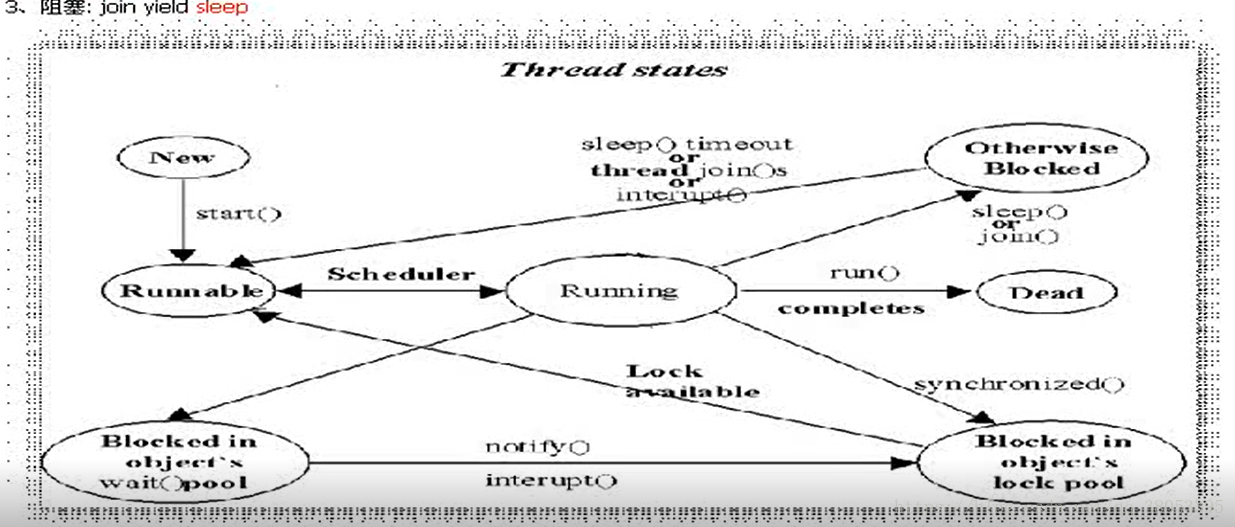
1.多线程的总结:


2.网络编程
注意:网络编程和网页编程不是一个概念(网络编程可以称为是网页的一个基础)



肯定是学类了:

底层还是要用到IO流的;
3.socket
socket(也叫套接字)最初是在Unix系统上开发的网络通信的接口。
后来微软等公司将它移植到了windows下,当然原来unix系统下的还是好用的。
对于socket可以这样理解:
它就是一个函数库,里面包括大量的函数和相应的数据结构,已经实现好了。
它支持网络通信。
程序开发人员可以通过阅读相关的函数文档,了解函数的使用方法,进行网络的编程。
两种形式的socket:流式套接字,对应与TCP协议。
数据报套接字,对应与UDP协议。
-
套接字
TCP用主机的IP地址加上主机上的端口号作为TCP连接的端点,这种端点就叫做套接字(socket)或插口。
套接字用(IP地址:端口号)表示。
它是网络通信过程中端点的抽象表示,包含进行网络通信必需的五种信息:连接使用的协议,本地主机的IP地址,本地进程的协议端口,远地主机的IP地址,远地进程的协议端口。
4.
Class InetAddress
static InetAddress |
getLocalHost()
返回本地主机的地址。
|
String |
getHostAddress()
返回文本显示中的IP地址字符串。
|
String |
getHostName()
获取此IP地址的主机名。
|
static InetAddress |
getByName(String host)
确定主机名称的IP地址。
|
注意:这个类是没有封装端口号的
这个类是没有公开的构造器的 所以他用静态方法返回InetAddress这个方法
package ip;
/**
* 测试InetAddress
*
*/
import java.net.InetAddress;
import java.net.UnknownHostException;
public class InetAddressDemo01 {
public static void main(String[] args) throws UnknownHostException {
// 使用getLocalHost方法创建InetAddress对象
InetAddress addr = InetAddress.getLocalHost();
System.out.println(addr.getHostAddress()); // 返回:本机的地址
System.out.println(addr.getHostName()); // 输出计算机名
// 根据域名得到InetAddress对象
addr = InetAddress.getByName("www.163.com");
System.out.println(addr.getHostAddress()); // 返回 163服务器的ip:61.135.253.15
System.out.println(addr.getHostName()); // 输出:www.163.com
// 根据ip得到InetAddress对象
addr = InetAddress.getByName("61.135.253.15");
System.out.println(addr.getHostAddress()); // 返回 163服务器的ip:61.135.253.15
System.out.println(addr.getHostName()); // 输出ip而不是域名。如果这个IP地
// 址不存在或DNS服务器不允许进行IP地址和域名的映射,getHostName方法就直接返回这个IP地址。
}
}
5.
Class InetSocketAddress
- java.lang.Object
-
- java.net.SocketAddress
-
- java.net.InetSocketAddress
-
该类实现IP套接字地址(IP地址+端口号)它也可以是一对(主机名+端口号),在这种情况下将尝试解析主机名。 如果解决方案失败,那么该地址被认为是 未解决的,但在某些情况下仍可以使用,例如通过代理连接。
package ip;
import java.net.InetAddress;
import java.net.InetSocketAddress;
import java.net.UnknownHostException;
/**
*
* 这个类其实就是InetAddress加上端口号
* 他有自己的构造器
*
* @author Wang
*
*/
public class InetSocketAddress01 {
public static void main(String[] args) throws UnknownHostException {
InetSocketAddress address = new InetSocketAddress("192.168.218.1",9);
address = new InetSocketAddress(InetAddress.getByName("192.168.218.1"),9);//上面的这个构造器实现的方法其实就是这样的 只不过他封装了一下
System.out.println(address.getHostName());
System.out.println(address.getPort());
InetAddress addr =address.getAddress();
System.out.println(addr.getHostAddress()); //返回:地址
System.out.println(addr.getHostName()); //输出计算机名字
}
}
6.URL

-
套接字
编辑
TCP用主机的IP地址加上主机上的端口号作为TCP连接的端点,这种端点就叫做套接字(socket)或插口。
套接字用(IP地址:端口号)表示。
它是网络通信过程中端点的抽象表示,包含进行网络通信必需的五种信息:连接使用的协议,本地主机的IP地址,本地进程的协议端口,远地主机的IP地址,远地进程的协议端口。
package URL;
import java.net.MalformedURLException;
import java.net.URL;
/**
*
* URL的简单例子
* @author Wang
*
*/
public class UrlDemo01 {
public static void main(String[] args) throws MalformedURLException {
//绝对路径构建
URL url = new URL("http://www.baidu.com:80/index.html?uname=bjsxt");
System.out.println("协议:"+url.getProtocol());
System.out.println("域名:"+url.getHost());
System.out.println("端口:"+url.getPort());
System.out.println("资源:"+url.getFile());
System.out.println("相对路径的资源:"+url.getPath());
System.out.println("锚点:"+url.getRef()); //锚点
System.out.println("参数:"+url.getQuery());//?后面的是参数 :存在锚点 参数会返回null ,不存在,返回参数的内容
url = new URL("http://www.baidu.com:80/a/");
url = new URL(url,"b.txt"); //相对路径的构建
System.out.println(url.toString());
}
}
如果不指明资源的相对路径那么我们默认访问的是网页的主页;
我们在这里写一个爬虫的第一步 获取主页的源代码;
注意我们的URL都是大写 这在我们以往的学习中是很少见的;
从
String表示形成一个
URL对象。
InputStream |
openStream()
打开与此
URL ,并返回一个
InputStream ,以便从该连接读取。
|
注意我们的转换流 , 一般都要与其对应的缓冲流相结合;
一是因为缓冲流能提高他们的读取速度,二是因为缓冲流有方便读取的方法比如说readLine(),而转换流中没有;请注意一下 下面转换流的用法;
package URL;
import java.io.BufferedReader;
import java.io.BufferedWriter;
import java.io.File;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStreamReader;
import java.io.OutputStreamWriter;
import java.net.URL;
/**
*
* 我们在这里写一个网络爬虫的第一步
*
* @author Wang
*
*/
public class urlDemo02 {
public static void main(String[] args) throws IOException {
URL url = new URL("https://www.baidu.com");
/*InputStream is = url.openStream();
byte[] flush = new byte[1024];
int length = 0;
while((length = is.read(flush)) != -1) {
System.out.println(new String(flush,0,length));//这里面会有乱码,是因为百度用的是UTF-8的字符集 我们eclipse的默认的编码集是GBK
//那么我们就想象到用处理流中的转换流(在这里我们也加上缓冲流来加快效率)来改变一下编码的字符集; 乱码的另一个原因 就是字节数不够这里显然不是
}
is.close();*/
/*BufferedReader br = new BufferedReader(new InputStreamReader(url.openStream(),"UTF-8"));
String info = null;//用一个字符串来接收一下读取到的字符;
while((info = br.readLine()) != null) {
System.out.println(info);//这次我们就不会出现乱码的问题了
//我们来把他写进一个文件中 文件的格式为.html那样就可以成为一个访问百度的快捷方式了
}
br.close()*/
BufferedReader br = new BufferedReader(new InputStreamReader(url.openStream(),"UTF-8"));
//BufferedWriter bw = new BufferedWriter(new OutputStreamWriter(new FileOutputStream("baidu.html"),"UTF-8"));
BufferedWriter bw = new BufferedWriter(new OutputStreamWriter(new FileOutputStream(new File("F:/testIO/baidu.html")),"UTF-8"));
String info = null;//用一个字符串来接收一下读取到的字符;
while((info = br.readLine()) != null) {
bw.append(info);
bw.newLine();
}
bw.flush();
bw.close();
br.close();
}
}