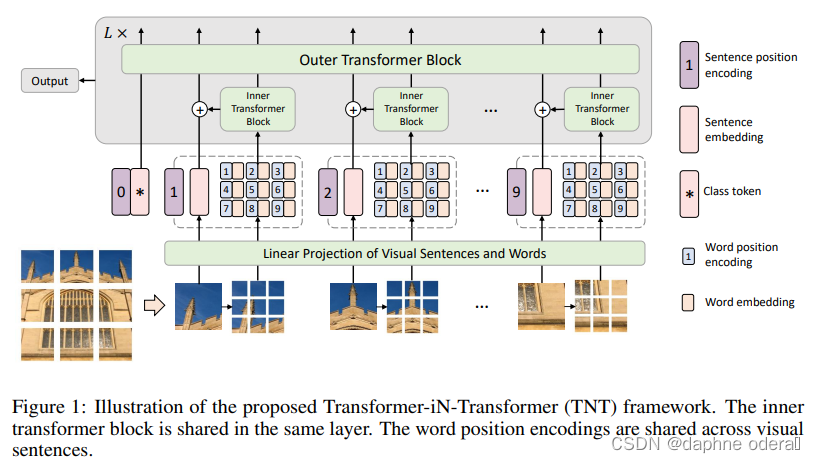
论文标题:Transformer in Transformer(NIPS 2021)华为诺亚方舟实验室
arXiv:https://arxiv.org/pdf/2103.00112.pdf
github:https://github.com/huawei-noah/Efficient-AI-Backbones/tree/master/tnt_pytorch
2、Pyramid Vision Transformer: A Versatile Backbone for Dense Prediction without Convolutions(ICCV 2021,PVT)
Pyramid Vision Transformer: A Versatile Backbone for Dense Prediction without Convolutions(ICCV 2021,PVT)提出了适用于像素级图像任务的Transformer模型(需要对每个像素点预测一个label)。之前的VIT将图像分成了patch,导致输出的结果分辨率较低,并且Transformer模型的计算开销随着序列长度增长而变大,直接应用像素级别的预测任务会导致计算和内存消耗暴涨。因此VIT还只适用于图像分类任务。为了解决上述问题,本文提出了将Pyramid CNN的思路引入Transformer,通过将初始分辨率调高,并逐层降低分辨率的方式,捕捉更细粒度信息,同时降低运行开销。PVT将模型分成4个阶段,每个阶段模型都会由patch embedding+Transformer组成,区别在于每层输出的分辨率是逐层降低的,从4*4的高分辨率逐渐变成32*32的低分辨率,适用于各种任务。模型结构图以及与VIT的对比如下:
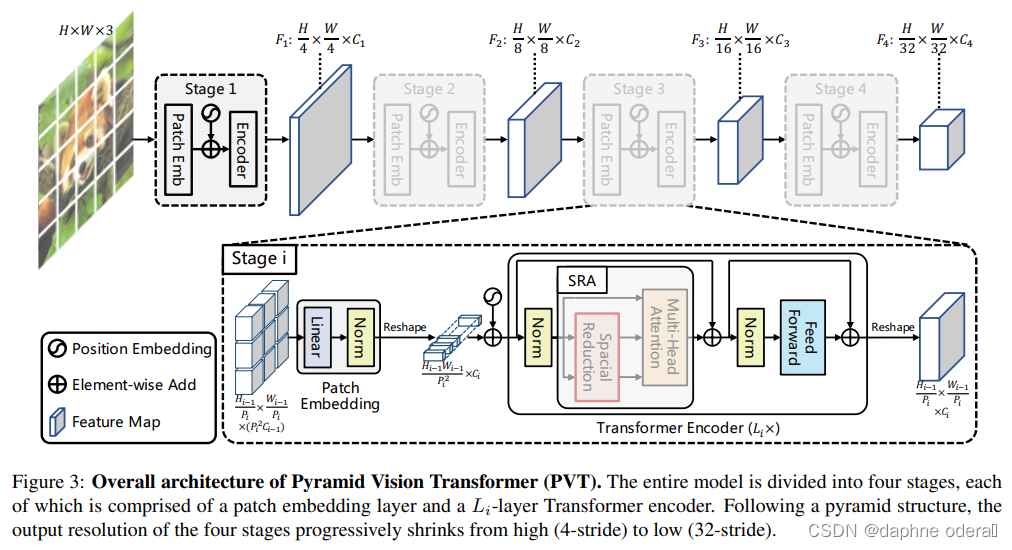
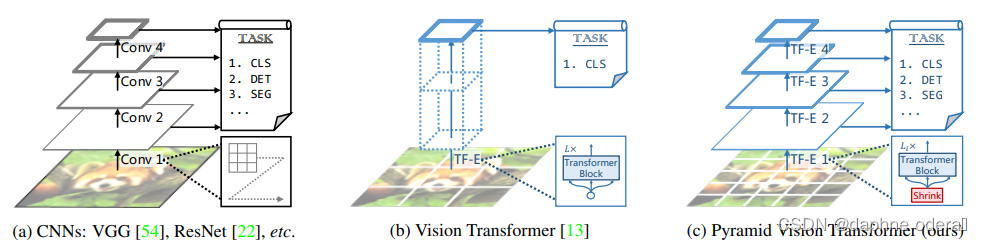
论文标题:Pyramid Vision Transformer: A Versatile Backbone for Dense Prediction without Convolutions(ICCV 2021,PVT)
3、 Tokens-to-Token ViT: Training Vision Transformers from Scratch on ImageNet(ICCV 2021,T2T-VIT)
Tokens-to-Token ViT: Training Vision Transformers from Scratch on ImageNet(ICCV 2021,T2T-VIT)提出了T2T-ViT模型。本文认为ViT之所以无法直接用中等数量数据集训练取得较好效果,是因为ViT对图像进行分patch拼接成序列的处理方法太简单了,模型无法学习到图像的结构信息,并且文中通过比较ViT和CNN中间每层输出的表示也印证了这一点。因此本文提出了新的Tokenize方法,将每一层的输出再还原成一个图像,然后在图像上进行soft split。Soft split指的是有重叠的进行patch划分,这样就建立起了上一层不同patch之间的关系。通过这种方法也使得网络输入序列的长度逐层减小。网络的具体结构如下图:

论文标题:Tokens-to-Token ViT: Training Vision Transformers from Scratch on ImageNet(ICCV 2021,T2T-VIT)
4、 Swin Transformer: Hierarchical Vision Transformer using Shifted Windows(ICCV 2021 最佳论文奖)
Swin Transformer: Hierarchical Vision Transformer using Shifted Windows(ICCV 2021 最佳论文奖)思路类似于PVT,也是将图像分成更细的batch,并且逐层合并降低分辨率。
如果说VIT将transformer从NLP领域应用到了视觉领域,但是它仅做了分类工作,Swin transformer的提出彻底将Transformer应用到了视觉领域的各个细分领域中,使得transformer成为了视觉领域的一个骨干网络。 Swin-T和Vit对比如下图所示。
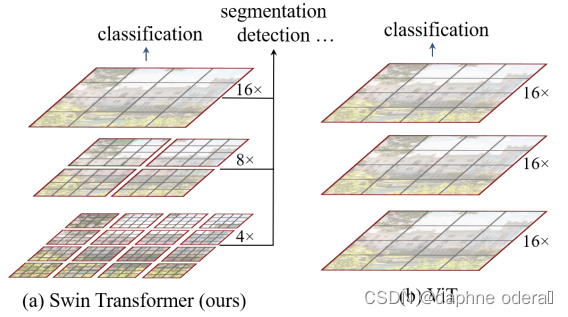
Swin Transformer中采用local attention的方式,将patch划分成window,patch间的attention只在window内进行,以提升运行效率。但是单纯基于窗口的自注意力计算方法丢失了相邻窗口间的相关性,限制了其建模能力。为了保持非重叠窗口的高效计算同时引入跨窗口连接,提出了shift-window,一种新的窗口划分方式:在两个连续的Swin-T Block中交替使用两种划分设置。
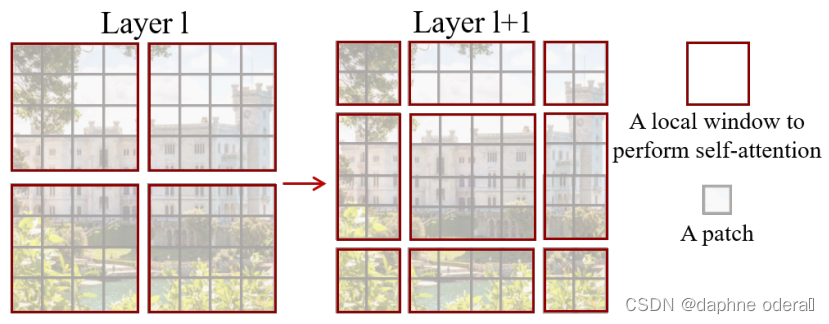 第一个模块使用从左上角patch开始的常规窗口分割策略,将8×8的特征图均匀的分割为4×4(该处M=4)的2×2个窗口。第二个模块窗口划分起点向右下(左上)移动M/2个patch,跨越了窗口的边界,提供了它们之间的连接。
第一个模块使用从左上角patch开始的常规窗口分割策略,将8×8的特征图均匀的分割为4×4(该处M=4)的2×2个窗口。第二个模块窗口划分起点向右下(左上)移动M/2个patch,跨越了窗口的边界,提供了它们之间的连接。
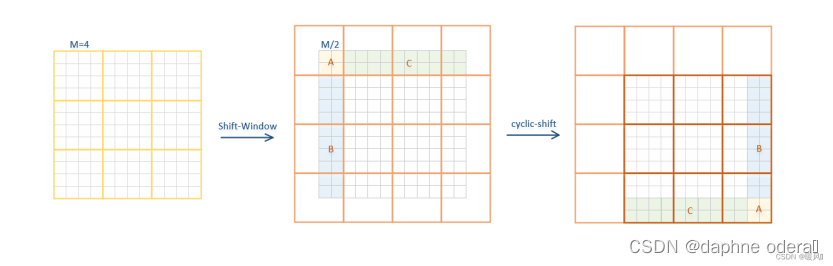 窗口经过移位后,导致窗口数量增加了。当常规分区中窗口数量很小时(例如2×2),增加的计算量就很大了(2×2)→(3×3),即2.25倍大,如上图所示。(一般窗口的数量都不会太多的)解决的方法是将较小的窗口填充到M×M的大小,并在计算注意力时屏蔽填充值。将左上方小块循环移位填充到右下方,如上图。在这个移位之后,某些窗口内可能由几个在特征图中不相邻的子窗口组成,因此使用掩蔽机制将自注意计算限制在每个子窗口内(这个子窗口是指被移动的不同颜色的小块构成的,这些有颜色的部分会被遮盖)。通过循环移位,窗口的数量与常规窗口分区的数量相同。
窗口经过移位后,导致窗口数量增加了。当常规分区中窗口数量很小时(例如2×2),增加的计算量就很大了(2×2)→(3×3),即2.25倍大,如上图所示。(一般窗口的数量都不会太多的)解决的方法是将较小的窗口填充到M×M的大小,并在计算注意力时屏蔽填充值。将左上方小块循环移位填充到右下方,如上图。在这个移位之后,某些窗口内可能由几个在特征图中不相邻的子窗口组成,因此使用掩蔽机制将自注意计算限制在每个子窗口内(这个子窗口是指被移动的不同颜色的小块构成的,这些有颜色的部分会被遮盖)。通过循环移位,窗口的数量与常规窗口分区的数量相同。
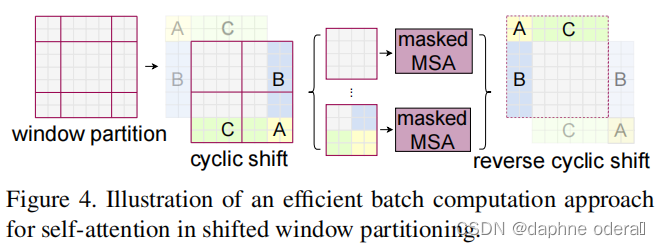
本文主要贡献:
1、基于局部窗口做注意力
2、构建了一种层次化的特征表示
3、关键部分是提出了Shift window移动窗口(W-MSA、SW-MSA),改进了ViT中忽略局部窗口之间相关性的问题。
4、并使用cyclic-shift 循环位移和mask机制,保证计算量不变,并且忽略不相关部分的注意力权重。
5、加入了相对位置偏置B。
论文标题:Swin Transformer: Hierarchical Vision Transformer using Shifted Windows(ICCV 2021 最佳论文奖)
arXiv:https://arxiv.org/abs/2103.14030
github:https://github.com/microsoft/Swin-Transformer
代码讲解:https://blog.csdn.net/qq_52302919/article/details/123988764
视频讲解:Swin Transformer论文精讲及其PyTorch逐行复现_哔哩哔哩_bilibili
笔记推荐:https://blog.csdn.net/qq_45122568/article/details/124659955
5、A Time Series is Worth 64 Words: Long-term Forecasting with Transformers(ICLR 2023)
自从时间序列预测论文Are transformers effective for time series forecasting?(2022)中以一个简单模型打败了复杂的Transformer模型后,关于Transformer是否适用于时间序列预测任务成为学术界一个主要争论点。ICLR 2023上的一篇文章A TIME SERIES IS WORTH 64 WORDS: LONG-TERM FORECASTING WITH TRANSFORMERS(ICLR 2023)中,提出了基于Transformer时序预测和时序表示学习新方法,将时间序列数据转换成类似Vision Transformer中的patch形式,取得非常显著的效果。
文中提出的模型名为PatchTST,整体结构如下图。对于原始的多变时间序列,首先拆成多个单变量时间序列,每个单变量序列独立的输入到共享参数的Transformer中,分别产出预测结果,最终再拼接到一起,得到最终的多变量预测结果。
对于一个单变量时间序列,将其分成有重叠或无重叠的patch。每个patch使用一个全连接映射到表示空间。此外,每个patch也会加上position embedding,标记各个patch的顺序。随后,每个单变量的patch序列输入到Transformer模型中进行编码,输出的编码经过全连接得到预测结果。

论文标题:A TIME SERIES IS WORTH 64 WORDS: LONG-TERM FORECASTING WITH TRANSFORMERS(ICLR 2023)
五、基于MLP的TiDE模型,未使用注意力机制、CNN和RNN
继之前针对Transformer在时间序列预测中真的有效吗、使用MLP打败复杂模型等研究后,谷歌在最佳发表了一篇最新的时间序列预测工作,Long-term Forecasting with TiDE: Time-series Dense Encoder(2023)提出了TiDE模型,整个模型没有任何注意力机制、RNN或CNN,完全由全连接组成。
模型整体可以分为Feature Projection、Dense Encoder、Dense Decoder、Temporal Decoder四个部分。
Feature Projection将外部变量映射到一个低维向量,使用Residual Block实现,主要目的是对外部变量进行降维。
Dense Encoder部分将历史序列、属性信息、外部变量映射的低维向量拼接到一起,使用多层Residual Block对其进行映射,最终得到一个编码结果e。
Dense Decoder部分将e使用同样的多层Residual Block映射成g,并将g进行reshape成一个[p, H]的矩阵。其中H对应的是预测窗口的长度,p是Decoder输出维度,相当于预测窗口每个时刻都得到一个向量。
Temporal Decoder将上一步的g和外部变量x按照时间维度拼接到一起,使用一个Residual Block进行每个时刻的输出结果映射,后续会加入历史序列的直接映射结果做一个残差连接,得到最终的预测结果。
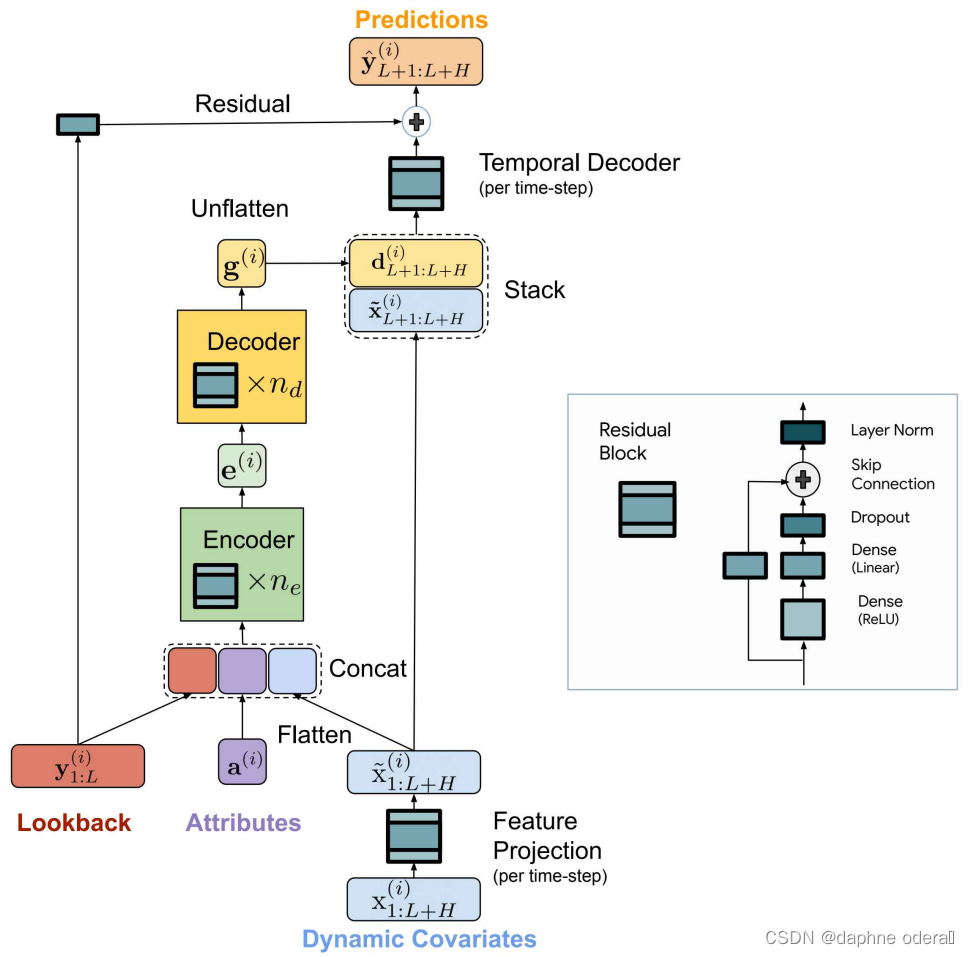
论文标题:Long-term Forecasting with TiDE: Time-series Dense Encoder(2023)
内容除本人阅读文献整理以外,另参考以下优质文章,有时间的小伙伴可以认真阅读一下:
https://mp.weixin.qq.com/s/e14myypqfYrPuBCv2rPCfA
此外,还有更多期刊会议相关论文整理:
2020顶级会议回顾 | 从这些最佳论文中总结研究趋势(文中附论文下载链接) - 腾讯云开发者社区-腾讯云 (tencent.com)