
What & Why
应用TMA方法,即可在目标机器上运行一次,便可得到上图结果
TMA对CPU有四个分类,每个分类的比重可以简单理解为所消耗的比重。在最“好”的情况下,Retiring(退休)的比重为100%,其余比重0%,即其余三类是导致CPU效率不高的分类。
利用TMA结果分析时,只关注第一层级比重最高的分支,然后逐级向下追溯,例如,得知第一层级是Backend,然后只需关注memory部分,最终可以得知,CPU效率不高主要是CPU访问DRAM这条路径导致的。
业界基准测试 Benchmark----比如SPEC CPU
Latency 延迟
对于多线程优化,最怕的就是锁这类问题
TMA与传统的热点分析方法所处的层级不一样,TMA是站在微架构层级对软件的性能进行分析
How
cpu内部分前端和后端,前端主要负责取值,译码等操作,是顺序执行;后端负责接收前端的指令,并且乱序执行,顺序retire。
一个CPU若出现性能瓶颈,有可能出现在前端or后端,也有可能是分支预测导致。
TMA的第一层级中有Frontend,Backend,Speculation这三个分类,还有retiring,retiring分类表示是理想状况的流水线执行比重。
Pipeline Slots:若四发射CPU---即每个周期前端向后端发送四个uops,后端每个周期也能接收4个uops,Pipline被uop填充后叫作pipeline slot。

上图Pipline Slots只被填充了50%,即出现了50%的Bubble气泡,所以Retiring这个分类有可能为50%(若发生Bad Speculation错误推测,Retiring这个分类将<50%)
这样,我们就能大致了解到TMA的第一层级是对Pipeline Slots进行划分,看究竟有多少的Pipeline Slots被充分地利用。
没利用的pipline slots如何进一步划分?
TMA思路:先查看CPU前端和后端交界处,即Issued这个事件的状况。每个周期每个pipline,分为有uop issued和无uop issued两个状态。
若无uop issued ,代表前端或者后端出问题,因此只需要查看后端是否发送堵塞,便可进行相应的划分。
对于issue成功的uops,后续也可能因为分支预测错误的原因,导致uops最终没有被retire,即做了无用功。

若没有uops被issue,后端没堵塞(Back-end stall),归结为前端不给力(Frontend Bound)
TMA并不需要在每个周期都去探查一次CPU的具体情况,只需要执行完整测试程序后,拿到这个程序的一些特定的performance Counter值,便可进行TMA。
为什么拿到一些统计结果就可以进行第一层级的划分呢?
Total Slots,即总共有多少个Pipeline Slots,只需用程序的执行周期乘以CPU每个周期的发射数便可得到。
Slots Retired,即被成功Retired的uops数量,这个计数器在大部分的CPU中都有被实现,只需要每个周期加上这个周期Retired的uops数量便可以实现。
Slots issued,即总共有多少的uops被成功发射,这个也在大部分的CPU中已经实现。
Fetch Bubbles,即只需要统计没有出现后端拥塞的情况下,前端没有利用好pipeline slots的数量。
Recovery Bubbles,指的是由于Recovery的原因导致前端出现瓶颈,在后端没有拥塞的情况下,没有发射uops的数量。
Fetch Bubbles和Recovery Bubbles的和便是Frontend Bubbles,即在后端没有拥塞的情况下,前端导致了多少的Pipeline Slost被浪费。
通过在CPU中设计相应的逻辑电路,加上Performance monitoring units (PMUs),便可以很容易得到以上公式中我们所需要的统计值。
Fetch所导致的Bubbles占所有Pipeline Slots的比重,便是前端所浪费的Slots比重。
用Issued uops总数减去Retired uops总数,表示虽然Issue但是没有Retire,做了无用功的uops数量,再加上Recovery过程中所导致的Bubbles,这两者之和再除以总的Slots数量,便可以表示Bad Speculation所浪费的Slots比重。
uops:微指令,是一种底层硬件操作,CPU前端负责获取体系结构指令中表示的程序代码,并将其解码为一个或多个uops
Pipline Slots:表示处理一个uop需要的硬件资源
Pipline Width:表示pipline slots的数量
以Pipeline Slots测得的Top-Down度量,如Front-End Bound和Back-End Bound,表示因各种原因(如Front-End问题和Back-End问题)导致的Pipeline Slots 阻塞的百分比。
对于前端和后端划分:一般将(micro-op)uops queue 往后的部分称为后端,micro-op Queue 模块往后的带宽是CPU发射宽度
现代乱序执行CPU使用的一些机制:
piplined
superscalar 超标量体系结构
OOO execution
speculation 投机
multiple caches 多级cache
memory pre-fetching and disambiguation 内存预取和消除歧义
vector operations 向量运算
Frontend---前端
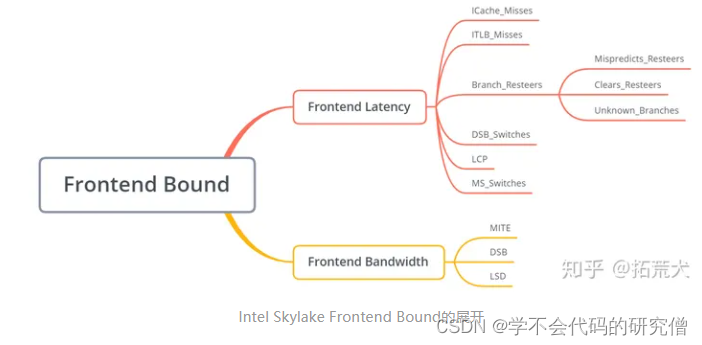
frontend bound 可以划分为
latency 延迟,表示由于前端latency过大导致没有uops发送到后端的比重,
bandwidth带宽 ,表示由于前端decode能力不足导致前端不能充分利用四发射的带宽比重,
下列的公式均来源于TMAM 3.5中的skl_client_ratios.py文件,该文件主要存放的是Skylake的TMA比例系数和公式
公式中使用到的PMC事件具体说明,可以在Inter的Intel® 64 and IA-32 Architectures Software Developer’s Manual中找到,具体是在Volume 3 (3A, 3B, 3C & 3D): System Programming Guide中的CHAPTER 19 PERFORMANCE MONITORING EVENTS。
Frontend Bound:
公式:self.val = EV("IDQ_UOPS_NOT_DELIVERED.CORE", 1) / SLOTS(self, EV, 1)
上式中,EV函数代表对具体事件的调用,而SLOTS是另一个函数,具体的计算方法可以找到相应的函数定义来查看。frontend bound的值是利用IDQ_UOPS_NOT_DELIVERED.CORE事件的值除以SLOTs函数的值。SLOTS表示整个执行周期Pipline所具有的slots数量,具体方法就是用流水线的宽度乘CPU的运行周期。
def SLOTS(self, EV, level):
return Pipeline_Width * CORE_CLKS(self, EV, level)
IDQ_UOPS_NOT_DELIVERED.CORE事件又表示的是什么意思呢?通过查阅Intel的手册,可以找到该事件的定义:Count issue pipeline slots where no uop was delivered from the front end to the back end when there is no back-end stall。简单来说,就是后端没有stall阻塞的时候,前端没有发射的uops数量,即由于前端原因所浪费的uops数目。然后再用该值除以总的SLOTS数目,即为Frontend Bound的比重。
SLOTS计算公式,在pipline_Width定义为一个常数,为4,这是因为流水线宽度为4,根据不同CPU架构需要相应修改
CORE_CLKS函数的公式,由于现代CPU中的机制比较多,因此core clks要分多种情况考虑
def CORE_CLKS(self, EV, level):
return ((EV("CPU_CLK_UNHALTED.THREAD", level) / 2)*(1 + EV("CPU_CLK_UNHALTED.ONE_THREAD_ACTIVE", level) / EV("CPU_CLK_UNHALTED.REF_XCLK", level)))
if ebs_mode else(EV("CPU_CLK_UNHALTED.THREAD_ANY", level) / 2)
if smt_enabled else CLKS(self, EV, level)
def CLKS(self, EV, level):
return EV("CPU_CLK_UNHALTED.THREAD", level)
根据ebs_mode和smt_enabled 的值对core clks取三种不同的值,ebs_mode的值恒为FALSE,所以目前仅考虑smt_enabled的值
SMT--同步多线程
在intel中称HT(Hyper Threading)超线程
在Intel和AMD的CPU中,每个Core最多为双线程,即一个Core可以同时运行两个Thread。当smt_enabled为True时,Core Clks为CPU_CLK_UNHALTED.THREAD_ANY除以2
CPU_CLK_UNHALTED.THREAD_ANY事件的解释为:Core cycles when at least one thread on the physical core is not in halt state,即有线程在Core内执行的周期数。这里除以2是因为超线程的时候,两个线程会共享4发射的流水线宽度,若两个线程是静态划分的话,这样每个线程的Slots数量即为2*Clks。
从此也可以佐证,TMA对于超线程的CPU进行分析也是可以的,因为开启超线程的时候,可以简单理解为每个逻辑内核的流水线宽度变为原来的一半,SLOTS数量变为原来的二分之一。
Frontend_Latency:
公式:self.val = Pipeline_Width * EV("IDQ_UOPS_NOT_DELIVERED.CYCLES_0_UOPS_DELIV.CORE", 2) / SLOTS(self, EV, 2)
这里IDQ_UOPS_NOT_DELIVERED.CYCLES_0_UOPS_DELIV.CORE事件的说明为:Counts, on the per-thread basis, cycles when no uops are delivered to Resource Allocation Table (RAT)。即每个Thread没有uops发射的周期数,用这个周期数乘以流水线宽度,即可以得到前端延时过大所浪费的Slots数目,最后用该Slots数目除以总的Slost数,便是相应的比重。
所以我们在应用TMAM的时候,应该尽量避免开启SMT,若开启了SMT,也尽量不要同时使用一个物理内核中的两个逻辑内核,这也算是TMAM的一个小小缺陷吧。
可以导致Frontend Latency:ICache_Misses,ITLB_Misses,Branch_Resteers,DSB_Switches,LCP,MS_Switches这六个子类
Icache_misses
首先是ICache_misses,一旦发生instruction cache miss,Frontend没有Instruction去做decode,必然会导致没有相应的uops发往后端,导致Frontend Latency出现瓶颈。
self.val = (EV("ICACHE_16B.IFDATA_STALL", 3) + 2 * EV("ICACHE_16B.IFDATA_STALL:c1:e1", 3)) / CLKS(self, EV, 3)
这里可以先简单理解为,用L1 ICache Miss所导致pipeline Stall的周期数,除以总的周期数,以得到L1 ICache Miss所占的一个比重。 ICACHE_16B.IFDATA_STALL事件的说明为:Cycles where a code line fetch is stalled due to an L1 instruction cache miss. The legacy decode pipeline works at a 16 Byte granularity.由于L1指令缓存丢失而导致代码行读取停滞的周期。
ITLB_misses:
ITLB_Misses,思路还是和ICache Misses一样,也是站在Cycles这个层级去统计计算的,为什么不继续站在Slots的层级去统计计算呢?Slots层级的优势当然比Cycles层级的优势多得多,但是很多具体的底层事件,所站的角度是在Cycles这一个级别的,很难、甚至不可能计算出所浪费的Slots数量,所以这时候就只能在Cycles这一个层级做统计分析,这样会更加方便和简洁。
公式:self.val = EV("ICACHE_64B.IFTAG_STALL", 3) / CLKS(self, EV, 3)
其中的ICACHE_64B.IFTAG_STALL事件的解释为:Cycles where a code fetch is stalled due to L1 instruction cache tag miss。由于L1指令缓存标记丢失而导致代码获取停滞的周期。若发生了Cache Tag Miss,即表明在TLB中没有找到相应的Tag,发生了TLB Miss,用Tag Miss所导致停顿的周期数,除以总周期数,即为相应的比重。
Branch_Resteers:
统计的是前端从一条错误的分支恢复过来,中间所消耗的周期数占所有周期数的比重。
可能会和其他miss重复统计
self.val = (EV("INT_MISC.CLEAR_RESTEER_CYCLES", 3) + BAClear_Cost * EV("BACLEARS.ANY", 3)) / CLKS(self, EV, 3)
对于公式中的INT_MISC.CLEAR_RESTEER_CYCLES事件,对应的解释为:Cycles the issue-stage is waiting for front-end to fetch from resteered path following branch misprediction or machine clear events. 即前端等待Resteer的周期数。
resteer指分支预测错误恢复过程
BACLEARS.ANY ---前端预测错误发生的次数
BAClear_Cost 每发生一次分支预测错误,就会浪费的周期数
对于Branch Resteers,还能继续向下展开为三类,分别为Branch Misprediction,Machine Clears和new branch address clears三类原因导致的比重。
DSB_Switches:
这个分类统计的是从DSB pipeline切换到MITE pipeline导致前端停顿的周期比重。
DSB是Decoded Stream Buffer的缩写,存放的一些已经被decode的uops,可以把它理解为一个uops ICahce,DSB是在Intel的Sandy Bridge架构中引入的,DSB对应到AMD中就是Op Cache,顾名思义,就是存放uOps的Cache。
MITE是Micro-instruction Translation Engine的缩写,其实就是没有引入DSB之前传统的decode pipeline。
由于前端从DSB切换到MITE Pipeline,会有一定的惩罚周期,导致没有uops发往Micro-op Queue,这个分类主要就是计算这部分周期占总周期的一个比重。
self.val = EV("DSB2MITE_SWITCHES.PENALTY_CYCLES", 3) / CLKS(self, EV, 3)
DSB2MITE_SWITCHES.PENALTY_CYCLES事件表示的是Cycles of delay due to Decode Stream Buffer to MITE switches,即切换所浪费的周期数,然后用该值除以总周期数,得到相应的比重。
LCP:Length Changing Prefixes长度变化前缀
正在decode的指令,若发生动态长度前缀改变,即会发生几个cycle的stall,大约三个周期,使用适当的编译器标志或者默认的编译器,可能会解决LCP的问题
self.val = EV("ILD_STALL.LCP", 3) / CLKS(self, EV, 3)
ILD_STALL.LCP事件表示的是Stalls caused by changing prefix length of the instruction,即由于LCP导致停顿的周期数,除以总的周期数。
MS_Switches:
想要表达的是从DSB pipeline或MITE pipeline切换到MS pipeline所浪费的周期比重。
MS是Microcode Sequencer微编码序列的缩写,对应的是Intel架构图中的MSROM module和AMD架构图中的Microcode Rom。
self.val = MS_Switches_Cost * EV("IDQ.MS_SWITCHES", 3) / CLKS(self, EV, 3)
IDQ.MS_SWITCHES事件统计的是切换的次数,具体的解释为:Number of switches from DSB (Decode Stream Buffer) or MITE (legacy decode pipeline) to the Microcode Sequencer,然后再用次数乘以切换所浪费的周期数MS_Switches_Cost (这里MS_Switches_Cost为常数2),变得可以得到MS切换所导致停顿的周期数。最后用这个值除以总的周期数,便是MS Switch相应的比重。
这也是为什么TMA方法学所强调的,不同层级、不同分类下的数值比较没有意义。只有当Frontend Latency这个分类是主要瓶颈的时候,我们才会对他展开,然后我们只需要比较它下面的六个子类比重大小,而不用再去考虑其他的分类。
Frontend Bandwidth:
前端没有充分利用带宽所消耗的Slots比重
self.val = self.Frontend_Bound.compute(EV) - self.Frontend_Latency.compute(EV)
即直接用父类Frontend_Bound的值减去他兄弟Frontend_Latency的值,由于这两个子类的和一定等于前端总浪费的Slots数量,所以就可以通过这样简单地相减得到。接下来主要详细看下Bandwidth下的三个子类,对于Bandwidth,TMA将他划分成了MITE,DSB和LSD三个子类,这三个子类分别对应三种Frontend pipeline,均有可能出现issue的uops宽度不为4的情况。
对于Bandwidth,TMA将他划分成了MITE,DSB和LSD三个子类,这三个子类分别对应三种Frontend pipeline,均有可能出现issue的uops宽度不为4的情况。
MITE:(Micro-instruction Translation Engine)微指令翻译引擎
由于Frontend的Decoder pipeline可能会出现inefficiencies(无能)的情况,所以会导致MITE的Bandwidth不理想。
公式:
self.val = (EV("IDQ.ALL_MITE_CYCLES_ANY_UOPS", 3) - EV("IDQ.ALL_MITE_CYCLES_4_UOPS", 3)) / CORE_CLKS(self, EV, 3)
对于IDQ.ALL_MITE_CYCLES_ANY_UOPS,统计的是有uops从MITE发送到IDQ(Instruction Decode Queue)的周期数,对应的解释为:Counts cycles MITE is delivered at least one uops。
然后对于IDQ.ALL_MITE_CYCLES_4_UOPS,统计的是有4个uops从MITE发往IDQ的周期数,即Counts cycles MITE is delivered four uops。
两者之差,即为MITE的Bandwidth不为4的周期数,再用这个差除以总的周期数,即可得到相应的比重。当然,我们可以将MITE分别向IDQ发送1、2、3uops的周期数全部加起来,即可得到Bandwidth小于4的周期数,再用这个周期数除以总周期数,也可以得到同样的结果。
DSB:(Decoded Stream Buffer)解码uop缓存
也有可能出现inefficient(效率低)的情况,具体原因可能是没有利用好DSB cache structure,或者在读取的时候发生了Bank conflict,这些原因均会导致DSB没有充分利用带宽。具体的计算公式为:
self.val = (EV("IDQ.ALL_DSB_CYCLES_ANY_UOPS", 3) - EV("IDQ.ALL_DSB_CYCLES_4_UOPS", 3)) / CORE_CLKS(self, EV, 3)
公式中的两个事件解释与MITE公式中的两个事件解释一致,只不过观察的对象变成了DSB pipeline。两个事件之差,便是DSB效率低的周期数,再除以总的周期数,便可以得到相应的比重。
不过我发现,好像随着Intel CPU Microarchitecture的升级,MITE和DSB的Bandwidth也有所升级,最大的带宽肯定不再是4。再次拿Skylake的架构图来说明,通过架构图我们可以了解到,DSB的最大Bandwidth已经变成了6,MITE的Bandwidth变成了5。所以这里的公式应该用MITE/DSB有uops发射的周期,减去uops带宽大于等于4的周期,才比较合理。要么就用发送1、2、3 uops的周期数的和作为分子,除以总的周期数,而不是用减法实现。
fusion:是Intel CPU的一种机制,使得Frontend可以将多个uops融合成一个复杂的uop进行处理,然后在后端执行的时候,会将其拆分来进行处理。
LSD:Loop Stream Detector 循环流检测器
检测、保存uops循环序列,当uops循环序列小于或等于LSD的容量时候,可存放在LSD中,便可以不需要再通过前端的译码得到相应的uops序列,只需要不断从LSD中取出相应的uops序列便可。
self.val = (EV("LSD.CYCLES_ACTIVE", 3) - EV("LSD.CYCLES_4_UOPS", 3)) / CORE_CLKS(self, EV, 3)
看来还是和他的兄弟节点计算方法一致,LSD.CYCLES_ACTIVE事件为Cycles with at least one uop delivered by the LSD and none from the decoder(LSD至少有一个上行而解码器没有上行的周期),LSD.CYCLES_4_UOPS事件为Cycles with 4 uops delivered by the LSD and none from the decoder(由LSD提供的4个上行周期,而解码器没有)。那么两者之差便是LSD带宽不满的周期数,然后再用这个数值除以总的周期数,得到相应的比重。
正确的分析方法还是先看第一层,然后再看对应的第二层,接着再看对应的第三层,根本没必要去关注不同分支下的各个类比的比重大小,只需要关注同一个分支下的比重大小即可。