目录
软硬件环境:
OS: Ubuntu 20.04
CPU: AMD5800
GPU: 2*RTX3060
Ubuntu-driver: 515
CUDA driver: 11.2
一. 双卡并行环境配置
下载nccl: https://developer.nvidia.com/nccl/nccl-legacy-downloads
选择对应的操作系统和CUDA版本(这里选择离线安装):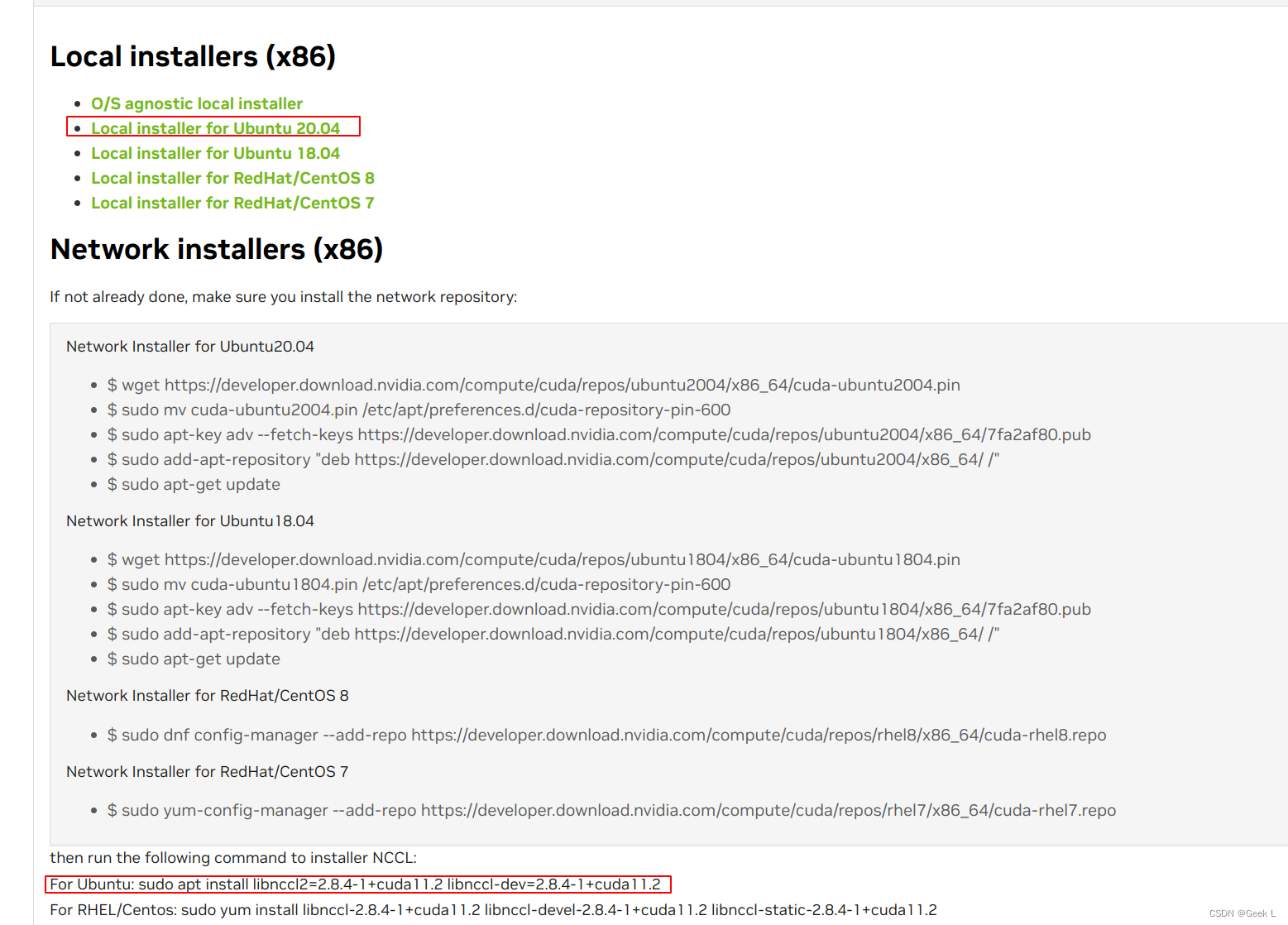
下载好后进行离线安装:
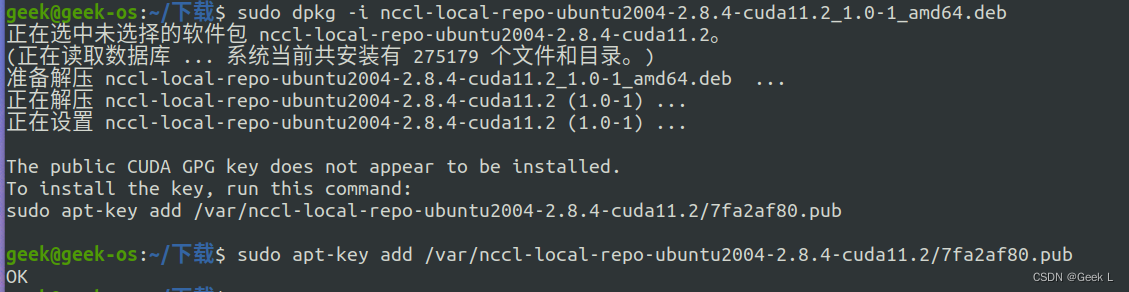
sudo dpkg -i nccl-local-repo-ubuntu2004-2.8.4-cuda11.2_1.0-1_amd64.deb
接下来提示需要安装一个CUDA GPG公钥,必须先安装公钥才能进行接下来的操作.
安装公钥:
sudo apt-key add /var/nccl-local-repo-ubuntu2004-2.8.4-cuda11.2/7fa2af80.pub
更新软件源:
sudo gedit /etc/apt/sources.list
清华源最好用:
deb http://mirrors.tuna.tsinghua.edu.cn/ubuntu/ xenial main multiverse restricted universe
deb http://mirrors.tuna.tsinghua.edu.cn/ubuntu/ xenial-backports main multiverse restricted universe
deb http://mirrors.tuna.tsinghua.edu.cn/ubuntu/ xenial-proposed main multiverse restricted universe
deb http://mirrors.tuna.tsinghua.edu.cn/ubuntu/ xenial-security main multiverse restricted universe
deb http://mirrors.tuna.tsinghua.edu.cn/ubuntu/ xenial-updates main multiverse restricted universe
deb-src http://mirrors.tuna.tsinghua.edu.cn/ubuntu/ xenial main multiverse restricted universe
deb-src http://mirrors.tuna.tsinghua.edu.cn/ubuntu/ xenial-backports main multiverse restricted universe
deb-src http://mirrors.tuna.tsinghua.edu.cn/ubuntu/ xenial-proposed main multiverse restricted universe
deb-src http://mirrors.tuna.tsinghua.edu.cn/ubuntu/ xenial-security main multiverse restricted universe
deb-src http://mirrors.tuna.tsinghua.edu.cn/ubuntu/ xenial-updates main multiverse restricted universe
然后更新:
sudo apt update
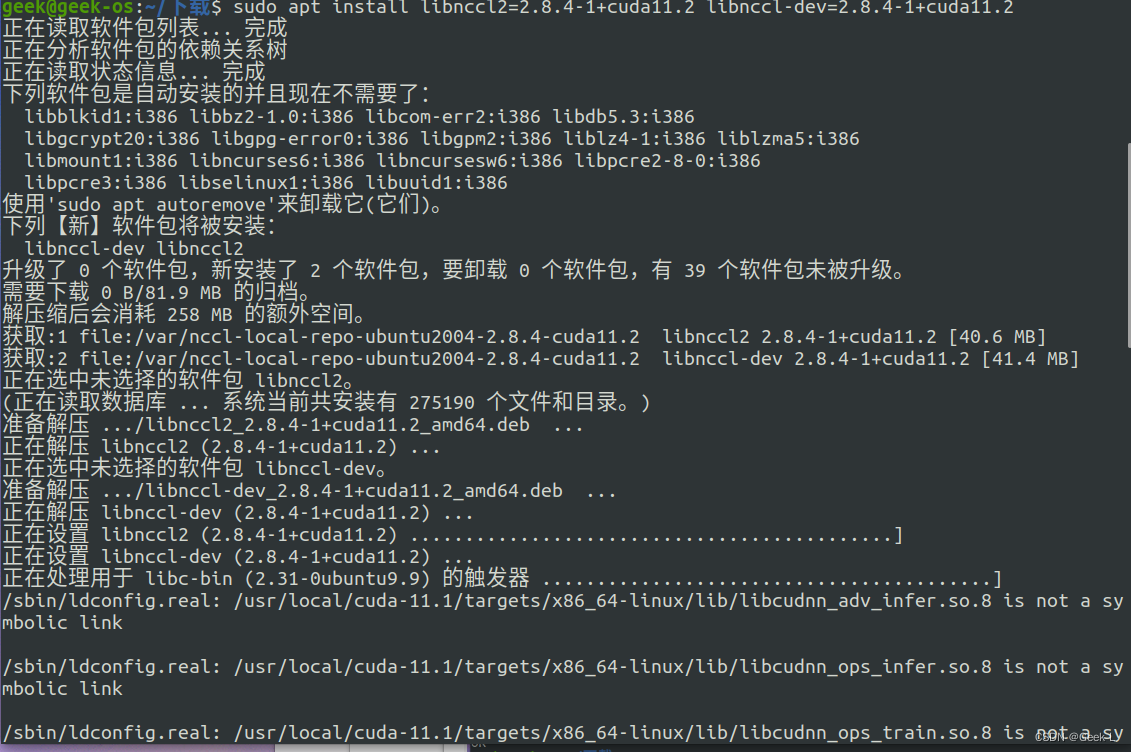
安装nccl:
sudo apt install libnccl2=2.8.4-1+cuda11.2 libnccl-dev=2.8.4-1+cuda11.2
将nccl添加到环境变量中:
nccl默认的安装目录是/usr/lib/x86_64-linux-gnu ,修改~/.bashrc文件,添加如下内容到文件中:
sudo gedit ~/.bashrc
#设置cuda库的目录
export LD_LIBRARY_PATH=/usr/local/cuda-10.0/lib64
#将nccl添加到LD_LIBRARY_PATH中
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/lib/x86_64-linux-gnu
添加好之后保存文件,使用source ~/.bashrc让文件的配置生效,在通过echo $LD_LIBRARY_PATH查看环境变量设置是否成功,配置成功之后输出的信息如下:

扫描二维码关注公众号,回复:
15859886 查看本文章

二. 验证单机多卡
2.1 paddle
python
import paddle
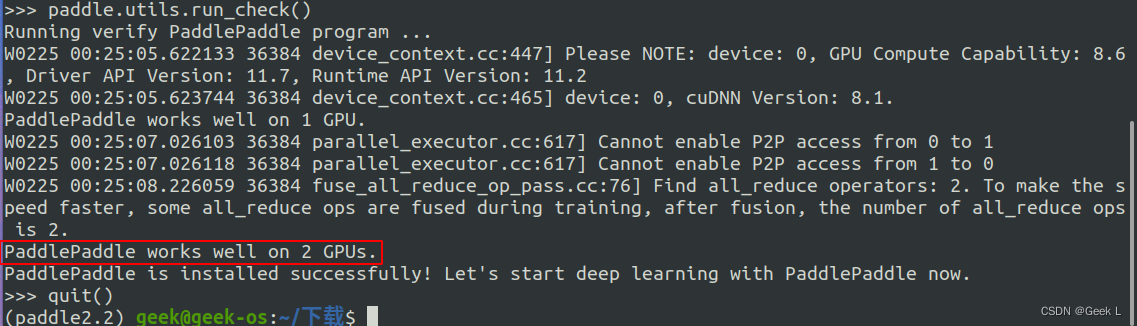
paddle.utils.run_check()
若输出为以下则正确:
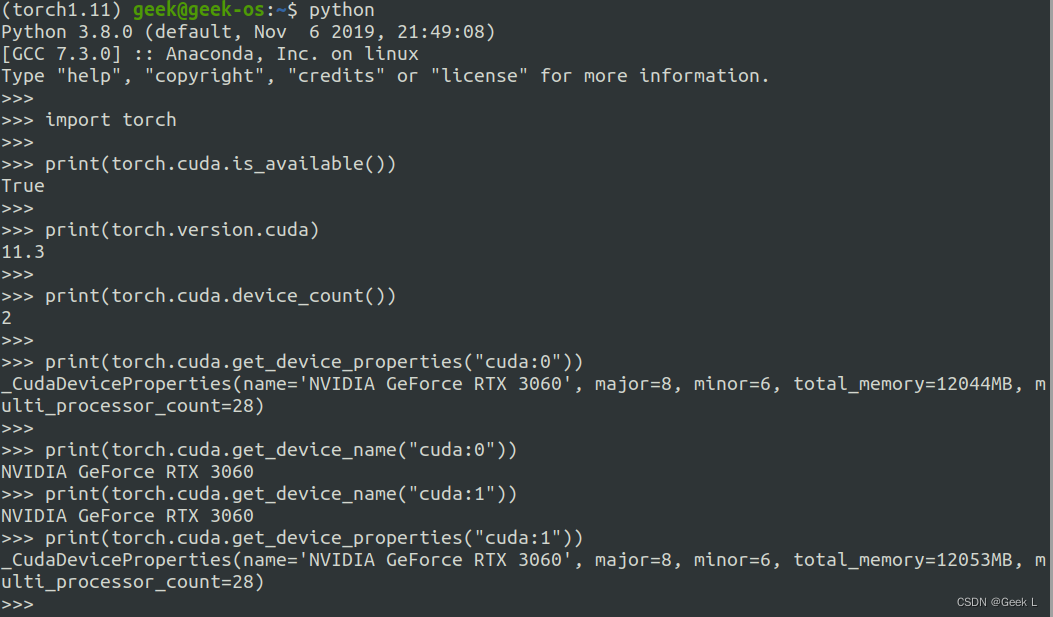
2.2 pytorch
python
import torch
print(torch.cuda.is_available())
print(torch.cuda.device_count())
print(torch.cuda.get_device_name("cuda:0"))
print(torch.cuda.get_device_properties("cuda:0"))
三. 单机多卡训练模板
3.1 pytorch
训练命令:
CUDA_VISIBLE_DEVICES=0,1 python -m torch.distributed.launch --nproc_per_node=2 train.py --use_mix_precision
from datetime import datetime
import argparse
import torchvision
import torchvision.transforms as transforms
import torch
import torch.nn as nn
import torch.distributed as dist
from tqdm import tqdm
from torch.cuda.amp import GradScaler
# 使用CUDA_VISIBLE_DEVICES指定gpu --nproc_per_node=2 用2卡
# CUDA_VISIBLE_DEVICES=0,1 python -m torch.distributed.launch --nproc_per_node=2 train.py --use_mix_precision
# import os
# os.environ['MASTER_ADDR'] = 'localhost'
# os.environ['MASTER_PORT'] = '12345'
class ConvNet(nn.Module):
def __init__(self, num_classes=10):
super(ConvNet, self).__init__()
self.layer1 = nn.Sequential(
nn.Conv2d(1, 16, kernel_size=5, stride=1, padding=2),
nn.BatchNorm2d(16),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2))
self.layer2 = nn.Sequential(
nn.Conv2d(16, 32, kernel_size=5, stride=1, padding=2),
nn.BatchNorm2d(32),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2))
self.fc = nn.Linear(7*7*32, num_classes)
def forward(self, x):
out = self.layer1(x)
out = self.layer2(out)
out = out.reshape(out.size(0), -1)
out = self.fc(out)
return out
#################################### N11 ##################################
def evaluate(model, gpu, test_loader, rank):
model.eval()
size = torch.tensor(0.).to(gpu)
correct = torch.tensor(0.).to(gpu)
with torch.no_grad():
for i, (images, labels) in enumerate(tqdm(test_loader)):
images = images.to(gpu)
labels = labels.to(gpu)
# Forward pass
outputs = model(images)
size += images.shape[0]
correct += (outputs.argmax(1) == labels).type(torch.float).sum()
# 群体通信 reduce 操作 change to allreduce if Gloo
dist.reduce(size, 0, op=dist.ReduceOp.SUM)
# 群体通信 reduce 操作 change to allreduce if Gloo
dist.reduce(correct, 0, op=dist.ReduceOp.SUM)
if rank == 0:
print('Evaluate accuracy is {:.2f}'.format(correct / size))
#################################################################################
def train(gpu, args):
##################################################################
# 训练函数中仅需要更改初始化方式即可。在ENV中只需要指定init_method='env://'。
# TCP所需的关键参数模型会从环境变量中自动获取,环境变量可以在程序外部启动时设定,参考启动方式。
# 当前进程的rank值可以通过dist.get_rank()得到
dist.init_process_group(backend='nccl', init_method='env://') #
args.rank = dist.get_rank() #
##################################################################
model = ConvNet()
model.cuda(gpu)
# define loss function (criterion) and optimizer
criterion = nn.CrossEntropyLoss().to(gpu)
optimizer = torch.optim.SGD(model.parameters(), 1e-4)
####################################### N2 ########################
# 并行环境下,对于用到BN层的模型需要转换为同步BN层;
# 用DistributedDataParallel将模型封装为一个DDP模型,并复制到指定的GPU上。
# 封装时不需要更改模型内部的代码;设置混合精度中的scaler,通过设置enabled参数控制是否生效。
model = nn.SyncBatchNorm.convert_sync_batchnorm(model) #
model = nn.parallel.DistributedDataParallel(model, device_ids=[gpu]) #
scaler = GradScaler(enabled=args.use_mix_precision) #
#########################################################################
# Data loading code
train_dataset = torchvision.datasets.MNIST(root='./datasets',
train=True,
transform=transforms.ToTensor(),
download=True)
#################################### N3 #######################################
# DDP要求定义distributed.DistributedSampler,通过封装train_dataset实现;在建立DataLoader时指定sampler。
# 此外还要注意:shuffle=False。DDP的数据打乱需要通过设置sampler,参考N4。
train_sampler = torch.utils.data.distributed.DistributedSampler(train_dataset) #
train_loader = torch.utils.data.DataLoader(dataset=train_dataset, #
batch_size=args.batch_size, #
shuffle=False, #
num_workers=0, #
pin_memory=True, #
sampler=train_sampler) #
#####################################################################################
#################################### N9 ###################################
test_dataset = torchvision.datasets.MNIST(root='./datasets', #
train=False, #
transform=transforms.ToTensor(), #
download=True) #
test_sampler = torch.utils.data.distributed.DistributedSampler(test_dataset) #
test_loader = torch.utils.data.DataLoader(dataset=test_dataset, #
batch_size=args.batch_size, #
shuffle=False, #
num_workers=0, #
pin_memory=True, #
sampler=test_sampler) #
#################################################################################
start = datetime.now()
total_step = len(train_loader)
for epoch in range(args.epochs):
################ N4 ################
# 在每个epoch开始前打乱数据顺序。(注意total_step已经变为orignal_length // args.world_size。)
train_loader.sampler.set_epoch(epoch) #
##########################################
model.train()
for i, (images, labels) in enumerate(tqdm(train_loader)):
images = images.to(gpu)
labels = labels.to(gpu)
# Forward pass
######################## N5 ################################
# 利用torch.cuda.amp.autocast控制前向过程中是否使用半精度计算。
with torch.cuda.amp.autocast(enabled=args.use_mix_precision): #
outputs = model(images) #
loss = criterion(outputs, labels) #
##################################################################
# Backward and optimize
optimizer.zero_grad()
############## N6 ##########
# 当使用混合精度时,scaler会缩放loss来避免由于精度变化导致梯度为0的情况。
scaler.scale(loss).backward() #
scaler.step(optimizer) #
scaler.update() #
##################################
################ N7 ####################
# 为了避免log信息的重复打印,可以只允许rank0号进程打印。
if (i + 1) % 100 == 0 and args.rank == 0: #
##############################################
print('Epoch [{}/{}], Step [{}/{}], Loss: {:.4f}'.format(epoch + 1, args.epochs, i + 1, total_step,
loss.item()))
########### N8 ############
# 清理进程
dist.destroy_process_group() #
if args.rank == 0: #
#################################
print("Training complete in: " + str(datetime.now() - start))
def parse_args():
parser = argparse.ArgumentParser()
parser.add_argument('-g', '--gpuid', default=0, type=int,
help="which gpu to use")
parser.add_argument('-e', '--epochs', default=2, type=int,
metavar='N',
help='number of total epochs to run')
parser.add_argument('-b', '--batch_size', default=4, type=int,
metavar='N',
help='number of batchsize')
##################################################################################
# 这里指的是当前进程在当前机器中的序号,注意和在全部进程中序号的区别,即指的是GPU序号0,1,2,3。
# 在ENV模式中,这个参数是必须的,由启动脚本自动划分,不需要手动指定。要善用local_rank来分配GPU_ID。
# 不需要填写,脚本自动划分
parser.add_argument("--local_rank", type=int, #
help='rank in current node') #
# 是否使用混合精度
parser.add_argument('--use_mix_precision', default=False, #
action='store_true', help="whether to use mix precision") #
# Need 每台机器使用几个进程,即使用几个gpu 双卡2,
parser.add_argument("--nproc_per_node", type=int, #
help='numbers of gpus') #
# 分布式训练使用几台机器,设置默认1,单机多卡训练
parser.add_argument("--nnodes", type=int, default=1, help='numbers of machines')
# 分布式训练使用的当前机器序号,设置默认0,单机多卡训练只能设置为0
parser.add_argument("--node_rank", type=int, default=0, help='rank of machines')
# 分布式训练使用的0号机器的ip,单机多卡训练设置为默认本机ip
parser.add_argument("--master_addr", type=str, default="127.0.0.1",
help='ip address of machine 0')
##################################################################################
args = parser.parse_args()
#################################
# train(args.local_rank, args):一般情况下保持local_rank与进程所用GPU_ID一致。
print("----------")
print(args.local_rank)
print(args.batch_size)
print("------------")
return args
# exit()
#
#################################
if __name__ == '__main__':
args = parse_args()
train(args.local_rank, args)
from datetime import datetime
import argparse
import torchvision
import torchvision.transforms as transforms
import torch
import torch.nn as nn
import torch.distributed as dist
from tqdm import tqdm
from torch.cuda.amp import GradScaler
# 使用CUDA_VISIBLE_DEVICES指定gpu --nproc_per_node=2 用2卡
# CUDA_VISIBLE_DEVICES=0,1 python -m torch.distributed.launch --nproc_per_node=2 train.py --use_mix_precision
class ConvNet(nn.Module):
def __init__(self, num_classes=10):
super(ConvNet, self).__init__()
self.layer1 = nn.Sequential(
nn.Conv2d(1, 16, kernel_size=5, stride=1, padding=2),
nn.BatchNorm2d(16),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2))
self.layer2 = nn.Sequential(
nn.Conv2d(16, 32, kernel_size=5, stride=1, padding=2),
nn.BatchNorm2d(32),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2))
self.fc = nn.Linear(7*7*32, num_classes)
def forward(self, x):
out = self.layer1(x)
out = self.layer2(out)
out = out.reshape(out.size(0), -1)
out = self.fc(out)
return out
def evaluate(model, gpu, test_loader, rank):
model.eval()
size = torch.tensor(0.).to(gpu)
correct = torch.tensor(0.).to(gpu)
with torch.no_grad():
for i, (images, labels) in enumerate(tqdm(test_loader)):
images = images.to(gpu)
labels = labels.to(gpu)
# Forward pass
outputs = model(images)
size += images.shape[0]
correct += (outputs.argmax(1) == labels).type(torch.float).sum()
# 群体通信 reduce 操作 change to allreduce if Gloo
dist.reduce(size, 0, op=dist.ReduceOp.SUM)
# 群体通信 reduce 操作 change to allreduce if Gloo
dist.reduce(correct, 0, op=dist.ReduceOp.SUM)
if rank == 0:
print('Evaluate accuracy is {:.2f}'.format(correct / size))
def train(gpu, args):
#训练函数中仅需要更改初始化方式即可。在ENV中只需要指定init_method='env://'。
#TCP所需的关键参数模型会从环境变量中自动获取,环境变量可以在程序外部启动时设定,参考启动方式。
#当前进程的rank值可以通过dist.get_rank()得到
dist.init_process_group(backend='nccl', init_method='env://')
args.rank = dist.get_rank()
model = ConvNet()
model.cuda(gpu)
# define loss function (criterion) and optimizer
criterion = nn.CrossEntropyLoss().to(gpu)
optimizer = torch.optim.SGD(model.parameters(), 1e-4)
#并行环境下,对于用到BN层的模型需要转换为同步BN层;
#用DistributedDataParallel将模型封装为一个DDP模型,并复制到指定的GPU上。
#封装时不需要更改模型内部的代码;设置混合精度中的scaler,通过设置enabled参数控制是否生效。
model = nn.SyncBatchNorm.convert_sync_batchnorm(model)
model = nn.parallel.DistributedDataParallel(model, device_ids=[gpu])
scaler = GradScaler(enabled=args.use_mix_precision)
# Data loading code
train_dataset = torchvision.datasets.MNIST(root='./datasets',
train=True,
transform=transforms.ToTensor(),
download=True)
# DDP要求定义distributed.DistributedSampler,通过封装train_dataset实现;在建立DataLoader时指定sampler。
# 此外还要注意:shuffle=False。DDP的数据打乱需要通过设置sampler,参考N4。
train_sampler = torch.utils.data.distributed.DistributedSampler(train_dataset)
train_loader = torch.utils.data.DataLoader(dataset=train_dataset,
batch_size=args.batch_size,
shuffle=False,
num_workers=0,
pin_memory=True,
sampler=train_sampler)
test_dataset = torchvision.datasets.MNIST(root='./datasets',
train=False,
transform=transforms.ToTensor(),
download=True)
test_sampler = torch.utils.data.distributed.DistributedSampler(test_dataset)
test_loader = torch.utils.data.DataLoader(dataset=test_dataset,
batch_size=args.batch_size,
shuffle=False,
num_workers=0,
pin_memory=True,
sampler=test_sampler)
start = datetime.now()
total_step = len(train_loader)
for epoch in range(args.epochs):
# 在每个epoch开始前打乱数据顺序。(注意total_step已经变为orignal_length // args.world_size。)
train_loader.sampler.set_epoch(epoch)
model.train()
for i, (images, labels) in enumerate(tqdm(train_loader)):
images = images.to(gpu)
labels = labels.to(gpu)
# Forward pass
# 利用torch.cuda.amp.autocast控制前向过程中是否使用半精度计算。
with torch.cuda.amp.autocast(enabled=args.use_mix_precision):
outputs = model(images)
loss = criterion(outputs, labels)
# Backward and optimize
optimizer.zero_grad()
# 当使用混合精度时,scaler会缩放loss来避免由于精度变化导致梯度为0的情况。
scaler.scale(loss).backward()
scaler.step(optimizer)
scaler.update()
# 为了避免log信息的重复打印,可以只允许rank0号进程打印。
if (i + 1) % 100 == 0 and args.rank == 0:
print('Epoch [{}/{}], Step [{}/{}], Loss: {:.4f}'.format(epoch + 1, args.epochs, i + 1, total_step,
loss.item()))
# 清理进程
dist.destroy_process_group()
if args.rank == 0:
print("Training complete in: " + str(datetime.now() - start))
def parse_args():
parser = argparse.ArgumentParser()
parser.add_argument('-g', '--gpuid', default=0, type=int,
help="which gpu to use")
parser.add_argument('-e', '--epochs', default=2, type=int,
metavar='N',
help='number of total epochs to run')
parser.add_argument('-b', '--batch_size', default=4, type=int,
metavar='N',
help='number of batchsize')
# 这里指的是当前进程在当前机器中的序号,注意和在全部进程中序号的区别,即指的是GPU序号0,1,2,3。
# 在ENV模式中,这个参数是必须的,由启动脚本自动划分,不需要手动指定。要善用local_rank来分配GPU_ID。
# 不需要填写,脚本自动划分
parser.add_argument("--local_rank", type=int,
help='rank in current node')
# 是否使用混合精度
parser.add_argument('--use_mix_precision', default=False,
action='store_true', help="whether to use mix precision")
# Need 每台机器使用几个进程,即使用几个gpu 双卡2,
parser.add_argument("--nproc_per_node", type=int,
help='numbers of gpus')
# 分布式训练使用几台机器,设置默认1,单机多卡训练
parser.add_argument("--nnodes", type=int, default=1, help='numbers of machines')
# 分布式训练使用的当前机器序号,设置默认0,单机多卡训练只能设置为0
parser.add_argument("--node_rank", type=int, default=0, help='rank of machines')
# 分布式训练使用的0号机器的ip,单机多卡训练设置为默认本机ip
parser.add_argument("--master_addr", type=str, default="127.0.0.1",
help='ip address of machine 0')
args = parser.parse_args()
# train(args.local_rank, args):一般情况下保持local_rank与进程所用GPU_ID一致。
print(args.local_rank)
print(args.batch_size)
return args
# exit()
if __name__ == '__main__':
args = parse_args()
train(args.local_rank, args)
3.2 paddle
训练命令:
#单机多卡启动,设置当前使用第0号和第1号卡
export CUDA_VISIABLE_DEVICES='0,1'
python -m paddle.distributed.launch train.py
3.2.1 launch方式(paddle2.3以前适用)
paddle.distributed.launch通过指定启动的程序文件,以文件为单位启动多进程来实现多卡同步训练。以前在aistudio脚本任务说明里,就是推荐这种方法启动多卡任务。launch这种方式对进程管理要求较高。
- 高层训练API
%%writefile hapitrain.py
import warnings
warnings.filterwarnings("ignore")
import paddle
from paddle.vision.transforms import ToTensor
paddle.set_device("gpu")
train_dataset = paddle.vision.datasets.MNIST(mode='train', transform=ToTensor())
test_dataset = paddle.vision.datasets.MNIST(mode='test', transform=ToTensor())
lenet = paddle.vision.models.LeNet()
# Mnist继承paddle.nn.Layer属于Net,model包含了训练功能
model = paddle.Model(lenet)
# 设置训练模型所需的optimizer, loss, metric
model.prepare(
paddle.optimizer.Adam(learning_rate=0.001, parameters=model.parameters()),
paddle.nn.CrossEntropyLoss(),
paddle.metric.Accuracy(topk=(1, 2))
)
# 启动训练
model.fit(train_dataset, epochs=1, batch_size=64, log_freq=400)
# 启动评估
model.evaluate(test_dataset, log_freq=100, batch_size=64)
训练发现高层训练API使用后使用了数据并行,将数据切成两份分别放入两个GPU,训练速度毫无疑问加快了。
- 基础训练API
%%writefile normaltrain.py
import warnings
warnings.filterwarnings("ignore")
import paddle #这是有3处改动的版本
from paddle.vision.transforms import ToTensor
import paddle.distributed as dist #第1处改动,import库
paddle.set_device("gpu")
train_dataset = paddle.vision.datasets.MNIST(mode='train', transform=ToTensor())
test_dataset = paddle.vision.datasets.MNIST(mode='test', transform=ToTensor())
# 加载训练集 batch_size 设为 64
train_loader = paddle.io.DataLoader(train_dataset, batch_size=64, shuffle=True)
def train():
# 第2处改动,初始化并行环境
dist.init_parallel_env()
# 第3处改动,增加paddle.DataParallel封装
net = paddle.DataParallel(paddle.vision.models.LeNet()) #手册这里没有写全LeNet的库路径
epochs = 1
adam = paddle.optimizer.Adam(learning_rate=0.001, parameters=net.parameters())
# 用Adam作为优化函数
for epoch in range(epochs):
for batch_id, data in enumerate(train_loader()):
x_data = data[0]
y_data = data[1]
predicts = net(x_data)
acc = paddle.metric.accuracy(predicts, y_data, k=2)
avg_acc = paddle.mean(acc)
loss = paddle.nn.functional.cross_entropy(predicts, y_data, reduction='mean')
loss.backward() #这里手册误写成了avg_loss
if batch_id % 400 == 0:
print("epoch: {}, batch_id: {}, loss is: {}, acc is: {}".format(epoch, batch_id, loss.numpy(), avg_acc.numpy())) #这里手册误写成了avg_loss
adam.step()
adam.clear_grad()
# 启动训练
train()
基础训练API发现两个GPU虽然显存占用正常,但step数没有差异,整体训练时间也不变,但收敛更快,可能是梯度共享了。
3.2.2 spawn方式(paddle2.0及以后适用)
paddle.distributed.spawn是以function函数为单位启动多进程来实现多卡同步的,可以更好地控制进程,在日志打印、训练退出时更友好。这是当前推荐的用法。
- 高层API场景
# %%writefile hapispawn.py
import paddle
from paddle.vision.transforms import ToTensor
import paddle.distributed as dist
paddle.set_device("gpu")
train_dataset = paddle.vision.datasets.MNIST(mode='train', transform=ToTensor())
test_dataset = paddle.vision.datasets.MNIST(mode='test', transform=ToTensor())
lenet = paddle.vision.models.LeNet()
# Mnist继承paddle.nn.Layer属于Net,model包含了训练功能
model = paddle.Model(lenet)
# 设置训练模型所需的optimizer, loss, metric
model.prepare(
paddle.optimizer.Adam(learning_rate=0.001, parameters=model.parameters()),
paddle.nn.CrossEntropyLoss(),
paddle.metric.Accuracy(topk=(1, 2))
)
def train():
# 启动训练
model.fit(train_dataset, epochs=1, batch_size=64, log_freq=400)
# 启动评估
# model.evaluate(test_dataset, log_freq=20, batch_size=64)
if __name__ == '__main__':
dist.spawn(train, nprocs=4, gpus='0,1,2,3')
- 基础API场景
import paddle #这是有3处改动的版本
from paddle.vision.transforms import ToTensor
import paddle.distributed as dist #第1处改动,import库
paddle.set_device("gpu")
train_dataset = paddle.vision.datasets.MNIST(mode='train', transform=ToTensor())
test_dataset = paddle.vision.datasets.MNIST(mode='test', transform=ToTensor())
# 加载训练集 batch_size 设为 64
train_loader = paddle.io.DataLoader(train_dataset, batch_size=64, shuffle=True)
def train():
# 第2处改动,初始化并行环境
dist.init_parallel_env()
# 第3处改动,增加paddle.DataParallel封装
net = paddle.DataParallel(paddle.vision.models.LeNet()) #手册这里没有写全LeNet的库路径
epochs = 1
adam = paddle.optimizer.Adam(learning_rate=0.001, parameters=net.parameters())
# 用Adam作为优化函数
for epoch in range(epochs):
for batch_id, data in enumerate(train_loader()):
x_data = data[0]
y_data = data[1]
predicts = net(x_data)
acc = paddle.metric.accuracy(predicts, y_data, k=2)
avg_acc = paddle.mean(acc)
loss = paddle.nn.functional.cross_entropy(predicts, y_data, reduction='mean')
loss.backward() #这里手册误写成了avg_loss
if batch_id % 400 == 0:
print("epoch: {}, batch_id: {}, loss is: {}, acc is: {}".format(epoch, batch_id, loss.numpy(), avg_acc.numpy())) #这里手册误写成了avg_loss
adam.step()
adam.clear_grad()
# 启动train多进程训练,默认使用所有可见的GPU卡
import paddle.distributed as dist
if __name__ == '__main__':
dist.spawn(train)
四. 常见问题解决
4.1 强制结束后显存不释放
一般使用Ctrl+C强制结束进程后就会自动释放显存,但多卡时的释放常常出现问题。
解决方法:
#查看所有占用显存的进程
fuser -v /dev/nvidia*
#取出PID
fuser -v /dev/nvidia*|awk -F " " '{print $0}' >/tmp/pid.file
#强制杀死进程
while read pid ; do kill -9 $pid; done </tmp/pid.file