上文 探究Vue源码:mustache模板引擎(7) 手写模板字符串转换tokens数组过程中 我们操作出了一个较为简单的 tokens数组 并简单处理了 井号反斜杠的特殊符号语法
那么 我们现在需要将零散的tokens嵌套起来
主要就体现在 我们 井号 到 反斜杠 中间的内容 显然是属于循环语句中的子集
但我们现在是一个平级的关系

而 这个东西主要麻烦在 内部是可能存在多层嵌套的
例如 我们循环中 再循环
处理它 就会形成一个一层一层的数据结构 那么 很多人会想到 栈
那么 这又是一个 很多人听过 但没有深入了解到的知识点
我们先来讲 栈 的概念
首先 这是一个堆叠结果 生活中也比较常见 例如 我们的羽毛球桶
他只有一头是开口的
我们想放球进去 只能一个叠一个的放进去

而这个结构 你往出拿时 肯定是拿最后放的
你如 你放进去 顺序是 abcd 那么 他堆叠的结构 由上至下 是 dcba
那么 你往出拿 自然也是这个顺序
简单说 就叫 先进后出
那么 概念就是 遇见 井号 进栈 遇到反斜杠 则出栈
那么 有了思路 我们就打开项目
在src下创建一个 nestTokens.js
先将代码写成这样
/*
整合tokens 将#与/ 之前的内容 整合为 下标为三的元素
*/
export default function nestTokens(tokens) {
};
我们这个文件只抛出一个函数 函数用来处理tokens
将 井号下的内容 到反斜杠之前的内容 整合成 下标为三的数组
然后 我们打开 formConversToken.js 引入并使用这个nestTokens
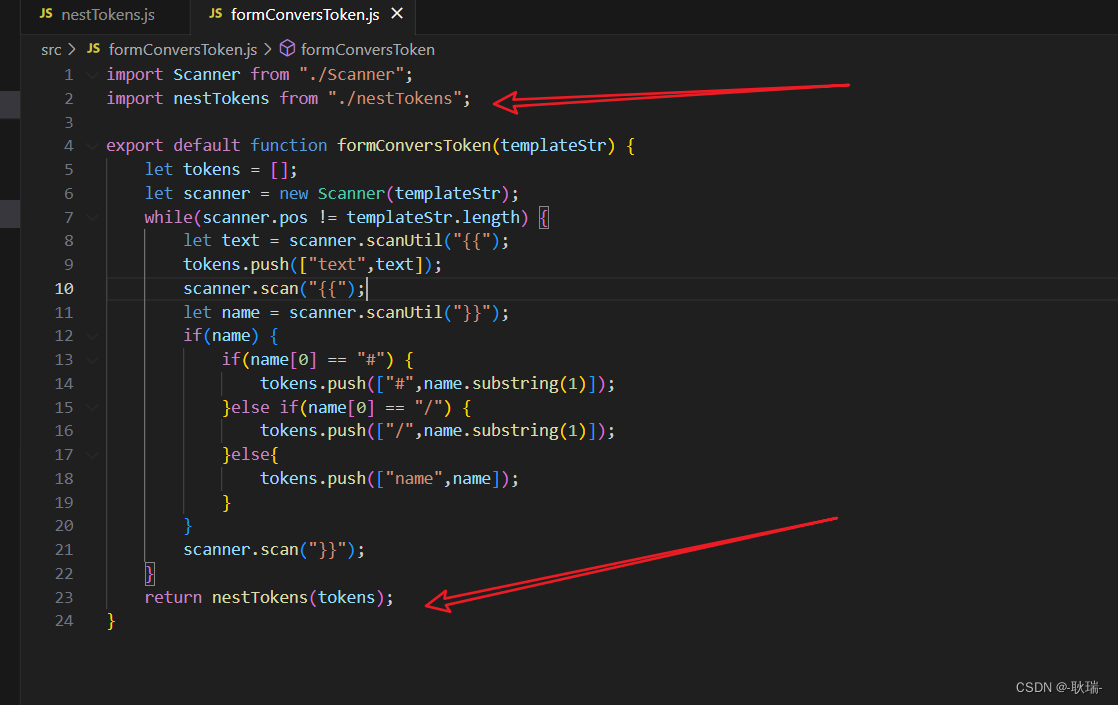
上面引入一下这个处理tokens的函数
然后返回时 顺带放到函数中让他处理一下这个数据
但 这样 原本有点 tokens 现在就成了 undefined
 、
、
因为我们nestTokens还没写东西 他没有返回值 那我们这样套 自然是没有东西的
那么 这里 我们先改成 nestTokens 直接将接到的返回回去
我们的tokens 就又出来了
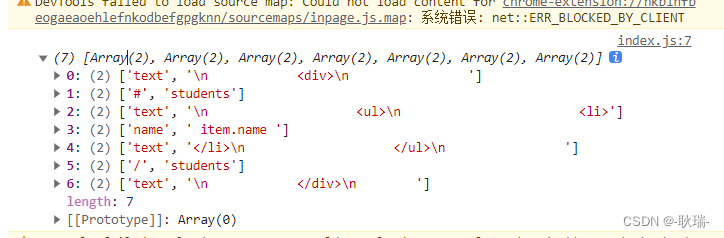
然后 接下来就要开始写算法了 当然 任何算法 只要滤清思路 都不会难
重要的是 理解 我们要做什么 然后 我们用什么样的方式去实现
我们先将nestTokens函数改成这样
/*
整合tokens 将#与/ 之前的内容 整合为 下标为三的元素
*/
export default function nestTokens(tokens) {
//先定义一个数组 存储放回结果
let nestedTokens = [];
//做一个数组 来存栈中数据
let sections = [];
//循环遍历外面传进来的tokens
for(let i = 0;i < tokens.length;i++) {
//定义一个叫token的变量存储 当前循环遍历的下标
let token = tokens[i];
//判断下一当前循环的下标数组 第一个下标是不是 井号 或者 反斜杠 如果都不是 做另外处理
switch(token[0]) {
case '#':
//如果是井号
sections.push(token);
console.log(token[1],"入栈啦");
break;
case '/':
//如果是反斜杠
let pot = sections.pop();
console.log(pot[1],"出栈啦");
break;
default:
//既不是井号 又不是反斜杠
}
}
return nestedTokens;
};
我们先进来定义一个nestedTokens 用来存储最后返回的结果
然后 定义sections数组 来处理我们入栈和出栈的逻辑
然后 循环遍历传进来的tokens数组
然后 定义一个 token 来存储当前循环遍历的下标内容
如果第 0 下标是 井号 说明 这是 我们要入栈
用push加内容加进来
如果是反斜杠 则 用pop 这个方法大家可以了解一下 删除数组最后一个下标 并将删除的内容返回回来
然后 我们接收返回值 输出一下
运行结果如下
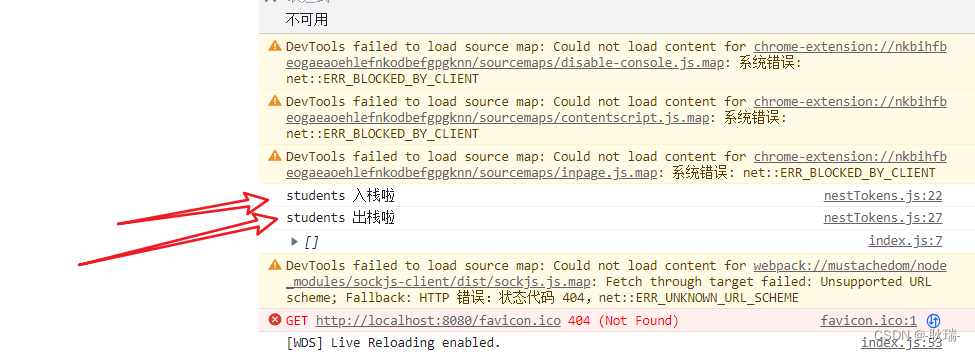
匹配到了井号之后 将内容通过push加进数组
然后匹配到反斜杠 通过pop将数组最后一个下标干掉
因为我们nestedTokens没有做任何处理 返回值自然就是个空数组
然后 我们就可以进而将代码改成这样
/*
整合tokens 将#与/ 之前的内容 整合为 下标为三的元素
*/
export default function nestTokens(tokens) {
//先定义一个数组 存储放回结果
let nestedTokens = [];
//做一个数组 来存栈中数据
let sections = [];
//循环遍历外面传进来的tokens
for(let i = 0;i < tokens.length;i++) {
//定义一个叫token的变量存储 当前循环遍历的下标
let token = tokens[i];
//判断下一当前循环的下标数组 第一个下标是不是 井号 或者 反斜杠 如果都不是 做另外处理
switch(token[0]) {
case '#':
//将当前遍历的元素的第二个下标定义为一个空数组 以便收集井号内的子元素
token[2] = [];
//如果是井号
sections.push(token);
break;
case '/':
//如果是反斜杠
let pot = sections.pop();
//将被删除的栈内容 加入到nestedTokens中
nestedTokens.push(pot);
break;
default:
//既不是井号 又不是反斜杠
//判断sections储存栈内容数组 是否是空的
if(sections.length == 0) {
//直接将当前下标装入结果数组
nestedTokens.push(token);
} else {
//走进else 说明 sections 中是有内容的 当前正在入栈
//将当前遍历的下标内容 push进sections最后一个元素的 2下标下
sections[sections.length - 1][2].push(token);
}
}
}
return nestedTokens;
};
重点改动的是 default 当前遍历的下标 数组0下标 既不是 井号 又不是反斜杠 那么 我们就判断 sections中有没有内容 因为 sections 有内容 则表示 当前是循环在收集元素
如果sections是空的 说明 当前这块内容 没有被包裹在 井号和反斜杠内 直接可以加入到nestedTokens 成为第一级的数据
否则 直接将当前这个 push进sections最后一个下标的 数组的 2下标下 我们之前case ‘#’:中写到过 如果是井号 直接创建出一个 2下标 默认值是一个空数组 这里 则是将内容push进这个空数组
然后 另一个改的就是 出栈 case ‘/’:
在出栈时 将sections 通过 push 加入到nestedTokens 结果数组中
运行结果如下
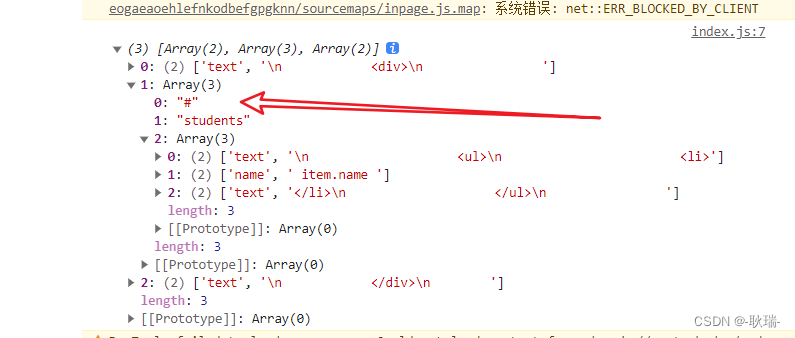
可以看到 我们数组中内容 很成功的收集到了 井号和反斜杠中间的内容
但是 这样还有点问题
我们将 www下的 index.html 改成这样
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
</head>
<body>
<script src = "/xuni/bundle.js"></script>
<script>
let templateStr = `
<div>
{
{#students}}
<ul>
<li>{
{ item.name }}</li>
{
{#item.list}}
<li>{
{ . }}</li>
{
{/item.list}}
</ul>
{
{/students}}
</div>
`;
let data = {
name: "小猫猫",
age: 2,
students: [
{
id: 0,
name: "小明",
list: [
"篮球",
"唱",
"跳"
]
},
{
id: 1,
name: "小红",
list: [
"电子游戏",
"计算机编程"
]
}
]
}
GrManagData.render(templateStr,data);
</script>
</body>
</html>
这里 我们改成了两层嵌套 students先循环 然后 在里面有写了 循环对应下标下的list数组
但是 我们运行结果如下
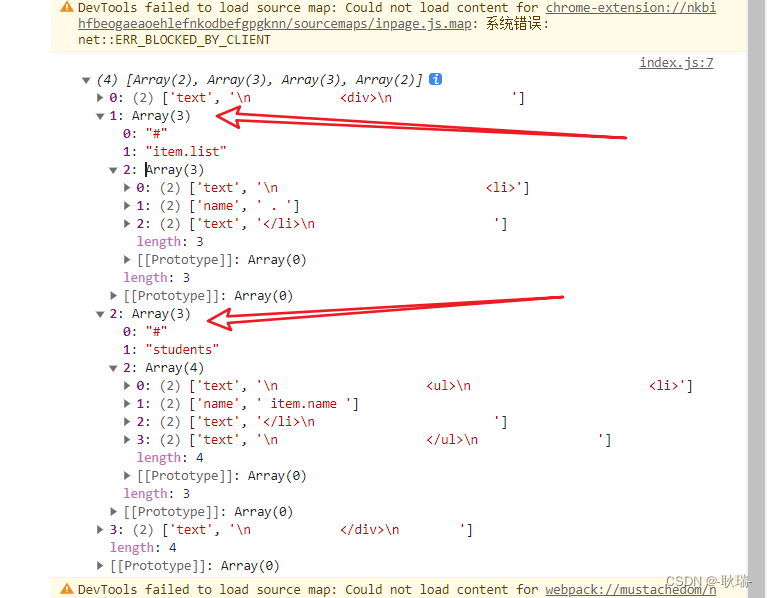
很明显 两个 井号变成了平级的结构 但是 显然 item.list 应该是 students的子集
我们可以看mustache.js官方的写法 在 mustache.js 中搜索nestTokens 就是如下的一个函数内容
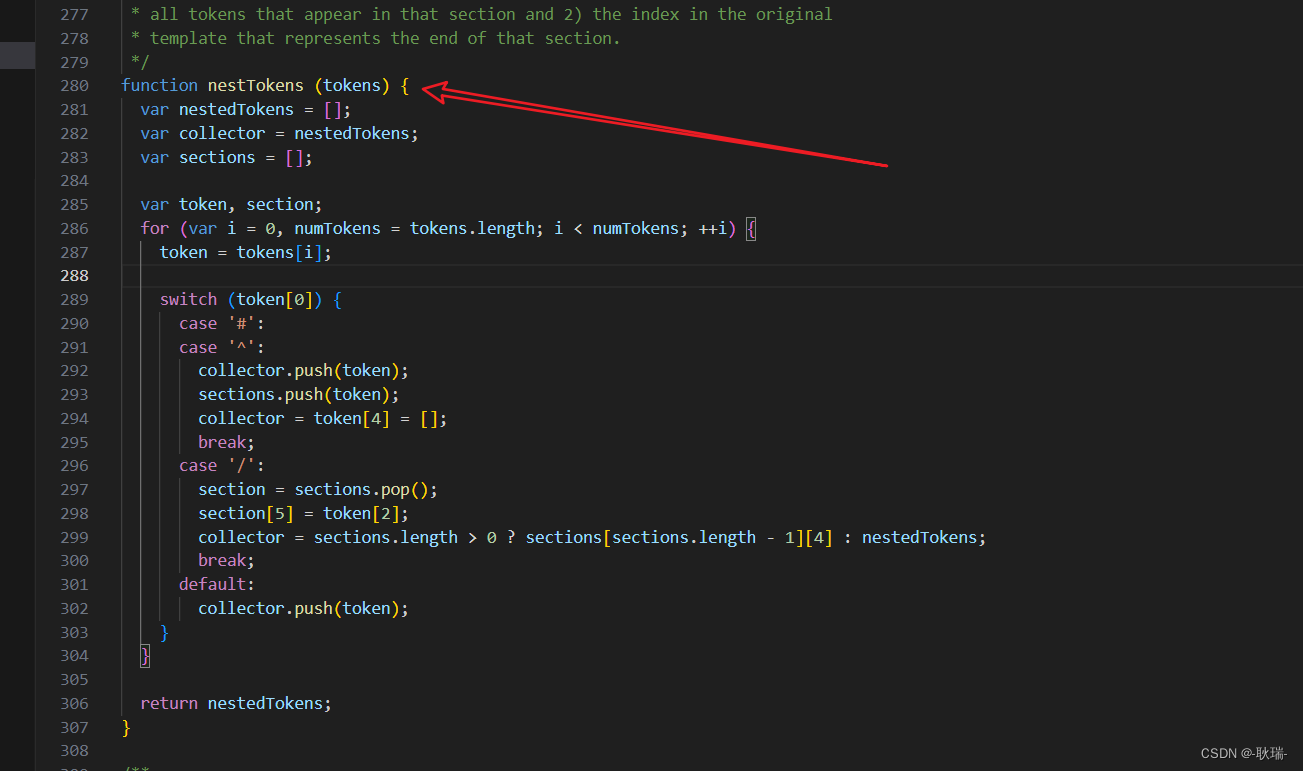
首先 这句话 利用了 js中浅拷贝的语法 大家可以去了解一下深拷贝和浅拷贝概念 这里 我们就是利用了引用类型的 直接等于
这样就相当于 collector和nestedTokens 指向的都是同一个存储空间
也可以理解为 这两个变量都指向同一个数组
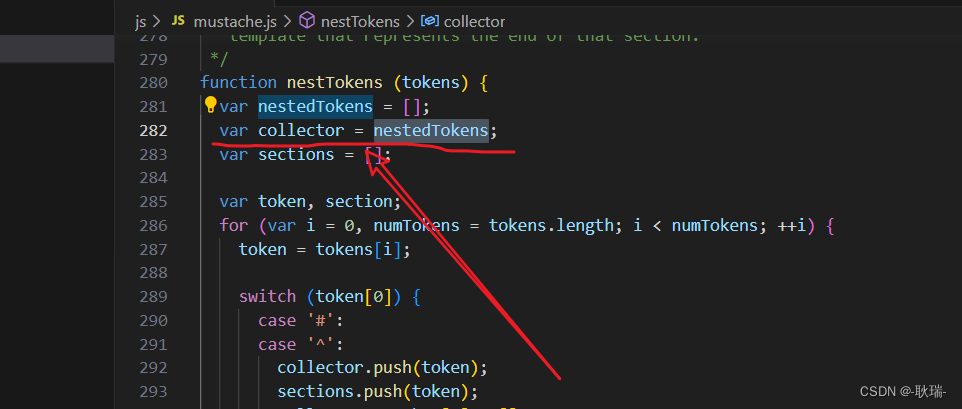
但是 我们会发现 其实这个方法还是不太一样的 但是 思路上 差的不是特别大
其实在用我们这个研究研究 也能解决这个问题
我只是带着大家自己写一下 那么 我们这个 循环语句直接重写 还是按官方的方案来
这里 直接将我们的 nestTokens 改成这样
/*
整合tokens 将#与/ 之前的内容 整合为 下标为三的元素
*/
export default function nestTokens(tokens) {
//先定义一个数组 存储放回结果
let nestedTokens = [];
//做一个数组 来存栈中数据
let sections = [];
//创建 collector 收集器 直接指向 nestedTokens 结果数组
let collector = nestedTokens;
//循环遍历外面传进来的tokens
for(let i = 0;i < tokens.length;i++) {
//定义一个叫token的变量存储 当前循环遍历的下标
let token = tokens[i];
//判断下一当前循环的下标数组 第一个下标是不是 井号 或者 反斜杠 如果都不是 做另外处理
switch(token[0]) {
case '#':
//如果是井号
//将当前元素 存入collector收集器
collector.push(token);
//当前元素入栈
sections.push(token);
//直接在用等于 让收集器collector指向 当前元素的2下标 顺手token[2] = []; 就是给token定义 2下标 默认值一个空数组
collector = token[2] = [];
break;
case '/':
//如果是反斜杠 出栈
let pot = sections.pop();
//判断 如果sections是空的 则等于nestedTokens结果数组 如果不是 就等于 sections最后一个下标的二下标
collector = sections.length > 0?sections[sections.length - 1][2]:nestedTokens;
break;
default:
//直接将内容放入收起器中
collector.push(token);
}
}
return nestedTokens;
};
这个函数 很巧妙的利用了js浅拷贝 数组等引用类型可以直接利用 等于来改变指向的原理
很多人可能因为浅拷贝给代码带来BUG 但这里 就是对浅拷贝作用很好的一个利用
首先 collector最开始指向的 nestedTokens 就是我们结果数组
然后 每次collector.push 都会存入nestedTokens
当遇到井号之后呢 每次 就会 collector.push 进到 最近 一次入栈的 元素的 2下标中
然后 出栈时 这个判断比较精髓
如果sections通过 pop 干掉最后一个元素之后 还有元素
那么说明 他之前还匹配过其他 井号 说明 我们这个循环是在其他循环中编写的
就直接继续等于上一个入栈的 元素的 2下标
如果没了 表示 到最后了 就重新指回 nestedTokens
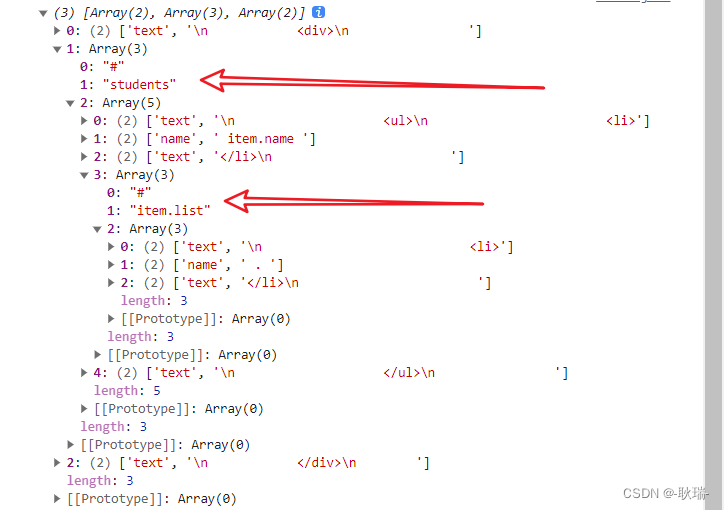
可以看到 这个结果就非常的完美 这个算法可以说非常的巧妙 尤其是对 浅拷贝的精准应用
真的希望 大家如果学一款框架 重点记API 如果学原理 例如这些算法 还是要理解 然后延伸出更多场景用法
我说实话这东西如果死记硬背 那真的不如不要浪费时间 真的没用