ChatGLM 更新:LongBench—评测长文本理解能力的数据集,支持 32k 上下文的 ChatGLM2-6B-32K
收录于合集#人工智能50个
“ ChatGLM这次推出了两大更新!一个是长文理解能力测试集LongBench,让我们可以检验 ChatGLM 阅读长篇文章的水平。另一个是全新支持32K上下文的ChatGLM2-6B-32K模型!这无疑将会带来更连贯、合理的长篇对话体验。”

01
—
之前有朋友吐槽,ChatGLM 处理长对话时上下文理解得不好,记忆力差。但现在有了新的长文本数据集和支持更长上下文的模型,ChatGLM 的表现大为改善。ChatGLM 推出了评测长文本理解能力的 LongBench 数据集和支持更长上下文的 ChatGLM2-6B-32K 模型。
上下文窗口大小是影响模型解决更广泛问题的重要维度之一。为了解决这一问题,GLM 技术团队基于内部长期的探索,开发了专门针对模型长文本理解能力的评测数据集 LongBench。
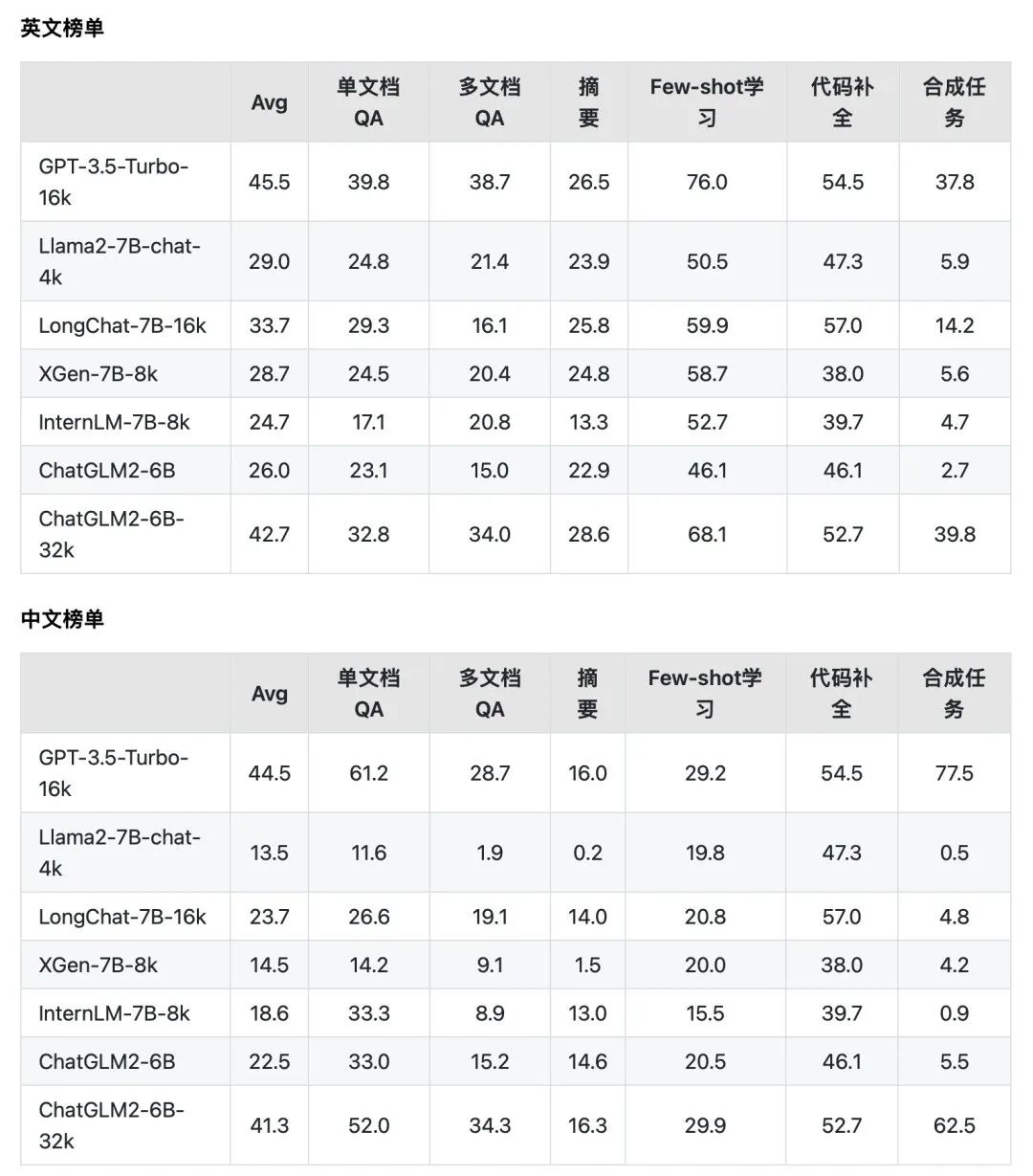
该数据集包含了 13 个英文任务、5个中文任务和 2 个代码任务。多数任务的平均长度在5k-15k之间,共包含约4500条测试数据。
从主要任务分类上,LongBench包含单文档QA、多文档QA、摘要、Few-shot学习、代码补全和合成任务等六大类任务 20 个不同子任务。
Few-shot学习(Few-shot Learning)是一种机器学习的范式,旨在解决在极少量(少于常规监督学习所需数据量)标注样本的情况下进行学习和泛化的问题。
LongBench 特点
双语:LongBench 能够针对中、英双语的长文本进行更全面的评估。
多任务:LongBench由六大类、二十个不同的任务组成,覆盖了单文档QA、多文档QA、摘要、Few-shot学习、代码补全和合成任务等关键的长文本应用场景。
自动评测:因为模型评测过程中可能产生的高昂成本,尤其是长文本场景下(如人工标注成本或API调用成本)。因此,官方采用了一种全自动的评测方式,旨在以最低的成本,最有效地衡量和评估模型的长文本理解能力。
利用该评测数据集,官方分别对 GPT-3.5-Turbo-16k、Llama2-7B-chat-4k、LongChat-7B-16k、XGen-7B-8k、InternLM-7B-8k、ChatGLM2-6B、ChatGLM2-6B-32k* 等 7 个支持长文本的模型的性能。

在文章《为什么你在用 ChatGPT 的提示词 Prompt 似乎效果不如人意?》中,大模型在不同语言之间的推理能力不同,所以数据集需要包含中英两种语言,以提高模型的表现。
能力变化
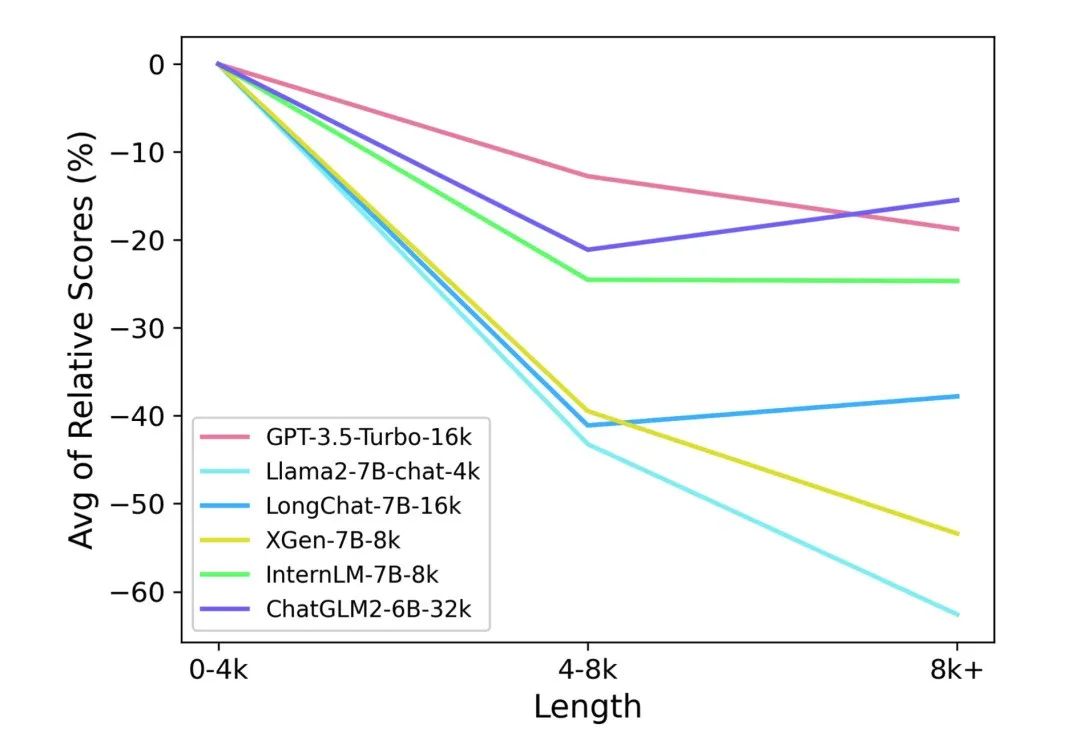
为了更有针对性地分析模型在不同文本长度下的相对表现,下图展示了模型在不同文本长度区间上,所有任务上的平均相对分数。
02
—
使用 LongBench
载入数据
通过Hugging Face datasets来下载并载入LongBench的数据:
from datasets import load_datasetdatasets = ["hotpotqa", "2wikimqa", "musique", "dureader", "narrativeqa", "qasper", "multifieldqa_en", \"multifieldqa_zh", "gov_report", "qmsum", "vcsum", "trec", "nq", "triviaqa", "lsht", "passage_count", \"passage_retrieval_en", "passage_retrieval_zh", "lcc", "repobench-p"]for dataset in datasets:data = load_dataset('THUDM/LongBench', dataset, split='test')
每个名称对应一个数据集,比如 “hotpotqa” 表示 HotpotQA 数据集,“2wikimqa” 表示 2WikiMQA 数据集,依此类推。
'THUDM/LongBench': 表示数据集所在的路径或名称。在这里,使用了 THUDM/LongBench 表示数据集来自 THUDM 团队的 LongBench 数据集。
split='test': 表示要加载的数据集的分割部分。在这里,使用了 'test' 表示加载测试集数据。
评测
官方提供了以 ChatGLM2-6B 为例提供了一份评测代码。
运行仓库下的pred.py
CUDA_VISIBLE_DEVICES=0 python pred.py在pred/文件夹下得到模型在所有数据集下的输出,此后运行eval.py的评测代码:
python eval.py在result.json中得到在各数据集上的评测结果。
官方的评测结果,朋友们可以自己实验一下。
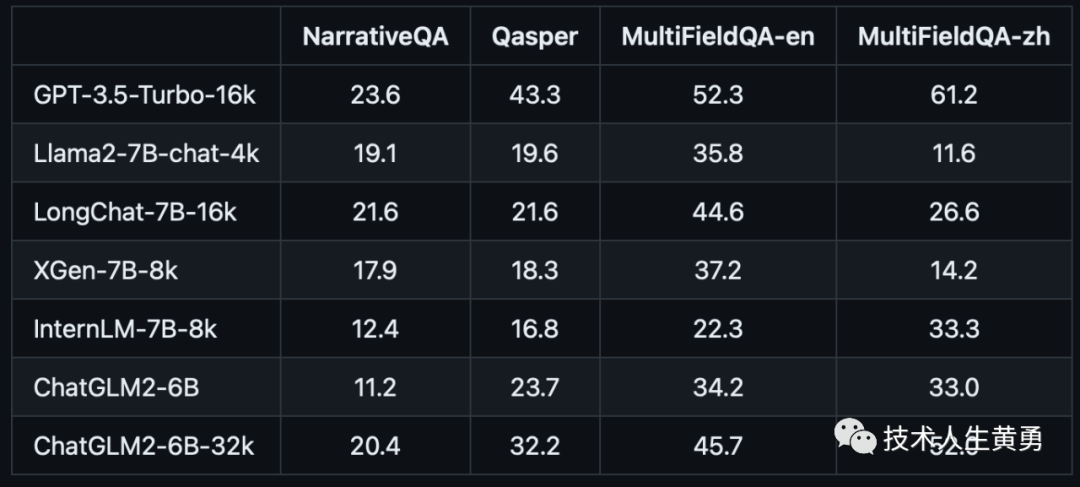
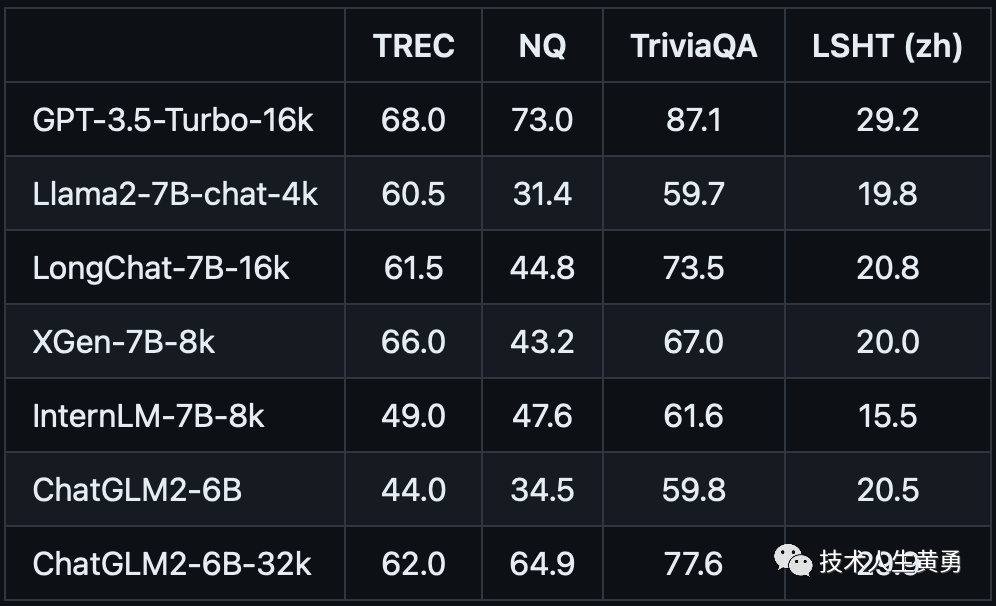
单文档QA
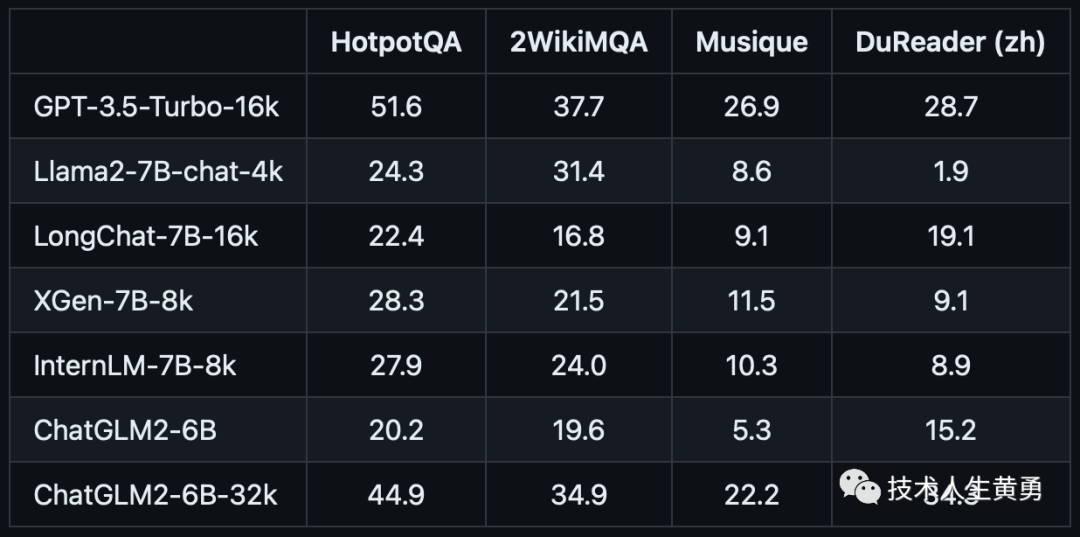
多文档QA
摘要
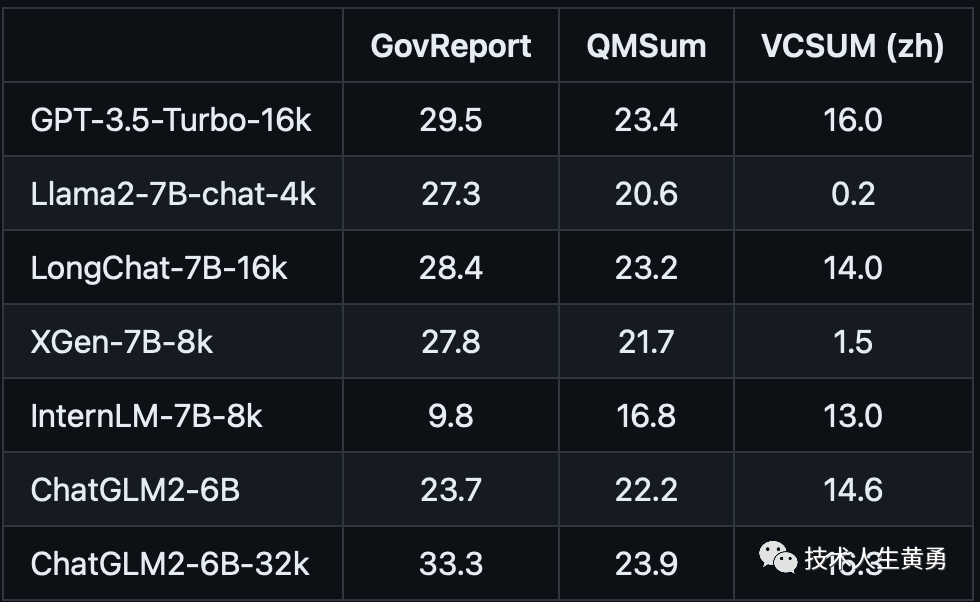
Few-shot学习
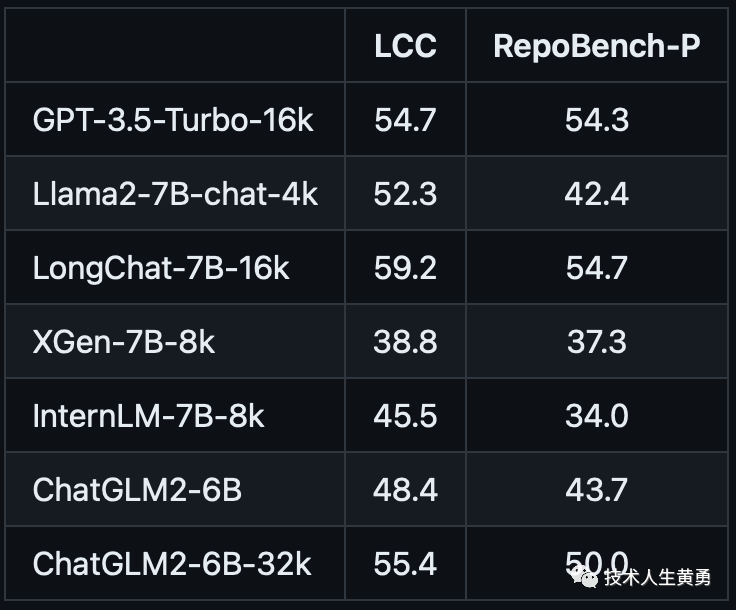
代码补全
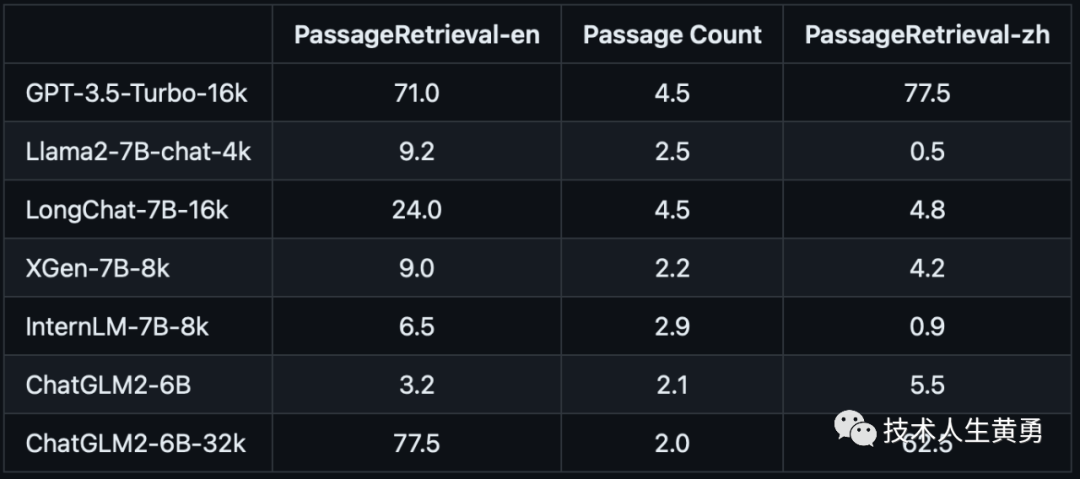
合成任务
这次更新的还有支持32k上下文的模型: ChatGLM-6B-32k。
手快的朋友已经下载了模型,并和自家兄弟 ChatGLM-6B 做了对比:给两个模型分别读了一篇万字文章。每个模型根据文章内容提出自己的问题并回答。剔除了引用无效资料和没有目标对象的问题后,下图是统计结果:
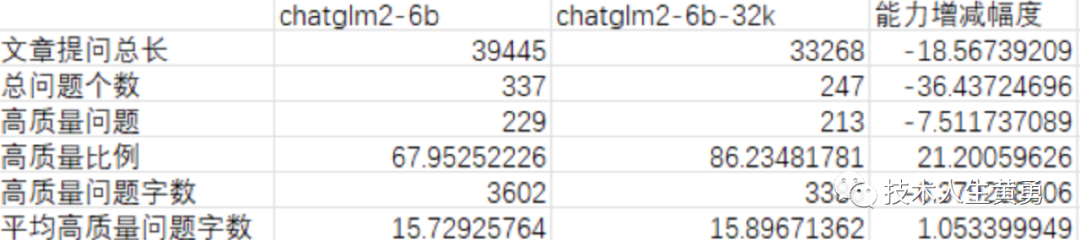
从单篇万字文章的统计结果看,ChatGLM-6B-32k 确实提高了知识库调用质量,避免了大量无效输出,可提高效率20%以上。
有朋友觉得大模型很笨,希望它能“一发话就知道怎么写”,但现实中的场景是多种多样的,变化无常。
从上面训练集的内容和评测就可以看出:只有训练集足够大,覆盖足够全,才可能部分满足这种需求,而且训练之后,对话中还需要有良好的提示词。
涉及到的数据集、模型地址
LongBench
Github:https://github.com/THUDM/LongBench
Huggingface:https://huggingface.co/datasets/THUDM/LongBench
ChatGLM2-6B-32k
https://huggingface.co/THUDM/chatglm2-6b-32k
评测数据地址:
https://huggingface.co/datasets/THUDM/LongBench/resolve/main/data.zip
往期热门文章推荐:
又一家顶级的大模型开源商用了!Meta(Facebook)的 Llama 2 搅动大模型混战的格局
教程|使用免费GPU 资源搭建专属知识库 ChatGLM2-6B + LangChain
工程落地实践|基于 ChatGLM2-6B + LangChain 搭建专属知识库初步完成
工程落地实践|国产大模型 ChatGLM2-6B 阿里云上部署成功
快捷部署清华大模型 ChatGLM2-6B,一键搞定 HuggingFace Space 空间
为什么对ChatGPT、ChatGLM这样的大语言模型说“你是某某领域专家”,它的回答会有效得多?(二)
拥抱未来,学习 AI 技能!关注我,免费领取 AI 学习资源。