首先介绍一下Collectors 类的静态工厂方法
1.Collectors 类
| 工厂方法 | 返回类型 | 作用 |
|---|---|---|
| toList | List |
把流中所有项目收集到一个 List |
| toSet | Set |
把流中所有项目收集到一个 Set,删除重复项 |
| toCollection | Collection |
把流中所有项目收集到给定的供应源创建的集合menuStream.collect(toCollection(), ArrayList::new) |
| counting | Long | 计算流中元素的个数 |
| sumInt | Integer | 对流中项目的一个整数属性求和 |
| averagingInt | Double | 计算流中项目 Integer 属性的平均值 |
| summarizingInt | IntSummaryStatistics | 收集关于流中项目 Integer 属性的统计值,例如最大、最小、 总和与平均值 |
| joining | String | 连接对流中每个项目调用 toString 方法所生成的字符串collect(joining(", ")) |
| maxBy | Optional |
一个包裹了流中按照给定比较器选出的最大元素的 Optional, 或如果流为空则为 Optional.empty() |
| minBy | Optional |
一个包裹了流中按照给定比较器选出的最小元素的 Optional, 或如果流为空则为 Optional.empty() |
| reducing | 归约操作产生的类型 | 从一个作为累加器的初始值开始,利用 BinaryOperator 与流 中的元素逐个结合,从而将流归约为单个值累加int totalCalories = menuStream.collect(reducing(0, Dish::getCalories, Integer::sum)); |
| collectingAndThen | 转换函数返回的类型 | 包裹另一个收集器,对其结果应用转换函数int howManyDishes = menuStream.collect(collectingAndThen(toList(), List::size)) |
| groupingBy | Map> |
根据项目的一个属性的值对流中的项目作问组,并将属性值作 为结果 Map 的键 |
| partitioningBy | Map> |
根据对流中每个项目应用谓词的结果来对项目进行分区 |
1.1流的其他操作
- concat()–
此方法创建一个延迟连接的流,其元素是firstStream的所有元素,后跟secondStream的所有元素。 如果两个输入流都是有序的,则对所得到的流进行排序。如果任一输入流是并行的,则得到的流是平行的。 - peek()(Consumer<? super T> action)-------stream.peek的操作是返回一个新的stream的,主要是用来debug调试的,因此使用steam.peek()必须对流进行一次处理再产生一个新的stream
- ofNullable(T t)-如果此流不为null,则ofNullable(T)方法将返回包含单个元素的顺序Stream,否则该方法将返回空Stream。
- takeWhile()(Predicate<? super T> predicate)–takeWhile() 方法使用一个断言作为参数,获取满足断言条件的元素直到断言为false为止。丢弃后面的元素,如果第一个值不满足断言条件,将返回一个空的 Stream。
- dropWhile()(Predicate<? super T> predicate)—dropWhile 方法和 takeWhile 作用相反的,使用一个断言作为参数,从Stream中依次删除满足断言条件的元素,直到不满足条件为止结束删除
1.2Spliterator接口
Spliterator用来遍历和分割序列,它是为了并行执行而设计的;集合实现了 Spliterator 接口,提供了一个spliterator()方法
- tryAdvance() 方法的行为类似于普通的 Iterator ,因为它会按顺序一个一个使用 Spliterator 中的元素,并且如果还有其他元素要遍历就返回 true,否则返回false
- trySplit() --Spliterator最核心的方法;把一些元素划出去分给第二个 Spliterator (由该方法返回且装载已分割的元素),分割的Spliterator被用于每个子线程进行处理,从而达到并发处理的效果。当分割器Spliterator不能继续分割,则返回null。
- 如果两个或多个线程在同一个spliterator上并发运行,则拆分和遍历的行为是不确定的。如果原始线程将一个spliterator移交给另一个线程进行处理,最好是在使用tryAdvance()消费任何元素之前进行切换
- 理想的trySplit()方法有效地(无遍历)将其元素精确地分成两半,允许平衡并行计算。许多偏离这种理想仍然非常有效;
- forEachRemaining()–在当前线程中串行对剩余元素执行迭代操作,直到所有元素都被处理或抛出异常。 如果是串行的,则按相关顺序执行操作。异常被转发给调用者。
- estimateSize()—该接口是返回forEachRemaining遍历所遇到的元素数量的估计值,如果为无穷大,未知数或计算成本太高,则返回Long.MAX_VALUE。
2.分组方法
2.1groupingBy
使用 groupingBy() 将数据进行分组,最终返回一个 Map 类型。
根据部门对用户列表进行分组。
/**
* 使用 groupingBy() 分组 by 青冘
*/
@Test
public void groupingByTest()
{
//获取用户列表
List<User> userList = UserService.getUserList();
//根据部门对用户列表进行分组
Map<String,List<User>> userMap = userList.stream().collect(Collectors.groupingBy(User::getDepartment));
//遍历分组后的结果
userMap.forEach((key, value) -> {
System.out.println(key + ":");
value.forEach(System.out::println);
System.out.println("--------------------------------------------------------------------------");
});
}执行结果:

2.2多级分组
groupingBy 可以接受一个第二参数实现多级分组。
根据部门和性别对用户列表进行分组。
/**
* 使用 groupingBy() 多级分组 by 青冘
*/
@Test
public void multGroupingByTest()
{
//获取用户列表
List<User> userList = UserService.getUserList();
//根据部门和性别对用户列表进行分组
Map<String,Map<String,List<User>>> userMap = userList.stream()
.collect(Collectors.groupingBy(User::getDepartment,Collectors.groupingBy(User::getSex)));
//遍历分组后的结果
userMap.forEach((key1, map) -> {
System.out.println(key1 + ":");
map.forEach((key2,user)->
{
System.out.println(key2 + ":");
user.forEach(System.out::println);
});
System.out.println("--------------------------------------------------------------------------");
});
}执行结果:

2.3分组汇总
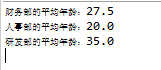
根据部门进行分组,汇总各个部门用户的平均年龄。
/**
* 使用 groupingBy() 分组汇总 by 青冘
*/
@Test
public void groupCollectTest()
{
//获取用户列表
List<User> userList = UserService.getUserList();
//根据部门进行分组,汇总各个部门用户的平均年龄
Map<String, Double> userMap = userList.stream().collect(Collectors.groupingBy(User::getDepartment, Collectors.averagingInt(User::getAge)));
//遍历分组后的结果
userMap.forEach((key, value) -> {
System.out.println(key + "的平均年龄:" + value);
});
}执行结果:
3.排序方法
3.1 sorted() / sorted((T, T) -> int)
如果流中的元素的类实现了 Comparable 接口,即有自己的排序规则,那么可以直接调用 sorted() 方法对元素进行排序,如 Stream。反之, 需要调用 sorted((T, T) -> int) 实现 Comparator 接口。
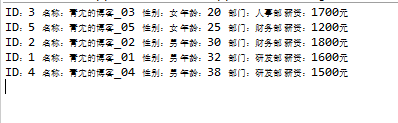
根据用户年龄进行排序。
/**
* 使用 sorted() 排序 by 青冘
*/
@Test
public void sortedTest()
{
//获取用户列表
List<User> userList = UserService.getUserList();
//根据年龄排序(升序)
userList = userList.stream().sorted((u1, u2) -> u1.getAge() - u2.getAge()).collect(Collectors.toList());
//推荐:userList = userList.stream().sorted(Comparator.comparingInt(User::getAge)).collect(Collectors.toList());
//降序:userList = userList.stream().sorted(Comparator.comparingInt(User::getAge).reversed()).collect(Collectors.toList());
//遍历用户列表
userList.forEach(System.out::println);
}执行结果:
4.安卓兼容
如果是安卓使用stream会报错提示SDK必须大于24才能使用
但是有用户的机型SDK是小于24的,这样肯定不行的。
可以在app\build.gradle中添加引用的库;如下:
implementation 'com.annimon:stream:1.2.1'
注意:
在导包的时候,要导如下:
import com.annimon.stream.Collectors;
import com.annimon.stream.Stream;
在使用的时候有一些不同
是使用Stream.of()
ArrayList<Person> arrayList = new ArrayList<>();
List<String> names = Stream.of(arrayList)
.map(Person::getName)
.collect(Collectors.toList());