集合
集合介绍
集合可以看作一个加强的数组,都是可以将同种类型的元素放到一个统一的位置。集合可分为单列集合和双列集合。
单列集合的总接口是:Collection,继承了Collection的接口是:List和Set,List中的元素可重复,Set中的元素不可重复。List有两个实现类:ArrayList和LinkedList。Set有两个实现类:HashSet和TreeSet。
双列集合的总接口是:Map,Map的两个实现类是:HashMap和TreeMap。
迭代器
Iterator
方法:
Iterator it = list.iterator();
it.hasNext();
it.next();
删除:
it.remove(); 用来删除该迭代器指向的元素。
获取迭代器对象,利用迭代器对象进行数据迭代,即数据遍历。
package day01;
import java.util.ArrayList;
import java.util.Collection;
import java.util.Iterator;
public class Demo01 {
public static void main(String[] args) {
Collection<String> coll = new ArrayList<>();
coll.add("1");
coll.add("2");
coll.add("3");
coll.add("4");
coll.add("5");
// 获取迭代器对象 Iterator.利用Iterator的对象方法,hasNext判断是否有下一个,
// 使用next取出下一个元素
Iterator<String> iter = coll.iterator();
while (iter.hasNext()) {
System.out.println(iter.next());
}
}
}
当使用next时,迭代器取出当前指向的元素,并指向下一个元素。
Set集合
概述:
Set集合特点:
可以去除重复
存取顺序不一致
没有带索引的办法,所以不能使用普通for循环遍历,也不能通过索引来获取,删除Set集合里面的元素。
Set集合练习
存储字符串并遍历。
set集合的基本使用。set集合中不可以重复,如果元素重复的话,只会保留其中的一个。
存取顺序不一致。Set没有索引,普通的for循环不能使用。
private static void demo02() {
Set<String> set = new HashSet<>();
set.add("Hello");
set.add("world");
set.add("Hello");
// 增强for循环
for (String s : set) {
System.out.println(s);
}
// 迭代器循环
Iterator<String> iterator = set.iterator();
while (iterator.hasNext()) {
System.out.println(iterator.next());
}
}
HashSet
底层使用哈希表
重写HashCode 和 equals方法。
TreeSet
TreeSet集合特点
不包含重复元素的集合
没有带索引的方法
可以将元素按照规则进行排序
底层使用红黑树
必须给定排序规则。
自然排序
自然排序要实现comparable接口,并重写其中的compareTo方法,this就是当前正要进行排序的对象,o就是已经在集合中的对象,如果返回值 < 0,就说明this应该在左边,否则应该在右边,如果是0说明对象重复,不做操作。
private static void demo04() {
Student s1 = new Student("陈歌", 18);
Student s2 = new Student("王文", 19);
Student s3 = new Student("双双", 18);
Student s4 = new Student("之言", 33);
TreeSet<Student> set = new TreeSet<>();
// 存入学生到TreeSet集合
set.add(s1);
set.add(s2);
set.add(s3);
set.add(s4);
for (Student s : set) {
System.out.print(s.getName() + " ");
System.out.println(s.getAge());
}
}
package day01;
//写一个学生类,并使用TreeSet集合来存储5个学生
//按照自定义的规则进行排序,自然排序
public class Student implements Comparable<Student> {
private String name;
private Integer age;
public Student(){
}
public Student(String name,Integer age){
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Integer getAge() {
return age;
}
public void setAge(Integer age) {
this.age = age;
}
@Override
public int compareTo(Student o) {
int result = this.getAge() - o.getAge();
result = result == 0 ? this.getName().compareTo(o.getName()) : result;
return result;
}
}
比较器排序
比较器排序不是写在类似于Student对象中的,而是写在集合中的,集合中的有参方法中可以写入一个比较器。通过重写比较方法。
private static void demo05() {
Teacher t1 = new Teacher("陈歌", 18);
Teacher t2 = new Teacher("犯花痴", 24);
Teacher t3 = new Teacher("风速", 20);
Teacher t4 = new Teacher("白色", 16);
TreeSet<Teacher> set = new TreeSet<>(new Comparator<Teacher>() {
@Override
public int compare(Teacher o1, Teacher o2) {
// 此时的o1就是即将进行排序的,o2是集合中已经排好序的。
int result = o1.getAge() - o2.getAge();
result = result == 0 ? o1.getName().compareTo(o2.getName()) : result;
return result;
}
});
set.add(t1);
set.add(t2);
set.add(t3);
set.add(t4);
for (Teacher t : set) {
System.out.print(t.getName() + " ");
System.out.println(t.getAge());
}
}
两种比较方式小结:
自然排序:自定义类实现Comparable接口,重写compareTo方法,根据返回值进行排序。
比较器排序:创建TreeSet的时候传递Compartor的比较器对象,重写compare方法,根据返回值进行排序。
返回值的规则:
如果返回值 < 0,表示当前存入值是较小值,存左边 。
= 0,当前存入值重复。
返回值是正数,当前存入值是较大值,存右边。
二叉树
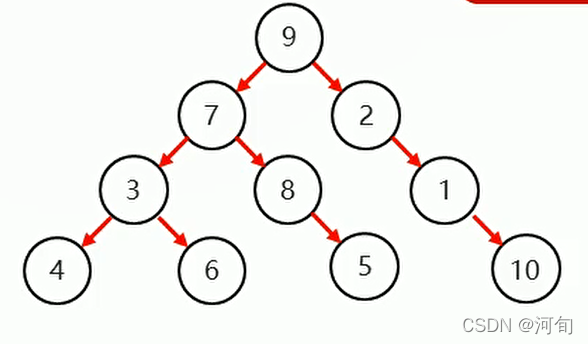
二叉查找树
不能保持平衡,不能保证性能。
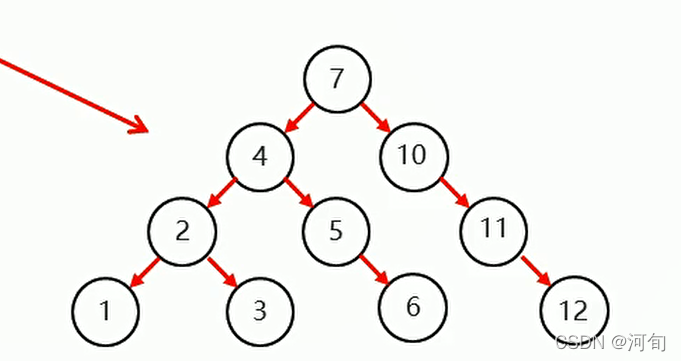
平衡二叉树
添加节点后,查看是否破坏二叉树的平衡,如果破环平衡,需要进行左旋或右旋重新保持平衡。
左旋
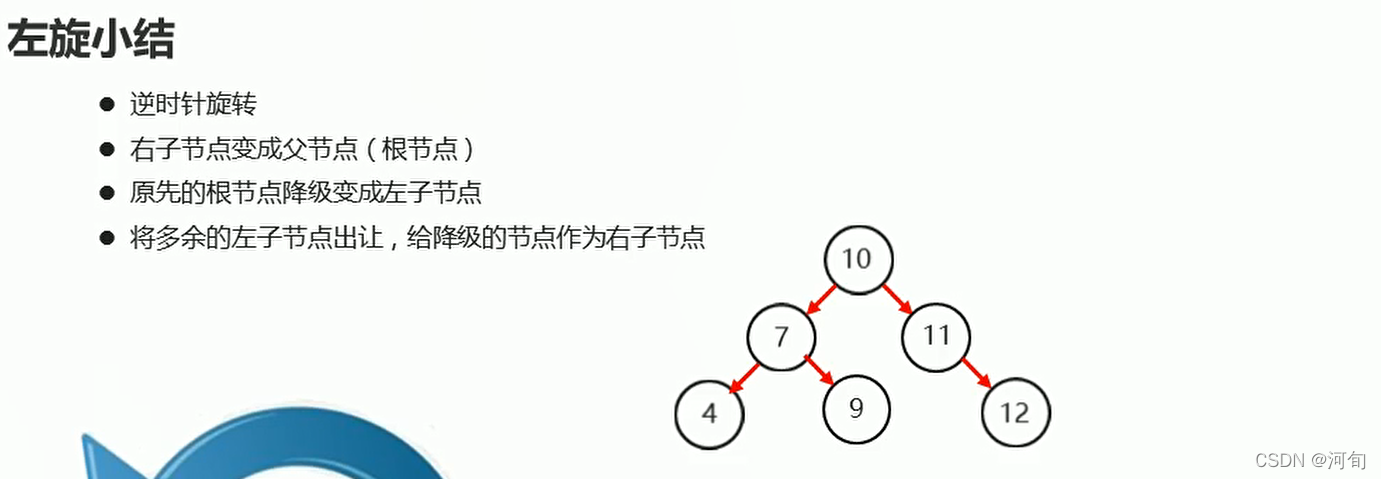
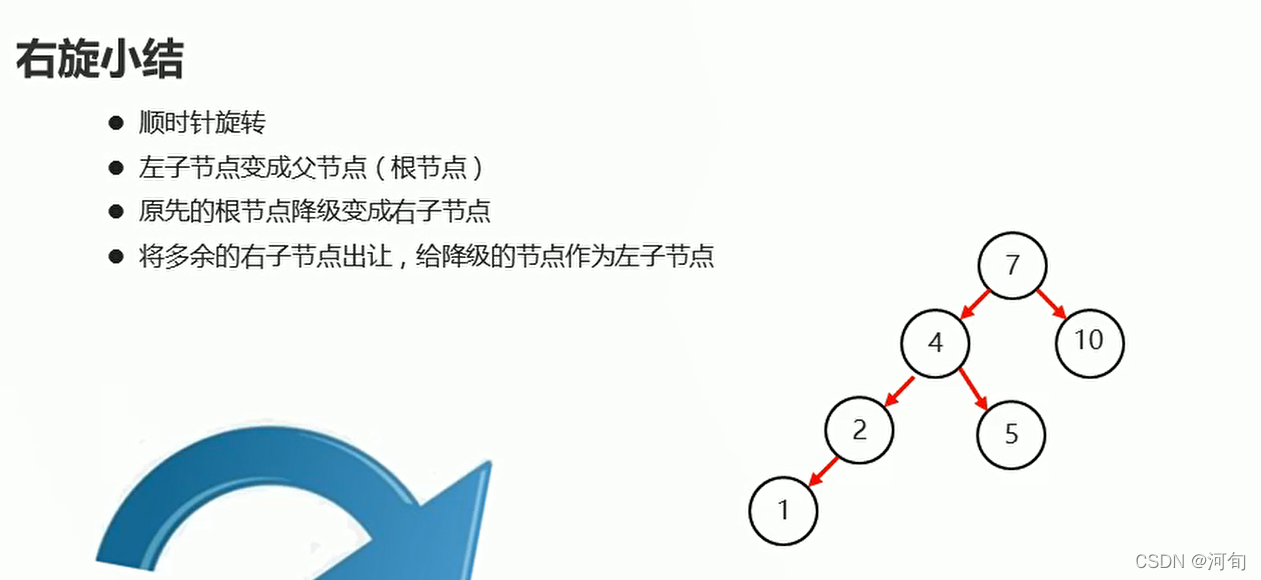
右旋
红黑树
TreeSet底层原理是红黑树。
红黑树不是高度平衡的,它的平衡是根据红黑规则进行实现的。
规则:
每个节点是红色或黑色,根节点必须是黑色。
每个叶节点是黑色的
不能出现两个红色节点相连。
对每一个节点,到其所有后代叶结点的简单路径上,均包含相同数目的黑色节点。

Map集合
interface Map<K,V> K:键的数据类型,V:值的数据类型。
键不能重复,值可以重复。
键值对又被称为 Entry对象。
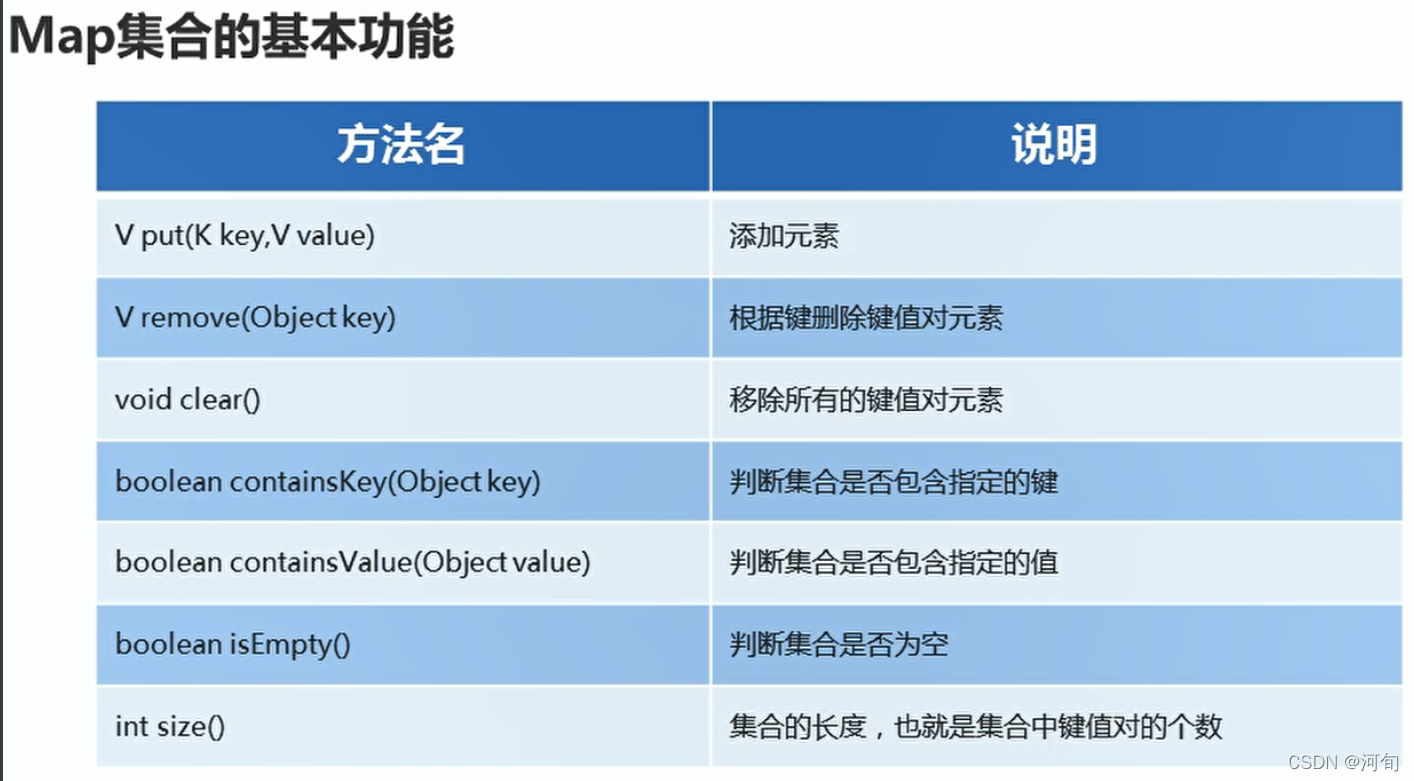
private static void demo06() {
// Map的使用
/*
put(K key,V value)
remove(Object key)
void clear()
boolean containsKey(Object key)
boolean isEmpty()
int size()
*/
Map<String, String> map = new HashMap<>();
map.put("1002", "王雯雯");
map.remove("1001");
map.clear();
map.put("1001", "赵新龙");
boolean flag = map.containsKey("1001");
System.out.println(flag);
System.out.println(map.size());
System.out.println(map);
}
遍历键值对
第一种方式:(根据所有的key获取value)
private static void demo06() {
Map<String, String> map = new HashMap<>();
map.put("itheima01", "a");
map.put("itheima02", "b");
map.put("itheima03", "c");
map.put("itheima04", "d");
map.put("itheima05", "e");
// 获取所有的键
Set<String> set = map.keySet();
for (String key : set) {
String value = map.get(key);
System.out.println(key + " : " + value);
}
}
第二种方式:获取每个键值对
// 获取所有的entry
Set<Map.Entry<String, String>> entries = map.entrySet();
for (Map.Entry<String,String> entry : entries){
System.out.println(entry.getKey() + " " + entry.getValue());
}