回归预测 | MATLAB实现Attention-GRU多输入单输出回归预测----注意力机制融合门控循环单元,即TPA-GRU,时间注意力机制结合门控循环单元
目录
效果一览





基本介绍
MATLAB实现Attention-GRU多输入单输出回归预测(注意力机制融合门控循环单元,也可称呼TPA-GRU,时间注意力机制结合门控循环单元),将注意力机制( attention mechanism) 引入GRU( gated recurrent unit) 模型之中,最后,将特征数据集划分为训练集、验证集和测试集,训练集用于训练模型,确定最优模型参数,验证集和测试集用于对模型效果进行评估。
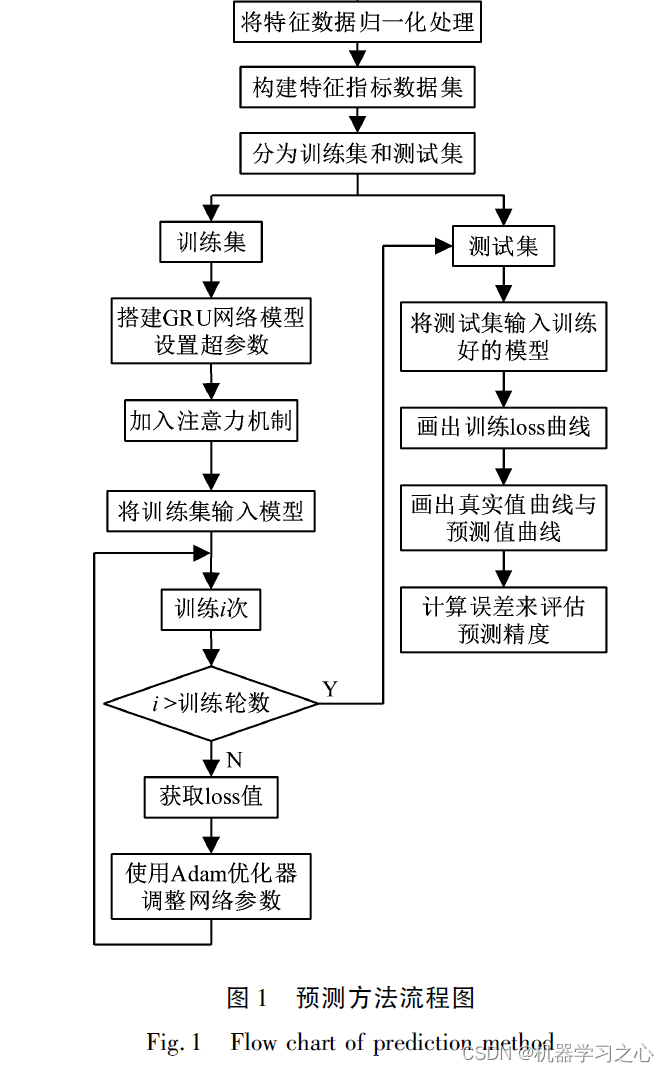
模型结构
相较于LSTM,GRU网络比较大的改动在于:
(1)GRU网络将单元状态与输出合并为隐藏状态,依靠隐藏状态来传输信息。
(2) GRU网络将LSTM 中的遗忘门和输入门整合成为了一个更新门限。正是由于这两个创新点的引入,使得GRU 模型较LSTM 模型具有如下优点: 参数量减少了三分之一,不容易发生过拟合的现象,在一些情况下可以省略dropout 环节; 在训练数据很大的时候可以有效减少运算时间,加速迭代过程,提升运算效率; 从计算角度看,其可扩展性有利于构筑较大的模型。同时,GRU继承了LSTM 处理梯度问题的能力,其门结构可以有效过滤掉无用信息,捕捉输入数据的长期依赖关系,在处理序列问题上具有非常出色的表现。
注意力机制是深度学习中的一种仿生机制,它的提出是由人类观察环境的习惯规律所总结而来的,人类在观察环境时,大脑往往只关注某几个特别重要的局部,获取需要的信息,构建出关于环境的描述,而注意力机制正是如此,其本质就是对关注部分给予较高权重,从而获取更有效的信息,从数学意义上来说,它可以理解为是一种加权求和。注意力机制的主要作用包括:
( 1) 对输入序列的不同局部,赋予不同的权重。
( 2) 对于不同的输出序列局部,给输入局部不一样赋权规划。


程序设计
- 完整程序和数据下载:私信博主回复Attention-GRU多输入单输出回归预测。
%% 注意力参数
Attentionweight = params.attention.weight; % 计算得分权重
Ht = GRU_Y(:, :, end); % 参考向量
num_time = size(GRU_Y, 3); % 时间尺度
%% 注意力得分
socre = dlarray;
for i = 1: num_time - 1
A = extractdata(squeeze(GRU_Y(:, :, i)));
A = repmat(A, [1, 1, num_hidden]);
A = permute(A, [1, 3, 2]);
A = dlarray(A, 'SCB');
B = squeeze(sum(A .* dlarray(Attentionweight, 'SC'), 1));
C = squeeze(sum(B .* Ht, 1));
socre = [socre; C];
end
%% 注意力得分
a = sigmoid(socre);
Vt = 0;
for i = 1: num_time - 1
Vt = Vt + a(i, :) .* GRU_Y(:, :, i);
end
%% 注意力机制
bias1 = params.attenout.bias1;
bias2 = params.attenout.bias2;
weight1 = params.attenout.weight1;
weight2 = params.attenout.weight2;
HVT = fullyconnect(Vt, weight1, bias1) + fullyconnect(Ht, weight2, bias2);
%% 全连接层
LastBias = params.fullyconnect.bias1;
LastWeight = params.fullyconnect.weight1;
%% 注意力参数初始化
params.attention.weight = gpuArray(dlarray(0.01 * randn(num_hidden, num_hidden)));
%% 注意力权重初始化
params.attenout.weight1 = gpuArray(dlarray(0.01 * randn(num_hidden, num_hidden)));
params.attenout.weight2 = gpuArray(dlarray(0.01 * randn(num_hidden, num_hidden)));
参考资料
[1] https://blog.csdn.net/kjm13182345320/article/details/127944569?spm=1001.2014.3001.5502
[2] https://blog.csdn.net/kjm13182345320/article/details/127944537?spm=1001.2014.3001.5502