克雷西 萧箫 发自 凹非寺
量子位 | 公众号 QbitAI
他来了他来了,老黄带着「最强生成式AI处理器」和一系列重磅更新来了!

在计算机图形学顶会SIGGRAPH上,老黄宣布了英伟达最新的超级芯片NVIDIA DGX GH200 Grace Hopper。
这块芯片搭载了全球最快的内存,不仅带宽每秒5TB,内存容量更是暴增接近50%来到141GB,「任何大语言模型都能运行」。
同时,英伟达还宣布了和Hugging Face的合作——
以后在Hugging Face平台上,不需要再下载ML模型自己运行,只需要几步简单操作,就能在笔记本上运行大模型,有Colab内味了(就是不知道有没有免费版)。
至于软件更新,字里行间也全是AI。
不仅在Omniverse平台中集成了一系列时下热门的AI工具,新的软件有不少也是基于大模型打造,像ChatUSD就能帮开发者们写代码。
这也是时隔五年,老黄再次登上SIGGRAPH的舞台。在会上,他自信满满地宣布:
生成式人工智能的「iPhone时刻」,已经来临。
有网友看完发布会后感慨:
英伟达在AI硬件这方面,已经无人能及了。
新芯片组成的「最强超算」来袭
这场发布会中最先抛出,也是最引人瞩目的,非「最强超算」莫属。
这台超级计算机由256块DGX GH200 Grace Hopper(简称DGX GH200)连接而成。
用老黄的话,这个「庞然大物」就是为AIGC时代量身打造的。
它的算力和内存容量分别达到了1E(10^15)FLOPS和144TB。
下面这张图展示了它的真实大小(中间的黑影是老黄)。

不仅是性能优异,对比发现,性价比简直完爆CPU。
同样花1亿美元,拿来买CPU和GPU分别能得到什么?
CPU的话,可以买8800个x86架构的产品。
这近九千块CPU加起来,只能带动一个LLaMA 2、SDXL这样规模的AI程序。
功率嘛……是5兆瓦,也就是每小时5000度电。

如果换成GPU的话,则是2500块DGX GH200。
能带动的近似规模的AI程序一下增加到了12个,功率却降低到了3兆瓦。

平均到单个程序上,需要210块DGX GH200,价格是800万美元,功率则为0.26兆瓦。

而组成这个「最强超算」的DGX GH200,同样是王者级别,被称为「最强生成式AI处理器」。

DGX GH200由Grace CPU和Hopper GPU组成。
其中Grace CPU包含72核心,而后者拥有4P(10^12)FLOPS的算力和500GB的LPDDR5X。
此外,DGX GH200中还加入了海力士的「最快内存」HBM3e。
它的容量为141GB,带宽则高达每秒5TB,分别是H100的1.7倍和1.55倍。
(好家伙,H100都只配当baseline了)

在DGX GH200中,CPU和GPU之间的连接速度是第五代PCIe的7倍。

而从单块DGX GH200到整个超级计算机的过程,主打的就是一个「叠」。
这要得益于它的多GPU高速连接能力。
双联体的DGX GH200,性能几乎没有损失,直接就是单体的两倍。

将双联体的DGX GH200与BlueField-3 DPU和ConnectX-7网卡,就组成了一个「计算盒」。

通过NVLink,8个这样的「计算盒」高速连接,就得到了DGX构建块,总内存达到了4.6TB。

这样的构建块可以合二为一形成新的计算盒,并最终扩展成256 GPU的工作集群Superpod。
NVLink的高速连接能力,让这256块GPU「就像是一块一样」工作。

至此,显卡超算的规模已经达到了本节开头老黄所展示的水平。
但这还没有结束——Superpod之间还能继续连接。
在高速低延时的Quantum-2 Infiniband平台帮助下,超算的规模可以接着扩展……

讲到这里,老黄还打趣道:
如果哪天你从(某电商平台)上买显卡的时候发现了它,千万不要觉得惊讶!
总之,根据不同需要,利用DGX GH200将能构建出不同规模的、适应AIGC时代的超级计算机。
据预计,DGX GH200将于明(2024)年第二季度投产。
还发了3个RTX新专业显卡
除了「最强生成式AI处理器」以外,英伟达这次也推出了3款船新的工作站显卡:
RTX 5000、RTX 4500和RTX 4000。
这几款显卡均基于Ada Lovelace架构设计,目前参数已经同步英伟达官网:
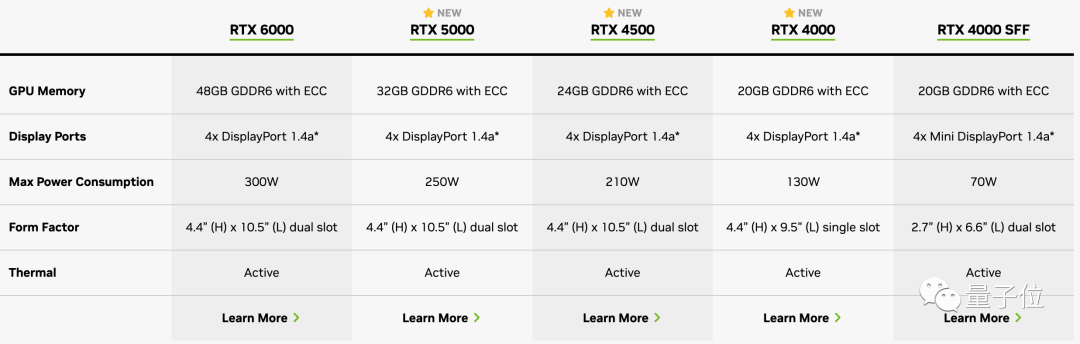
当然,专业显卡售价也更贵。
其中RTX 5000售价达到4000美元(约合人民币2.87万元),RTX 4500售价2250美元(约1.6万元),RTX 4000售价1250美元(约8987元)。
老黄也在发布RTX显卡时,再次说出那句经典名言:
买得越多,省得越多(the more you buy, the more you save)。

至于去年9月发布的RTX 6000 Ada显卡,在这次大会上也推出了一个新的工作站设计:4块叠起来,搞个顶级「叠叠乐」。
这样设计的单个RTX工作站,单个可以提供5828 TFLOPS的AI性能,以及192GB的GPU内存。
除此之外,老黄还在这次大会上宣布了一个搭载L40S Ada GPU的新款OVX服务器,数据中心专用。

每台服务器搭载8块L40S Ada GPU,每块L40S包含高达18176个CUDA核心,可以提供近5倍于A100的单精度浮点(FP32)性能。
相比A100,L40S微调(fine-tune)大模型的性能提升了大约1.7倍。
(没错,A100已经被老黄用来给新硬件当对比了)
具体来说,在这个OVX服务器上微调一个几百亿参数的大模型,现在只需要几小时就可以完成;
像400亿参数的GPT-3大模型,860M token只需要7个小时就能微调完成。
在渲染上,L40S性能也不错,配备了142个第三代RT核心,可以提供212 teraflops的光线追踪性能。
预计L40S将于今年秋季上市。
AIGC版Colab来了,笔记本跑大模型
不仅是硬件上接连抛出一系列「重磅炸弹」,软件方面英伟达也发布了多款新产品。
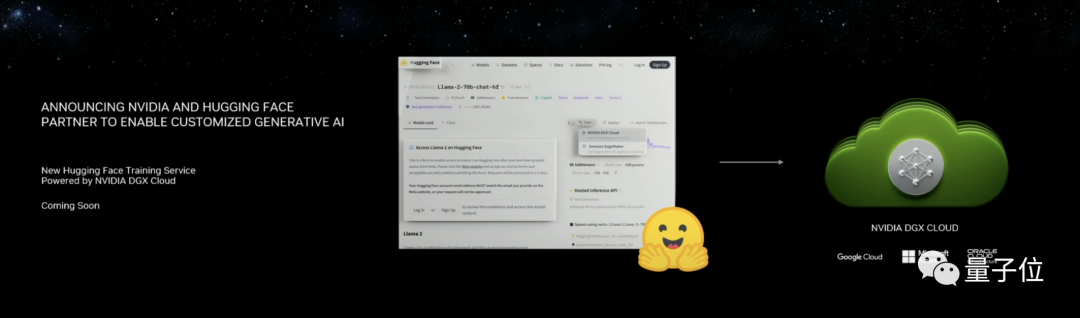
首先是和HuggingFace合作,把NVIDIA DGX Cloud AI整合到其中。
在HF的页面中,一键就能让模型在云上调整运行。
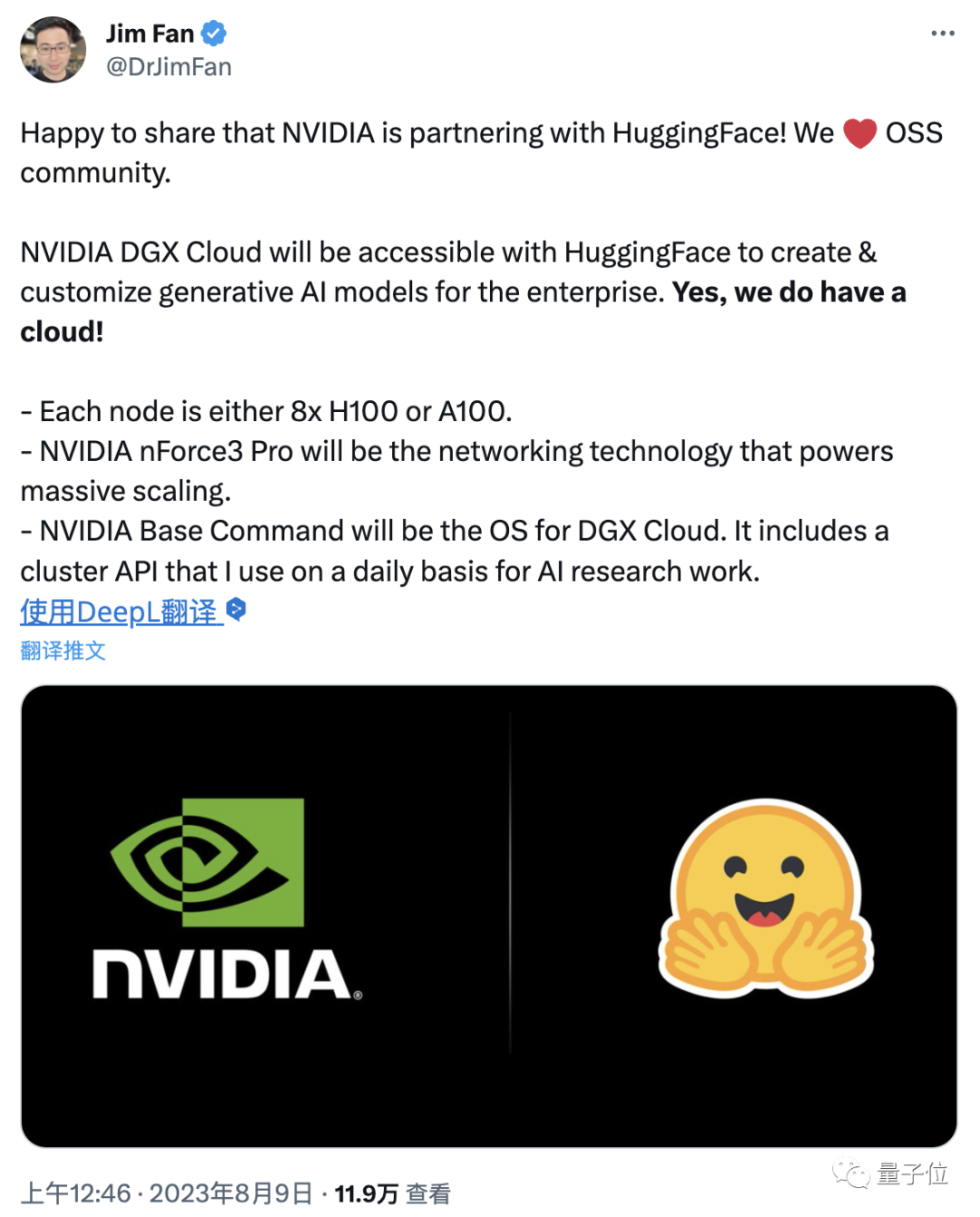
英伟达科学家范麟熙(Jim Fan)激动地宣布了这一消息,还透露其中使用的每个节点都是8个H100或A100。
除了与HF合作,英伟达还推出了自己的Workbench平台。
通过连接云端服务,用笔记本电脑就能跑大模型。
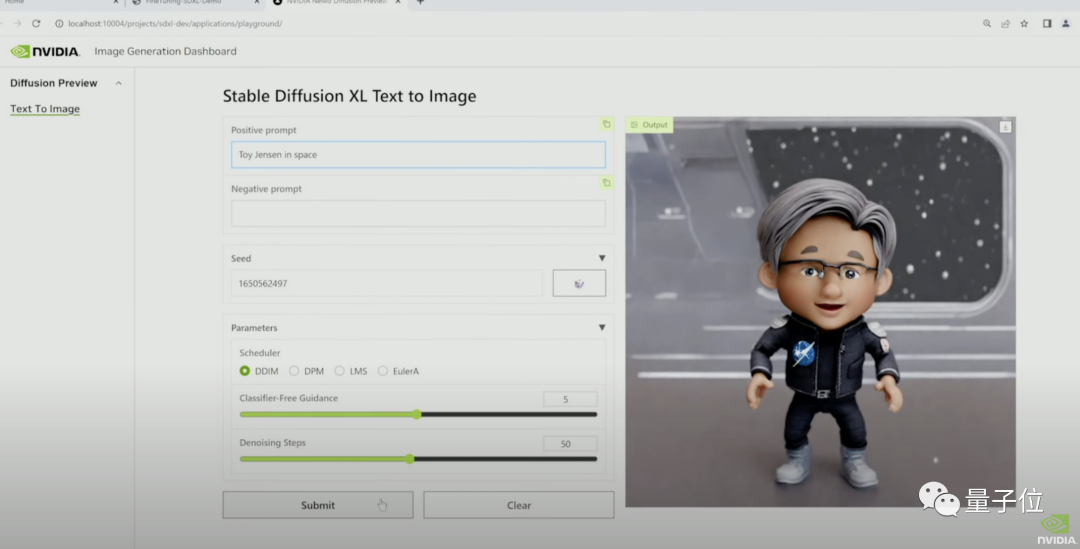
现场还播放了通过Workbench跑SDXL的演示视频。
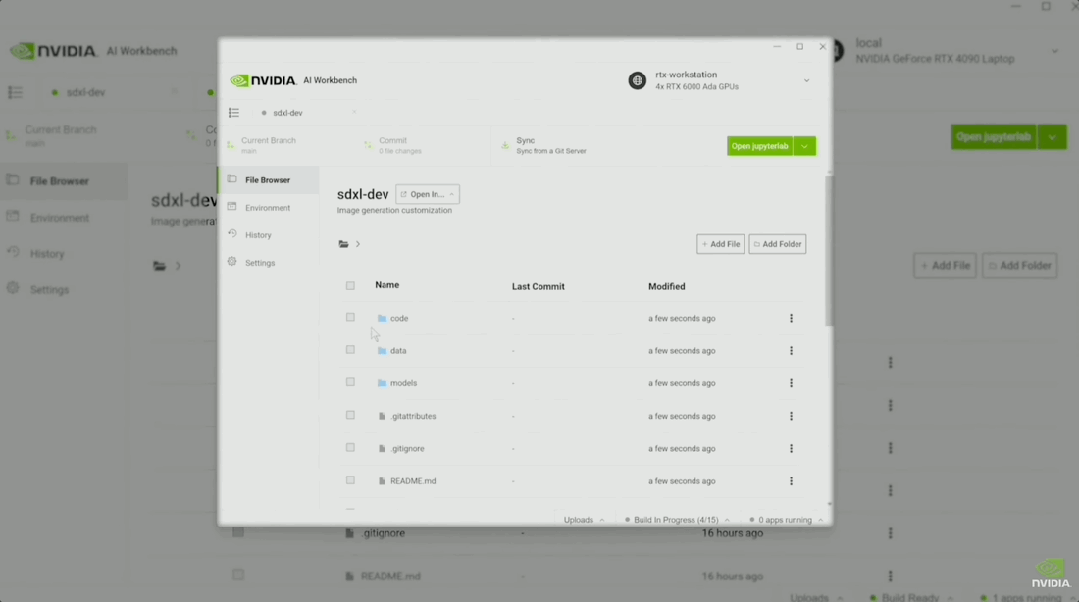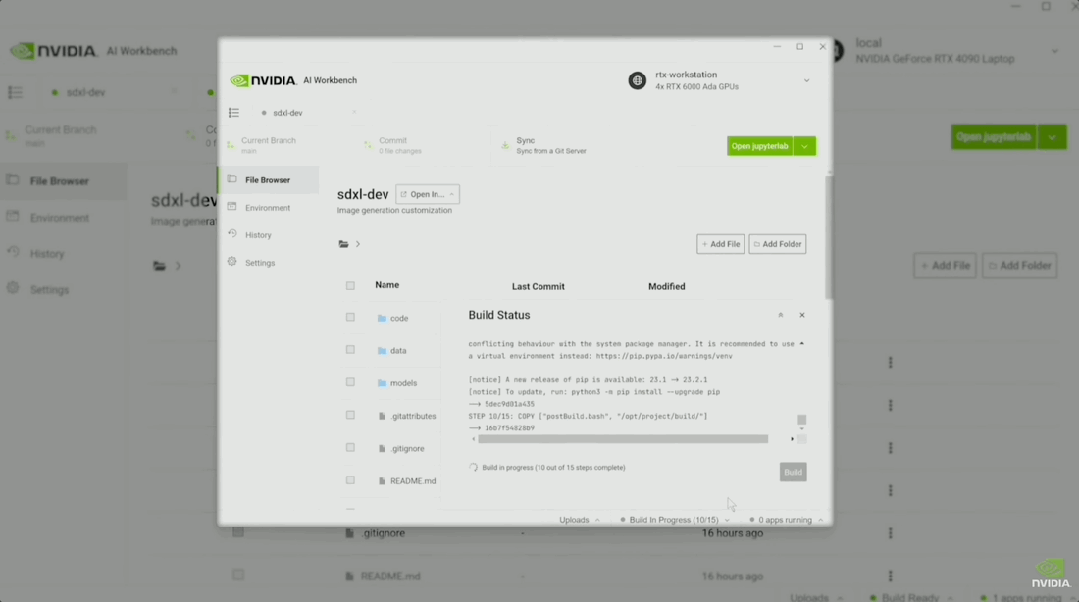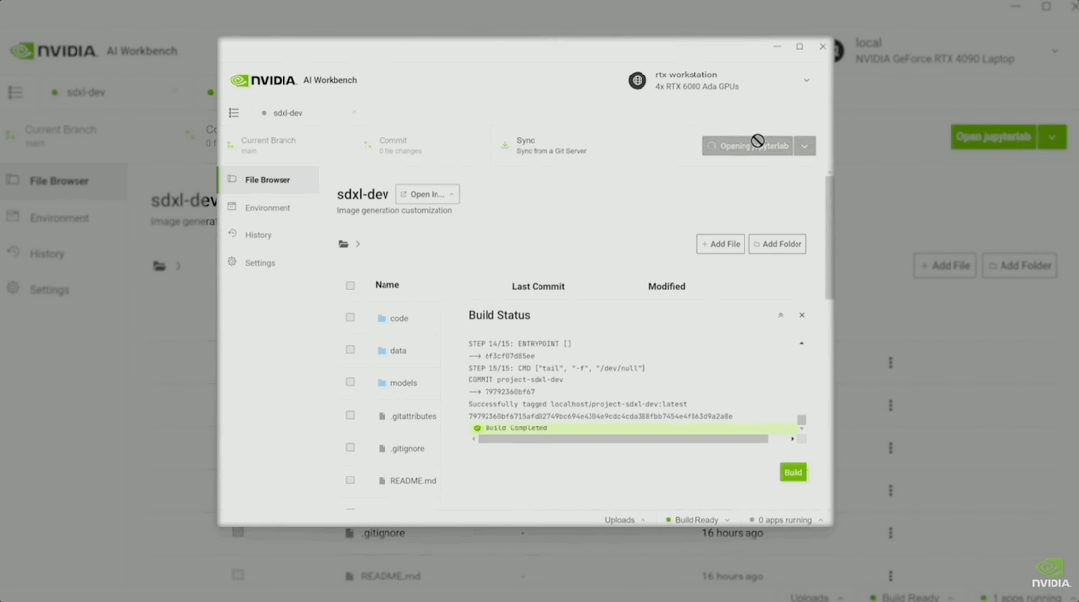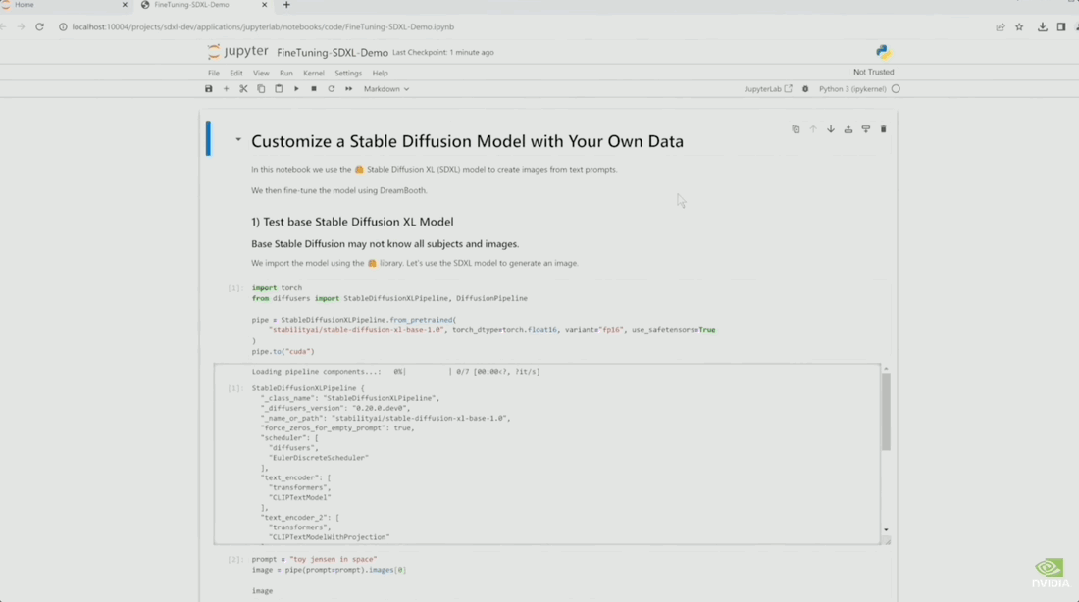
在Jupyter中,演示者让SDXL画一个「玩具老黄」。
此时的SDXL还不知道「玩具老黄」是个啥玩意儿。
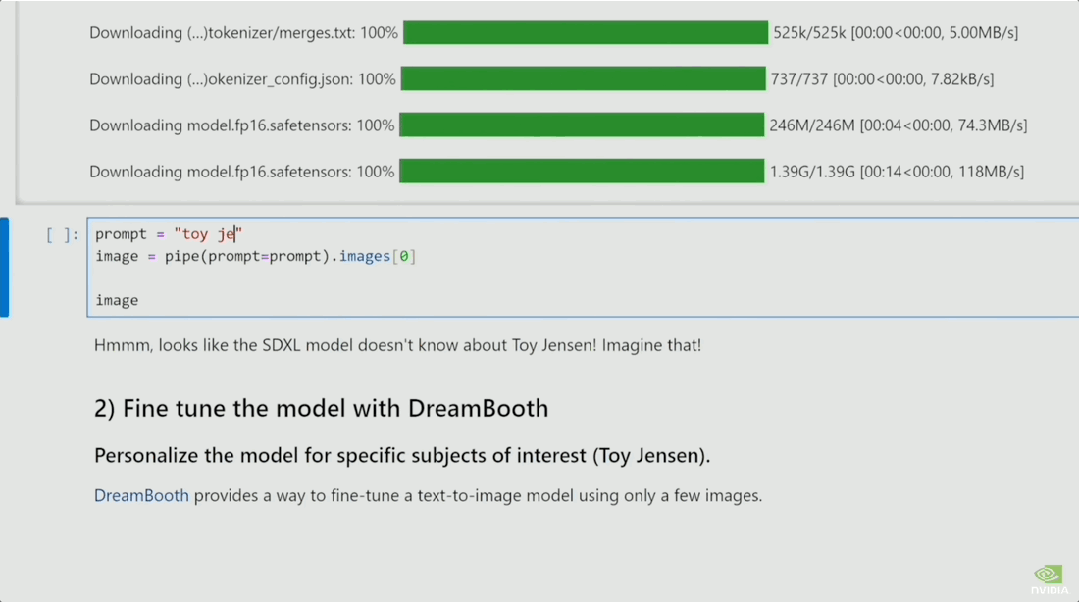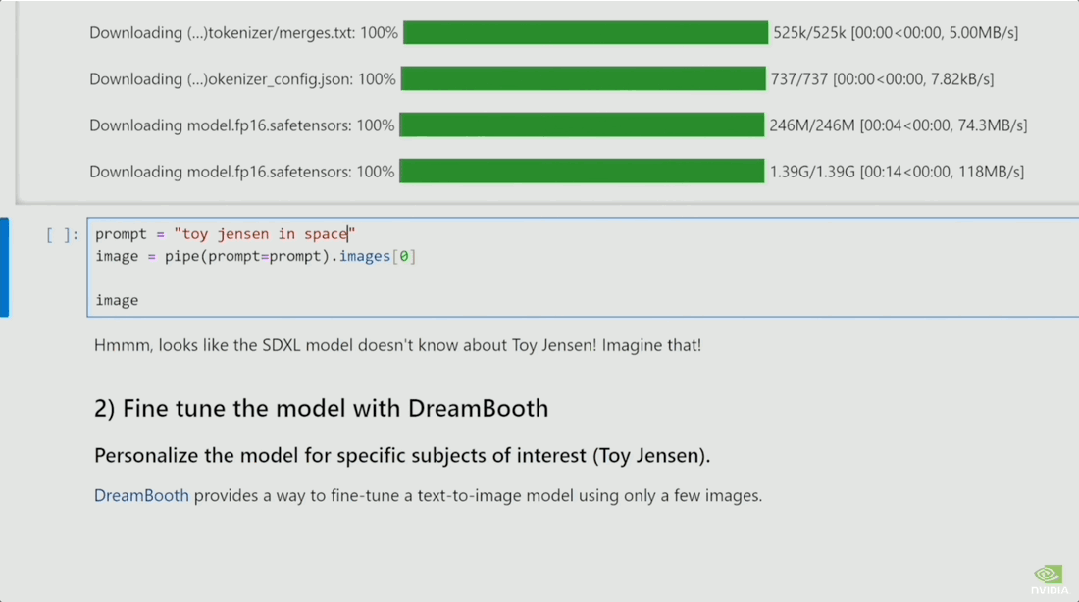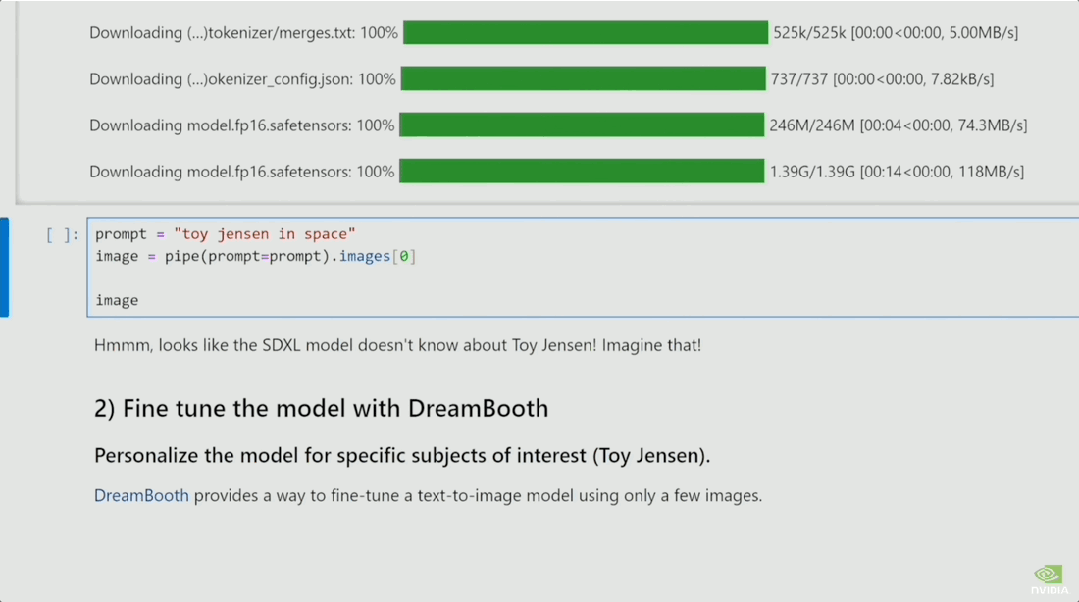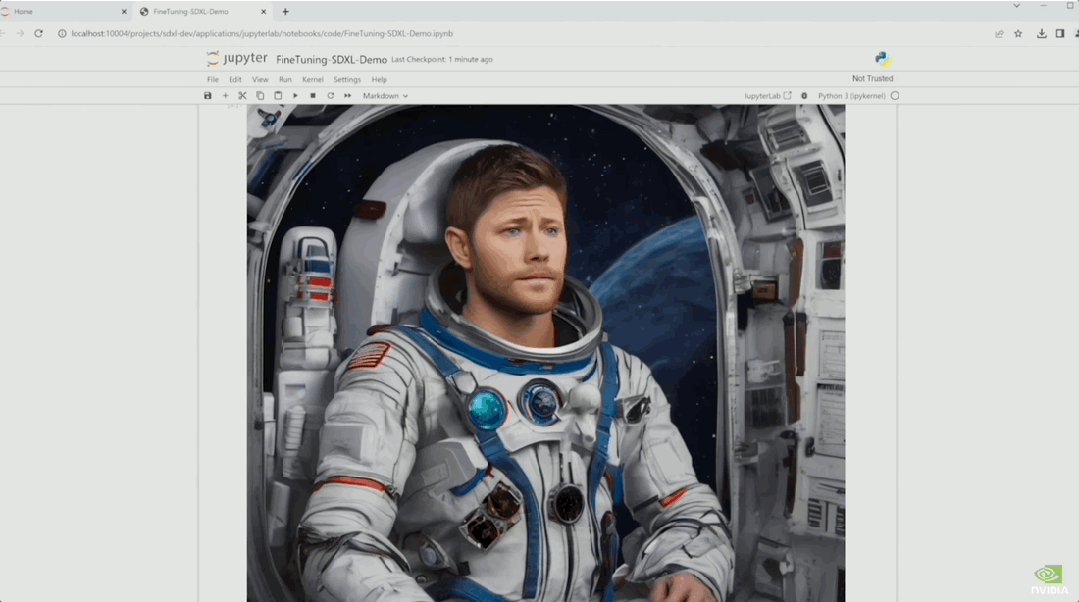
于是演示者现场用8张图对模型进行了微调。

微调后重新绘制的作品,是不是有那味了?
除了上述两款大模型运行工具,英伟达还推出了最新版的企业软件平台NVIDIA AI enterprise 4.0。
软件包的数量达到了4500个,还有数以万计的相关依赖,而且安全可靠。

谷歌、微软、亚马逊、甲骨文等英伟达合作方都会在自己的云平台中集成这项服务。
「人类将成为一门新的编程语言」
除此之外,英伟达的计算机图形与仿真模拟平台Omniverse,也宣布了一系列新进展。
一方面,更多AI工具可以直接在Omniverse里面调用了。
包括对话式AI角色创建工具Convai、高保真AI动捕工具Move AI、AI低成本制作CG工具CGWonder Dynamics在内,一系列流行AI工具,现在都已经通过OpenUSD集成到Omniverse中。
就连Adobe,也计划将Adobe Firefly作为API,提供在Omniverse中(就是估计会收费)。

另一方面,英伟达还将生成式AI技术和OpenUSD结合,推出了一些好用的AI工具。
例如ChatUSD,就是一个基于NVIDIA Nemo框架大模型Copilot,不仅可以回答开发者有关USD的问题,还能帮忙生成Python-USD代码。
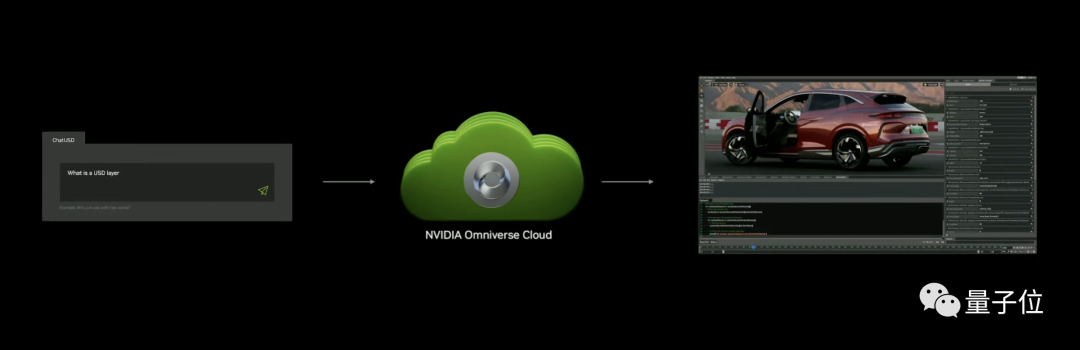
又例如DeepSearch,也是一个基于大模型的新工具,基于文本或图像输入,可以快速对数据库进行3D语义搜索。
在这次大会上,老黄先是回顾了自己过去所做的「正确决定」——用AI重塑CG,为AI重新发明GPU。
随后,他对未来AI行业的发展做了大胆的展望:
未来,几乎所有事物的前方都会有一个大语言模型。
「人」,将成为一种新的编程语言。
以工厂为例,老黄认为,未来的工厂将会由软件和机器人来「主宰」。
像汽车这样的产品,本身就是机器人,所以生产汽车的工厂,将会呈现出机器人制造机器人的场面。
看来,乘大模型东风迅速崛起的英伟达,这次是真的要ALL IN生成式AI了。
参考链接:
[1]https://www.anandtech.com/show/20001/nvidia-unveils-gh200-grace-hopper-gpu-with-hbm3e-memory
[2]https://twitter.com/DrJimFan/status/1688954935248027648
[3]https://tehcrunch.com/2023/08/08/nvidia-ceo-we-bet-the-farm-on-ai-and-no-one-knew-it
[4]https://www.youtube.com/watch?v=3qSQjRaseos