一、项目中遇到的问题及优化
如何保证在Neo4j中维护平台全量粉丝关注数据
针对粉丝关注数据我们有两份
第一份是历史粉丝关注数据
第二份是实时粉丝关注数据
如何通过这两份数据实现维护平台全量粉丝关注数据呢?
背景是这样的
历史粉丝数据是由服务端每天晚上0点的时候定时同步到mysql数据库中的,因为之前平台是把粉丝的关注数据,存储到了redis中,每天晚上定时向mysql中同步一次。
实时粉丝数据在准备做这个项目之前通过日志采集工具把这些数据采集到kafka里面了
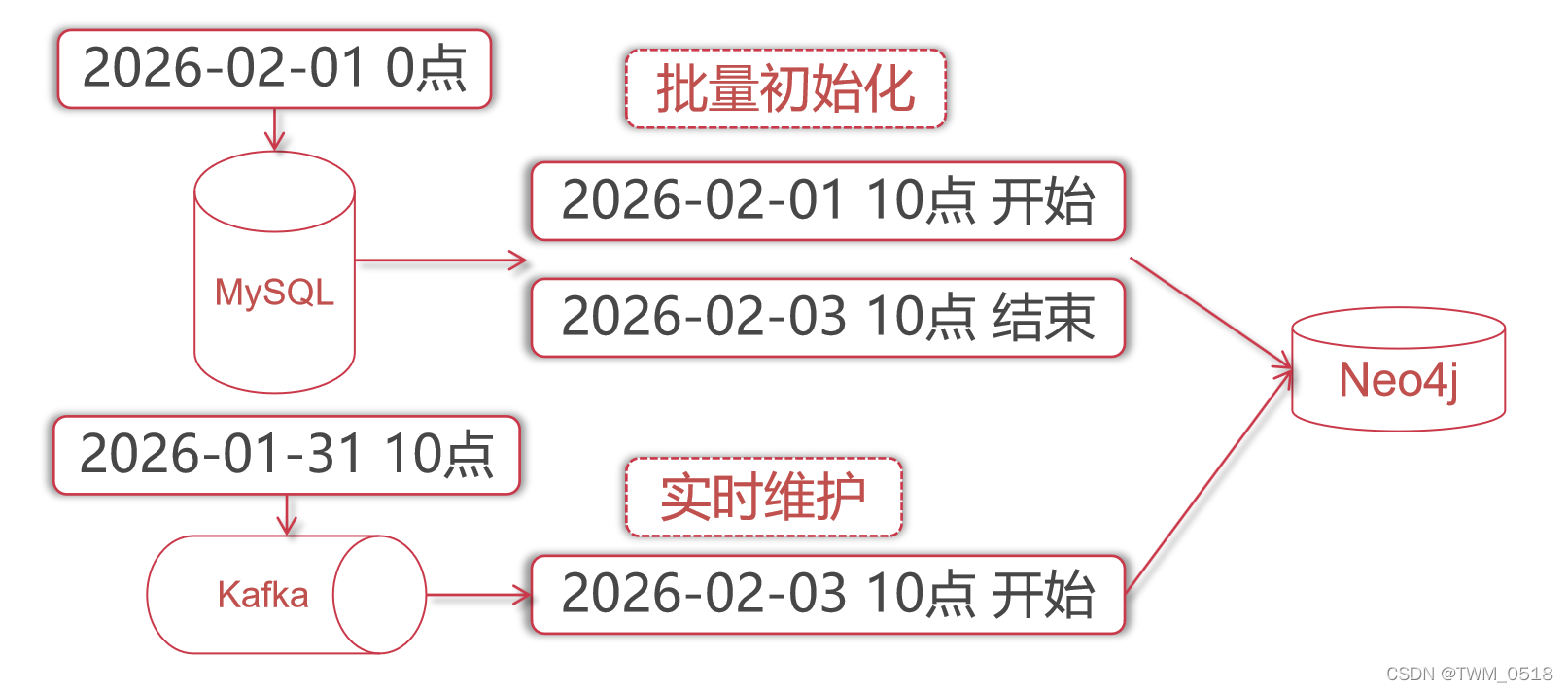
基于此,假设我们是在2026年2月1日那天上午10点开始将mysql中的历史数据导出来,然后批量导入到neo4j中,mysql中的粉丝数据其实是截止到2026年2月1日0点的。
这个导入过程当时耗时将近2天。
也就是在2026年2月3日上午10点左右导入完毕的,此时neo4j中的粉丝关注数据是截止到2026年2月1日0点的。
接下来我们需要通过kafka来将这两天内的粉丝关注数据读取出来,补充到neo4j中,如何实现呢?
因为我们的kafka当时是保存3天的数据,所以说这里面保存的还有2026-01-31 10点左右开始的数据,所以说当时我们开发好SparkStreaming程序之后,使用一个新的消费者groupid,然后将auto.offset.reset设置为earlist,读取最早的数据,这样就可以将这个topic中前3天的数据都读出来,然后在neo4j中进行维护,这样其实会重复执行2026-01-31 10点到2月1 日0点之间的数据,但是对最终的结果是没有影响的。
这样就可以实现在neo4j中全量维护粉丝关注数据了。
2、如何解决数据乱序导致的粉丝关注关系不准确
两种方案
通过在sparkStreaming内部对读取到的一小批数据基于时间进行排序,按照时间顺序执行粉丝关注相关操作,这样可以从一定程度上解决数据乱序的问题。
在v2.0中,我们使用了Flink计算引擎,此时可以使用watermark+eventtime来解决数据乱序的问题。
3、如何优化三度关系推荐列表数据计算程序
针对三度关系推荐列表数据计算程序:GetRecommendListScala
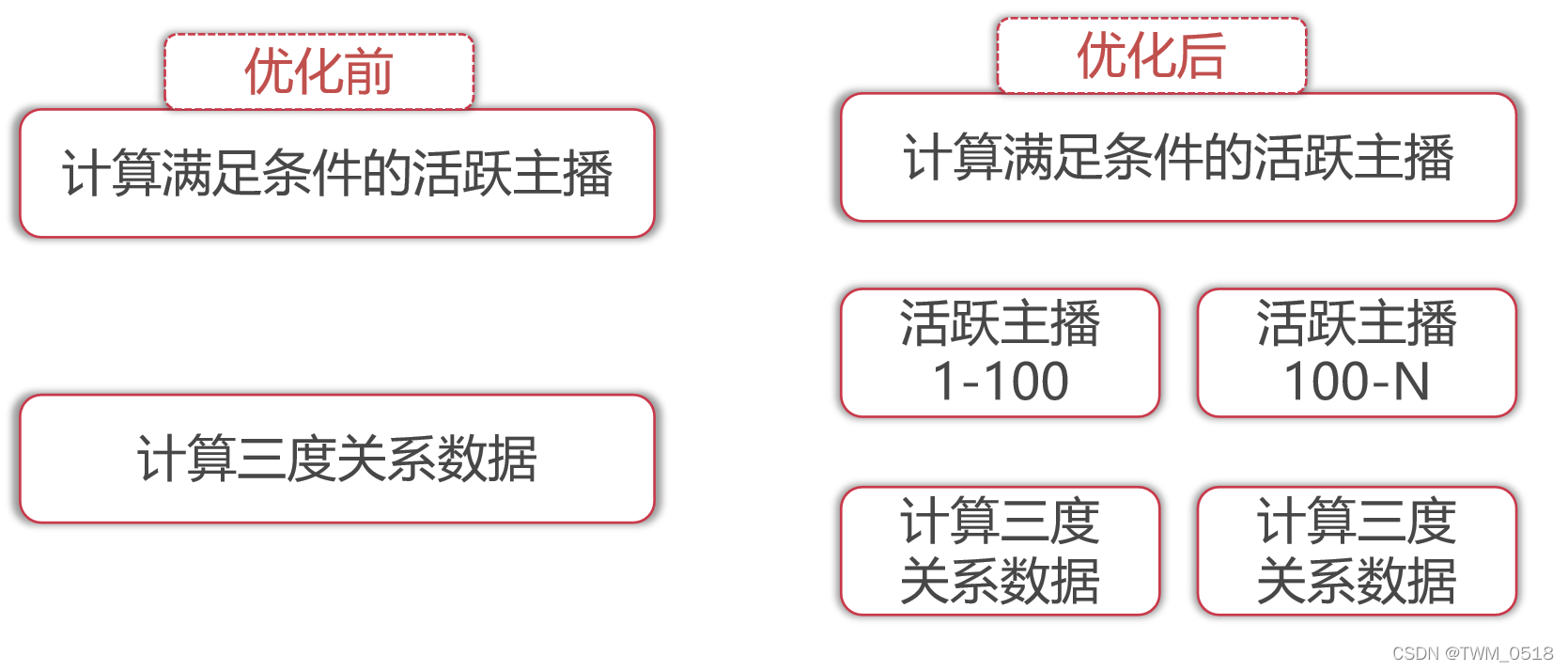
这个任务在执行的时候需要执行20个小时左右,因为这里面会先查询出来满足条件的主播,然后挨个计算这些主播的三度关系数据,这里面需要和neo4j进行交互,主要慢在了neo4j这里,因为三度关系查询是比较复杂的,所以会比较耗时。
这个任务在执行的时候我们会发现它有时候无缘无故的提示task丢失,进而导致任务失败,还得重新计算,代价太大,所以这样不太靠谱。
后来发现是由于spark离线任务执行时间过长的时候会出现这种task丢失的问题。
所以后来我们对这个程序又做了优化。
针对第一步计算出来的主播列表,分成20份保存到hdfs上面
match (a:User) where a.timestamp >= "+param("timestamp")+" and a.level >= "+param("level")+" return a.uid
这样就会把这些满足条件的uid分别存储到hdfs上的20个文件中。
接下来在shell脚本中通过for循环,遍历这20个文件,针对这20个文件按照顺序启动spark任务去执行,这样一个spark任务读取一个文件中的数据去计算,1个任务1个小时左右就执行完了。
这里执行的任务其实就是根据uid计算对应的三度关系
match (a:User {uid:'" + uid + "'}) <-[:follow]- (b:User) -[:follow]-> (c:User) where b.timestamp >= " + timestamp + " and c.timestamp >= " + timestamp + " and c.level >= " + level + " and c.flag = 1 return a.uid as auid,c.uid as cuid,count(c.uid) as sum order by sum desc limit 30
这样就可以避免Spark任务执行时间过长导致的task丢失问题了。
思路是这样的,在这给大家留一个作业,大家先做一下,到时候我也会把这个改造之后的代码发给大家,在这让大家自己先动手做一下,主要是为了加深理解。
4、项目数据规模
初始化用户数据2.5千万+
初始化用户关系数据5亿+
每天实时关系数据500万+
每天主活数据100万+
每天等级变化数据10万+
每天开播数据20万+
直播平台运营了1年,数据指标在这个级别。
5、集群资源规模(HDP集群)
大数据平台集群节点数量500+
内存:30T+,磁盘:1000T+
YARN资源队列分了4个:default+online+offline+machine
default:默认队列
online:运行一些线上实时任务
offline:运行离线任务
machine:专门为算法组服务的,跑一些算法任务,因为算法部门会经常跑一些递归执行的任务,非常耗时,也非常耗资源,所以给他们单独分了一个队列。
这几个队列之间的资源比例大致为:1:2:5:2
6、集群数据规模
HDFS上每日新增业务日志数据20T+
注意:这里面的日志不包含接口请求日志,这种除非是有需求需要用到,否则我们是不采集的,因为接口调用日志量太大了,在这里这20T+的数据都是我们需要用到的一些业务相关的日志。如果加上接口调用日志,每日新增日志数据量至少2PB。
Kafka中Topic数量90+
Kafka中的某一个大Topic,峰值每秒8K条左右,低峰期每秒5K左右,其它的小topic数据量没有这么大,一般每秒是在500~1000左右
注意:我们当时kafka的数据保存天数从最开始的5天,改为保存3天,最后又改为保存1天,因为后期接入的数据量越来越多,kafka集群的磁盘不够用了,因为这里面有用的数据我们都做了落盘操作,保存到了hdfs上面,所以说在kafka里面就没有必要保存太长时间了。
7、Neo4j性能指标
最开始搭建Neo4j使用的是一台8core、64g的服务器
用了半年左右,发现内存不够用了,对机器扩容,将内存升级到128g
针对此配置的机器,给neo4j进程实例分配了40G内存,给neo4j数据缓存部分分配了80G内存
当时在做技术选型的时候做过测试:
向neo4j中入库数据的情况是这样的:
节点数:2.5千万
关系数:4.2亿
此时这些数据在neo4j中占用的内存大致在15G左右。
查询某一个用户的关注关系,可以在毫秒级内返回
查询某一个用户的三度关系,耗时大致10ms左右
当时使用load csv批量入库数据,100W条数据大致需要执行3分钟左右
8、Neo4j核心参数修改
针对128g内存的服务器,我们当时是这样设置的。
dbms.memory.heap.initial_size=40g
dbms.memory.heap.max_size=40g
这两个参数是指定neo4j使用的jvm堆内存大小,其实就是给neo4j进程实例本身分配的。对neo4j中数据进行计算的时候会使用这部分内存
这两个值的大小建议设置成一样的即可。
dbms.memory.pagecache.size=80g
这个参数是指定neo4j数据缓存的内存大小,主要是为了缓存节点和关系数据,如果可以将neo4j中的所有节点和关系全部缓存到内存中,查询效率是最高的,如果内存中命中不了,就会到磁盘中读取,这样效率就低了。